หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
Microsoft Fabric มีหลายวิธีในการนําข้อมูลเข้าสู่สภาพแวดล้อมการวิเคราะห์ของคุณ ไม่ว่าคุณจะต้องการประมวลผลเหตุการณ์การสตรีมแบบเรียลไทม์ จําลองฐานข้อมูลการดําเนินงาน ประสานไปป์ไลน์แบตช์ หรือเข้าถึงข้อมูลโดยไม่ต้องคัดลอก Fabric มีความสามารถในตัวเพื่อรองรับแต่ละสถานการณ์ Fabric ยังรองรับรูปแบบการแบ่งปันข้อมูลที่มีการควบคุมผ่าน OneLake ทําให้สามารถเข้าถึงชุดข้อมูลสดแบบข้ามผู้เช่าและข้ามพื้นที่ทํางานได้โดยไม่ซ้ําซ้อน
บทความนี้อธิบายถึงตัวเลือกการนําเข้าข้อมูลหลักและการเคลื่อนย้ายข้อมูลใน Fabric ครอบคลุมถึง:
- การนําเข้าแบบเรียลไทม์ ด้วย Eventstreams และ Eventhouse
- การประสานชุดงาน ด้วยไปป์ไลน์ Data Factory และงานคัดลอก
- การจําลองแบบแบบเกือบเรียลไทม์ด้วย Mirroring
- การจําลองเสมือนข้อมูลด้วยทางลัด OneLake
ใช้ภาพรวมนี้เพื่อทําความเข้าใจวิธีการทํางานของแต่ละวิธี และเลือกกลยุทธ์ที่เหมาะกับความต้องการปริมาณงานของคุณมากที่สุดสําหรับเวลาแฝง
การนำเข้าข้อมูลแบบเรียลไทม์
รายการ Eventstream และ Eventhouse ในปริมาณงาน Real-Time Intelligence รองรับสถานการณ์การสตรีมข้อมูล Eventstreams นําเข้าและประมวลผลเหตุการณ์แบบเรียลไทม์ และ Eventhouse จะจัดเก็บและสืบค้นเหตุการณ์เหล่านั้นในวงกว้าง โดยทั่วไป คุณจะใช้ Eventstream เพื่อบันทึกและกําหนดเส้นทางข้อมูลไปยัง Eventhouse คุณยังสามารถใช้ความสามารถแต่ละอย่างได้อย่างอิสระตามความต้องการของคุณ ไดอะแกรมต่อไปนี้แสดงวิธีที่ชุดข้อมูลแบบเรียลไทม์ไหลไปยัง Eventstream และ Eventhouse ใน Fabric:
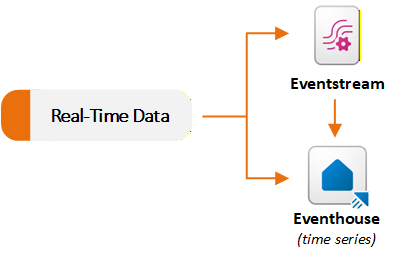
นําเข้าและกําหนดเส้นทางเหตุการณ์ด้วย Eventstream
Eventstream มอบประสบการณ์แบบไม่ใช้โค้ดเพื่อนําเข้าเหตุการณ์ลงใน Fabric ใช้การแปลงในสตรีม และกําหนดเส้นทางข้อมูลไปยังปลายทางหลายแห่ง Eventstream ทําหน้าที่เป็นไปป์ไลน์การนําเข้าแบบเรียลไทม์ คุณสร้าง Eventstream และเพิ่มตัวเชื่อมต่อแหล่งที่มาอย่างน้อยหนึ่งตัว Fabric รองรับแหล่งที่มาของการสตรีมจํานวนมาก รวมถึงเหตุการณ์ Fabric ภายใน เช่น เหตุการณ์พื้นที่ทํางาน Fabricเหตุการณ์ไฟล์ OneLake และเหตุการณ์งานไปป์ไลน์
