"Övning – Skapa ett Azure Data Factory-mappningsdataflöde"
Transformera data med Dataflöde
Du kan utföra datatransformeringar internt med Azure Data Factory-kod utan kostnad med hjälp av uppgiften Mappning Dataflöde. Mappning Dataflöde ger en helt visuell upplevelse utan att kodning krävs. Dina dataflöden körs i ditt eget körningskluster för utskalad databearbetning. Dataflödesaktiviteter kan operationaliseras via befintliga datafabriksfunktioner för schemaläggning, kontroll, flöde och övervakning.
När du skapar dataflöden kan du aktivera felsökningsläge, som aktiverar ett litet interaktivt Spark-kluster. Aktivera felsökningsläget genom att växla skjutreglaget överst i redigeringsmodulen. Det tar några minuter att värma upp felsökningskluster, men kan användas för att interaktivt förhandsgranska utdata från omvandlingslogik.

När Dataflöde mappning har lagts till och Spark-klustret körs kan du utföra omvandlingen och köra och förhandsgranska data. Ingen kodning krävs eftersom Azure Data Factory hanterar all kodöversättning, sökvägsoptimering och körning av dina dataflödesjobb.
Lägga till källdata i Dataflöde
Öppna arbetsytan Mappning Dataflöde. Klicka på knappen Lägg till källa på arbetsytan Dataflöde. I listrutan källdatauppsättning väljer du din datakälla. I det här fallet används ADLS Gen2-datauppsättningen i det här exemplet
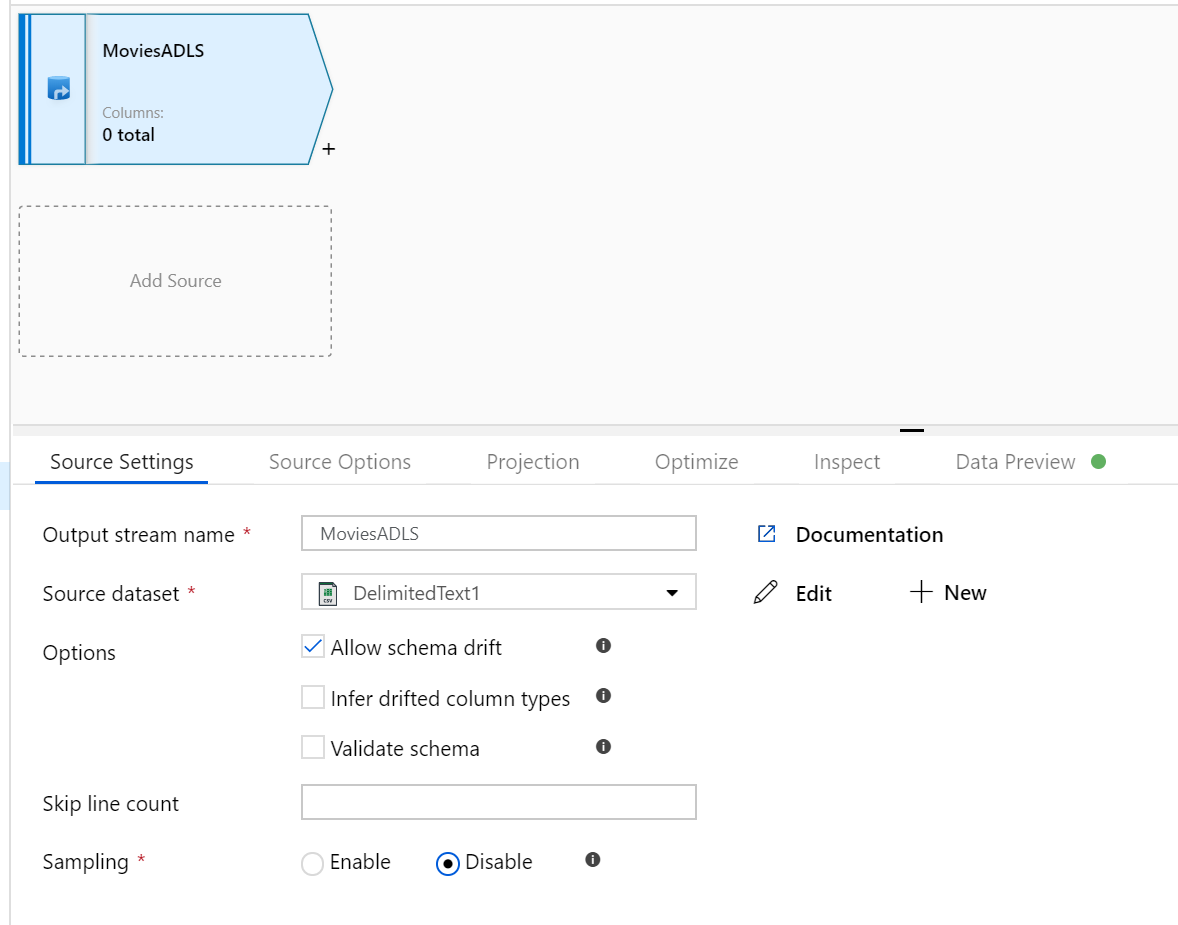
Det finns några punkter att notera:
