หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
รันไทม์ Fabric ให้การรวมที่ราบรื่นกับ Azure ซึ่งมีสภาพแวดล้อมที่ซับซ้อนสําหรับทั้งโครงการวิศวกรรมข้อมูลและวิทยาศาสตร์ข้อมูลที่ใช้ Apache Spark บทความนี้ให้ภาพรวมของคุณลักษณะและส่วนประกอบที่สําคัญของ Fabric Runtime 1.3
Microsoft Fabric Runtime 1.3 เป็นรุ่นรันไทม์ GA ที่รวมส่วนประกอบและการอัปเกรดต่อไปนี้ที่ออกแบบมาเพื่อปรับปรุงความสามารถในการประมวลผลข้อมูลของคุณ:
อาปาเช่ สปาร์ค 3.5
ระบบปฏิบัติการ: Mariner 2.0 (Azure Linux 2.0)
ชวา: 11
สเกลา: 2.12.17
งูหลาม: 3.11
ทะเลสาบเดลต้า: 3.2
แนวต้าน: 4.4.1
เคล็ดลับ
Fabric Runtime 1.3 มีการสนับสนุนสําหรับ กลไกจัดการการดําเนินการแบบเนทีฟซึ่งสามารถเพิ่มประสิทธิภาพได้อย่างมากโดยไม่มีค่าใช้จ่ายเพิ่มเติม เมื่อต้องการเปิดใช้งานกลไกการดําเนินการแบบดั้งเดิมในทุกงานและสมุดบันทึกในสภาพแวดล้อมของคุณ ให้นําทางไปยังการตั้งค่าสภาพแวดล้อมของคุณ เลือก Spark compute ไปที่แท็บ Acceleration และตรวจสอบ เปิดใช้งานกลไกการดําเนินการแบบดั้งเดิม หลังจากที่คุณบันทึกและเผยแพร่แล้ว การตั้งค่านี้จะนําไปใช้ในสภาพแวดล้อมดังนั้นงานใหม่และสมุดบันทึกทั้งหมดจะสืบทอดและได้รับประโยชน์จากความสามารถด้านประสิทธิภาพการทํางานที่ดีขึ้นโดยอัตโนมัติ
รวมรันไทม์ 1.3
Note
สําหรับข้อมูลเกี่ยวกับรันไทม์ Fabric ที่มีอยู่ทั้งหมดและสถานะปัจจุบัน โปรดดู รันไทม์ Apache Spark ใน Fabric
ใช้คําแนะนําต่อไปนี้เพื่อรวมรันไทม์ 1.3 ลงในพื้นที่ทํางานของคุณ และใช้คุณลักษณะใหม่:
