Azure Databricks'te performans sorunlarını giderme
Not
Bu makale, GitHub'da barındırılan bir açık kaynak kitaplığına dayanır: https://github.com/mspnp/spark-monitoring.
Özgün kitaplık, Azure Databricks Runtimes 10.x (Spark 3.2.x) ve önceki sürümleri destekler.
Databricks, şu konumdaki dalda Azure Databricks Runtimes 11.0 (Spark 3.3.x) ve üzerini l4jv2 desteklemek için güncelleştirilmiş bir sürüme katkıda bulunmuştur. https://github.com/mspnp/spark-monitoring/tree/l4jv2
Databricks Runtimes'da kullanılan farklı günlük sistemleri nedeniyle 11.0 sürümünün geriye dönük olarak uyumlu olmadığını lütfen unutmayın. Databricks Runtime'ınız için doğru derlemeyi kullandığınızdan emin olun. Kitaplık ve GitHub deposu bakım modundadır. Başka sürümler için plan yoktur ve sorun desteği yalnızca en iyi çabayı gösterir. Azure Databricks ortamlarınızı izleme ve günlüğe kaydetmeye yönelik kitaplık veya yol haritasıyla ilgili ek sorularınız için lütfen ile iletişime geçin azure-spark-monitoring-help@databricks.com.
Bu makalede, Azure Databricks'teki Spark işlerinde performans sorunlarını bulmak için izleme panolarının nasıl kullanılacağı açıklanır.
Azure Databricks , büyük veri analizini hızla geliştirmeyi ve dağıtmayı kolaylaştıran Apache Spark tabanlı bir analiz hizmetidir. Üretim Azure Databricks iş yüklerini çalıştırırken performans sorunlarını izleme ve giderme kritik önem taşır. Yaygın performans sorunlarını belirlemek için telemetri verilerine dayalı izleme görselleştirmelerini kullanmak yararlı olur.
Önkoşullar
Bu makalede gösterilen Grafana panolarını ayarlamak için:
Azure Databricks İzleme Kitaplığı'nı kullanarak Databricks kümenizi log analytics çalışma alanına telemetri gönderecek şekilde yapılandırın. Ayrıntılar için bkz. GitHub benioku.
Grafana'ı bir sanal makineye dağıtın. Bkz . Azure Databricks ölçümlerini görselleştirmek için panoları kullanma.
Dağıtılan Grafana panosu bir dizi zaman serisi görselleştirme içerir. Her grafik bir Apache Spark işi, işin aşamaları ve her aşamayı oluşturan görevlerle ilgili ölçümlerin zaman serisi çizimidir.
Azure Databricks performansına genel bakış
Azure Databricks, genel amaçlı bir dağıtılmış bilgi işlem sistemi olan Apache Spark'ı temel alır. İş olarak bilinen uygulama kodu, küme yöneticisi tarafından koordine edilen bir Apache Spark kümesinde yürütülür. Genel olarak, bir iş en üst düzey hesaplama birimidir. İş, Spark uygulaması tarafından gerçekleştirilen tam işlemi temsil eder. Tipik bir işlem bir kaynaktan veri okumayı, veri dönüştürmeleri uygulamayı ve sonuçları depolama alanına veya başka bir hedefe yazmayı içerir.
İşler aşamalara ayrılır. İş aşamalar arasında sıralı olarak ilerler, bu da sonraki aşamaların daha önceki aşamaların tamamlanmasını beklemesi gerektiği anlamına gelir. Aşamalar, Spark kümesinin birden çok düğümünde paralel olarak yürütülebilen özdeş görev gruplarını içerir. Görevler, verilerin bir alt kümesinde gerçekleşen en ayrıntılı yürütme birimidir.
Sonraki bölümlerde performans sorunlarını gidermek için yararlı olan bazı pano görselleştirmeleri açıklanmaktadır.
İş ve aşama gecikme süresi
İş gecikme süresi, bir iş yürütülmeye başlandığından tamamlanana kadar olan süredir. Aykırı değerlerin görselleştirmesine izin vermek için küme ve uygulama kimliği başına bir iş yürütmesinin yüzdebirlik dilimleri olarak gösterilir. Aşağıdaki grafikte, 50. yüzdebirlik değer tutarlı olarak 10 saniye civarında olsa bile 90. yüzdebirlik değerin 50 saniyeye ulaştığı bir iş geçmişi gösterilmektedir.