- Om din datauppsättning pekar på en mapp med andra filer och du bara vill använda en fil kan du behöva skapa en annan datauppsättning eller använda parameterisering för att se till att endast en specifik fil läss
- Om du inte har importerat schemat i din ADLS, men redan har matat in dina data, går du till datauppsättningens schemaflik och klickar på Importera schema så att dataflödet känner till schemaprojektionen.
Mappning Dataflöde följer en elt-metod (extract, load, transform) och fungerar med mellanlagringsdatauppsättningar som alla finns i Azure. För närvarande kan följande datauppsättningar användas i en källtransformering:
- Azure Blob Storage (JSON, Avro, Text, Parquet)
- Azure Data Lake Storage Gen1 (JSON, Avro, Text, Parquet)
- Azure Data Lake Storage Gen2 (JSON, Avro, Text, Parquet)
- Azure Synapse Analytics
- Azure SQL Database
- Azure Cosmos DB
Azure Data Factory har åtkomst till över 80 interna anslutningsappar. Om du vill inkludera data från de andra källorna i dataflödet använder du kopieringsaktiviteten för att läsa in dessa data i något av de mellanlagringsområden som stöds.
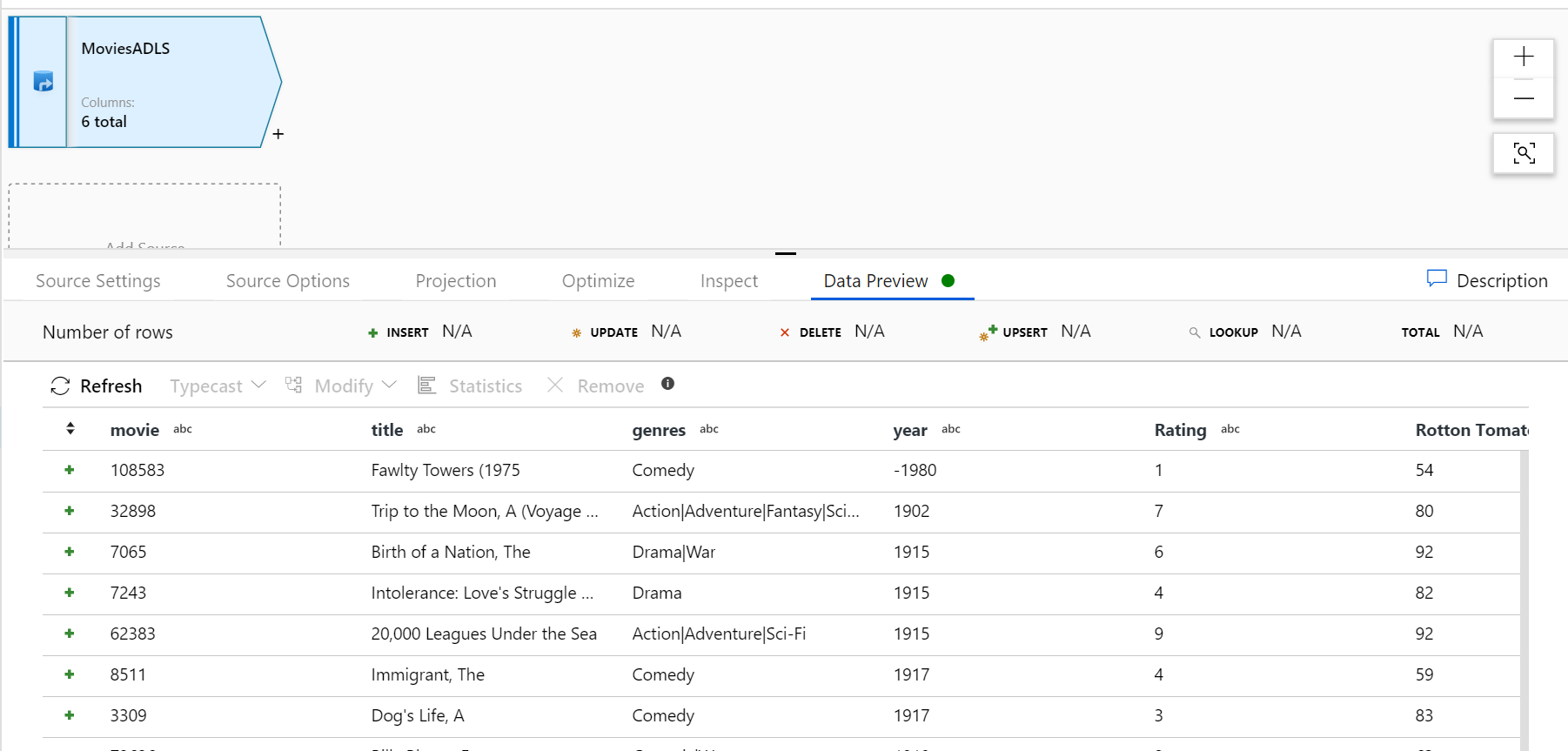
När felsökningsklustret har värmts upp kontrollerar du att dina data har lästs in korrekt via fliken Dataförhandsgranskning. När du klickar på uppdateringsknappen visar Mappning Dataflöde en ögonblicksbild av hur dina data ser ut när de är vid varje transformering.
Använda transformeringar i Dataflöde
Nu när du har flyttat data till Azure Data Lake Store Gen2 är du redo att skapa en mappnings-Dataflöde som omvandlar dina data i stor skala via ett Spark-kluster och sedan läser in dem i ett informationslager.