นําทางไปยังแท็บ การตั้งค่า พื้นที่ทํางานภายในพื้นที่ทํางาน Fabric ของคุณ
ไปที่แท็บ วิศวกรข้อมูล/วิทยาศาสตร์ และเลือก การตั้งค่า Spark
เลือกแท็บ สภาพแวดล้อม
ภายใต้เวอร์ชันรันไทม์ ขยายรายการแบบเลื่อนลง
เลือก 1.3 (Spark 3.5, Delta 3.2) และบันทึกการเปลี่ยนแปลงของคุณ การดําเนินการนี้จะตั้งค่า 1.3 เป็นรันไทม์เริ่มต้นสําหรับพื้นที่ทํางานของคุณ
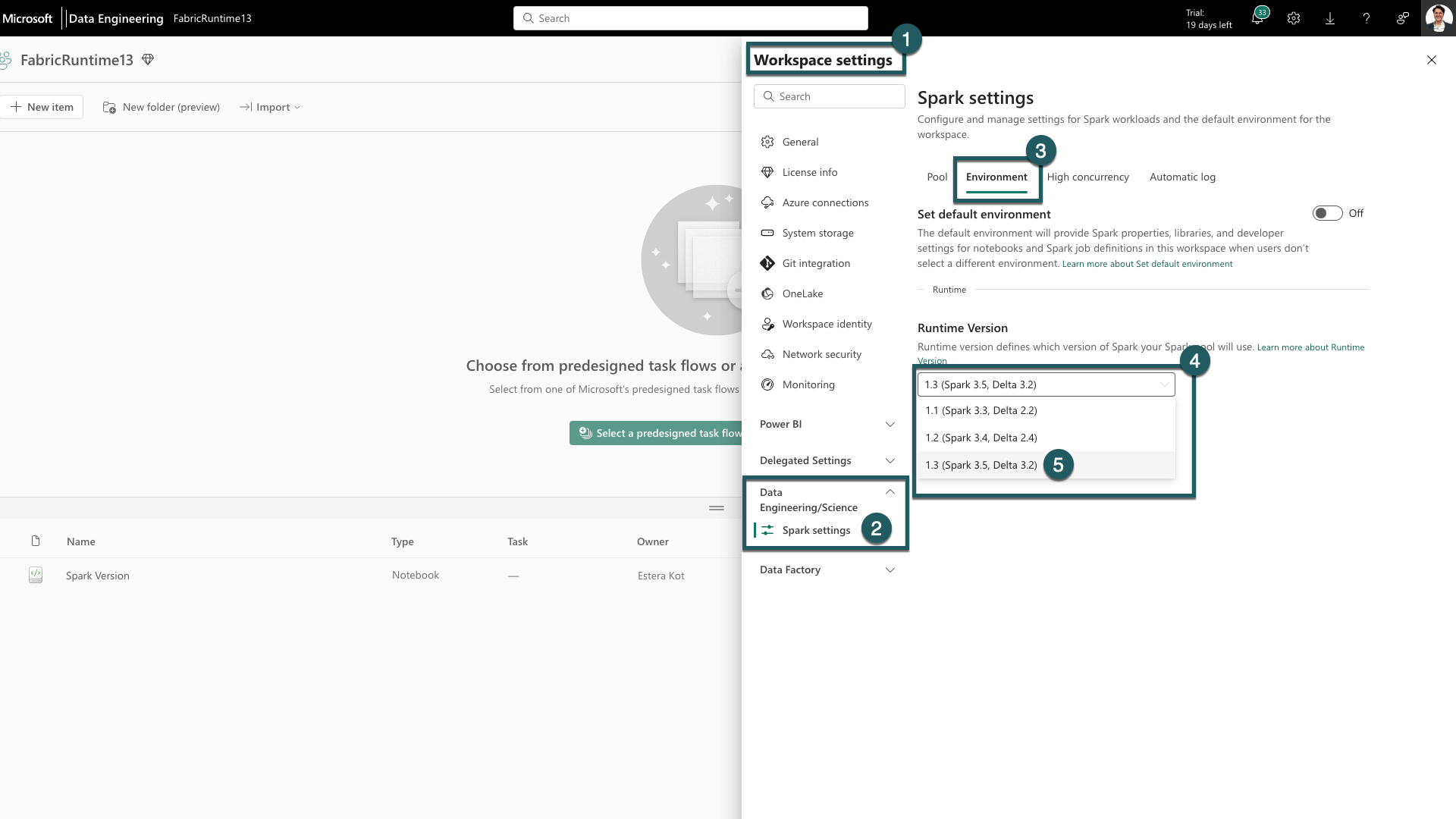

ตอนนี้คุณสามารถเริ่มต้นทํางานกับการปรับปรุงและฟังก์ชันการทํางานใหม่ล่าสุดที่แนะนําใน Fabric runtime 1.3 (Spark 3.5 และ Delta Lake 3.2) ได้แล้ว
เรียนรู้เกี่ยวกับ Apache Spark 3.5
Apache Spark 3.5.0 เป็นเวอร์ชันที่หกในซีรีส์ 3.x เวอร์ชันนี้เป็นผลิตภัณฑ์ของการทํางานร่วมกันที่ครอบคลุมภายในชุมชนโอเพนซอร์สซึ่งแก้ไขปัญหามากกว่า 1,300 ปัญหาตามที่บันทึกไว้ใน Jira
ในเวอร์ชันนี้ มีการอัปเกรดความเข้ากันได้สําหรับการสตรีมที่มีโครงสร้าง นอกจากนี้ การเผยแพร่นี้จะขยายฟังก์ชันการทํางานภายใน PySpark และ SQL ซึ่งจะเพิ่มคุณลักษณะ เช่น ส่วนคําสั่งตัวระบุ SQL อาร์กิวเมนต์ที่มีชื่อในการเรียกฟังก์ชัน SQL และการรวมอยู่ในฟังก์ชัน SQL สําหรับการรวมแบบโดยประมาณใน HyperLogLog
ความสามารถใหม่อื่น ๆ ยังรวมถึงฟังก์ชันตารางที่ผู้ใช้กําหนดเองของ Python การทําให้การฝึกอบรมแบบกระจายง่ายขึ้นผ่าน DeepSpeed และความสามารถในการสตรีมที่มีโครงสร้างใหม่ เช่น การเผยแพร่ลายน้ําและการดําเนินการ dropDuplicatesWithinWatermark
คุณสามารถตรวจสอบรายการทั้งหมดและการเปลี่ยนแปลงโดยละเอียดได้ที่นี่: Spark Release 3.5.0