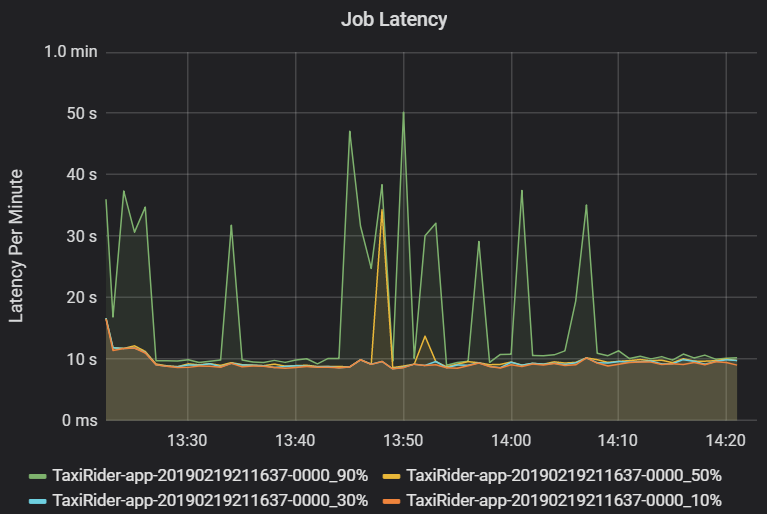
Gecikme süresindeki ani artışları arayarak kümeye ve uygulamaya göre iş yürütmeyi araştırın. Yüksek gecikme süresine sahip kümeler ve uygulamalar tanımlandıktan sonra aşama gecikme süresini araştırmak için ilerleyin.
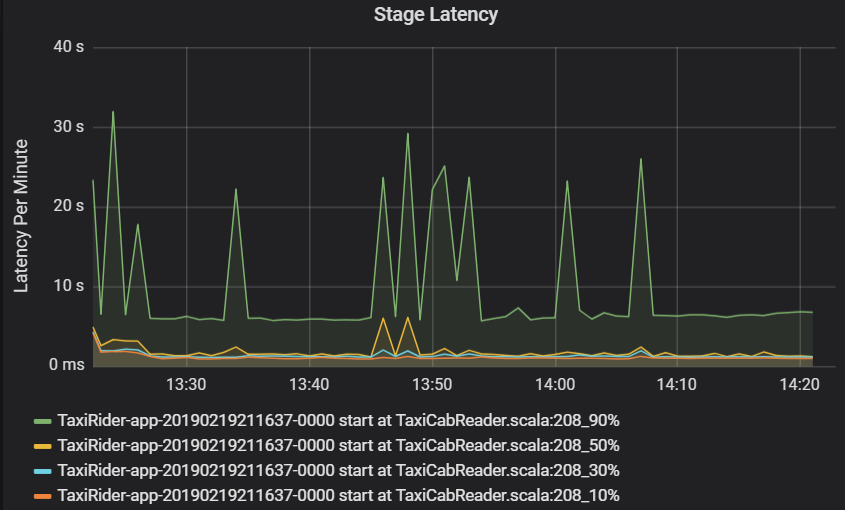
Aşama gecikme süresi, aykırı değerlerin görselleştirmesine olanak sağlamak için yüzdebirlik dilimler olarak da gösterilir. Aşama gecikme süresi küme, uygulama ve aşama adına göre ayrılır. Aşamanın tamamlanmasını hangi görevlerin bekleteceğini belirlemek için grafikteki görev gecikme süresindeki ani artışları belirleyin.