Huvuduppgifterna för detta är följande:
Förbereda miljön
Lägga till en datakälla
Använda mappning Dataflöde transformering
Skriva till en datamottagare
Uppgift 1: Förbereda miljön
Aktivera Dataflöde Felsökning Aktivera skjutreglaget Dataflöde Felsökning längst upp i redigeringsmodulen.
Kommentar
Dataflöde kluster tar 5–7 minuter att värma upp.
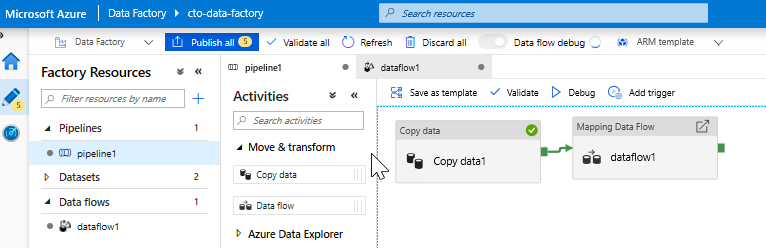
Lägg till en Dataflöde aktivitet. Öppna dragspelet Flytta och transformera i fönstret Aktiviteter och dra aktiviteten Dataflöde till pipelinearbetsytan. På bladet som visas klickar du på Skapa ny Dataflöde och väljer Mappning Dataflöde och klickar sedan på OK. Klicka på fliken pipeline1 och dra den gröna rutan från din aktiviteten Kopiera till Dataflöde-aktiviteten för att skapa ett villkor för att lyckas. Du ser följande på arbetsytan:
Uppgift 2: Lägga till en datakälla
Lägg till en ADLS-källa. Dubbelklicka på objektet Mappning Dataflöde på arbetsytan. Klicka på knappen Lägg till källa på arbetsytan Dataflöde. I listrutan Källdatauppsättning väljer du din ADLSG2-datauppsättning som används i din aktiviteten Kopiera
- Om din datauppsättning pekar på en mapp med andra filer kan du behöva skapa en annan datauppsättning eller använda parameterisering för att se till att endast filen moviesDB.csv är läst
- Om du inte har importerat schemat i din ADLS, men redan har matat in dina data, går du till datauppsättningens schemaflik och klickar på Importera schema så att dataflödet känner till schemaprojektionen.
