หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
APPLIES TO:  Azure Data Factory
Azure Synapse Analytics
Azure Data Factory
Azure Synapse Analytics
Tip
Data Factory in Microsoft Fabric is the next generation of Azure Data Factory, with a simpler architecture, built-in AI, and new features. If you're new to data integration, start with Fabric Data Factory. Existing ADF workloads can upgrade to Fabric to access new capabilities across data science, real-time analytics, and reporting.
Several mapping data flows transformations allow you to reference template columns based on patterns instead of hard-coded column names. This matching is known as column patterns. You can define patterns to match columns based on name, data type, stream, origin, or position instead of requiring exact field names. There are two scenarios where column patterns are useful:
- If incoming source fields change often such as the case of changing columns in text files or NoSQL databases. This scenario is known as schema drift.
- If you wish to do a common operation on a large group of columns. For example, wanting to cast every column that has 'total' in its column name into a double.
Column patterns in derived column and aggregate
To add a column pattern in a derived column, aggregate, or window transformation, click on Add above the column list or the plus icon next to an existing derived column. Choose Add column pattern.
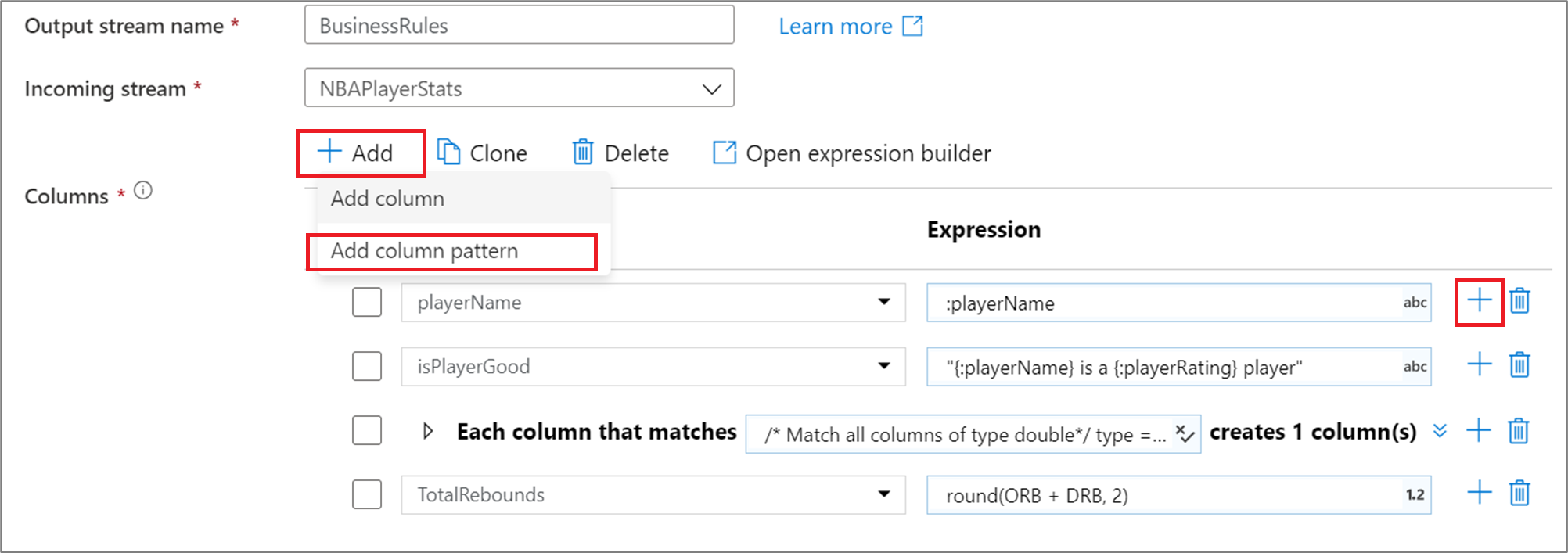
Use the expression builder to enter the match condition. Create a boolean expression that matches columns based on the name, type, stream, origin, and position of the column. The pattern will affect any column, drifted or defined, where the condition returns true.
