หมายเหตุ
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลอง ลงชื่อเข้าใช้หรือเปลี่ยนไดเรกทอรีได้
การเข้าถึงหน้านี้ต้องได้รับการอนุญาต คุณสามารถลองเปลี่ยนไดเรกทอรีได้
ใช้ Azure Synapse Link สำหรับ Dataverse เพื่อส่งออกข้อมูล Microsoft Dataverse ของคุณในรูปแบบ Delta Lake Delta Lake เป็นรูปแบบดั้งเดิมสำหรับ Microsoft Fabric และเครื่องมืออื่นๆ จำนวนมาก เช่น Azure Databricks การส่งออกข้อมูลในรูปแบบ Delta Lake โดยตรงจาก Dataverse ไม่จำเป็นต้องมีกระบวนการแปลง Delta Lake ที่แยกต่างหากของคุณเอง และเร่งเวลาเข้าถึงข้อมูลเชิงลึก บทความนี้ให้ข้อมูลเกี่ยวกับคุณลักษณะนี้และแสดงวิธีการทำงานต่อไปนี้:
- อธิบายถึง Delta Lake และ Parquet และเหตุผลที่คุณควรส่งออกข้อมูลในรูปแบบนี้
- ส่งออกข้อมูล Dataverse ของคุณไปยังพื้นที่ทำงาน Azure Synapse Analytics ในรูปแบบ Delta Lake ด้วย Azure Synapse Link
- ตรวจสอบ Azure Synapse Link และการแปลงข้อมูลของคุณ
- ดูข้อมูลของคุณจาก Azure Data Lake Storage รุ่น2
- ดูข้อมูลของคุณจาก Synapse Workspace
- ดูข้อมูลของคุณ ใน Microsoft Fabric
Delta Lake คืออะไร
Delta Lake เป็นโครงการโอเพ่นซอร์สที่ช่วยให้สามารถสร้างสถาปัตยกรรม Lakehouse บน Data Lake Delta Lake สร้างธุรกรรม ACID (ครบหน่วย ความสม่ำเสมอ การแยกตัว และความทนทาน) การจัดการเมตาดาต้าที่ปรับขนาดได้ และรวมเอาการประมวลผลข้อมูลแบบสตรีมและชุดงานไว้ที่ด้านบนของ Data Lake ที่มีอยู่ Azure Synapse Analytics เข้ากันได้กับ Linux Foundation Delta Lake Delta Lake เวอร์ชันปัจจุบันที่มาพร้อมกับ Azure Synapse รองรับภาษาสำหรับ Scala, PySpark และ .NET ข้อมูลเพิ่มเติม: Delta Lake คืออะไร คุณยังสามารถเรียนรู้เพิ่มเติมได้จาก วิดีโอบทนำเกี่ยวกับตาราง Delta
Apache Parquet เป็นรูปแบบพื้นฐานสำหรับ Delta Lake ซึ่งช่วยให้คุณสามารถใช้ประโยชน์จากเค้าร่างการบีบอัดและการเข้ารหัสที่มีประสิทธิภาพซึ่งมาจากรูปแบบดั้งเดิม รูปแบบไฟล์ Parquet ใช้การบีบอัดแบบคอลัมน์ มีประสิทธิภาพและประหยัดพื้นที่จัดเก็บ การสอบถามที่ดึงค่าคอลัมน์เฉพาะไม่จำเป็นต้องอ่านข้อมูลทั้งแถว ซึ่งจะช่วยปรับปรุงประสิทธิภาพ ดังนั้นพูล SQL แบบไร้เซิร์ฟเวอร์จึงต้องการเวลาน้อยลงและคำขอที่เก็บข้อมูลน้อยลงในการอ่านข้อมูล