När felsökningsklustret har värmts upp kontrollerar du att dina data har lästs in korrekt via fliken Dataförhandsgranskning. När du klickar på uppdateringsknappen visar Mappning Dataflöde en ögonblicksbild av hur dina data ser ut när de är vid varje transformering.
Uppgift 3: Använda mappning Dataflöde transformering
Lägg till en Välj transformering för att byta namn på och släppa en kolumn. I förhandsversionen av data kanske du har märkt att kolumnen "Rotton Tomatoes" är felstavad. Om du vill ge den ett korrekt namn och släppa den oanvända klassificeringskolumnen kan du lägga till en Välj transformering genom att klicka på ikonen + bredvid ADLS-källnoden och välja Välj under Schemamodifierare.
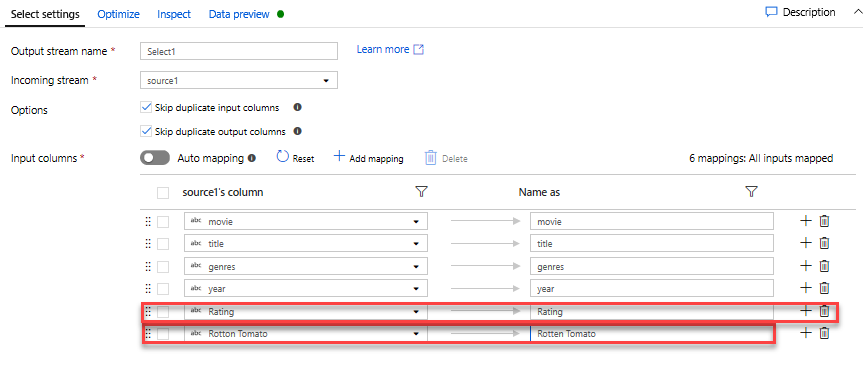
I fältet Namn som ändrar du "Rotton" till "Rotten". Om du vill släppa kolumnen Klassificering hovra över den och klicka på papperskorgsikonen.
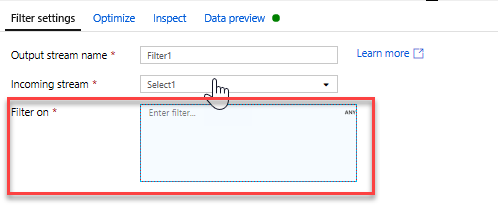
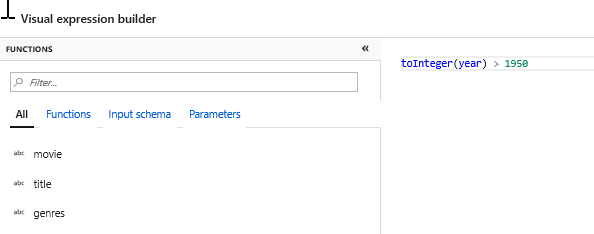
Lägg till en filtertransformering för att filtrera bort oönskade år. Säg att du bara är intresserad av filmer gjorda efter 1951. Du kan lägga till en filtertransformering för att ange ett filtervillkor genom att klicka på ikonen + bredvid välj transformering och välja Filter under Radmodifierare. Klicka på uttrycksrutanför att öppna uttrycksverktyget och ange i filtervillkoret. Med syntaxen för uttrycksspråket Mappning Dataflöde konverterar toInteger(year) > 1950 strängårsvärdet till ett heltal och filtrerar rader om värdet är över 1950.