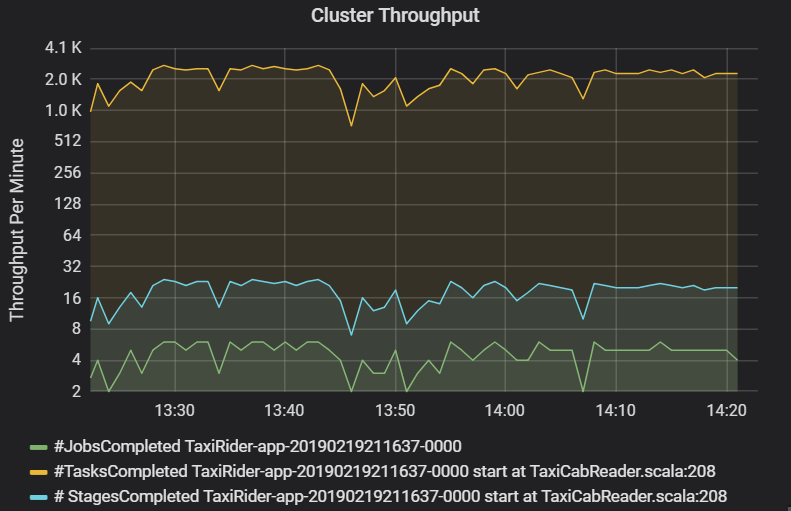
Küme aktarım hızı grafiği dakikada tamamlanan iş, aşama ve görev sayısını gösterir. Bu, iş başına aşama ve görev sayısı açısından iş yükünü anlamanıza yardımcı olur. Burada dakikada iş sayısının 2 ile 6 arasında olduğunu, aşama sayısının ise dakikada yaklaşık 12 ile 24 arasında olduğunu görebilirsiniz.
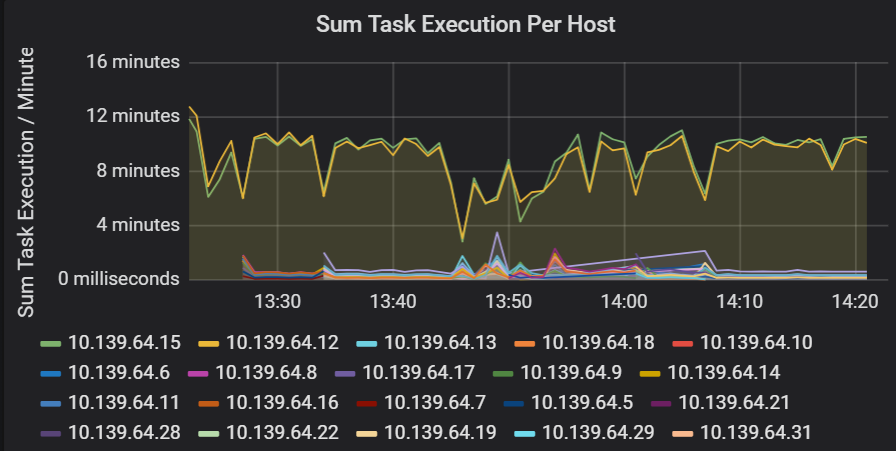
Görev yürütme gecikme süresi toplamı
Bu görselleştirme, bir kümede çalışan konak başına görev yürütme gecikme süresinin toplamını gösterir. Konak kümede yavaşlama veya yürütücü başına görevlerin yanlış konumlanması nedeniyle yavaş çalışan görevleri algılamak için bu grafiği kullanın. Aşağıdaki grafikte, konakların çoğunun toplamı yaklaşık 30 saniyedir. Ancak, konaklardan ikisinin toplamları yaklaşık 10 dakikadır. Konaklar yavaş çalışıyor veya yürütücü başına görev sayısı yanlış ayrılmış.
Yürütücü başına görev sayısı, iki yürütücüye orantısız sayıda görev atandığını gösterir ve bu da bir performans sorununa neden olur.