ทำไมจึงต้องใช้ Delta Lake
- ความสามารถในการปรับขนาด: Delta Lake สร้างขึ้นบนสิทธิการใช้งาน Apache แบบโอเพ่นซอร์ส ซึ่งได้รับการออกแบบให้เป็นไปตามมาตรฐานอุตสาหกรรมสำหรับการจัดการเวิร์กโหลดการประมวลผลข้อมูลขนาดใหญ่
- ความน่าเชื่อถือ: Delta Lake มอบธุรกรรมแบบ ACID เพื่อให้มั่นใจถึงความสอดคล้องของข้อมูลและความน่าเชื่อถือแม้ขณะเผชิญความล้มเหลวหรือการเข้าถึงพร้อมกัน
- ประสิทธิภาพ: Delta Lake ใช้ประโยชน์จากรูปแบบการจัดเก็บแบบคอลัมน์ของ Parquet ซึ่งใช้เทคนิคการบีบอัดและการเข้ารหัสที่ดีกว่า สามารถนำไปสู่การปรับปรุงประสิทธิภาพการสอบถามเมื่อเทียบกับการสอบถามไฟล์ CSV
- คุ้มค่า: รูปแบบไฟล์ Delta Lake เป็นเทคโนโลยีการจัดเก็บข้อมูลที่มีการบีบอัดสูงซึ่งช่วยประหยัดพื้นที่เก็บข้อมูลที่สำคัญสำหรับธุรกิจ รูปแบบนี้ได้รับการออกแบบมาโดยเฉพาะเพื่อเพิ่มประสิทธิภาพการประมวลผลข้อมูล และอาจลดจำนวนรวมของข้อมูลที่ประมวลผลหรือเวลาทำงานที่จำเป็นสำหรับการประมวลผลแบบออนดีมานด์
- การปฏิบัติตามข้อกำหนดการปกป้องข้อมูล: Delta Lake ที่มี Azure Synapse Link มีเครื่องมือและคุณลักษณะต่างๆ รวมถึงการลบแบบชั่วคราวและการลบแบบถาวรเพื่อให้เป็นไปตามข้อบังคับด้านความเป็นส่วนตัวของข้อมูลต่างๆ รวมถึงข้อบังคับทั่วไปเกี่ยวกับการคุ้มครองข้อมูล (GDPR)
Delta Lake ทำงานร่วมกับ Azure Synapse Link สำหรับ Dataverse อย่างไร
เมื่อตั้งค่า Azure Synapse Link สำหรับ Dataverse คุณสามารถเปิดใช้งานคุณลักษณะ ส่งออกไปยัง Delta Lake และเชื่อมต่อกับ Synapse workspace และ Spark pool Azure Synapse Link จะส่งออกตาราง Dataverse ที่เลือกในรูปแบบ CSV ตามช่วงเวลาที่กำหนด โดยประมวลผลผ่านงาน Spark การแปลง Delta Lake เมื่อกระบวนการแปลงนี้เสร็จสิ้น ข้อมูล CSV จะถูกล้างเพื่อให้ประหยัดที่เก็บข้อมูล นอกจากนี้ ชุดของงานการบำรุงรักษาถูกจัดกำหนดการให้ทำงานทุกวัน โดยดำเนินการบีบอัดและทำความสะอาดโดยอัตโนมัติเพื่อรวมและล้างไฟล์ข้อมูลในการเพิ่มประสิทธิภาพการจัดเก็บและปรับปรุงประสิทธิภาพการสอบถาม
สำคัญ
- หากคุณกำลังอัปเกรดจาก CSV เป็น Delta Lake ด้วยมุมมองแบบกำหนดเองที่มีอยู่ เราขอแนะนำให้อัปเดตสคริปต์เพื่อแทนที่ตาราง partitioned ทั้งหมดเป็นตาราง non_partitioned ดำเนินการนี้โดยค้นหาอินสแตนซ์ของ