Du kan använda uttrycksverktygets inbäddade förhandsgranskningsfönster för data för att kontrollera att villkoret fungerar korrekt
Lägg till en Härled transformering för att beräkna den primära genren. Som du kanske har märkt är kolumnen genrer en sträng avgränsad med ett |-tecken. Om du bara bryr dig om den första genren i varje kolumn kan du härleda en ny kolumn med namnet PrimaryGenre via transformeringen Härledd kolumn genom att klicka på ikonen + bredvid filteromvandlingen och välja Härledd under Schemamodifierare. Precis som filtertransformeringen använder den härledda kolumnen byggare för mappning Dataflöde uttryck för att ange värdena för den nya kolumnen.

I det här scenariot försöker du extrahera den första genren från kolumnen genrer, som är formaterad som "genre1|genre2|...|genreN'. Använd funktionen locate för att hämta det första 1-baserade indexet för |i genresträngen. Om indexet är större än 1 med funktionen iif kan den primära genren beräknas via den vänstra funktionen, som returnerar alla tecken i en sträng till vänster om ett index. Annars är Värdet PrimaryGenre lika med genrefältet. Du kan verifiera utdata via uttrycksverktygets fönstret Dataförhandsgranskning.
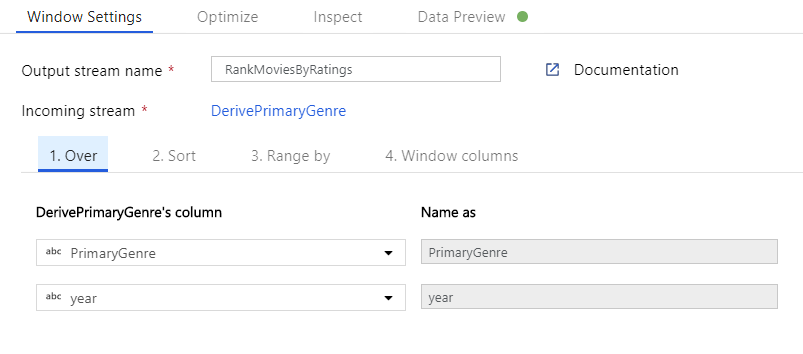
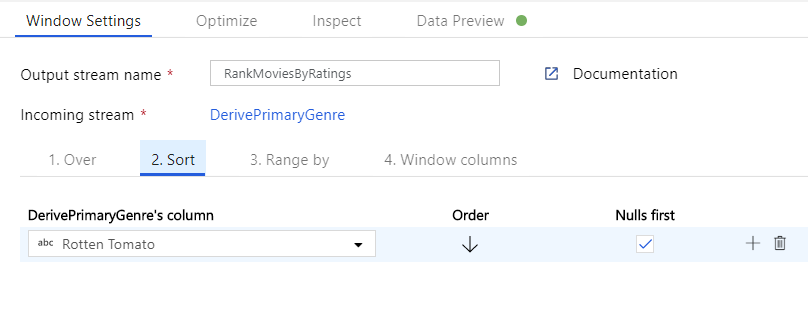
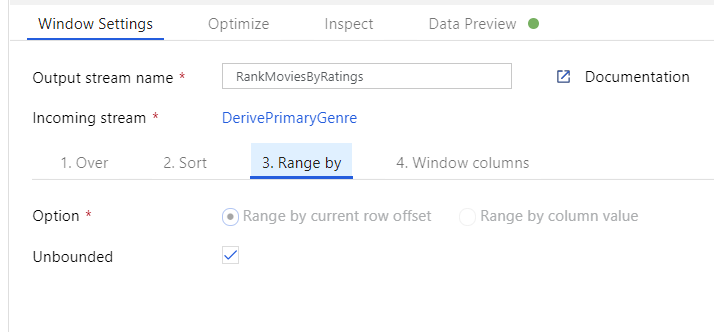
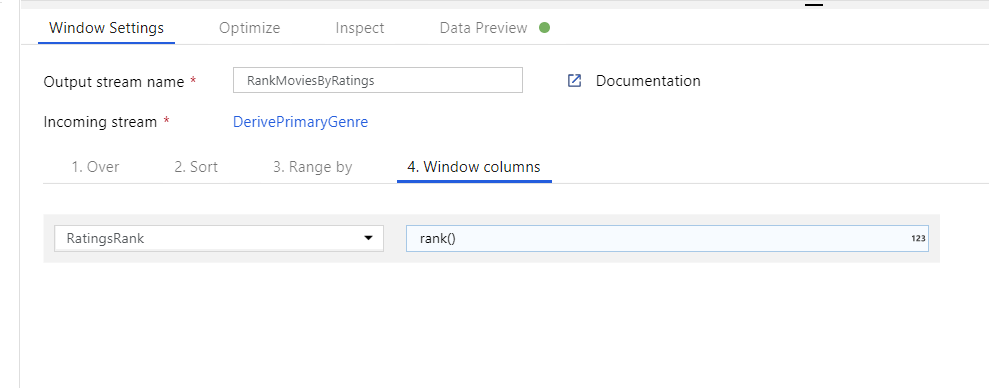
Rangordna filmer via en fönsteromvandling. Anta att du är intresserad av hur en film rankas inom sitt år för sin specifika genre. Du kan lägga till en fönstertransformering för att definiera fönsterbaserade aggregeringar genom att klicka på ikonen + bredvid omvandlingen av den härledda kolumnen och klicka på Fönstret under Schemamodifierare. För att åstadkomma detta anger du vad du fönsterar över, vad