หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
บทช่วยสอนนี้แสดงตัวอย่างแบบ end-to-end ของเวิร์กโฟลว์ Synapse Data Science ใน Microsoft Fabric ซึ่งใช้ทั้งทรัพยากรข้อมูล nycflights13 และ R เพื่อคาดการณ์ว่าเครื่องบินมาถึงสายมากกว่า 30 นาทีหรือไม่ จากนั้นใช้ผลลัพธ์การคาดการณ์เพื่อสร้างแดชบอร์ด Power BI แบบโต้ตอบ
ในบทช่วยสอนนี้ คุณจะได้เรียนรู้วิธีการ:
ใช้แพคเกจ tidymodels
- สูตร
- parsnip
- rsample
- ขั้นตอนการทํางาน เพื่อประมวลผลข้อมูลและฝึกแบบจําลองการเรียนรู้ของเครื่อง
เขียนข้อมูลผลลัพธ์ไปยังเลคเฮ้าส์เป็นตารางเดลต้า
สร้างรายงานวิชวล Power BI เพื่อเข้าถึงข้อมูลในเลคเฮ้าส์โดยตรง
ข้อกําหนดเบื้องต้น
รับ การสมัครใช้งาน Microsoft Fabric หรือลงทะเบียนสําหรับ Microsoft Fabric รุ่นทดลองใช้ฟรี
ลงชื่อเข้าใช้ Microsoft Fabric
ใช้ตัวสลับประสบการณ์การใช้งานที่ด้านล่างซ้ายของหน้าหลักของคุณเพื่อเปลี่ยนเป็น Fabric
เปิดหรือสร้างสมุดบันทึก หากต้องการเรียนรู้วิธีการ ดู วิธีใช้สมุดบันทึก Microsoft Fabric
ตั้งค่าตัวเลือกภาษาเพื่อ SparkR (R) เพื่อเปลี่ยนภาษาหลัก
แนบสมุดบันทึกของคุณเข้ากับเลคเฮ้าส์ ทางด้านซ้าย เลือก เพิ่ม เพื่อเพิ่มเลคเฮ้าส์ที่มีอยู่แล้ว หรือเพื่อสร้างเลคเฮ้าส์
ติดตั้งแพคเกจ
ติดตั้งแพคเกจ nycflights13 เพื่อใช้โค้ดในบทช่วยสอนนี้
install.packages("nycflights13")