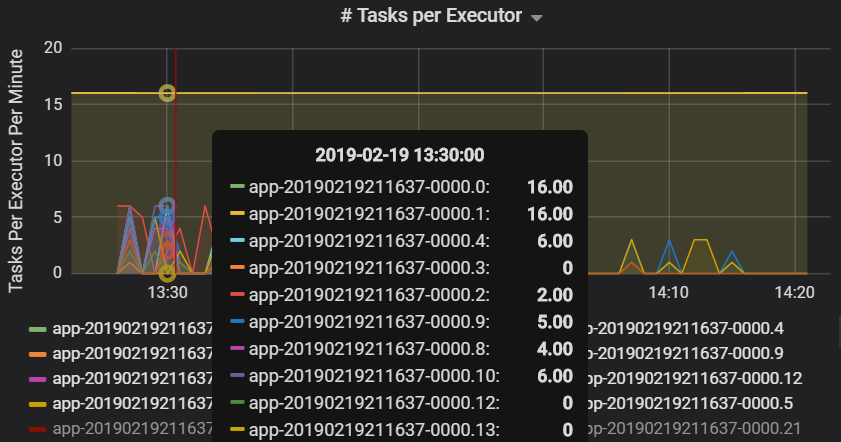
Aşama başına görev ölçümleri
Görev ölçümleri görselleştirmesi, görev yürütme için maliyet dökümünü verir. Seri hale getirme ve seri durumdan çıkarma gibi görevlerde harcanan göreli süreyi görmek için bunu kullanabilirsiniz. Bu veriler, verileri göndermekten kaçınmak için yayın değişkenlerini kullanarak iyileştirme fırsatları gösterebilir. Görev ölçümleri ayrıca bir görevin karıştırma veri boyutunu ve karıştırma okuma ve yazma sürelerini gösterir. Bu değerler yüksekse, ağ üzerinde çok fazla veri taşındığı anlamına gelir.
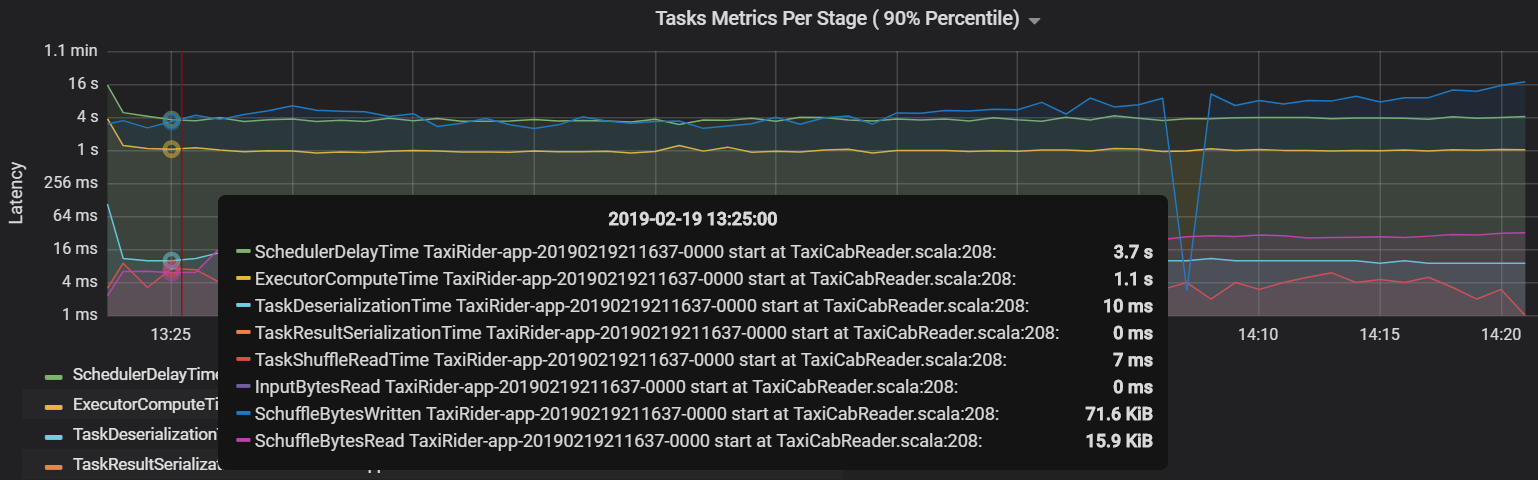
Bir diğer görev ölçümü de bir görevi zamanlamanın ne kadar sürdüğünü ölçen zamanlayıcı gecikmesidir. İdeal olan, bu değerin yürütücü işlem süresiyle karşılaştırıldığında düşük olmasıdır ve bu da görevi yürütmek için harcanan süredir.
Aşağıdaki grafikte yürütücü işlem süresini (1,1 sn) aşan bir zamanlayıcı gecikme süresi (3,7 sn) gösterilmektedir. Bu, görevlerin zamanlanması için beklemenin fiili çalışmayı yapmaktan daha fazla zaman harcadığı anlamına gelir.