du sorterar efter, vad intervallet är och hur du beräknar dina nya fönsterkolumner. I det här exemplet kommer vi att fönster över PrimaryGenre och år med ett obundet intervall, sortera efter Rotten Tomato fallande och beräkna en ny kolumn med namnet RatingsRank som är lika med den rangordning som varje film har inom sitt specifika genreår.
Aggregera klassificeringar med en aggregerad transformering. Nu när du har samlat in och härlett alla nödvändiga data kan vi lägga till en aggregerad transformering för att beräkna mått baserat på en önskad grupp genom att klicka på ikonen + bredvid fönsteromvandlingen och klicka på Aggregera under Schemamodifierare. Precis som i fönsteromvandlingen kan du gruppera filmer efter PrimaryGenre och år
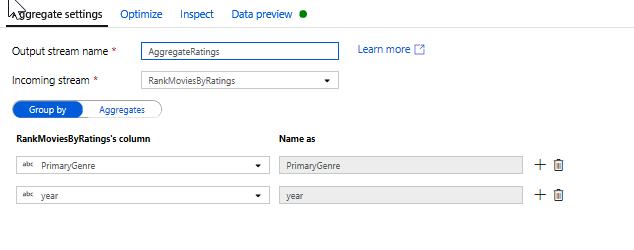
På fliken Aggregeringar kan du skapa aggregeringar som beräknas över den angivna gruppen efter kolumner. För varje genre och år kan vi få det genomsnittliga Rotten Tomatoes-betyget, den högst och lägst rankade filmen (med hjälp av fönsterfunktionen) och antalet filmer som finns i varje grupp. Sammansättning minskar avsevärt antalet rader i omvandlingsströmmen och sprider bara gruppen efter och aggregerade kolumner som anges i omvandlingen.
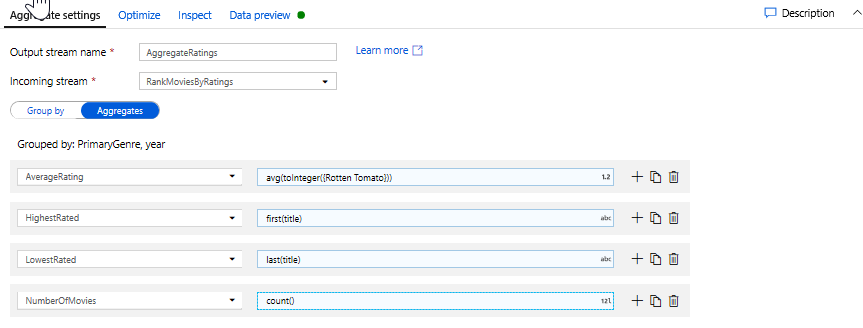
- Om du vill se hur den aggregerade omvandlingen ändrar dina data använder du fliken Dataförhandsgranskning
Ange Upsert-villkor via en Alter Row-transformering. Om du skriver till en tabellmottagare kan du ange principer för infoga, ta bort, uppdatera och utöka rader med transformering av alter row genom att klicka på ikonen + bredvid din aggregerade transformering och klicka på Ändra rad under Radmodifierare. Eftersom du alltid infogar och uppdaterar kan du ange att alla rader alltid ska utökas.