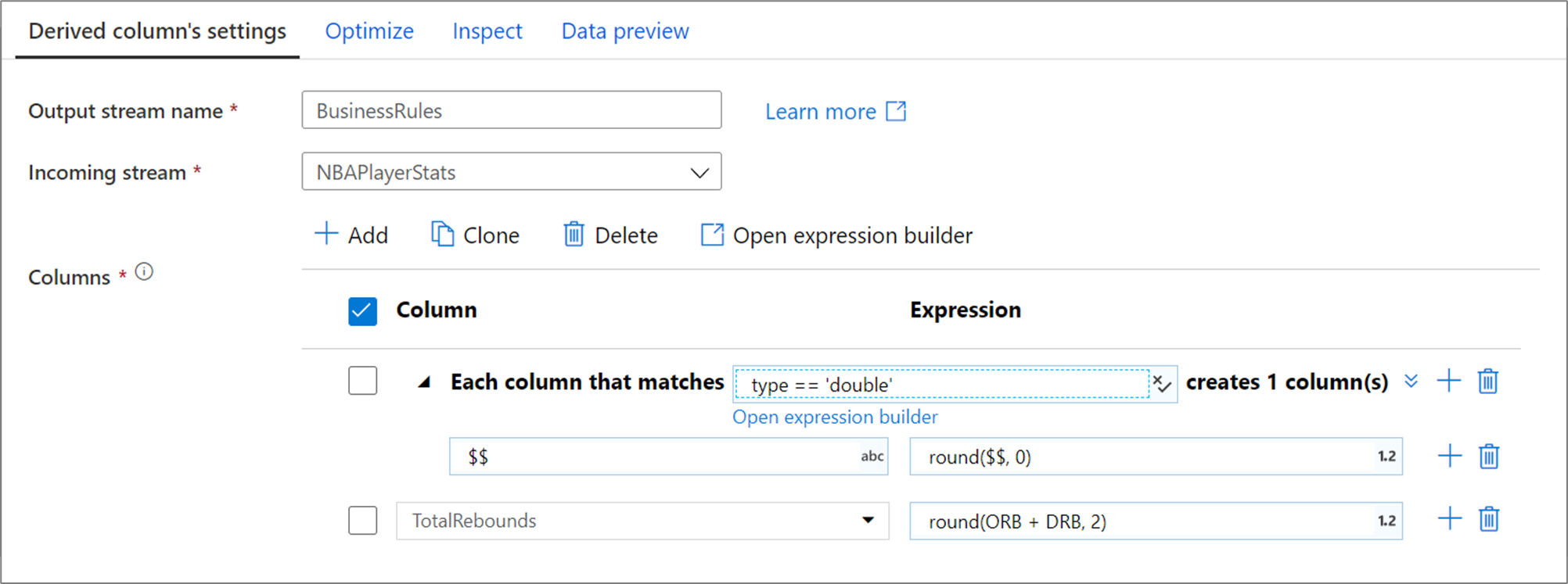
The above column pattern matches every column of type double and creates one derived column per match. By stating $$ as the column name field, each matched column is updated with the same name. The value of each column is the existing value rounded to two decimal points.
To verify your matching condition is correct, you can validate the output schema of defined columns in the Inspect tab or get a snapshot of the data in the Data preview tab.