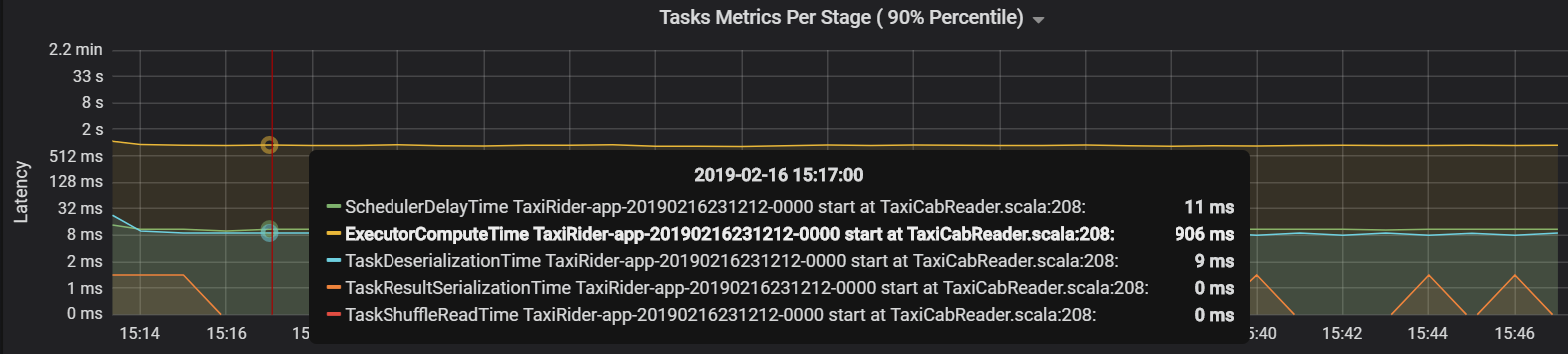
Bu durumda, sorun çok fazla bölüm olmasından kaynaklandı ve bu da çok fazla ek yüke neden oldu. Bölüm sayısı azaltıldığında zamanlayıcı gecikme süresi azaltıldı. Sonraki grafikte, çoğu zaman görevin yürütülmesi için harcandığını gösterilmektedir.
Akış aktarım hızı ve gecikme süresi
Akış aktarım hızı doğrudan yapılandırılmış akışla ilgilidir. Akış aktarım hızıyla ilişkili iki önemli ölçüm vardır: Saniye başına satır girişi ve saniye başına işlenen satırlar. Saniye başına giriş satırları saniyedeki işlenen satır sayısını aşıyorsa, akış işleme sisteminin geride kaldığı anlamına gelir. Ayrıca, giriş verileri Event Hubs veya Kafka'dan geliyorsa, saniye başına giriş satırları ön uçta veri alım hızına ayak uydurmalıdır.
İki iş benzer küme aktarım hızına sahip olabilir ancak çok farklı akış ölçümlerine sahip olabilir. Aşağıdaki ekran görüntüsünde iki farklı iş yükü gösterilmektedir. Bunlar küme aktarım hızı açısından benzerdir (dakikada işler, aşamalar ve görevler). Ancak ikinci çalıştırma 12.000 satır/sn ile 4.000 satır/sn'yi işler.
