หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
Tidyverse คือคอลเลกชันของแพคเกจ R ที่นักวิทยาศาสตร์ข้อมูลมักใช้ในการวิเคราะห์ข้อมูลประจําวัน ซึ่งรวมถึงแพคเกจสําหรับการนําเข้าข้อมูล (readr), การแสดงภาพข้อมูล (ggplot2), การจัดการข้อมูล (dplyr, tidyr), การเขียนโปรแกรมการทํางาน (purrr), และการสร้างแบบจําลอง (tidymodels) ฯลฯ แพ็คเกจใน tidyverse ได้รับการออกแบบให้ทํางานร่วมกันได้อย่างราบรื่นและปฏิบัติตามชุดหลักการการออกแบบที่สอดคล้องกัน
Microsoft Fabric จะกระจายเวอร์ชันล่าสุดที่เสถียรของ tidyverse กับทุกรุ่นที่มีการเผยแพร่รันไทม์ นําเข้าและเริ่มใช้แพคเกจ R ที่คุณคุ้นเคย
ข้อกำหนดเบื้องต้น
รับการสมัครใช้งาน Microsoft Fabric หรือลงทะเบียนเพื่อทดลองใช้งาน Microsoft Fabric ฟรี
ลงชื่อเข้าใช้ Microsoft Fabric
ใช้ตัวสลับประสบการณ์การใช้งานที่ด้านล่างซ้ายของหน้าหลักของคุณเพื่อเปลี่ยนเป็น Fabric
เปิดหรือสร้างสมุดบันทึก หากต้องการเรียนรู้วิธีการ ดู วิธีใช้สมุดบันทึก Microsoft Fabric
ตั้งค่าตัวเลือกภาษาเป็น SparkR (R) เพื่อเปลี่ยนภาษาหลัก
แนบสมุดบันทึกของคุณเข้ากับเลคเฮ้าส์ ทางด้านซ้าย เลือก เพิ่ม เพื่อเพิ่มเลคเฮาส์ที่มีอยู่ หรือเพื่อสร้างเลคเฮ้าส์
ภาระ tidyverse
# load tidyverse
library(tidyverse)
การนําเข้าข้อมูล
readr เป็นแพคเกจ R ที่มีเครื่องมือสําหรับการอ่านไฟล์ข้อมูลสี่เหลี่ยมผืนผ้า เช่น CSV, TSV และไฟล์ความกว้างคงที่
readr ให้วิธีการที่ง่ายและรวดเร็วในการอ่านไฟล์ข้อมูลสี่เหลี่ยมเช่นฟังก์ชั่นให้ฟังก์ชั่น read_csv() และ read_tsv() สําหรับการอ่านไฟล์ CSV และ TSV ตามลําดับ
ก่อนอื่น มาสร้าง R data.frame เขียนไปยัง lakehouse โดยใช้ readr::write_csv() และอ่านอีกครั้งด้วยreadr::read_csv()
หมายเหตุ
หากต้องการเข้าถึงไฟล์ Lakehouse โดยใช้ readrคุณต้องใช้เส้นทาง API ของไฟล์ ใน Lakehouse explorer คลิกขวาที่ไฟล์หรือโฟลเดอร์ที่คุณต้องการเข้าถึงและคัดลอกเส้นทาง API ของไฟล์จากเมนูตามบริบท
# create an R data frame
set.seed(1)
stocks <- data.frame(
time = as.Date('2009-01-01') + 0:9,
X = rnorm(10, 20, 1),
Y = rnorm(10, 20, 2),
Z = rnorm(10, 20, 4)
)
stocks
จากนั้นเรามาเขียนข้อมูลไปยัง lakehouse โดยใช้ เส้นทาง API ของไฟล์
# write data to lakehouse using the File API path
temp_csv_api <- "/lakehouse/default/Files/stocks.csv"
readr::write_csv(stocks,temp_csv_api)
อ่านข้อมูลจากเลคเฮ้าส์
# read data from lakehouse using the File API path
stocks_readr <- readr::read_csv(temp_csv_api)
# show the content of the R date.frame
head(stocks_readr)