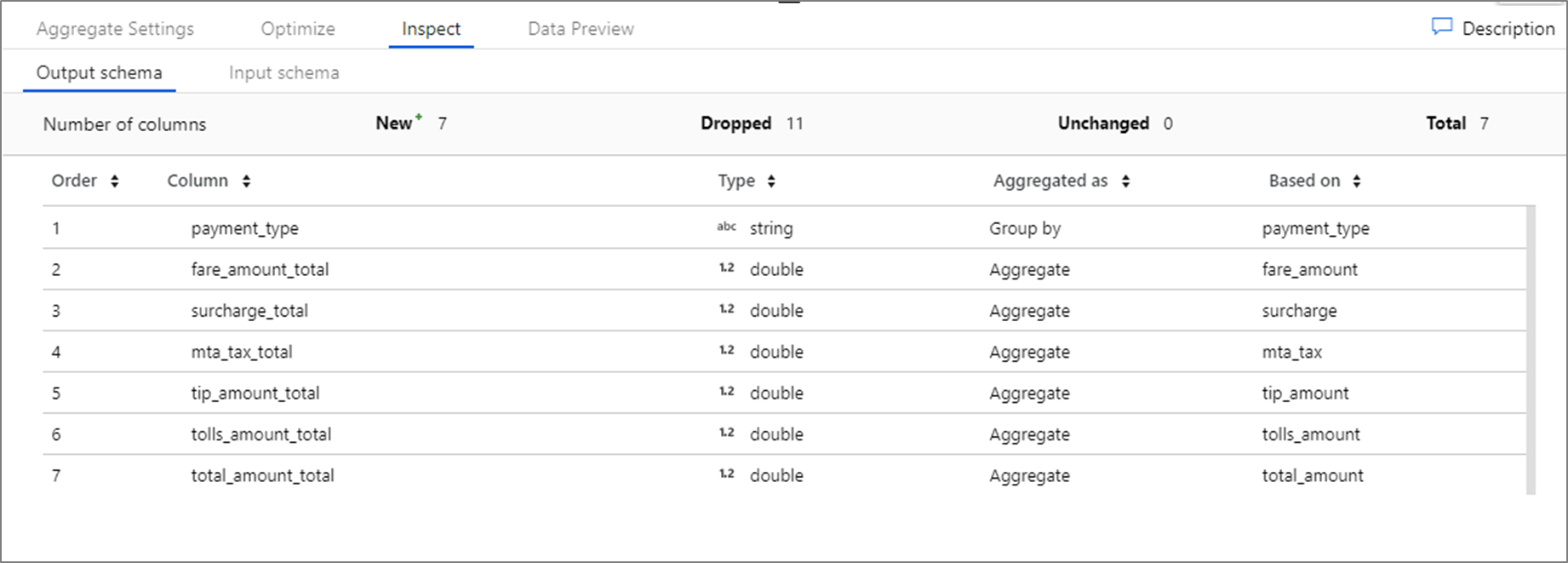
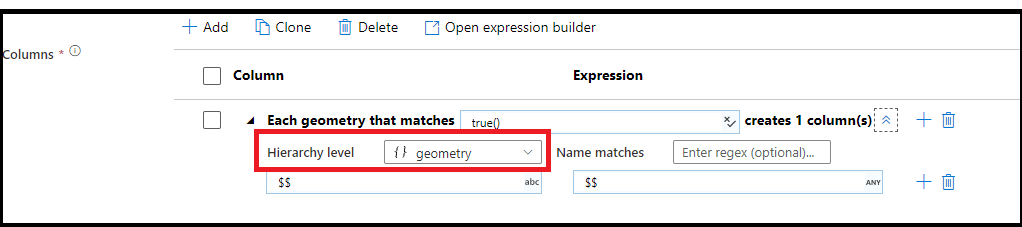
Hierarchical pattern matching
You can build pattern matching inside of complex hierarchical structures as well. Expand the section Each MoviesStruct that matches where you will be prompted for each hierarchy in your data stream. You can then build matching patterns for properties within that chosen hierarchy.
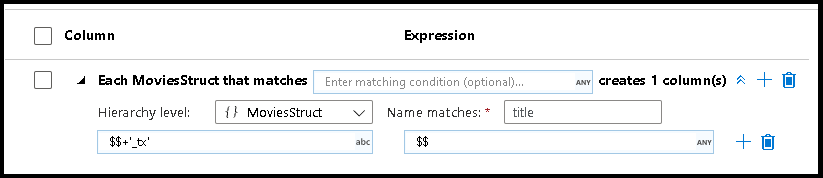
Flattening structures
When your data has complex structures like arrays, hierarchical structures, and maps, you can use the Flatten transformation to unroll arrays and denormalize your data. For structures and maps, use the derived column transformation with column patterns to form your flattened relational table from the hierarchies. You can use the column patterns that would look like this sample, which flattens the geography hierarchy into a relational table form:
Rule-based mapping in select and sink
When mapping columns in source and select transformations, you can add either fixed mapping or rule-based mappings. Match based on the name, type, stream, origin, and position of columns. You can have any combination of fixed and rule-based mappings. By default, all projections with greater than 50 columns will default to a rule-based mapping that matches on every column and outputs the inputted name.
To add a rule-based mapping, click Add mapping and select Rule-based mapping.

Each rule-based mapping requires two inputs: the condition on which to match by and what to name each mapped column. Both values are inputted via the expression builder. In the left expression box, enter your boolean match condition. In the right expression box, specify what the matched column will be mapped to.