หลังจากเหตุการณ์เริ่มไหล คุณสามารถใช้การแปลงแบบเรียลไทม์ที่เป็นตัวเลือกผ่านตัวแก้ไขแบบลากและวาง ตัวอย่างเช่น คุณสามารถกรองเหตุการณ์ คํานวณการรวมกรอบเวลา รวมหลายสตรีม หรือปรับรูปร่างฟิลด์โดยไม่ต้องเขียนโค้ด
คุณสามารถส่งสตรีมที่ประมวลผลไปยังปลายทางที่รองรับอย่างน้อยหนึ่งปลายทาง Eventstreams สามารถแสดงตําแหน่งข้อมูล Apache Kafka ผ่านแหล่งที่มาและปลายทางปลายทางที่กําหนดเองได้ ความสามารถนี้ช่วยให้ผู้ผลิต Kafka สามารถสตรีมเหตุการณ์ไปยัง Fabric และผู้บริโภค Kafka เพื่อใช้เหตุการณ์จาก Fabric
สตรีมเหตุการณ์ไม่ได้จัดเก็บข้อมูลอย่างถาวร พวกเขาสตรีมเหตุการณ์ผ่านหน่วยความจําและส่งต่อไปยังปลายทางที่กําหนดค่าไว้ การออกแบบนี้ทําให้ Eventstreams เหมาะสําหรับสถานการณ์การแยก แปลง โหลด (ETL) แบบเรียลไทม์ และสําหรับการกระจายข้อมูลการสตรีมไปยังหลายเป้าหมาย ตัวอย่างเช่น คุณสามารถนําเข้าการวัดและส่งข้อมูลทางไกลจากเซ็นเซอร์ Internet of Things (IoT) กรองและรวมข้อมูลแบบเรียลไทม์ ส่งสตรีมที่ปรับแต่งแล้วไปยัง Eventhouse เพื่อการวิเคราะห์ และกําหนดเส้นทางเหตุการณ์ที่ผิดปกติไปยัง Activator เพื่อแจ้งเตือน
นําเข้าข้อมูลไปยัง Eventhouse โดยตรง
Eventhouse สามารถนําเข้าข้อมูลได้โดยตรงจากหลายแหล่ง Fabric มีประสบการณ์ การรับข้อมูล แบบบูรณาการภายใน Eventhouse วิซาร์ดเชื่อมต่อกับแหล่งที่มา เช่น ไฟล์ในเครื่อง, Azure Storage, Amazon S3, Azure Event Hubs และ OneLake คุณสามารถโหลดข้อมูลลงในตารางฐานข้อมูล Kusto Query Language (KQL) แบบเรียลไทม์หรือโหมดแบทช์ได้โดยใช้อินเทอร์เฟซผู้ใช้ Eventhouse
คุณยังสามารถเลือก Eventstream ที่มีอยู่ใน Fabric เป็นแหล่งที่มาได้อีกด้วย ตัวอย่างเช่น หากคุณใช้ Eventstream ที่นําเข้าข้อมูลจาก IoT Hub หรือ Kafka คุณสามารถกําหนดเส้นทางเอาต์พุตไปยังตารางฐานข้อมูล KQL ได้โดยตรงโดยไม่ต้องกําหนดค่าเพิ่มเติม
การนําเข้าข้อมูลชุดงาน