_partitionedและแทนที่ด้วยสตริงว่าง - สำหรับการกำหนดค่า Dataverse ผนวกเท่านั้นถูกเปิดใช้งานตามค่าเริ่มต้นเพื่อส่งออกข้อมูล CSV ในโหมด
appendonlyตาราง Delta Lake จะมีโครงสร้างการอัปเดตแบบแทนที่ เนื่องจากการแปลง Delta Lake มาพร้อมกับกระบวนการผสานที่เกิดขึ้นเป็นประจำ - คุณต้องจัดเตรียมพูล Spark (ทรัพยากรการคำนวณ) ในการสมัครใช้งาน Azure ของคุณเองสำหรับการแปลง Delta พูล Spark นี้ใช้เพื่อทำการแปลง Delta เป็นระยะตามช่วงเวลาที่คุณเลือก
- ไม่มีค่าใช้จ่ายใดๆ เกิดขึ้นกับการสร้างกลุ่ม Spark ค่าใช้จ่ายจะเกิดขึ้นก็ต่อเมื่องาน Spark ถูกเรียกใช้บนกลุ่ม Spark เป้าหมายและอินสแตนซ์ Spark ถูกสร้างอินสแตนซ์แบบตามต้องการ ค่าใช้จ่ายเหล่านี้เกี่ยวข้องกับการใช้งาน Azure Synapse workspace Spark และจะเรียกเก็บเงินเป็นรายเดือน ค่าใช้จ่ายในการคำนวณ Spark ส่วนใหญ่ขึ้นอยู่กับช่วงเวลาสำหรับการอัปเดตส่วนเพิ่มและปริมาณข้อมูล ข้อมูลเพิ่มเติม: ราคา Azure Synapse Analytics
- คุณต้องสร้างพูล Spark ด้วยเวอร์ชัน 3.4 หากคุณใช้ คุณลักษณะ นี้กับ Spark เวอร์ชัน 3.3 อยู่แล้ว คุณต้องทำการอัปเกรดแบบแทนที่สำหรับโปรไฟล์ที่มีอยู่ของคุณ ข้อมูลเพิ่มเติม: อัปเกรดแบบแทนที่เป็น Apache Spark 3.4 ด้วย Delta Lake 2.4
หมายเหตุ
สถานะ Azure Synapse Link ใน Power Apps (make.powerapps.com) สะท้อนถึงสถานะการแปลง Delta Lake:
-
Countแสดงจำนวนรวมของเรกคอร์ดในตาราง Delta Lake - วันที่และเวลา
Last synchronized onแสดงถึงการบันทึกเวลาการแปลงที่สำเร็จครั้งล่าสุด -
Sync statusจะแสดงเป็น ใช้งานอยู่ เมื่อการซิงค์ข้อมูลและการแปลง Delta Lake เสร็จสิ้น ซึ่งแสดงว่าข้อมูลพร้อมสำหรับการใช้งาน
ข้อกำหนดเบื้องต้น
- Dataverse: คุณต้องมีบทบาทความปลอดภัย ผู้ดูแลระบบ Dataverse นอกจากนี้ ตารางที่คุณต้องการส่งออกผ่าน Azure Synapse Link ต้องเปิดใช้งานคุณสมบัติ ติดตามการเปลี่ยนแปลง ข้อมูลเพิ่มเติม: ตัวเลือกขั้นสูง
- Azure Data Lake Storage Gen2: คุณต้องมีบัญชี Azure Data Lake Storage Gen2 และการเข้าถึงบทบาท เจ้าของ และ ผู้สนับสนุน Storage Blob Data บัญชีที่เก็บข้อมูลของคุณต้องเปิดใช้งาน เนมสเปซแบบลำดับชั้น และ การเข้าถึงเครือข่ายสาธารณะ สำหรับทั้งการตั้งค่าเริ่มต้นและการซิงค์เดลต้า อนุญาตการเข้าถึงคีย์บัญชีที่เก็บข้อมูล จำเป็นสำหรับการตั้งค่าเริ่มต้นเท่านั้น