# Load the packages
library(tidymodels) # For tidymodels packages
library(nycflights13) # For flight data
สํารวจข้อมูล
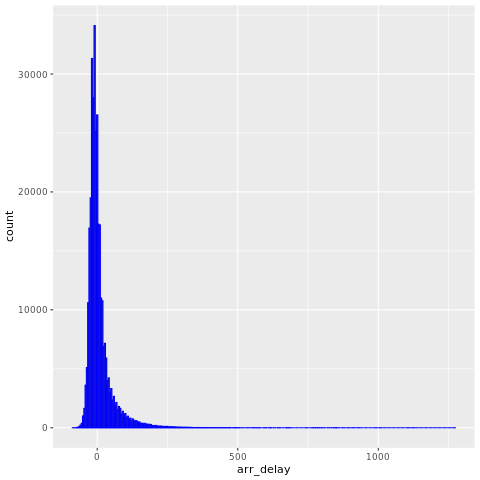
ข้อมูล nycflights13 มีข้อมูลเกี่ยวกับเที่ยวบิน 325,819 เที่ยวบินที่มาถึงใกล้เมืองนิวยอร์กในปี 2013 ก่อนอื่นให้ตรวจสอบการแจกแจงความล่าช้าของเที่ยวบิน เซลล์โค้ดต่อไปนี้จะสร้างกราฟที่แสดงว่าการแจกแจงการหน่วงเวลาการมาถึงถูกบิดขวา:
ggplot(flights, aes(arr_delay)) + geom_histogram(color="blue", bins = 300)
ซึ่งมีหางยาวในค่าสูง ดังที่แสดงในรูปต่อไปนี้:
โหลดข้อมูล และทําการเปลี่ยนแปลงบางอย่างไปยังตัวแปร:
set.seed(123)
flight_data <-
flights %>%
mutate(
# Convert the arrival delay to a factor
arr_delay = ifelse(arr_delay >= 30, "late", "on_time"),
arr_delay = factor(arr_delay),
# You'll use the date (not date-time) for the recipe that you'll create
date = lubridate::as_date(time_hour)
) %>%
# Include weather data
inner_join(weather, by = c("origin", "time_hour")) %>%
# Retain only the specific columns that you'll use
select(dep_time, flight, origin, dest, air_time, distance,
carrier, date, arr_delay, time_hour) %>%
# Exclude missing data
na.omit() %>%
# For creating models, it's better to have qualitative columns
# encoded as factors (instead of character strings)
mutate_if(is.character, as.factor)