Data Factory มอบประสบการณ์หลักสําหรับไปป์ไลน์การแยก แปลง โหลด (ETL) และแยก โหลด แปลง (ELT) แบบดั้งเดิม ประกอบด้วยไลบรารีตัวเชื่อมต่อขนาดใหญ่ Fabric Data Factory มี รายการตัวเชื่อมต่อแบบเนทีฟ สําหรับที่เก็บข้อมูลในองค์กรและระบบคลาวด์ รวมถึงฐานข้อมูล แอปพลิเคชันซอฟต์แวร์เป็นบริการ (SaaS) และระบบที่ใช้ไฟล์ ตัวเชื่อมต่อเหล่านี้ช่วยให้คุณเชื่อมต่อกับระบบต้นทางเกือบทุกระบบ
ประสานการเคลื่อนย้ายข้อมูลด้วยไปป์ไลน์
คุณสามารถสร้าง ไปป์ไลน์ ที่ใช้ตัวเชื่อมต่อเหล่านี้เพื่อคัดลอกหรือย้ายข้อมูลไปยัง OneLake หรือที่เก็บการวิเคราะห์ แนวทางนี้สนับสนุน:
- ชุดข้อมูลที่ไม่มีโครงสร้าง เช่น รูปภาพ วิดีโอ และเสียง
- ชุดข้อมูลกึ่งโครงสร้าง เช่น JSON, CSV และ XML
- ชุดข้อมูลที่มีโครงสร้างจากระบบฐานข้อมูลเชิงสัมพันธ์ที่รองรับ
ในไปป์ไลน์ คุณรวมส่วนประกอบการประสานรวมหลายรายการ รวมถึง:
- กิจกรรมการเคลื่อนย้ายข้อมูล เช่น คัดลอกข้อมูล และ คัดลอกงาน
- กิจกรรมการแปลงข้อมูล เช่น Dataflow Gen2, ลบข้อมูล, สมุดบันทึก Fabric และสคริปต์ SQL
- ควบคุมกิจกรรมโฟลว์ เช่น ForEach, Lookup, Set Variable และ Webhook
คุณสามารถเรียกใช้ไปป์ไลน์ได้ตามความต้องการ ตามกําหนดเวลา หรือเพื่อตอบสนองต่อเหตุการณ์ ตัวอย่างเช่น คุณสามารถกําหนดเวลาไปป์ไลน์ให้ทํางานทุกสองชั่วโมงในวันธรรมดา หรือทริกเกอร์เมื่อมีการสร้างไฟล์ใหม่ใน OneLake
ลดความซับซ้อนในการเคลื่อนย้ายข้อมูลด้วยงานคัดลอก
งานคัดลอก รองรับรูปแบบการส่งข้อมูลหลายรูปแบบ รวมถึงการคัดลอกจํานวนมาก สําเนาส่วนเพิ่ม และการจําลองแบบการบันทึกข้อมูลการเปลี่ยนแปลง (CDC) คุณสามารถใช้ คัดลอกงาน เพื่อย้ายข้อมูลจากแหล่งข้อมูลไปยัง OneLake โดยไม่ต้องสร้างไปป์ไลน์ ในขณะที่ยังคงเข้าถึงตัวเลือกการกําหนดค่าขั้นสูง งานคัดลอกรองรับแหล่งที่มาและปลายทางมากมาย มีการควบคุมมากกว่าการมิเรอร์และความซับซ้อนในการดําเนินงานน้อยกว่าการจัดการไปป์ไลน์ที่ใช้กิจกรรมการคัดลอก
ทําซ้ําข้อมูลด้วยการมิเรอร์
การมิเรอร์ จะจําลองข้อมูลจากระบบภายนอกไปยัง Fabric แบบเกือบเรียลไทม์ด้วยการตั้งค่าอัตโนมัติ คุณเชื่อมต่อกับระบบภายนอก เช่น ฐานข้อมูล Azure SQL, SQL Server, Oracle, SAP หรือ Snowflake Fabric ทําซ้ําข้อมูลหรือข้อมูลเมตาไปยัง OneLake อย่างต่อเนื่อง การมิเรอร์รองรับสามประเภท:
- การมิเรอร์ฐานข้อมูล จะจําลองฐานข้อมูลและตารางทั้งหมด