การทําให้ข้อมูลเป็นระเบียบ
tidyr เป็นแพคเกจ R ที่มีเครื่องมือสําหรับการทํางานกับข้อมูลที่ไม่ยุ่งเหงา ฟังก์ชันหลักใน tidyr ได้รับการออกแบบมาเพื่อช่วยให้คุณสามารถปรับรูปร่างข้อมูลให้อยู่ในรูปแบบที่เป็นระเบียบ ข้อมูลเรียบร้อยมีโครงสร้างเฉพาะที่แต่ละตัวแปรเป็นคอลัมน์และแต่ละการสังเกตคือแถวซึ่งทําให้ง่ายต่อการทํางานกับข้อมูลใน R และเครื่องมืออื่น ๆ
ตัวอย่างเช่น gather() ฟังก์ชัน ใน tidyr สามารถใช้ใน ในการแปลงข้อมูลกว้างเป็นข้อมูลแบบยาว ตัวอย่างมีดังนี้:
# convert the stock data into longer data
library(tidyr)
stocksL <- gather(data = stocks, key = stock, value = price, X, Y, Z)
stocksL
การเขียนโปรแกรมการทํางาน
purrr เป็นแพคเกจ R ที่ปรับปรุงชุดเครื่องมือการเขียนโปรแกรมที่ใช้งานได้ของ R โดยจัดหาชุดเครื่องมือที่สมบูรณ์และสอดคล้องกันสําหรับการทํางานกับฟังก์ชันและเวกเตอร์ จุดเริ่มต้นที่ดีที่สุด purrr คือกลุ่มของ map() ฟังก์ชันที่ช่วยให้คุณสามารถแทนที่จํานวนมากสําหรับลูปด้วยโค้ดที่รองรับและอ่านได้ง่ายขึ้น นี่คือตัวอย่างของการใช้ map() เพื่อนําฟังก์ชันไปใช้กับแต่ละองค์ประกอบของรายการ:
# double the stock values using purrr
library(purrr)
stocks_double = map(stocks %>% select_if(is.numeric), ~.x*2)
stocks_double
การจัดการข้อมูล
dplyr เป็นแพคเกจ R ที่มีชุดคํากริยาที่สอดคล้องกันซึ่งช่วยให้คุณแก้ปัญหาการจัดการข้อมูลที่พบบ่อยที่สุด เช่น การเลือกตัวแปรตามชื่อ กรณีการเบิกสินค้าตามค่า ลดค่าหลายค่าลงเป็นข้อมูลสรุปเดียว และเปลี่ยนลําดับของแถวเป็นต้น ต่อไปนี้คือตัวอย่างบางส่วน:
# pick variables based on their names using select()
stocks_value <- stocks %>% select(X:Z)
stocks_value
# pick cases based on their values using filter()
filter(stocks_value, X >20)
# add new variables that are functions of existing variables using mutate()
library(lubridate)
stocks_wday <- stocks %>%
select(time:Z) %>%
mutate(
weekday = wday(time)
)
stocks_wday
# change the ordering of the rows using arrange()
arrange(stocks_wday, weekday)
# reduce multiple values down to a single summary using summarise()
stocks_wday %>%
group_by(weekday) %>%
summarize(meanX = mean(X), n= n())
การนำเสนอภาพจากข้อมูล
ggplot2 เป็นแพคเกจ R สําหรับการสร้างกราฟิกอย่างประกาศโดยยึดตามไวยากรณ์ของกราฟิก คุณให้ข้อมูล บอก ggplot2 วิธีการแมปตัวแปรเพื่อความสวยงาม สิ่งพื้นฐานกราฟิกที่จะใช้ และจะดูแลรายละเอียด ยกตัวอย่างเช่น
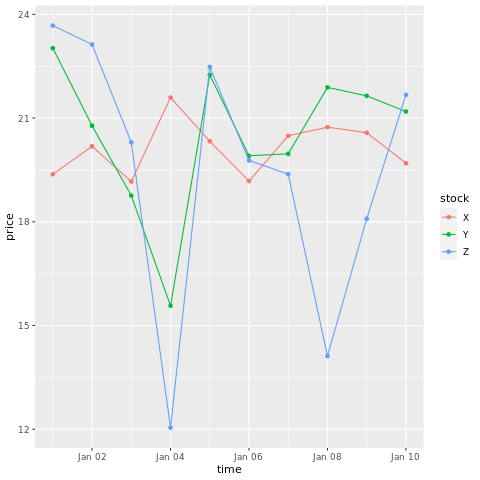