เรียนรู้เกี่ยวกับ Delta Spark
Delta Lake 3.2 มีความมุ่งมั่นร่วมกันในการทําให้ Delta Lake สามารถใช้งานได้ข้ามรูปแบบ ใช้งานได้ง่ายขึ้น และมีประสิทธิภาพมากขึ้น Delta Spark 3.2 ถูกสร้างขึ้นบนยอดของ Apache Spark™ 3.5 อาร์ติแฟกต์ Delta Spark maven ถูกเปลี่ยนชื่อจาก delta-core เป็น delta-spark
คุณสามารถตรวจสอบรายการทั้งหมดและการเปลี่ยนแปลงโดยละเอียดได้ที่นี่: https://docs.delta.io/index.html
ส่วนประกอบและไลบรารี
สําหรับข้อมูลล่าสุด รายการการเปลี่ยนแปลงโดยละเอียด และบันทึกย่อประจํารุ่นเฉพาะสําหรับ Fabric runtimes ตรวจสอบและสมัครใช้งาน การเผยแพร่และการอัปเดต Spark Runtimes
Note
EventHubConnector เลิกใช้แล้วใน Fabric Runtime 1.3 (Spark 3.5) และจะถูกลบออกจาก Fabric Runtime เวอร์ชันในอนาคต ขอแนะนําให้ลูกค้าใช้ Kafka Spark Connector แทน เนื่องจาก Event Hubs เข้ากันได้กับ Kafka อยู่แล้ว คุณสามารถค้นหาข้อมูลเพิ่มเติมเกี่ยวกับการใช้ Kafka Spark Connector กับฮับเหตุการณ์ได้ที่นี่: ฮับเหตุการณ์ Kafka Spark บทช่วยสอน
เนื้อหาที่เกี่ยวข้อง
- อ่านเกี่ยวกับ รันไทม์ Apache Spark ใน Fabric - ภาพรวม การกําหนดเวอร์ชัน การสนับสนุนรันไทม์หลายรายการ และการปรับรุ่นโพรโทคอล Delta Lake
- คู่มือการโยกย้าย Spark Core
- คู่มือการโยกย้าย SQL, ชุดข้อมูล และ DataFrame
- คู่มือการโยกย้ายแบบสตรีมมิ่งที่มีโครงสร้าง
- คู่มือการโยกย้าย MLlib (Machine Learning)
- คู่มือการโยกย้าย PySpark (Python บน Spark)
- คู่มือการโยกย้าย SparkR (R บน Spark)