- Synapse workspace: คุณต้องมี Synapse workspace และบทบาท เจ้าาของ ในการควบคุมการเข้าถึง (IAM) และการเข้าถึงของบทบาท ผู้ดูแลระบบ Synapse ภายใน Synapse Studio พื้นที่ทำงาน Synapse ต้องอยู่ในภูมิภาคเดียวกับบัญชี Azure Data Lake Storage Gen2 ของคุณ ต้องมีการเพิ่มบัญชีที่เก็บข้อมูลเป็นบริการที่เชื่อมโยงภายใน Synapse Studio ในการสร้างพื้นที่ทำงาน Synapse ไปที่ การสร้างพื้นที่ทำงาน Synapse
- พูล Apache Spark ใน Azure Synapse workspace ที่เชื่อมต่อที่มี Apache Spark เวอร์ชัน 3.4 ที่ใช้ การกำหนดค่าพูล Spark ที่แนะนำ นี้ สำหรับข้อมูลเกี่ยวกับวิธีสร้างพูล Spark ให้ไปที่ สร้างพูล Apache Spark ใหม่
- ข้อกำหนดเวอร์ชันขั้นต่ำของ Microsoft Dynamics 365 เพื่อใช้คุณลักษณะนี้คือ 9.2.22082 ข้อมูลเพิ่มเติม: เลือกเข้าร่วมเพื่อเข้าใช้การปรับปรุงล่วงหน้า
การกำหนดค่ากลุ่ม Spark ที่แนะนำ
การกำหนดค่านี้ถือเป็นขั้นตอนการเริ่มต้นระบบสำหรับกรณีการใช้งานโดยเฉลี่ย
- ขนาดโหนด: เล็ก (4 vCores / 32 GB)
- การปรับมาตราส่วนอัตโนมัติ: เปิดใช้งาน
- จำนวนโหนด: 3 ถึง 10 (หรือ 20 หากจำเป็น 1ข้อมูลเพิ่มเติมด้านล่าง)
- การหยุดชั่วคราวอัตโนมัติ: เปิดใช้งาน
- จำนวนนาทีที่ไม่ใช้งาน: 5
- Apache Spark: 3.4
- ตัวดำเนินการจัดสรรแบบไดนามิก: เปิดใช้งาน
- จำนวนตัวดำเนินการเริ่มต้น: 1 ถึง 9
สำคัญ
- ใช้พูล Spark เฉพาะสำหรับการดำเนินการแปลง Delta Lake ด้วย Synapse Link for Dataverse เพื่อความน่าเชื่อถือและประสิทธิภาพสูงสุด ให้หลีกเลี่ยงการเรียกใช้งาน Spark อื่นๆ โดยใช้พูล Spark เดียวกัน
- คุณอาจต้องเพิ่มจำนวนโหนดของพูล Spark หากคุณคาดว่าจะมีการประมวลผลแถวจำนวนมาก หากขนาดของพูล Spark ไม่เพียงพอ งานการแปลง Delta อาจล้มเหลว
- ระบบใช้พูล Spark เดียวกันเพื่อทำงานกลางคืนที่บีบอัดไฟล์ Delta ในทะเลสาบระหว่างเวลา 23.00 น. ถึง 6.00 น. ตามเวลาท้องถิ่น ระบบจะกำหนดเวลากลางคืนเพื่อเรียกใช้งานนี้ตามตำแหน่งที่ตั้งของสภาพแวดล้อม Dataverse ของคุณ คุณไม่สามารถระบุกรอบเวลาที่เฉพาะเจาะจงได้ ตัวเลือกนี้ช่วยลดขนาดไฟล์ Delta โดยการรวมไฟล์ที่เรียกว่า "การบีบอัด" ในบางกรณี งานนี้อาจรบกวนงานการแปลงแบบเพิ่มหน่วย คุณสามารถเพิ่มจำนวนโหนดเป็น 20 ในกรณีที่คุณสังเกตเห็นความล้มเหลวเหล่านี้