ก่อนที่เราจะสร้างแบบจําลอง ให้พิจารณาตัวแปรเฉพาะบางตัวที่มีความสําคัญสําหรับการประมวลผลเบื้องต้นและการสร้างแบบจําลอง
ตัวแปร arr_delay เป็นตัวแปรตัวประกอบ สําหรับการฝึกแบบจําลองการถดถอยโลจิสติกส์ เป็นสิ่งสําคัญที่ตัวแปรผลลัพธ์คือตัวแปรปัจจัย
glimpse(flight_data)
ประมาณ 16% ของเที่ยวบินในชุดข้อมูลนี้มาถึงสายมากกว่า 30 นาที:
flight_data %>%
count(arr_delay) %>%
mutate(prop = n/sum(n))
ฟีเจอร์ dest นี้มี 104 ปลายทางของเที่ยวบิน:
unique(flight_data$dest)
มี 16 ผู้ให้บริการที่แตกต่างกัน:
unique(flight_data$carrier)
แยกข้อมูล
แยกชุดข้อมูลเดี่ยวออกเป็นสองชุด: ชุด การฝึกอบรม
ใช้แพคเกจ rsample เพื่อสร้างวัตถุที่ประกอบด้วยข้อมูลเกี่ยวกับวิธีการแยกข้อมูล จากนั้นใช้สองฟังก์ชัน rsample เพิ่มเติมเพื่อสร้าง DataFrames สําหรับชุดการทดสอบและการฝึกอบรม:
set.seed(123)
# Keep most of the data in the training set
data_split <- initial_split(flight_data, prop = 0.75)
# Create DataFrames for the two sets:
train_data <- training(data_split)
test_data <- testing(data_split)
สร้างสูตรอาหารและบทบาท
สร้างสูตรสําหรับแบบจําลองการถดถอยโลจิสติกส์อย่างง่าย ก่อนการฝึกแบบจําลอง ให้ใช้สูตรเพื่อสร้างตัวคาดการณ์ใหม่และดําเนินการประมวลผลล่วงหน้าที่แบบจําลองต้องการ