Use $$ syntax to reference the input name of a matched column. Using the above image as an example, say a user wants to match on all string columns whose names are shorter than six characters. If one incoming column was named test, the expression $$ + '_short' will rename the column test_short. If that's the only mapping that exists, all columns that don't meet the condition will be dropped from the outputted data.
Patterns match both drifted and defined columns. To see which defined columns are mapped by a rule, click the eyeglasses icon next to the rule. Verify your output using data preview.
Regex mapping
If you click the downward chevron icon, you can specify a regex-mapping condition. A regex-mapping condition matches all column names that match the specified regex condition. This can be used in combination with standard rule-based mappings.

The above example matches on regex pattern (r) or any column name that contains a lower case r. Similar to standard rule-based mapping, all matched columns are altered by the condition on the right using $$ syntax.
Rule-based hierarchies
If your defined projection has a hierarchy, you can use rule-based mapping to map the hierarchies subcolumns. Specify a matching condition and the complex column whose subcolumns you wish to map. Every matched subcolumn will be outputted using the 'Name as' rule specified on the right.
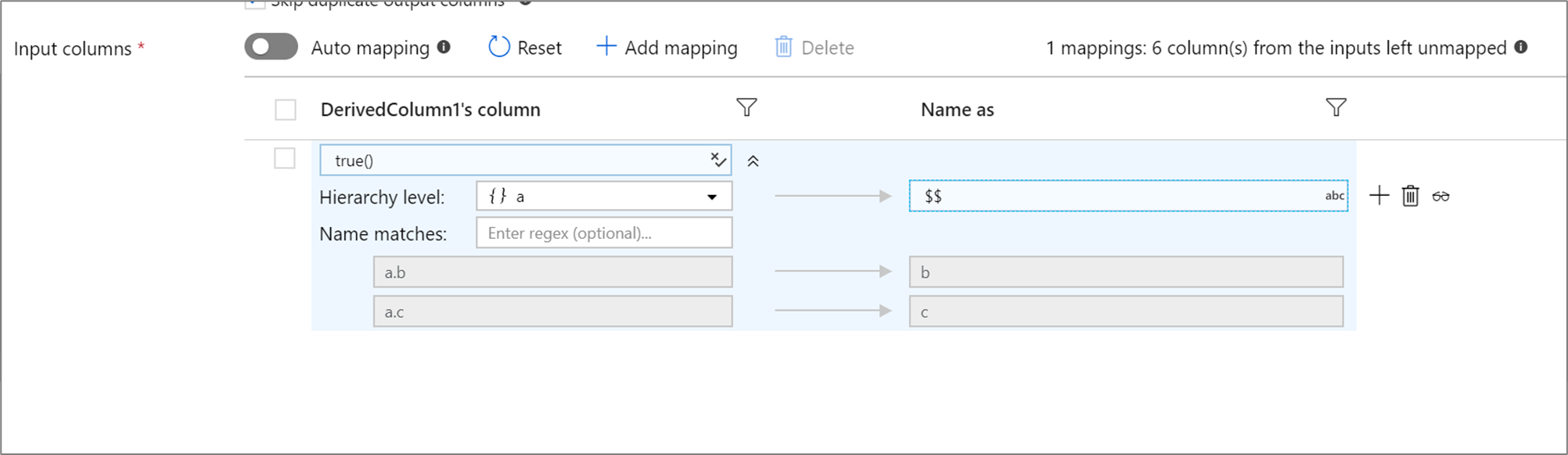
The above example matches on all subcolumns of complex column a. a contains two subcolumns b and c. The output schema will include two columns b and c as the 'Name as' condition is $$.
Pattern matching expression values
$$translates to the name or value of each match at run time. Think of$$as equivalent tothis$0translates to the current column name match at run time for scalar types. For hierarchical types,$0represents the current matched column hierarchy path.namerepresents the name of each incoming columntyperepresents the data type of each incoming column. The list of data types in the data flows type system can be found here.streamrepresents the name associated with each stream, or transformation in your flowpositionis the ordinal position of columns in your data floworiginis the transformation where a column originated or was last updated
Related content
- Learn more about the mapping data flows expression language for data transformations
- Use column patterns in the sink transformation and select transformation with rule-based mapping