Hadoop Dağıtılmış Dosya Sistemi (HDFS), büyük ticari sunucu kümelerine yayılabilen güvenilir, ölçeklenebilir veri depolama alanı sağlayan Java tabanlı bir dağıtılmış dosya sistemidir. Bu makalede HDFS'ye genel bir bakış ve Bunu Azure'a geçirme kılavuzu sağlanmaktadır.
Apache, Apache Spark®, Apache Hadoop®, Apache Hive ve alev logosu, Apache Software Foundation'ın Birleşik Devletler ve/veya diğer ülkelerdeki tescilli ticari markaları veya ticari markalarıdır.® Bu işaretlerin kullanılması Apache Software Foundation tarafından onaylanmamaktadır.
HDFS Mimarisi ve Bileşenleri
HDFS'nin birincil/ikincil tasarımı vardır. Aşağıdaki diyagramda NameNode birincil, DataNodes ise ikincil öğelerdir.
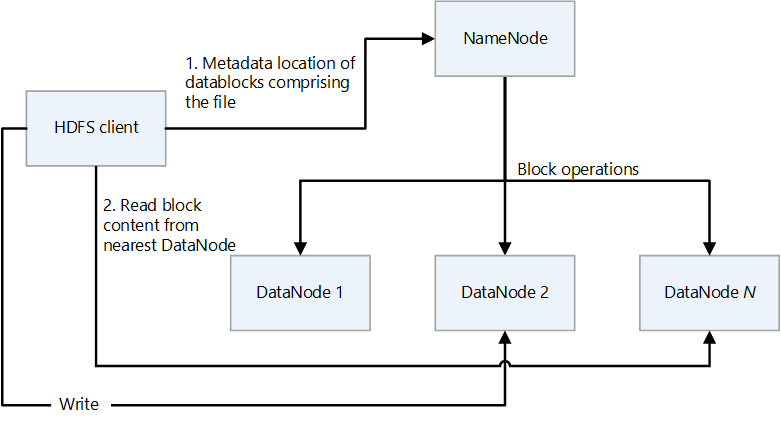
- NameNode , dizin hiyerarşisi olan dosyalara ve dosya sistemi ad alanına erişimi yönetir.
- Dosyalar ve dizinler NameNode üzerindeki düğümlerdir. İzinler, değişiklik ve erişim süreleri ve ad alanı ile disk alanı için boyut kotaları gibi öznitelikleri vardır.
- Bir dosya birden çok blok içerir. Varsayılan blok boyutu 128 megabayttır. Hdfs-site.xml dosyası değiştirilerek küme için varsayılan olmayan bir blok boyutu ayarlanabilir.
- Dosyanın her bloğu, birden çok DataNodes'ta bağımsız olarak çoğaltılır. Çoğaltma faktörü için varsayılan değer üç değerdir, ancak her kümenin kendi varsayılan olmayan değeri olabilir. Çoğaltma faktörü istediğiniz zaman değiştirilebilir. Değişiklik, kümenin yeniden dengelenmesine neden olur.
- NameNode, ad alanı ağacını ve dosya bloklarının DataNodes ile eşlemesini (dosya verilerinin fiziksel konumları) korur.
- HDFS istemcisi bir dosyayı okuduğunda:
- Dosyanın veri bloklarının konumları için NameNode ile iletişim kurar.
- En yakın DataNode'dan blok içeriğini okur.
- HDFS, ad alanının tamamını RAM'de tutar.
- DataNodes , dosya sisteminde okuma ve yazma işlemleri gerçekleştiren ve oluşturma, çoğaltma ve silme gibi blok işlemleri gerçekleştiren ikincil düğümlerdir.
- DataNode, depolanan dosyaların sağlama toplamlarını tutan meta veri dosyaları içerir. DataNode tarafından barındırılan her bir blok çoğaltması için, sağlama toplamı bilgileri de dahil olmak üzere çoğaltmayla ilgili meta verileri içeren karşılık gelen bir meta veri dosyası vardır. Meta veri dosyası, blok dosyasıyla aynı temel ada ve .meta uzantısına sahiptir.
- DataNode, bloğun verilerini tutan veri dosyasını içerir.
- DataNode bir dosyayı okuduğunda, NameNode'dan blok konumlarını ve çoğaltma konumlarını getirir ve en yakın konumdan okumaya çalışır.