update_role()ใช้ฟังก์ชัน ที่มีบทบาทแบบกําหนดเองที่IDชื่อว่า เพื่อให้สูตรสูตรทราบว่า flight และ time_hour เป็นตัวแปร บทบาทสามารถมีค่าอักขระใดก็ได้ สูตรประกอบด้วยตัวแปรทั้งหมดในชุดการฝึกเป็นตัวทํานาย ยกเว้นarr_delay สูตรเก็บตัวแปร ID สองตัวนี้ แต่ไม่ใช้เป็นผลลัพธ์หรือตัวคาดการณ์:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID")
หากต้องการดูตัวแปรและบทบาทชุดปัจจุบัน ให้ใช้ฟังก์ชัน summary():
summary(flights_rec)
สร้างคุณลักษณะ
วิศวกรรมคุณลักษณะสามารถปรับปรุงแบบจําลองของคุณได้ วันที่เที่ยวบินอาจมีผลกระทบอย่างสมเหตุสมผลต่อความเป็นไปได้ที่น่าจะถึงล่าช้า:
flight_data %>%
distinct(date) %>%
mutate(numeric_date = as.numeric(date))
ซึ่งอาจช่วยในการเพิ่มเงื่อนไขแบบจําลองซึ่งมาจากวันที่ที่มีความสําคัญต่อแบบจําลอง ได้รับคุณลักษณะที่มีความหมายดังต่อไปนี้จากตัวแปรวันที่เดียว:
- วันของสัปดาห์
- เดือน
- กําหนดว่าวันที่สอดคล้องกับวันหยุดหรือไม่
เพิ่มสามขั้นตอนลงในสูตรของคุณ:
flights_rec <-
recipe(arr_delay ~ ., data = train_data) %>%
update_role(flight, time_hour, new_role = "ID") %>%
step_date(date, features = c("dow", "month")) %>%
step_holiday(date,
holidays = timeDate::listHolidays("US"),
keep_original_cols = FALSE) %>%
step_dummy(all_nominal_predictors()) %>%
step_zv(all_predictors())