- การสะท้อนข้อมูลเมตา จะซิงโครไนซ์ข้อมูลเมตา เช่น ชื่อแค็ตตาล็อก สคีมา และตารางแทนการย้ายข้อมูลทางกายภาพ วิธีการนี้ใช้ทางลัดเพื่อให้ข้อมูลยังคงอยู่ในระบบต้นทางในขณะที่ยังคงสามารถเข้าถึงได้ใน Fabric
- การสะท้อนแบบเปิด ใช้รูปแบบตาราง Delta Lake แบบเปิด นักพัฒนาสามารถเขียนการเปลี่ยนแปลงแอปพลิเคชันไปยังรายการฐานข้อมูลที่มิเรอร์ใน OneLake ได้โดยตรงโดยใช้ API สาธารณะ
Fabric รับฟังการเปลี่ยนแปลงของระบบต้นทาง (ผ่านการบันทึกข้อมูลการเปลี่ยนแปลงหรือวิธีการที่คล้ายกัน) และใช้การเปลี่ยนแปลงเหล่านั้นในแบบเรียลไทม์กับสําเนามิเรอร์ ผลลัพธ์ที่ได้คือชุดข้อมูลแบบสดที่สืบค้นได้ซึ่งซิงค์กันด้วยเวลาแฝงต่ําโดยไม่ต้องใช้ไปป์ไลน์ ETL ที่ซับซ้อน
ปัจจุบันการมิเรอร์ รองรับแหล่งที่มาต่างๆ รวมถึง Azure SQL Database, SQL Managed Instance, Azure Cosmos DB, Azure Database for PostgreSQL, Google BigQuery, Oracle, SAP, Snowflake และ SQL Server นอกจากนี้ยังรองรับแหล่งข้อมูลจากโซลูชันของพันธมิตรที่นํา Open Mirroring API มาใช้ ข้อมูลที่มิเรอร์จะถูกเก็บไว้ใน OneLake เป็นตารางเดลต้า up-toวันที่ Fabric จะรักษาตารางเหล่านี้โดยอัตโนมัติ เพื่อให้คุณสามารถใช้สําหรับการวิเคราะห์แบบเรียลไทม์หรือรวมเข้ากับข้อมูล Fabric อื่นๆ ความสามารถนี้รองรับสถานการณ์การประมวลผลธุรกรรมและการวิเคราะห์แบบไฮบริด ซึ่งข้อมูลการดําเนินงานจะไหลเข้าสู่แพลตฟอร์มการวิเคราะห์ของคุณอย่างต่อเนื่อง
การมิเรอร์ช่วยลดความจําเป็นในการสร้างไปป์ไลน์โหลดที่เพิ่มขึ้นด้วยตนเอง จากมุมมอง ต้นทุนการมิเรอร์ การดําเนินการคํานวณที่ซิงค์ฐานข้อมูลมิเรอร์จะไม่ใช้หน่วยความจุ (CU) จากความจุ Fabric ของคุณ ที่เก็บข้อมูลมิเรอร์ใน OneLake ยังว่างถึงขีดจํากัดเทราไบต์ใน Fabric SKU ของคุณ (ตัวอย่างเช่น F64 มีที่เก็บข้อมูลฐานข้อมูลมิเรอร์ฟรี 64 TB)
เข้าถึงข้อมูลภายนอกด้วยทางลัด