- Bir HDFS kümesinde binlerce DataNodes ve küme başına on binlerce HDFS istemcisi olabilir. Her DataNode aynı anda birden çok uygulama görevi yürütebilir.
- DataNodes'a bir blok yazıldığında HDFS yazma işlem hattının bir parçası olarak uçtan uca sağlama toplamı hesaplaması gerçekleştirilir.
- HDFS İstemcisi , uygulamaların dosyalara erişmek için kullandığı istemcidir.
- HDFS dosya sistemi arabirimini dışarı aktaran bir kod kitaplığıdır.
- Dosyaları okuma, yazma ve silme işlemlerini ve dizin oluşturup silme işlemlerini destekler.
- Uygulama bir dosyayı okuduğunda aşağıdaki adımları gerçekleştirir:
- NameNode dosyasındaki DataNodes listesinden ve dosya bloklarını barındıran konumlardan alır. Liste, çoğaltmaları içerir.
- DataNodes'tan istenen blokları almak için listeyi kullanır.
- HDFS, dosya bloklarının konumlarını kullanıma sunan bir API sağlar. Bu, MapReduce çerçevesi gibi uygulamaların okuma performansını iyileştirmek için verilerin bulunduğu yerde çalışacak bir görev zamanlamasını sağlar.
Özellik haritası
Azure Blob Dosya Sistemi (ABFS) sürücüsü, Azure Data Lake Depolama'nin HDFS dosya sistemi olarak davranmasını mümkün kılan bir arabirim sağlar. Aşağıdaki tabloda ABFS sürücüsünün ve Data Lake Depolama temel işlevleri HDFS ile karşılaştırilmiştir.
| Özellik | ABFS sürücüsü ve Data Lake Depolama | HDFS |
|---|---|---|
| Hadoop ile uyumlu erişim | HdFS ile yaptığınız gibi verileri yönetebilir ve bu verilere erişebilirsiniz. ABFS sürücüsü, Azure HDInsight ve Azure Databricks dahil olmak üzere tüm Apache Hadoop ortamlarında kullanılabilir. | MapR kümesi, hdfs:// veya webhdfs:// protokolleriyle dış HDFS kümesine erişebilir |
| POSIX izinleri | Data Lake 2. Nesil güvenlik modeli, erişim denetim listesi (ACL) ve POSIX izinlerinin yanı sıra Data Lake Storage 2. Nesil özgü bazı ek ayrıntı düzeyini destekler. Ayarlar, Apache Hive ve Apache Spark gibi yönetim araçları veya çerçeveleri kullanılarak yapılandırılabilir. | Kesin olarak atomik dizin yeniden adlandırmaları, ayrıntılı HDFS izinleri veya HDFS ortak bağlantıları gibi dosya sistemi özellikleri gerektiren işler yalnızca HDFS üzerinde çalışabilir. |
| Maliyet uygunluğu | Data Lake Depolama düşük maliyetli depolama kapasitesi ve işlemler sunar. Azure Blob Depolama yaşam döngüleri, veriler yaşam döngüsü boyunca ilerledikçe faturalama oranlarını ayarlayarak maliyetleri düşürmeye yardımcı olur. | |
| İyileştirilmiş sürücü | ABFS sürücüsü büyük veri analizi için iyileştirilmiştir. Karşılık gelen REST API'leri dağıtılmış dosya sistemi (DFS) uç noktası dfs.core.windows.netaracılığıyla sağlanır. |
|
| Blok Boyutu | Bloklar tek bir Ekleme API'sine eşdeğerdir ( Ekleme API'si yeni bir blok oluşturur) ve çağrı başına 100 MB ile sınırlıdır. Ancak yazma deseni, Dosya başına çok kez (paralel olarak bile) en fazla 50.000'e kadar Append çağrısını ve ardından Flush çağrısını (PutBlockList'e eşdeğerdir) destekler. En fazla 4,75 TB dosya boyutuna bu şekilde ulaşılır. | HDFS, verileri bir veri bloğunda depolar. Hadoop dizinindeki hdfs-site.xml dosyasında bir değer ayarlayarak blok boyutunu ayarlarsınız. Varsayılan boyut 128 MB'tır. |