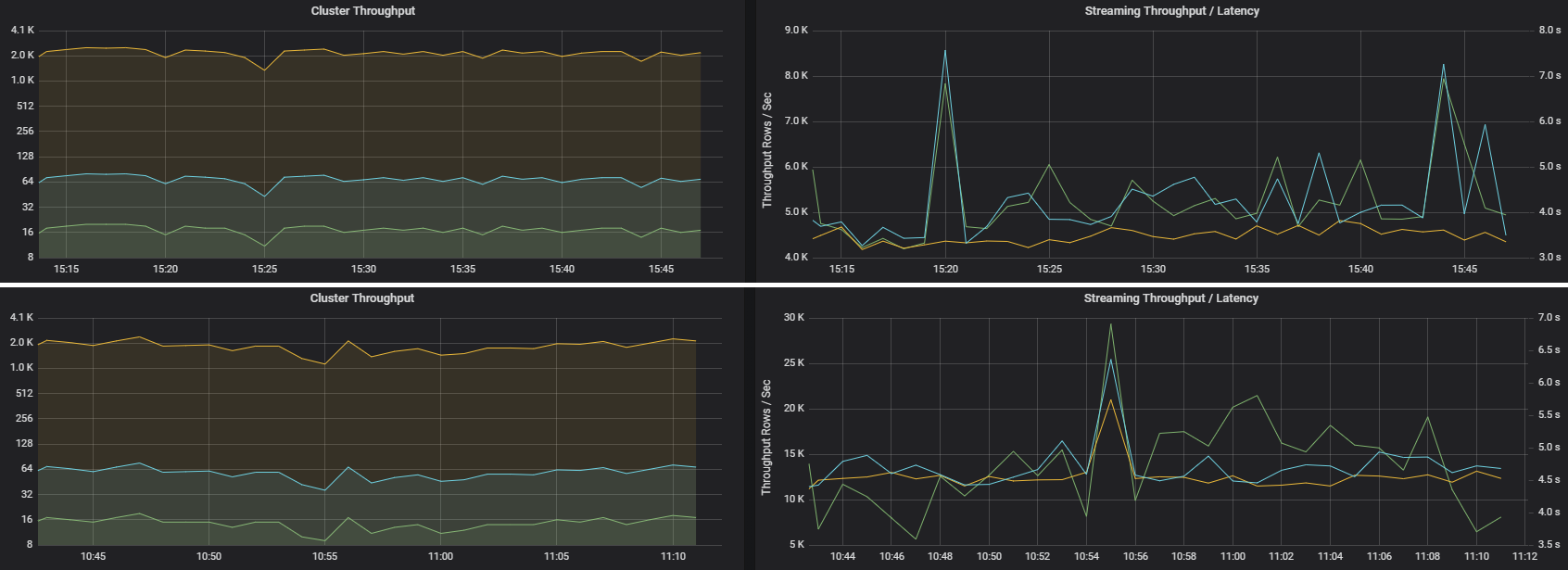
İşlenen veri kayıtlarının sayısını ölçtlüğünden akış aktarım hızı genellikle küme aktarım hızına göre daha iyi bir iş ölçümüdür.
Yürütücü başına kaynak tüketimi
Bu ölçümler, her yürütücü tarafından gerçekleştirdiği işin anlaşılmasına yardımcı olur.
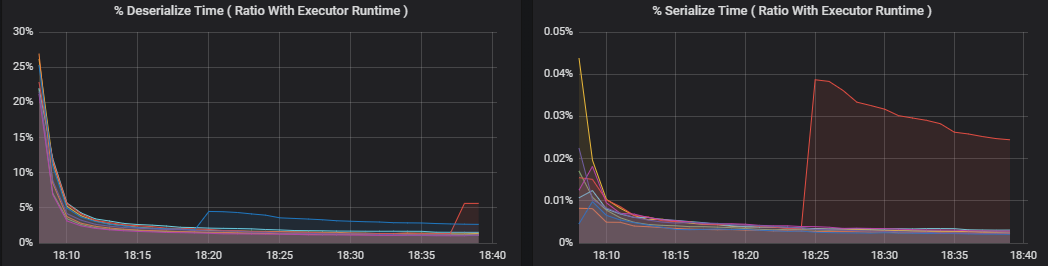
Yüzde ölçümleri , yürütücünün çeşitli işlemler için harcadığı süreyi ölçer ve genel yürütücü işlem süresine kıyasla harcanan süre oranı olarak ifade edilir. Ölçümler şunlardır:
- Serileştirme süresi yüzdesi
- Seri durumdan çıkarma süresi yüzdesi
- CPU yürütme süresi yüzdesi
- JVM süresi yüzdesi
Bu görselleştirmeler, bu ölçümlerin her birinin genel yürütücü işlemeye ne kadar katkı sağlayacağını gösterir.