Fabric มี ทางลัด เพื่อเปิดใช้งานการจําลองเสมือนของข้อมูล ทางลัดใน OneLake อ้างอิงข้อมูลที่จัดเก็บไว้ในระบบภายนอก เช่น Azure Data Lake Storage Gen2, Amazon S3 หรือ SharePoint ทางลัดยังสามารถอ้างอิงข้อมูลภายใน OneLake เอง รวมถึงข้อมูลจากพื้นที่ทํางานอื่นๆ และข้อมูลที่แชร์ระหว่างผู้เช่าผ่านการแชร์ข้อมูล OneLake แทนที่จะคัดลอกข้อมูล ทางลัดอนุญาตให้ OneLake อ้างอิงไฟล์ภายนอกและภายในซึ่งเป็นส่วนหนึ่งของ Data Lake แบบรวม คุณสามารถสืบค้นหรือรวมข้อมูลภายนอกกับข้อมูลภายในเครื่องโดยไม่ต้องทําการย้ายข้อมูลครั้งแรก วิธีการนําเข้าแบบไม่คัดลอกนี้มีประโยชน์เมื่อข้อกําหนดเกี่ยวกับถิ่นที่อยู่ของข้อมูลหรือข้อกังวลเกี่ยวกับการทําซ้ําขัดขวางการย้ายข้อมูล ไดอะแกรมต่อไปนี้แสดงวิธีที่ทางลัดเชื่อมต่อระบบจัดเก็บข้อมูลภายนอกกับรายการ Fabric โดยไม่ต้องคัดลอกข้อมูล:
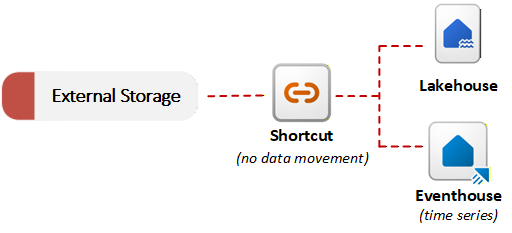
OneLake สามารถตรวจจับชนิดข้อมูลที่อ้างอิงโดยทางลัด และใช้ การแปลงไฟล์ หรือ การแปลง AI โดยไม่ต้องใช้ไปป์ไลน์หรือโค้ดแบบกําหนดเอง การแปลงเหล่านี้ทํางานกับเป้าหมายทางลัดใดๆ รวมถึงข้อมูลที่แชร์จากผู้เช่ารายอื่นผ่านการแชร์ข้อมูล OneLake OneLake รักษาตารางเดลต้าที่เป็นผลลัพธ์ให้ซิงค์กับแหล่งที่มาโดยอัตโนมัติ ตัวอย่างเช่น คุณสามารถแปลง .csv ไฟล์เป็นตารางเดลต้า หรือใช้การวิเคราะห์ความคิดเห็นที่ใช้ AI กับ .txt ไฟล์ในโฟลเดอร์
เมื่อรวมกับการสะท้อนทางลัดจะให้รูปแบบการเข้าถึงข้อมูลที่ยืดหยุ่นแก่คุณ คุณสามารถเก็บข้อมูลไว้กับที่ได้โดยใช้ทางลัด หรือคุณสามารถจําลองข้อมูลโดยใช้การสะท้อนภาพ ในทั้งสองกรณี ข้อมูลพร้อมสําหรับเครื่องมือวิเคราะห์ Fabric โดยไม่ต้องใช้ ETL ที่ซับซ้อน
คู่มือการตัดสินใจ: เลือกกลยุทธ์การเคลื่อนย้ายข้อมูล
Microsoft Fabric มีตัวเลือกมากมายสําหรับการนําข้อมูลเข้าสู่ Fabric รวมถึง Eventstreams สําหรับการประมวลผลแบบเรียลไทม์ การมิเรอร์ ไปป์ไลน์ที่มีกิจกรรมคัดลอก งานคัดลอก และทางลัด แต่ละตัวเลือกมีความสมดุลของการควบคุม ระบบอัตโนมัติ และความซับซ้อนในการดําเนินงานที่แตกต่างกัน เมื่อคุณต้องการการเข้าถึงข้อมูลที่มีอยู่แล้วใน OneLake (ไม่ว่าจะอยู่ในผู้เช่าเดียวกันหรือแชร์จากองค์กรอื่น) ให้พิจารณารวมการแชร์ข้อมูล OneLake กับทางลัดแทนการจําลองข้อมูล
สําหรับคําแนะนําในการเลือกแนวทางที่เหมาะสมสําหรับสถานการณ์ของคุณ โปรดดู คู่มือการตัดสินใจของ Microsoft Fabric: เลือกกลยุทธ์การเคลื่อนย้ายข้อมูล