| Varsayılan ACL'ler | Dosyalar varsayılan ACL'lere sahip değildir ve varsayılan olarak etkinleştirilmez. | Dosyaların varsayılan ACL'leri yoktur. |
| İkili Dosyalar | İkili dosyalar hiyerarşik olmayan bir ad alanında Azure Blob Depolama taşınabilir. Blob Depolama nesnelere Azure Depolama REST API, Azure PowerShell, Azure CLI veya Azure Depolama istemci kitaplığı üzerinden erişilebilir. İstemci kitaplıkları .NET, Java, Node.js, Python, Go, PHP ve Ruby gibi farklı diller için kullanılabilir | Hadoop, ikili dosyaları okuma ve yazma olanağı sağlar. SequenceFile, ikili anahtar ve değer çiftlerinden oluşan düz bir dosyadır. SequenceFile yazma, okuma ve sıralama için Yazıcı, Okuyucu ve Sıralayıcı sınıfları sağlar. Görüntüyü veya video dosyasını SequenceFile'a dönüştürün ve HDFS'de depolayın. Ardından HDFS SequenceFileReader/Writer yöntemlerini veya put komutunu kullanın: bin/hadoop fs -put /src_image_file /dst_image_file |
| İzin devralma | Data Lake Depolama POSIX stili modeli kullanır ve ACL'ler bir nesneye erişimi denetlerse Hadoop ile aynı şekilde davranır. Daha fazla bilgi için bkz. Data Lake Storage 2. Nesil erişim denetim listeleri (ACL'ler). | Bir öğenin izinleri öğenin kendisinde depolanır, öğe var olduktan sonra devralınmaz. İzinler yalnızca alt öğe oluşturulmadan önce üst öğede varsayılan izinler ayarlandıysa devralınır. |
| Veri çoğaltma | Azure Depolama hesabındaki veriler birincil bölgede üç kez çoğaltılır. Alanlar arası yedekli depolama, önerilen çoğaltma seçeneğidir. Birincil bölgedeki üç Azure kullanılabilirlik alanında zaman uyumlu olarak çoğaltılır. | Varsayılan olarak bir dosyanın çoğaltma faktörü üç olur. Sık erişilen kritik dosyalar veya dosyalar için daha yüksek bir çoğaltma faktörü hataya dayanıklılığı artırır ve okuma bant genişliğini artırır. |
| Yapışkan bit | Data Lake Depolama bağlamında yapışkan bitin gerekli olması pek olası değildir. Kısaca, yapışkan bit bir dizinde etkinleştirildiyse, alt öğe yalnızca alt öğenin sahibi olan kullanıcı tarafından silinebilir veya yeniden adlandırılabilir. Yapışkan bit, Azure portalında gösterilmez. | Yapışkan bit, süper kullanıcı, dizin sahibi veya dosya sahibi dışında herkesin dizin içindeki dosyaları silmesini veya taşımasını önlemek için dizinlerde ayarlanabilir. Bir dosya için yapışkan biti ayarlamanın hiçbir etkisi yoktur. |
Şirket içi HDFS'nin yaygın zorlukları
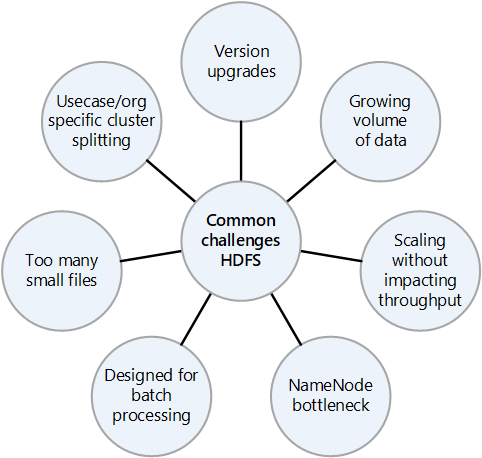
Şirket içi HDFS uygulaması tarafından sunulan birçok zorluk, buluta geçişin avantajlarını göz önünde bulundurmanın nedenleri olabilir:
- Sık karşılaşılan HDFS sürüm yükseltmeleri
- Artan veri miktarı
- Kümedeki tüm dosyaların meta verilerini denetleyen NameNode üzerindeki baskıyı artıran birçok küçük dosyaya sahip olma. Daha fazla dosya genellikle istemciler dosyaları okurken NameNode'da daha fazla okuma trafiği ve istemciler yazarken daha fazla çağrı anlamına gelir.