# draw a chart with points and lines all in one
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_point()+
geom_line()
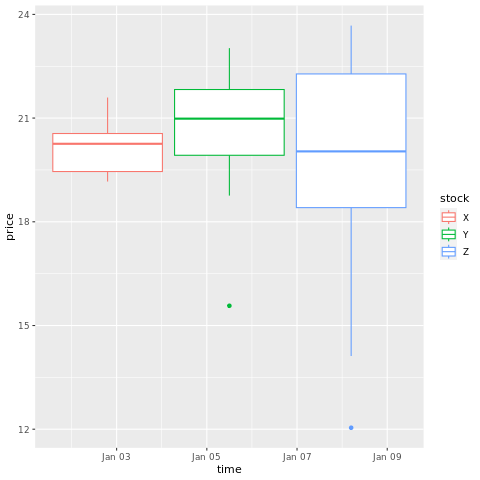
# draw a boxplot
ggplot(stocksL, aes(x=time, y=price, colour = stock)) +
geom_boxplot()
การสร้างแบบจําลอง
เฟรม tidymodels เวิร์กคือคอลเลกชันของแพคเกจสําหรับการสร้างแบบจําลองและการเรียนรู้ของเครื่องโดยใช้ tidyverse หลักการ ครอบคลุมรายการของแพคเกจหลักสําหรับงานการสร้างแบบจําลองที่หลากหลาย เช่น rsample สําหรับการ parsniprecipesแยกตัวอย่างชุดข้อมูลแบบฝึกหัด/ทดสอบ สําหรับข้อมูลจําเพาะworkflowsแบบจําลอง สําหรับการประมวลผลtuneล่วงหน้าข้อมูลสําหรับเวิร์กโฟลว์yardstickการสร้างแบบจําลองสําหรับการปรับแต่ง hyperparameters สําหรับการประเมินแบบจําลองbroomสําหรับคําแนะนําเอาต์พุตแบบจําลอง และdialsสําหรับการจัดการพารามิเตอร์การปรับแต่ง คุณสามารถเรียนรู้เพิ่มเติมเกี่ยวกับแพคเกจโดยไปที่ เว็บไซต์ tidymodels นี่คือตัวอย่างของการสร้างแบบจําลองการถดถอยเชิงเส้นเพื่อคาดการณ์ไมล์ต่อแกลลอน (mpg) ของรถยนต์ตามน้ําหนัก (wt):
# look at the relationship between the miles per gallon (mpg) of a car and its weight (wt)
ggplot(mtcars, aes(wt,mpg))+
geom_point()
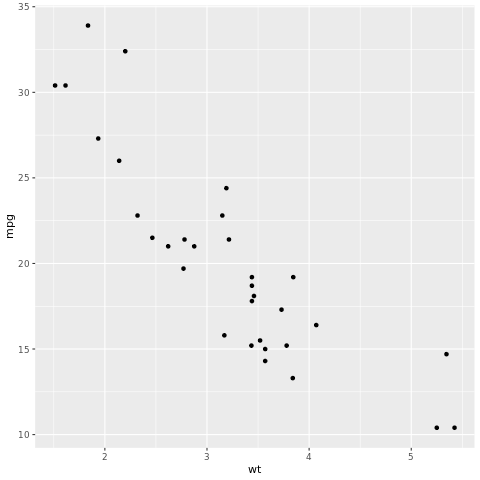
จากแผนภูมิกระจาย ความสัมพันธ์มีลักษณะเป็นเชิงเส้นโดยประมาณและความแปรปรวนดูคงที่ ลองจําลองสิ่งนี้โดยใช้การถดถอยเชิงเส้น
library(tidymodels)
# split test and training dataset
set.seed(123)
split <- initial_split(mtcars, prop = 0.7, strata = "cyl")
train <- training(split)
test <- testing(split)
# config the linear regression model
lm_spec <- linear_reg() %>%
set_engine("lm") %>%
set_mode("regression")
# build the model
lm_fit <- lm_spec %>%
fit(mpg ~ wt, data = train)
tidy(lm_fit)
ใช้แบบจําลองการถดถอยเชิงเส้นเพื่อคาดการณ์บนชุดข้อมูลทดสอบ
# using the lm model to predict on test dataset
predictions <- predict(lm_fit, test)
predictions
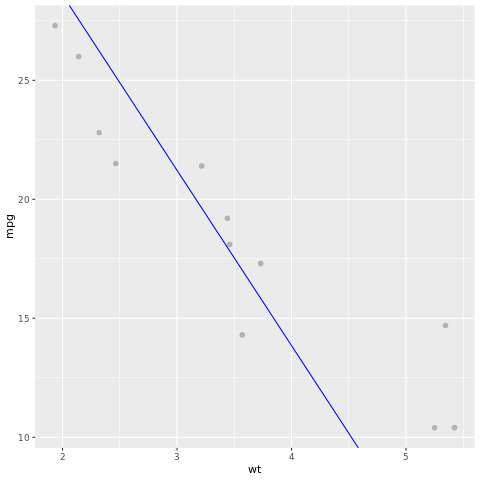
ลองมาดูผลลัพธ์แบบจําลอง เราสามารถวาดแบบจําลองเป็นแผนภูมิเส้นและทดสอบข้อมูลจริงภาคพื้นดินเป็นจุดบนแผนภูมิเดียวกันได้ แบบจําลองดูดี
# draw the model as a line chart and the test data groundtruth as points
lm_aug <- augment(lm_fit, test)
ggplot(lm_aug, aes(x = wt, y = mpg)) +
geom_point(size=2,color="grey70") +
geom_abline(intercept = lm_fit$fit$coefficients[1], slope = lm_fit$fit$coefficients[2], color = "blue")