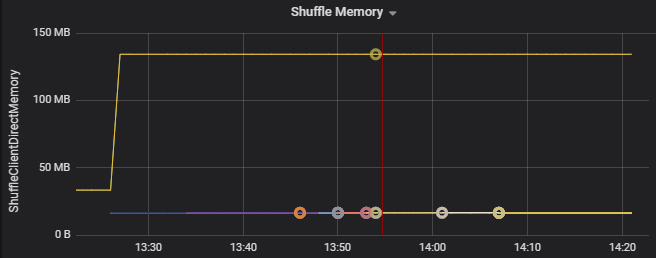
Karıştırma ölçümleri , yürütücüler arasında veri karıştırmayla ilgili ölçümlerdir.
- Karışık G/Ç
- Belleği karıştırma
- Dosya sistemi kullanımı
- Disk kullanımı
Yaygın performans sorunları
Spark'ta iki yaygın performans sorunu , görev saptırıcıları ve en uygun olmayan karıştırma bölümü sayısıdır.
Görev kalınlıkları
İşin aşamaları sırayla yürütülür ve erken aşamalar sonraki aşamaları engeller. Bir görev karışık bölümü diğer görevlerden daha yavaş yürütüyorsa, aşamanın tamamlanabilmesi için önce kümedeki tüm görevler yavaş görevin yetişmesini beklemelidir. Bu, aşağıdaki nedenlerle oluşabilir:
Bir konak veya konak grubu yavaş çalışıyor. Belirtiler: Yüksek görev, aşama veya iş gecikmesi ve düşük küme aktarım hızı. Konak başına görev gecikme sürelerinin toplamı eşit olarak dağıtılmamalıdır. Ancak, kaynak tüketimi yürütücüler arasında eşit olarak dağıtılır.
Görevlerin yürütülecek pahalı bir toplaması vardır (veri dengesizliği). Belirtiler: Yüksek görev gecikme süresi, yüksek aşama gecikme süresi, yüksek iş gecikmesi veya düşük küme aktarım hızı, ancak konak başına gecikme sürelerinin toplamı eşit olarak dağıtılır. Kaynak tüketimi yürütücüler arasında eşit olarak dağıtılır.
Bölümler eşit olmayan boyuttaysa, daha büyük bir bölüm dengesiz görev yürütmeye (bölüm dengesizliği) neden olabilir. Belirtiler: Yürütücü kaynak tüketimi, kümede çalışan diğer yürütücülerle karşılaştırıldığında yüksektir. Bu yürütücüde çalışan tüm görevler yavaş çalışır ve işlem hattında aşama yürütmesini tutar. Bu aşamaların aşama bariyerleri olduğu söylenir.
En uygun olmayan karıştırma bölümü sayısı
Yapılandırılmış akış sorgusu sırasında, bir görevin yürütücüye atanması küme için yoğun kaynak gerektiren bir işlemdir. Karıştırma verileri en uygun boyut değilse, görevin gecikme süresi aktarım hızını ve gecikme süresini olumsuz etkiler. Çok az bölüm varsa kümedeki çekirdekler az kullanılır ve bu da işlem verimsizliğine neden olabilir. Buna karşılık, çok fazla bölüm varsa, az sayıda görev için çok fazla yönetim yükü vardır.
Kümedeki yürütücülerin bölüm dengesizliği ve yanlış yerleştirilmesi sorunlarını gidermek için kaynak tüketimi ölçümlerini kullanın. Bir bölüm dengesizse, yürütücü kaynakları kümede çalışan diğer yürütücülere kıyasla yükseltilir.
Örneğin, aşağıdaki grafikte ilk iki yürütücüde karıştırılarak kullanılan belleğin diğer yürütücülerden 90 kat daha büyük olduğu gösterilmektedir:
Sonraki adımlar
- Azure Log Analytics Çalışma Alanında Azure Databricks'i izleme
- Öğrenme yolu: Azure Databricks ile makine öğrenmesi çözümleri oluşturma ve çalıştırma
- Azure Databricks belgeleri
- Azure İzleyici'ye genel bakış
İlgili kaynaklar
Geri Bildirim
Çok yakında: 2024 boyunca, içerik için geri bildirim mekanizması olarak GitHub Sorunları’nı kullanımdan kaldıracak ve yeni bir geri bildirim sistemiyle değiştireceğiz. Daha fazla bilgi için bkz. https://aka.ms/ContentUserFeedback.
Gönderin ve geri bildirimi görüntüleyin