- Kuruluştaki birden çok ekip farklı veri kümeleri gerektiriyorsa, HDFS kümelerini kullanım örneğine veya kuruluşa göre bölmek mümkün değildir. Sonuç olarak, veri yinelemesi artar ve bu da maliyetleri artırır ve verimliliği azaltır.
- HDFS kümesinin ölçeği artırıldı veya genişletildikçe NameNode performans sorununa neden olabilir.
- Hadoop 2.0'den önce, bir HDFS kümesine yönelik tüm istemci istekleri önce NameNode'den geçer, çünkü tüm meta veriler tek bir NameNode içinde depolanır. Bu tasarım NameNode'un olası bir performans sorunu ve tek hata noktası olmasını sağlar. NameNode başarısız olursa küme kullanılamaz.
Geçiş fikirleri
HDFS'nin Data Lake Depolama'a geçişini planlarken göz önünde bulundurmanız gereken bazı önemli şeyler şunlardır:
- Küçük dosyalardaki verileri Data Lake Depolama'daki tek bir dosyada toplamayı göz önünde bulundurun.
- HDFS'deki tüm dizin yapılarını listeleyin ve Data Lake Depolama'da benzer bölgelendirmeyi çoğaltın. komutunu kullanarak
hdfs -lsHDFS'nin dizin yapısını elde edebilirsiniz. - HEDEF ortamda çoğaltabilmeniz için HDFS kümesinde tanımlanan tüm rolleri listeleyin.
- HDFS'de depolanan dosyaların veri yaşam döngüsü ilkesine dikkat edin.
- HDFS'nin bazı sistem özelliklerinin Data Lake Depolama'da kullanılamadığını unutmayın, örneğin:
- Dizinlerin kesinlikle atomik olarak yeniden adlandırılması
- Ayrıntılı HDFS izinleri
- HDFS bağlantıları
- Azure Depolama coğrafi olarak yedekli çoğaltmaya sahiptir, ancak bunu kullanmak her zaman akıllıca değildir. Veri yedekliliği ve coğrafi kurtarma sağlar, ancak daha uzak bir konuma yük devretme performansı ciddi ölçüde düşürebilir ve ek maliyetlere neden olabilir. Verilerin daha yüksek kullanılabilirliğinin buna değip değmeyeceğini göz önünde bulundurun.
- Dosyalar aynı ön eklere sahip adlara sahipse, HDFS bunları tek bir bölüm olarak ele alır. Bu nedenle, Azure Data Factory kullanıyorsanız, tüm veri taşıma birimleri (DKU' lar) tek bir bölüme yazar.
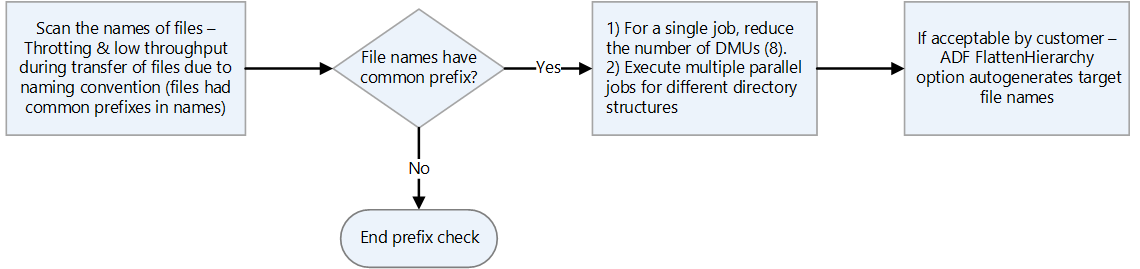
- Veri aktarımı için Data factory kullanıyorsanız, anlık görüntüleri hariç tutarak her dizinde tarama yapın ve komutunu kullanarak
hdfs dudizin boyutunu denetleyin. Birden çok alt dizin ve büyük miktarda veri varsa Data Factory'de birden çok kopyalama etkinliği başlatın. Örneğin, tek bir kopyalama etkinliği kullanarak dizinin tamamını aktarmak yerine alt dizin başına bir kopya kullanın.