- คุณจะถูกเรียกเก็บเงินสำหรับโหนดพูล Spark ที่ใช้งานจริงเท่านั้น การเพิ่มจำนวนโหนดอาจไม่ส่งผลให้มีค่าใช้จ่ายสูงขึ้น
เชื่อมต่อ Dataverse กับ Synapse workspace และส่งออกข้อมูลในรูปแบบ Delta Lake
ลงชื่อเข้าใช้ Power Apps และเลือกสภาพแวดล้อมที่คุณต้องการ
บนบานหน้าต่างการนำทางด้านซ้าย เลือก Azure Synapse Link หากรายการไม่อยู่ในบานหน้าต่างแผงด้านข้าง ให้เลือก …เพิ่มเติม แล้วเลือกรายการที่คุณต้องการ
บนแถบคำสั่ง ให้เลือก + ลิงก์ใหม่
เลือก เชื่อมต่อกับ Azure Synapse Analytics workspace ของคุณ แล้วเลือก การสมัครใช้งาน, กลุ่มทรัพยากร และ ชื่อพื้นที่ทำงาน
เลือก ใช้กลุ่ม Spark สำหรับการประมวลผล จากนั้นเลือก กลุ่ม Spark และ บัญชีที่เก็บข้อมูล ที่สร้างไว้ล่วงหน้า
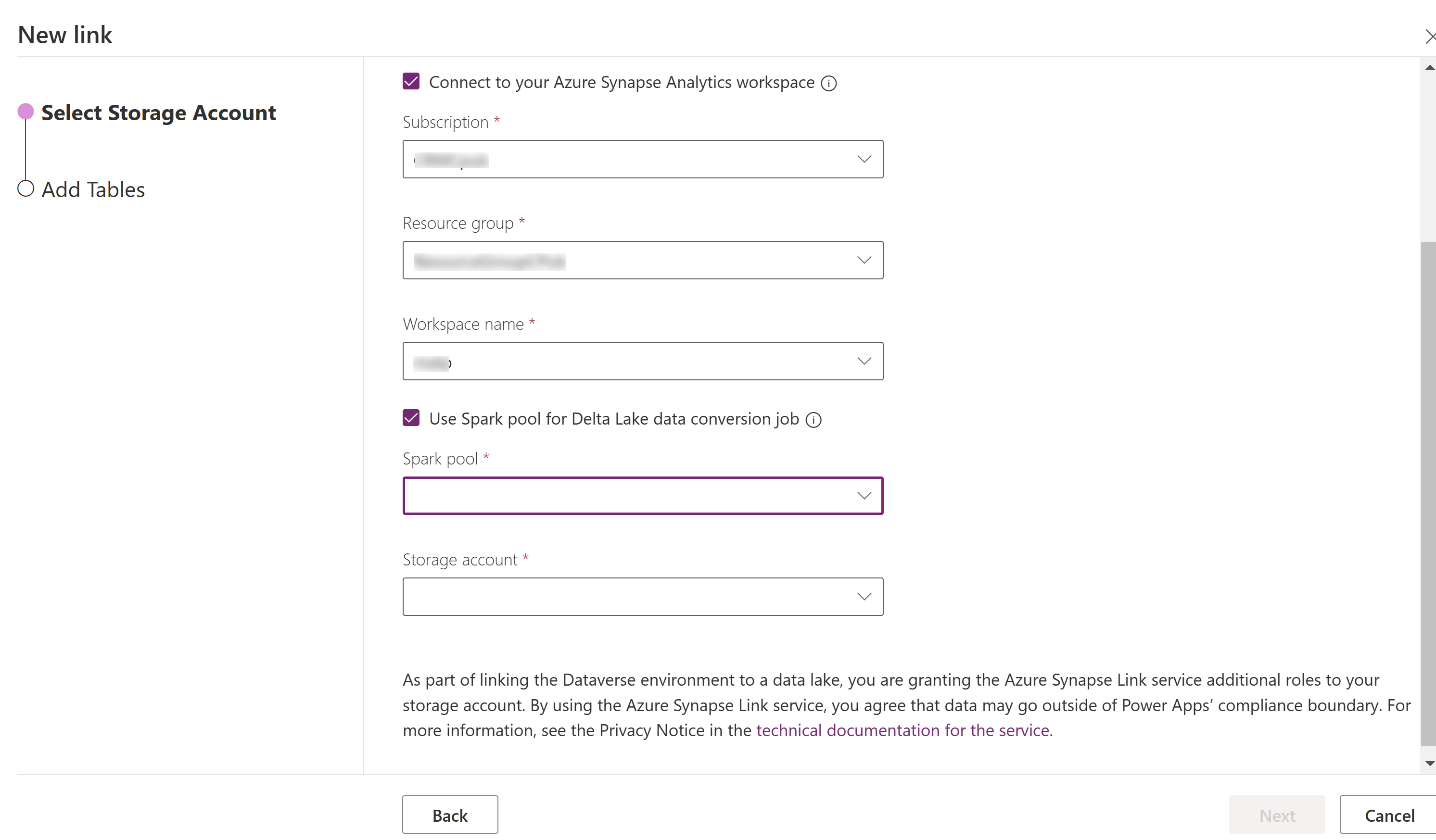
เลือก ถัดไป
เพิ่มตารางที่คุณต้องการส่งออก จากนั้นเลือก ขั้นสูง
หรือเลือก แสดงการตั้งค่าการกำหนดค่าขั้นสูง และป้อนช่วงเวลาเป็นนาทีสำหรับความถี่ที่ควรบันทึกการปรับปรุงแบบเพิ่มหน่วย
เลือก บันทึก
ตรวจสอบ Azure Synapse Link และการแปลงข้อมูลของคุณ
- เลือก Azure Synapse Link ที่คุณต้องการ แล้วเลือก ไปที่ Azure Synapse Analytics workspace บนแถบคำสั่ง
- เลือก การตรวจสอบ>แอปพลิเคชัน Apache Spark ข้อมูลเพิ่มเติม: ใช้ Synapse Studio เพื่อตรวจสอบแอปพลิเคชัน Apache Spark ของคุณ
ดูข้อมูลของคุณจาก Synapse workspace
- เลือก Azure Synapse Link ที่คุณต้องการ แล้วเลือก ไปที่ Azure Synapse Analytics workspace บนแถบคำสั่ง
- ขยาย ฐานข้อมูลที่จัดเก็บข้อมูลดิบ บนบานหน้าต่างด้านซ้าย เลือก dataverse-environmentNameorganizationUniqueName แล้วขยาย ตาราง มีการแสดงตาราง Parquet ทั้งหมดไว้และใช้ได้สำหรับการวิเคราะห์ด้วยแบบแผนการตั้งชื่อ DataverseTableName.(Non_partitioned Table)
หมายเหตุ
อย่าใช้ตารางที่มีหลักการตั้งชื่อ _partitioned เมื่อคุณเลือก Delta parquet เป็นรูปแบบ ตารางที่มีหลักการตั้งชื่อ _partition จะถูกใช้เป็นตารางการจัดเตรียมและลบออกหลังจากที่ระบบใช้งานแล้ว
ดูข้อมูลของคุณจาก Azure Data Lake Storage รุ่น2
- เลือก Azure Synapse Link ที่คุณต้องการ แล้วเลือก ไปยัง Azure Data Lake บนแถบคำสั่ง