พอดีกับแบบจําลองด้วยสูตร
ใช้การถดถอยโลจิสติกส์เพื่อจําลองข้อมูลเที่ยวบิน ก่อนอื่น ให้สร้างข้อกําหนดแบบจําลองด้วยแพคเกจ parsnip:
lr_mod <-
logistic_reg() %>%
set_engine("glm")
ใช้แพคเกจ workflows เพื่อรวมแบบจําลอง parsnip ของคุณ (lr_mod) เข้ากับสูตรอาหารของคุณ (flights_rec):
flights_wflow <-
workflow() %>%
add_model(lr_mod) %>%
add_recipe(flights_rec)
flights_wflow
ฝึกแบบจําลอง
ฟังก์ชันนี้สามารถเตรียมสูตรและฝึกแบบจําลองจากตัวทํานายผลลัพธ์:
flights_fit <-
flights_wflow %>%
fit(data = train_data)
ใช้ฟังก์ชันตัวช่วยเหลือ xtract_fit_parsnip() และ extract_recipe() เพื่อแยกออบเจ็กต์แบบจําลองหรือสูตรจากเวิร์กโฟลว์ ในตัวอย่างนี้ ให้ดึงวัตถุแบบจําลองที่พอดี จากนั้นใช้broom::tidy()ฟังก์ชันเพื่อรับสัมประสิทธิ์แบบจําลองที่เป็นระเบียบ:
flights_fit %>%
extract_fit_parsnip() %>%
tidy()
ทํานายผลลัพธ์
การเรียกไปยัง predict() เดียวใช้เวิร์กโฟลว์ที่ได้รับการฝึกอบรม (flights_fit) เพื่อทําการคาดการณ์ด้วยข้อมูลทดสอบที่ยังไม่รับรู้ วิธีการ predict() นําสูตรไปใช้กับข้อมูลใหม่จากนั้นจะส่งผ่านผลลัพธ์ไปยังแบบจําลองที่พอดี
predict(flights_fit, test_data)
รับผลลัพธ์จาก predict() เพื่อส่งกลับคลาสที่คาดการณ์ไว้: late เทียบกับ on_time อย่างไรก็ตาม สําหรับความน่าจะเป็นของระดับชั้นที่คาดการณ์สําหรับแต่ละเที่ยวบิน ให้ใช้ augment() กับแบบจําลอง รวมกับข้อมูลทดสอบเพื่อบันทึกเข้าด้วยกัน:
flights_aug <-
augment(flights_fit, test_data)
ตรวจทานข้อมูล:
glimpse(flights_aug)
ประเมินแบบจําลอง
ตอนนี้เรามีระดับความน่าจะเป็นของคลาสที่คาดการณ์ไว้ ในสองถึงสามแถวแรก แบบจําลองที่ทํานายได้อย่างถูกต้องห้าเที่ยวบินตรงเวลา (ค่าของ .pred_on_timep > 0.50) อย่างไรก็ตาม เราจําเป็นต้องมีการคาดการณ์ทั้งหมด 81,455 แถว
เราต้องการเมตริกที่บอกว่าแบบจําลองคาดการณ์การมาถึงสายได้ดีเพียงใดเมื่อเทียบกับสถานะที่แท้จริงของ arr_delay ตัวแปรผลลัพธ์
ใช้พื้นที่ภายใต้ลักษณะการใช้งานของตัวรับเส้นโค้ง (AUC-ROC) เป็นเมตริก คํานวณด้วย roc_curve() และ roc_auc()จากแพคเกจ yardstick:
flights_aug %>%
roc_curve(truth = arr_delay, .pred_late) %>%
autoplot()
สร้างรายงาน Power BI
ผลลัพธ์แบบจําลองดูดี ใช้ผลลัพธ์การคาดการณ์การหน่วงเวลาของเที่ยวบินเพื่อสร้างแดชบอร์ด Power BI แบบโต้ตอบ แดชบอร์ดแสดงจํานวนเที่ยวบินตามผู้ให้บริการ และจํานวนเที่ยวบินตามปลายทาง แดชบอร์ดสามารถกรองตามผลลัพธ์การคาดการณ์การหน่วงเวลา

ใส่ชื่อผู้ให้บริการและชื่อสนามบินในชุดข้อมูลผลลัพธ์การคาดการณ์:
flights_clean <- flights_aug %>%
# Include the airline data
left_join(airlines, c("carrier"="carrier"))%>%
rename("carrier_name"="name") %>%
# Include the airport data for origin
left_join(airports, c("origin"="faa")) %>%