- Veri platformları genellikle kayıt sistemlerinden kaldırılmış olabilecek bilgilerin daha uzun süreli saklaması için kullanılır. Arşivlenen verilerin bant yedeklerini veya anlık görüntülerini oluşturmayı planlamanız gerekir. Bilgileri bir kurtarma sitesine çoğaltmayı göz önünde bulundurun. Genellikle veriler uyumluluk veya geçmiş veri amacıyla arşivler. Verileri arşivlemeden önce, verileri saklamak için net bir nedeniniz olmalıdır. Ayrıca arşivlenen verilerin ne zaman kaldırılacağına karar verin ve bu verileri kaldırmak için işlemler oluşturun.
- Data Lake Depolama Arşiv erişim katmanının düşük maliyeti, verileri arşivleme için cazip bir seçenektir. Daha fazla bilgi için bkz . Arşiv erişim katmanı.
- HdFS istemcisi Blob Depolama erişmek için ABFS sürücüsünü kullandığında, istemci tarafından kullanılan yöntemin desteklenmediği ve AzureNativeFileSystem'ın DesteklenmeyenOperationException oluşturduğu örnekler olabilir. Örneğin,
append(Path f, int bufferSize, Progressable progress)şu anda desteklenmiyor. ABFS sürücüsüyle ilgili sorunları denetlemek için bkz . Hadoop özellikleri ve düzeltmeleri. - Eski Hadoop kümelerinde kullanılmak üzere ABFS sürücüsünün geri aktarılmış bir sürümü vardır. Daha fazla bilgi için bkz . ABFS Sürücüsü için Backport.
- Bir Azure sanal ağ ortamında DistCp aracı, Azure Depolama sanal ağ uç noktasıyla Azure ExpressRoute özel eşlemesini desteklemez. Daha fazla bilgi için bkz. Şirket içi Hadoop kümesindeki verileri Azure Depolama geçirmek için Azure Data Factory'yi kullanma.
Geçiş yaklaşımı
HDFS'yi Data Lake Depolama'a geçirmenin tipik yaklaşımı şu adımları kullanır:

HDFS değerlendirmesi
Şirket içi değerlendirme betikleri, Hangi iş yüklerinin Azure'a geçirilebileceğini ve verilerin tek seferde mi yoksa tek seferde bir parça mı geçirileceğini belirlemenize yardımcı olan bilgiler sağlar. Unravel gibi üçüncü taraf araçlar, ölçümleri sağlayabilir ve şirket içi HDFS'nin otomatik değerlendirmesini destekleyebilir. Planlama sırasında dikkate alınması gereken bazı önemli faktörler şunlardır:
- Veri hacmi
- İş etkisi
- Verilerin sahipliği
- İşleme karmaşıklığı
- Ayıklama, aktarma ve yükleme (ETL) karmaşıklığı
- Kişisel bilgiler (PII) ve diğer hassas veriler
Bu faktörlere bağlı olarak, kapalı kalma süresini ve iş kesintisini en aza indiren verileri Azure'a taşımak için bir plan formüle edebilirsiniz. Hassas veriler şirket içinde kalabilir. Geçmiş veriler artımlı yük taşımadan önce taşınabilir ve test edilebilir.
Aşağıdaki karar akışı, doğru bilgileri almak için çalıştırılacak ölçütlere ve komutlara karar vermenize yardımcı olur.

HDFS'den değerlendirme ölçümleri almaya yönelik HDFS komutları şunlardır:
Bir konumdaki tüm dizinleri listeleyin:
hdfs dfs -ls booksBir konumdaki tüm dosyaları yinelemeli olarak listeleyin:
hdfs dfs -ls -R booksHDFS dizininin ve dosyalarının boyutunu alın:
hadoop fs -du -s -h commandkomutu HDFS
hadoop fs -du -s -hdosyalarının ve dizininin boyutunu görüntüler. Hadoop dosya sistemi her dosyayı çoğaltdığından, dosyanın gerçek fiziksel boyutu, bir çoğaltmanın boyutuyla çarpılan dosya çoğaltmalarının sayısıdır.ACL'lerin etkinleştirilip etkinleştirilmediğini belirleyin. Bunu yapmak için değerini Hdfs-site.xml olarak alın
dfs.namenode.acls.enabled. Değeri bilmek, Azure Depolama hesabında erişim denetimini planlamaya yardımcı olur. Bu dosyanın içeriği hakkında bilgi için bkz . Varsayılan dosya ayarları.
Unravel gibi iş ortağı araçları, veri geçişlerini planlamak için değerlendirme raporları sağlar. Araçların şirket içi ortamda çalıştırılması veya rapor oluşturmak için Hadoop kümesine bağlanması gerekir.