Uppgift 4: Skriva till en datamottagare
- Skriv till en Azure Synapse Analytics-mottagare. Nu när du har slutfört all omvandlingslogik är du redo att skriva till en mottagare.
Lägg till en mottagare genom att klicka på ikonen + bredvid din Upsert-transformering och klicka på Mottagare under Mål.
På fliken Mottagare skapar du en ny datamängd för informationslagret via knappen + Ny.
Välj Azure Synapse Analytics i panellistan.
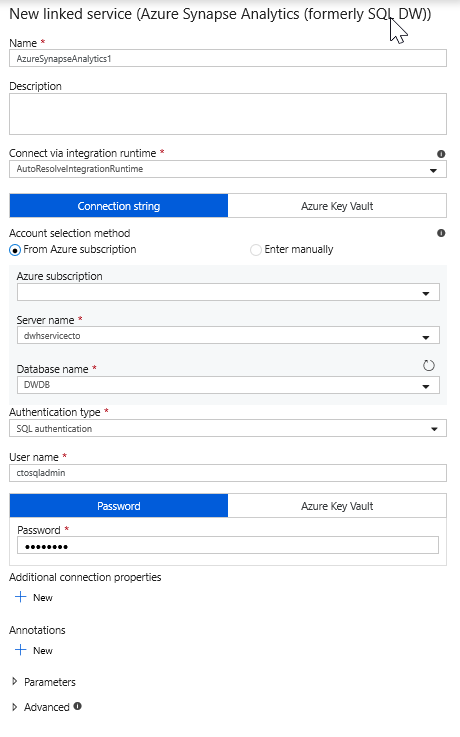
Välj en ny länkad tjänst och konfigurera din Azure Synapse Analytics-anslutning för att ansluta till DWDB-databasen. Klicka på Skapa när du är klar.
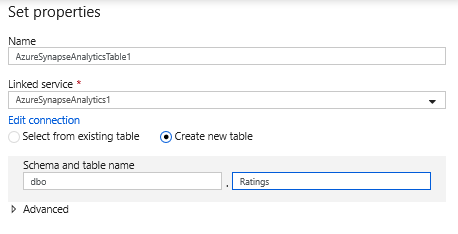
I datauppsättningskonfigurationen väljer du Skapa ny tabell och anger i schemat för Dbo och tabellnamnet ratings. Klicka på OK när det är klart.
Eftersom ett upsert-villkor har angetts måste du gå till fliken Inställningar och välja Tillåt upsert baserat på nyckelkolumnerna PrimaryGenre och year.
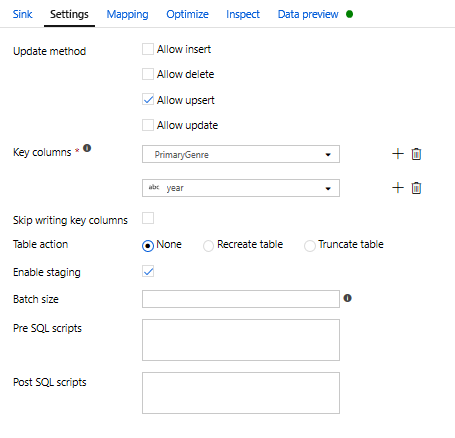
Nu har du skapat din 8-transformeringsmappning Dataflöde. Det är dags att köra pipelinen och se resultatet!

Uppgift 5: Köra pipelinen
Gå till fliken pipeline1 på arbetsytan. Eftersom Azure Synapse Analytics i Dataflöde använder PolyBase måste du ange en blob- eller ADLS-mellanlagringsmapp. På fliken Kör Dataflöde aktivitetsinställningar öppnar du PolyBase-dragspelet och väljer den länkade ADLS-tjänsten och anger en sökväg för mellanlagringsmappen.