- เลือก คอนเทนเนอร์ ภายใต้ ที่เก็บข้อมูล
- เลือก *dataverse- *environmentName-organizationUniqueName ไฟล์ Parquet ทั้งหมดจัดเก็บไว้ในโฟลเดอร์ deltalake
อัปเกรดแบบแทนที่เป็น Apache Spark 3.4 ด้วย Delta Lake 2.4
ตามนโยบายวงจรชีวิตของ Synapse runtime for Apache Spark, Azure Synapse runtime for Apache Spark 3.3 จะมีการเลิกใช้และปิดใช้งานในวันที่ 31 มีนาคม 2025 รันไทม์ที่เลิกใช้แล้วจะไม่สามารถใช้งานสำหรับพูล Spark ใหม่ และเวิร์กโฟลว์ที่มีอยู่กับพูล Spark 3.3 จะไม่ถูกดำเนินการ ในขณะที่เมตาดาต้าจะยังคงอยู่ในพื้นที่ทำงาน Synapse ชั่วคราว ข้อมูลเพิ่มเติม: รันไทม์ Azure Synapse สำหรับ Apache Spark 3.3 (EOSA)
เพื่อให้โปรไฟล์ Synapse Link ที่มีอยู่ของคุณดำเนินการประมวลผลข้อมูลต่อ คุณต้องอัปเกรดโปรไฟล์ Synapse Link เพื่อใช้พูล Spark 3.4 โดยใช้ "กระบวนการอัปเกรดแบบแทนที่"
ข้อกำหนดเบื้องต้นในการอัปเกรดแบบแทนที่
- คุณต้องมีโปรไฟล์ Azure Synapse Link สำหรับ Dataverse Delta Lake ที่ทำงานกับ Synapse Spark เวอร์ชัน 3.3
- คุณต้องสร้างพูล Synapse Spark ใหม่ด้วย Spark version 3.4 โดยใช้การกำหนดค่าฮาร์ดแวร์โหนดเดียวกันหรือสูงกว่าภายในพื้นที่ทำงาน Synapse เดียวกัน สำหรับข้อมูลเกี่ยวกับวิธีสร้างพูล Spark ให้ไปที่ สร้างพูล Apache Spark ใหม่ พูล Spark นี้ควรสร้างโดยไม่อิงกับพูล 3.3 ปัจจุบัน - อย่าลบพูล Spark 3.3 ของคุณหรือสร้างพูล Spark 3.4 ที่มีชื่อเดียวกัน
อัปเกรดแบบแทนที่เป็น Spark 3.4
- ลงชื่อเข้าใช้ Power Apps และเลือกสภาพแวดล้อมที่คุณต้องการ
- บนบานหน้าต่างการนำทางด้านซ้าย เลือก Azure Synapse Link หากรายการไม่อยู่ในบานหน้าต่างนำทางด้านซ้าย ให้เลือก …เพิ่มเติม แล้วเลือกรายการที่คุณต้องการ
- เปิดโปรไฟล์ Azure Synapse Link แล้วเลือก อัปเกรดเป็น Apache Spark 3.4 ที่มี Delta Lake 2.4
- เลือกพูล Spark ที่มีอยู่จากรายการและเลือก จากนั้น Update
หมายเหตุ
- การอัปเกรดพูล Spark จะเกิดขึ้นเมื่อมีการทริกเกอร์งาน Spark ที่แปลง Delta Lake ใหม่เท่านั้น ตรวจสอบให้แน่ใจว่ามีข้อมูลเปลี่ยนแปลงอย่างน้อยหนึ่งข้อมูลหลังจากเลือก Update
- คุณสามารถลบพูล Spark 3.3 ที่เก่ากว่าได้หลังจากตรวจสอบว่างานการแปลง Delta ใช้พูลใหม่