rename("origin_name"="name") %>%
# Include the airport data for destination
left_join(airports, c("dest"="faa")) %>%
rename("dest_name"="name") %>%
# Retain only the specific columns you'll use
select(flight, origin, origin_name, dest,dest_name, air_time,distance, carrier, carrier_name, date, arr_delay, time_hour, .pred_class, .pred_late, .pred_on_time)
ตรวจทานข้อมูล:
glimpse(flights_clean)
แปลงข้อมูลเป็น Spark DataFrame:
sparkdf <- as.DataFrame(flights_clean)
display(sparkdf)
เขียนข้อมูลลงในตารางเดลต้าในเลคเฮ้าส์ของคุณ:
# Write data into a delta table
temp_delta<-"Tables/nycflight13"
write.df(sparkdf, temp_delta ,source="delta", mode = "overwrite", header = "true")
ใช้ตารางส่วนที่แตกต่างเพื่อสร้างแบบจําลองความหมาย
ในการนําทางด้านซ้าย ให้เลือกพื้นที่ทํางานของคุณ และในกล่องข้อความขวาบน ให้ใส่ชื่อของเลคเฮ้าส์ที่คุณแนบมากับสมุดบันทึกของคุณ สกรีนช็อตต่อไปนี้แสดงให้เห็นว่าเราเลือก พื้นที่ทํางานของฉัน:
ใส่ชื่อของเลคเฮ้าส์ที่คุณแนบมากับสมุดบันทึกของคุณ เราป้อน test_lakehouse1 ดังที่แสดงในภาพหน้าจอต่อไปนี้:
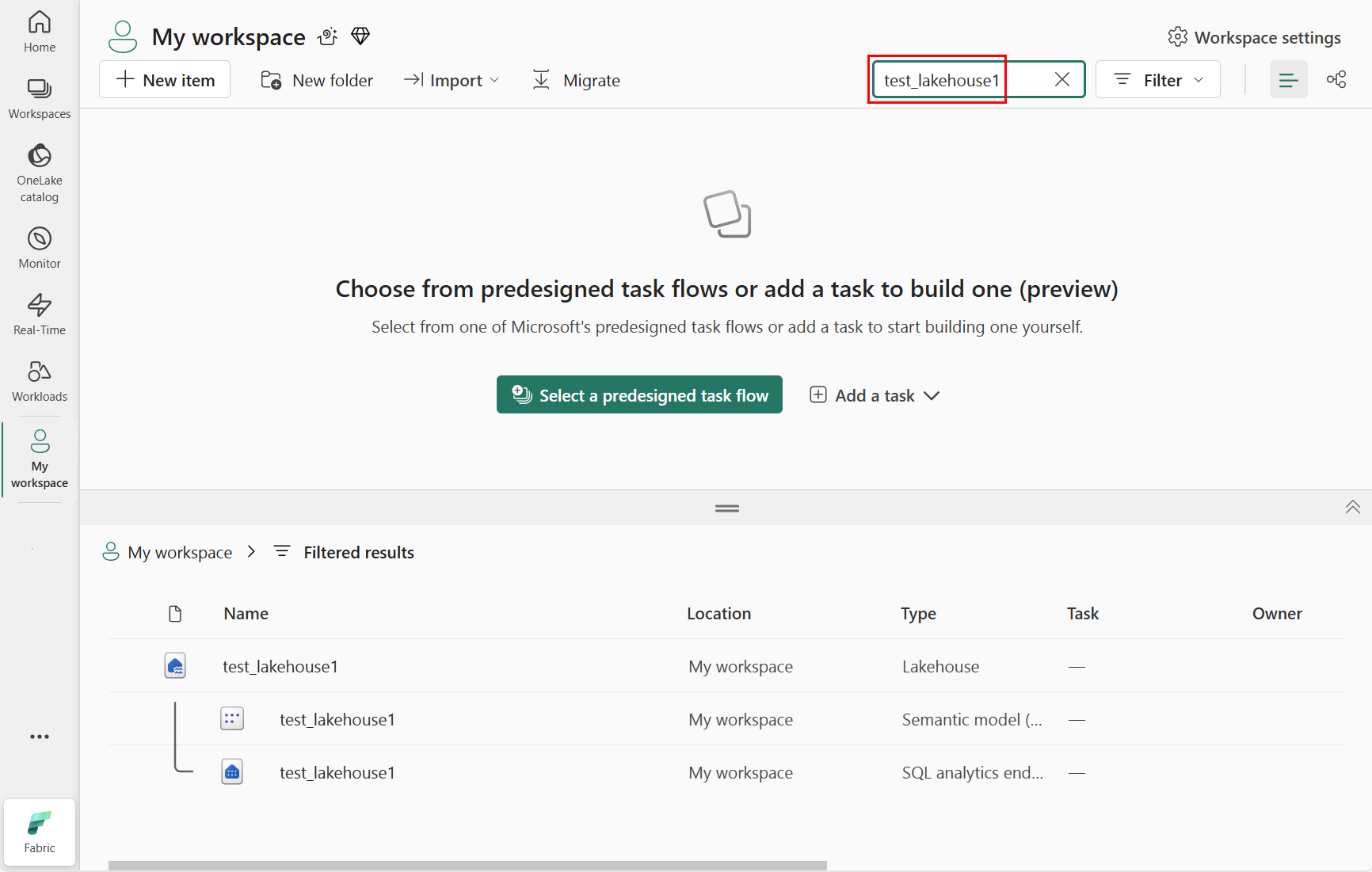
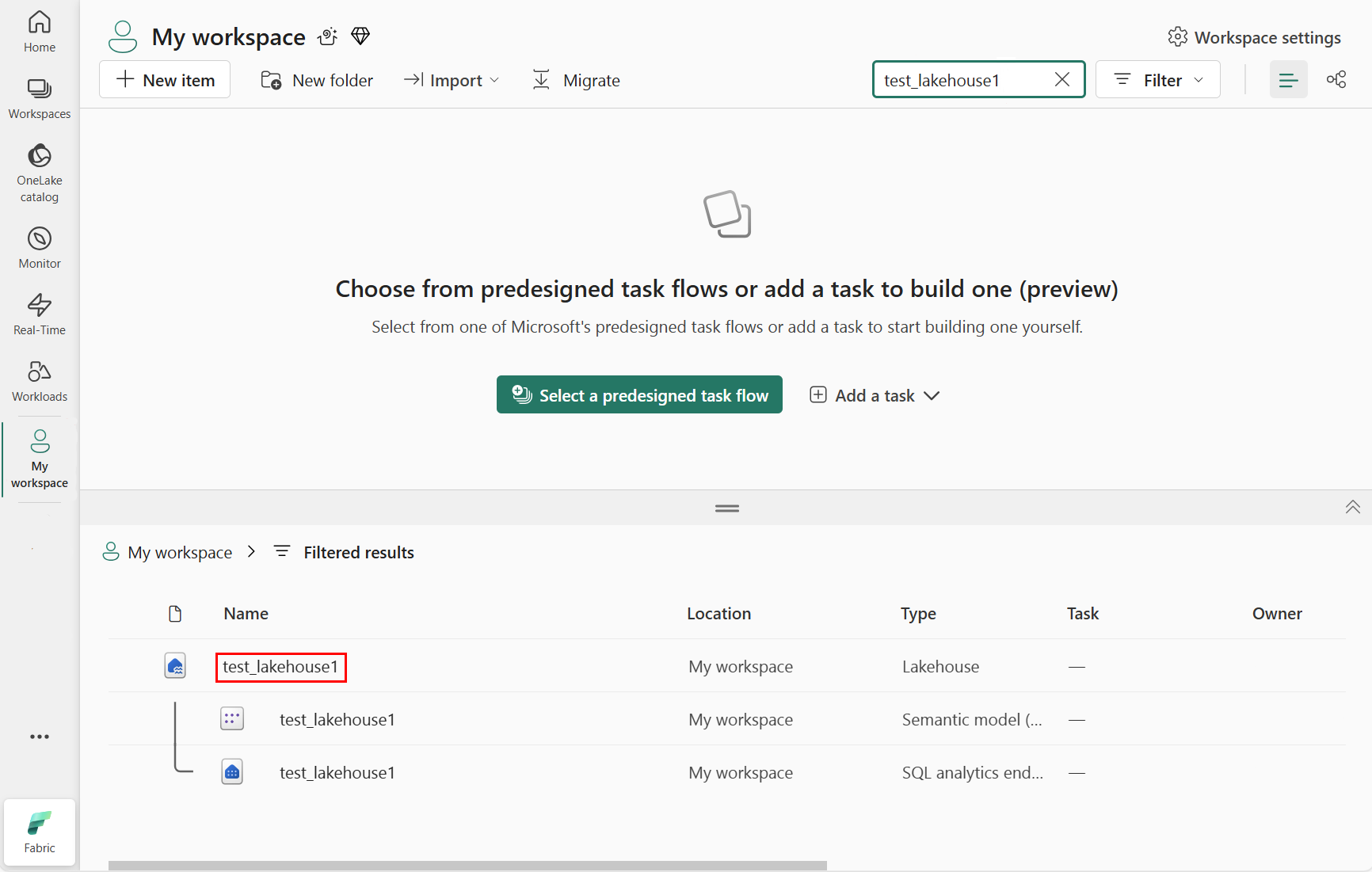
ในพื้นที่ผลลัพธ์ที่กรองแล้ว เลือก lakehouse ดังที่แสดงในภาพหน้าจอต่อไปนี้:
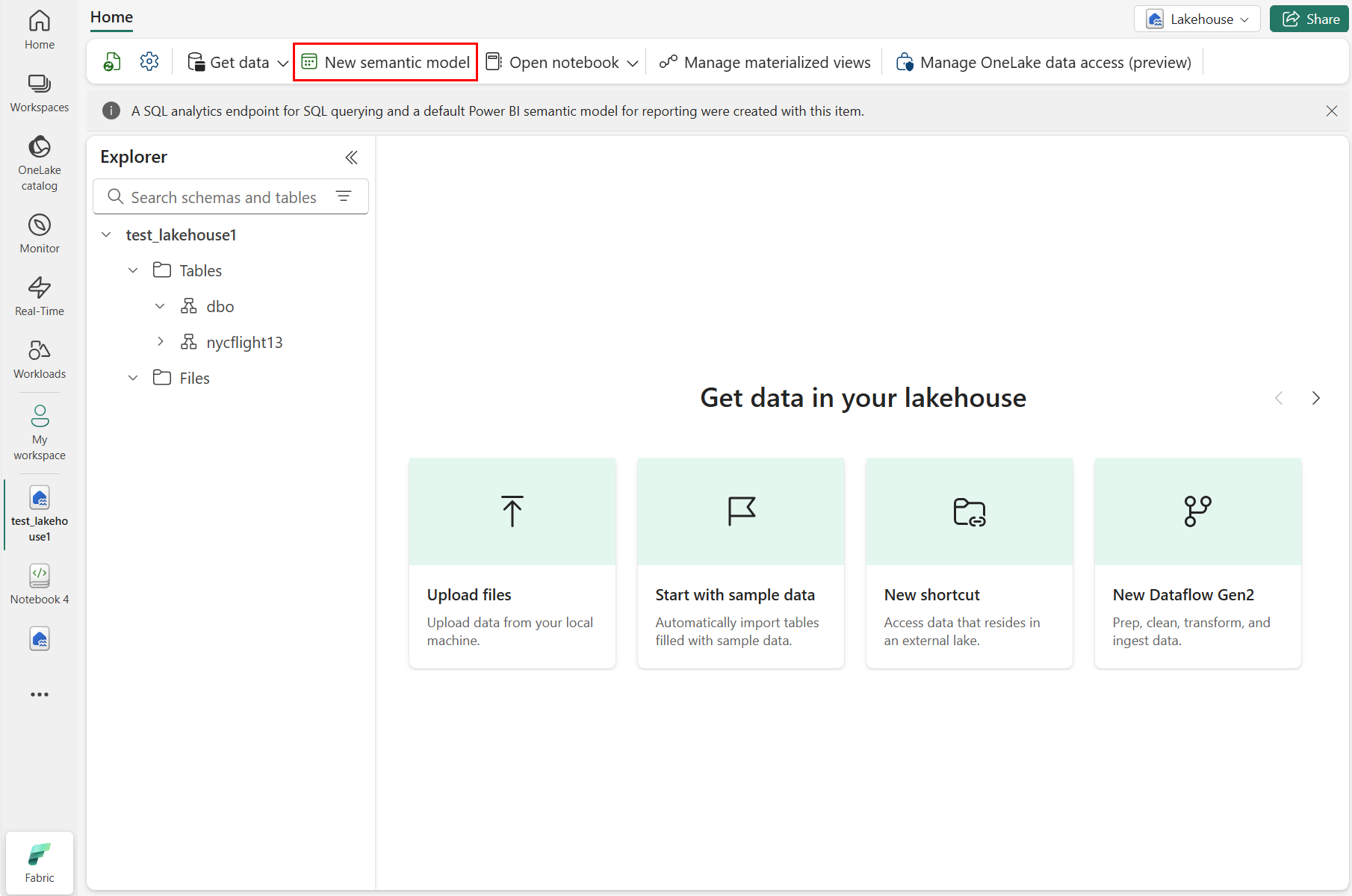
เลือก แบบจําลองความหมายใหม่ ดังที่แสดงในภาพหน้าจอต่อไปนี้:
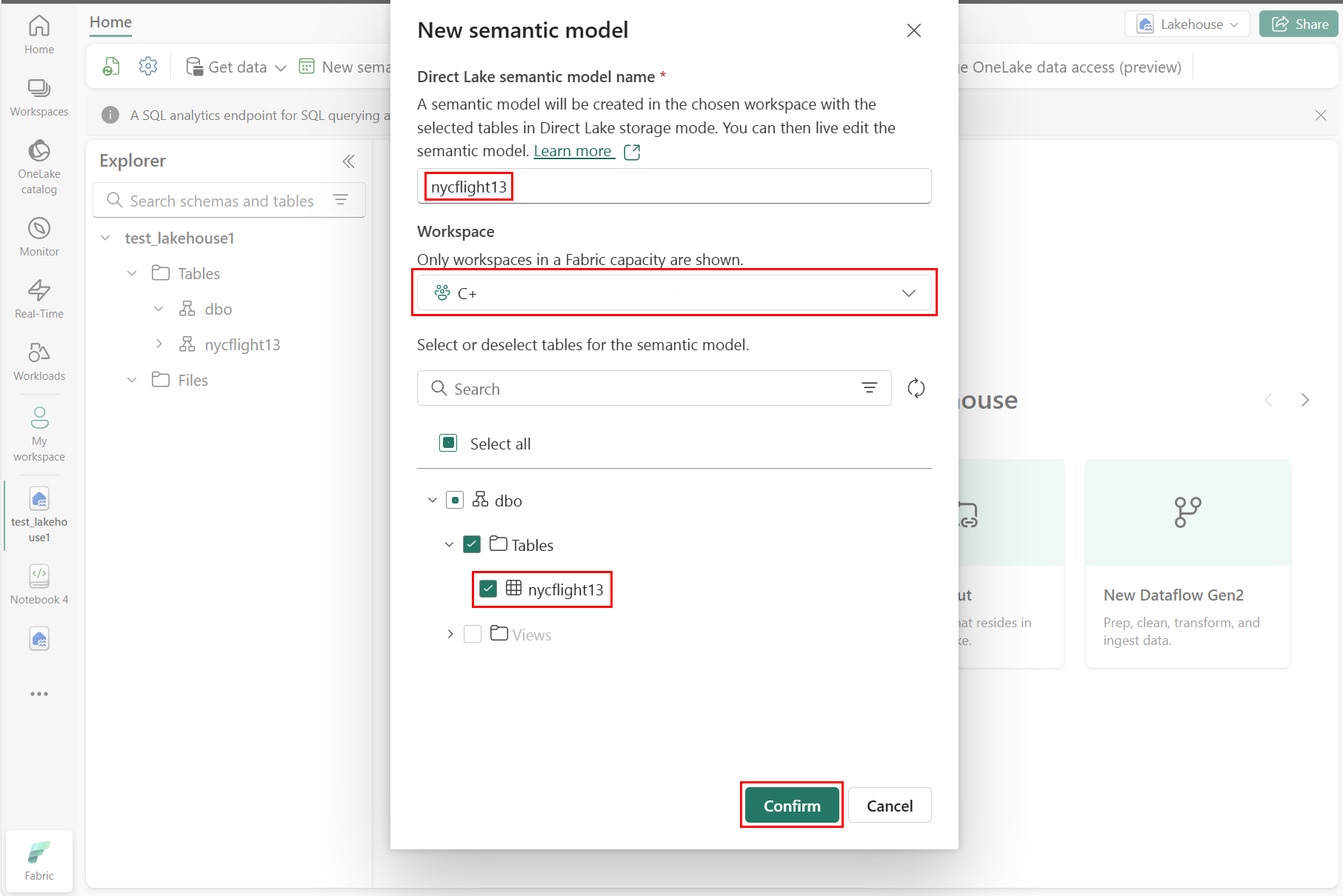
ที่บานหน้าต่าง แบบจําลองความหมายใหม่ ให้ป้อนชื่อสําหรับแบบจําลองความหมายใหม่ เลือกพื้นที่ทํางานและเลือกตารางที่จะใช้สําหรับแบบจําลองใหม่นั้น จากนั้นเลือก ยืนยัน ดังที่แสดงในภาพหน้าจอต่อไปนี้:
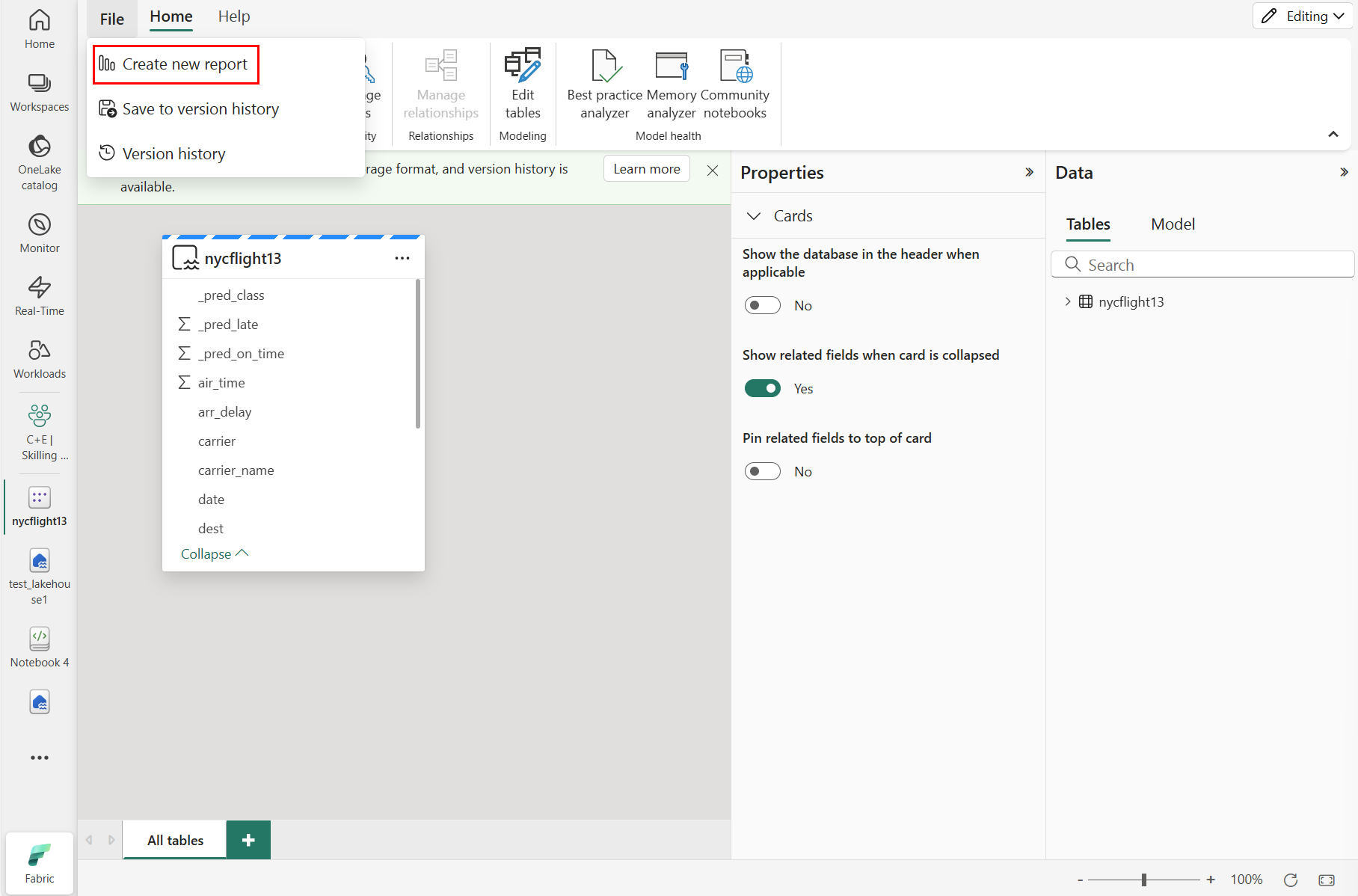
หากต้องการสร้างรายงานใหม่ ให้เลือก สร้างรายงานใหม่ ดังที่แสดงในภาพหน้าจอต่อไปนี้:
เลือกหรือลากเขตข้อมูลจาก ข้อมูล และการแสดงภาพ บานหน้าต่างลงในพื้นที่รายงานเพื่อสร้างรายงานของคุณ






หากต้องการสร้างรายงานที่แสดงในตอนต้นของส่วนนี้ ให้ใช้การแสดงภาพและข้อมูลเหล่านี้:
-
 แผนภูมิแท่งแบบเรียงซ้อนที่มี:
แผนภูมิแท่งแบบเรียงซ้อนที่มี: - แกน Y: carrier_name
- แกน X: เที่ยวบิน เลือก จํานวนสําหรับการรวม
- คําอธิบายแผนภูมิ: origin_name
-
แผนภูมิแท่งแบบเรียงซ้อนที่มี:
- แกน Y: dest_name
- แกน X: เที่ยวบิน เลือก จํานวนสําหรับการรวม
- คําอธิบายแผนภูมิ: origin_name
- ตัวแบ่งส่วนข้อมูล
 ด้วย:
ด้วย: - เขตข้อมูล: _pred_class
- ตัวแบ่งส่วนข้อมูล ด้วย:
- เขตข้อมูล: _pred_late
เนื้อหาที่เกี่ยวข้อง
- วิธีใช้ SparkR
- วิธีใช้ ประกาย
- วิธีใช้ Tidyverse
- การจัดการไลบรารี R
- แสดงข้อมูลด้วยภาพใน R
- บทช่วยสอน : ใช้ R เพื่อทํานายราคาอะโวคาโด