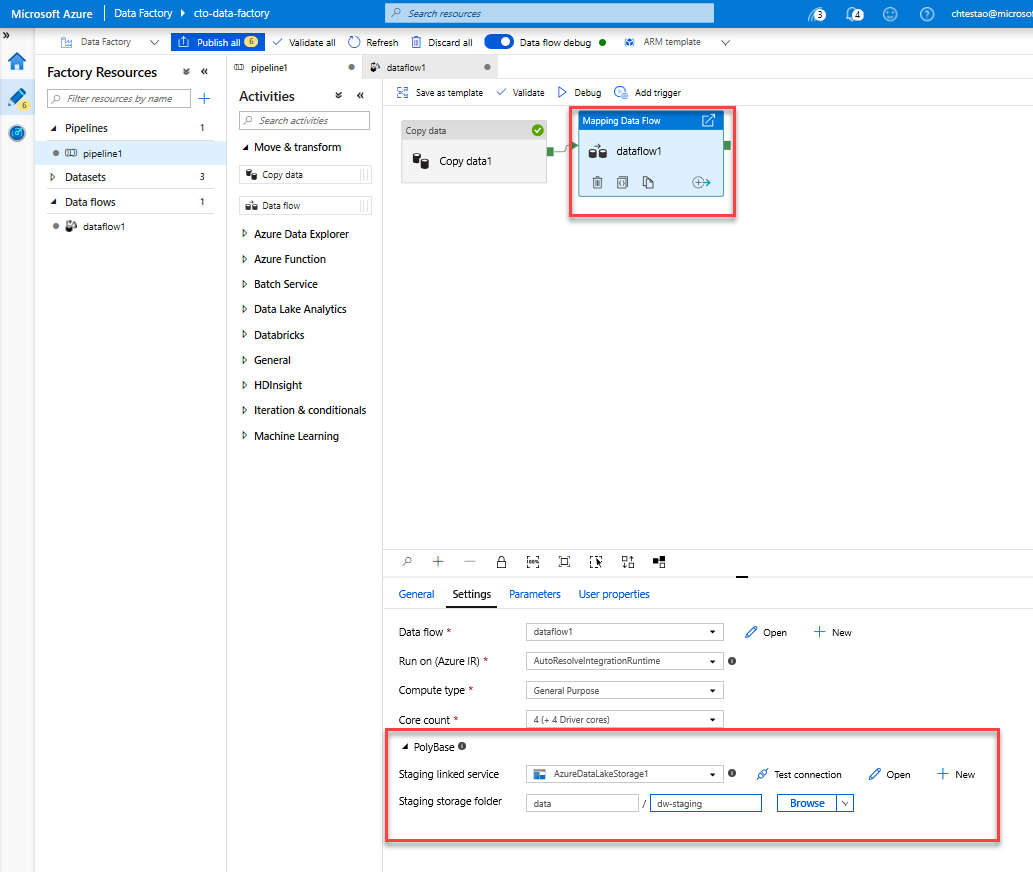
Innan du publicerar pipelinen kör du en annan felsökningskörning för att bekräfta att den fungerar som förväntat. Om du tittar på fliken Utdata kan du övervaka statusen för båda aktiviteterna när de körs.
När båda aktiviteterna har slutförts kan du klicka på glasögonikonen bredvid Dataflöde aktivitet för att få en mer djupgående titt på Dataflöde körning.
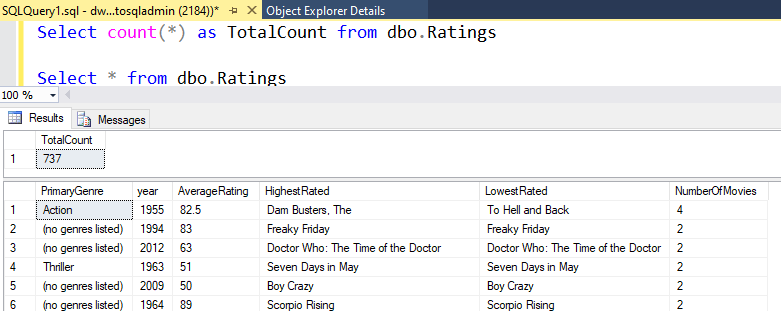
Om du använde samma logik som beskrivs i den här labbuppgiften kommer din Dataflöde att skriva 737 rader till SQL DW. Du kan gå till SQL Server Management Studio för att verifiera att pipelinen fungerade korrekt och se vad som skrevs.