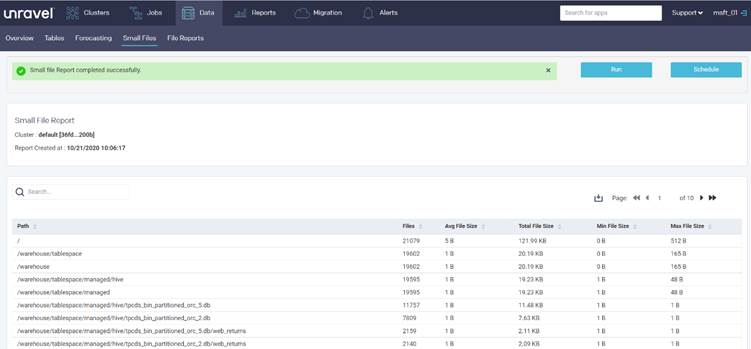
Aşağıdaki Unravel raporu, dizindeki küçük dosyalar hakkında dizin başına istatistikler sağlar:
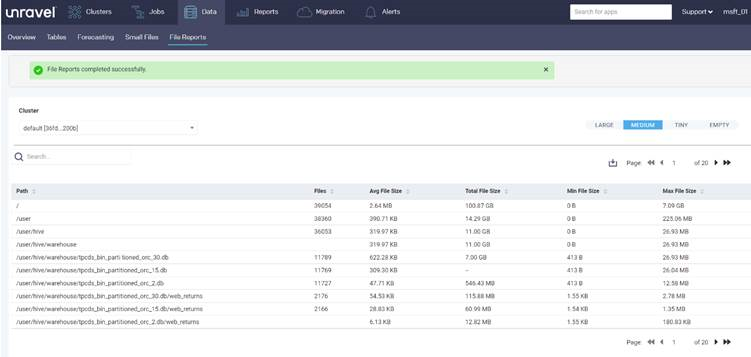
Aşağıdaki rapor, dizindeki dosyalar hakkında dizin başına istatistikler sağlar:
Veri aktarma
Verilerin, geçiş planınızda açıklandığı gibi Azure'a aktarılması gerekir. Aktarım için aşağıdaki etkinlikler gerekir:
Tüm alım noktalarını tanımlayın.
Güvenlik gereksinimleri nedeniyle veriler doğrudan buluta getirilemiyorsa, şirket içi bir ara giriş bölgesi olarak görev yapabilir. Verileri şirket içi sistemlerden çekmek için Data Factory'de işlem hatları oluşturabilir veya AZCopy betiklerini kullanarak verileri Azure Depolama hesabına gönderebilirsiniz.
Yaygın alım kaynakları şunlardır:
- SFTP sunucusu
- Dosya alımı
- Veritabanı alımı
- Veritabanı dökümü
- Değişiklik verilerini yakalama
- Akış alımı
Gereken depolama hesabı sayısını planlayın.
Gerekli depolama hesaplarının sayısını planlamak için geçerli HDFS üzerindeki toplam yükü anlayın. Tüm DataNode'lar genelinde geçerli eşzamanlı dosya erişimi sayısı olan TotalLoad ölçümünü kullanabilirsiniz. Bölgedeki depolama hesabı sınırını şirket içi TotalLoad değerine ve Azure'da beklenen büyümeye göre ayarlayın. Sınırı artırmak mümkünse tek bir depolama hesabı yeterli olabilir. Ancak bir veri gölü için, gelecekteki veri hacmi büyümesine hazırlanmak için her bölge için ayrı bir depolama hesabı tutmak en iyisidir. Ayrı bir depolama hesabı tutmanın diğer nedenleri şunlardır:
- Erişim denetimi
- Dayanıklılık gereksinimleri
- Veri çoğaltma gereksinimleri
- Verileri genel kullanım için kullanıma açma
Depolama hesabında hiyerarşik ad alanını etkinleştirdiğinizde, bunu düz bir ad alanına geri değiştiremezsiniz. Yedeklemeler ve VM görüntü dosyaları gibi iş yükleri hiyerarşik ad alanından hiçbir fayda sağlamaz.
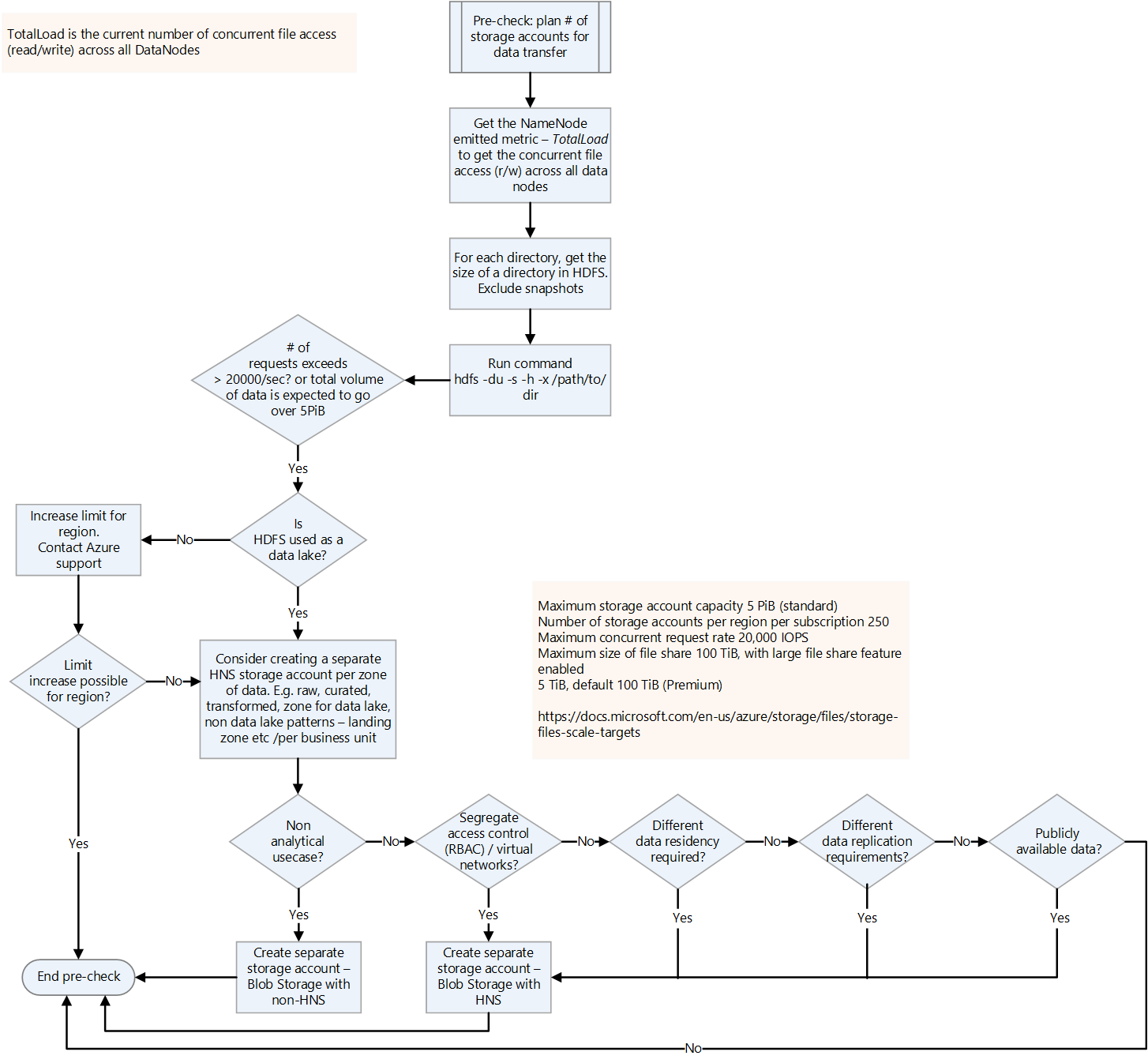
Özel bir bağlantı üzerinden sanal ağınızla depolama hesabınız arasındaki trafiğin güvenliğini sağlama hakkında bilgi için bkz. Depolama Hesaplarının Güvenliğini Sağlama.
Azure Depolama hesaplarının varsayılan sınırları hakkında bilgi için bkz. Standart depolama hesapları için ölçeklenebilirlik ve performans hedefleri. Giriş sınırı , depolama hesabına gönderilen veriler için geçerlidir. Çıkış sınırı , depolama hesabından alınan veriler için geçerlidir
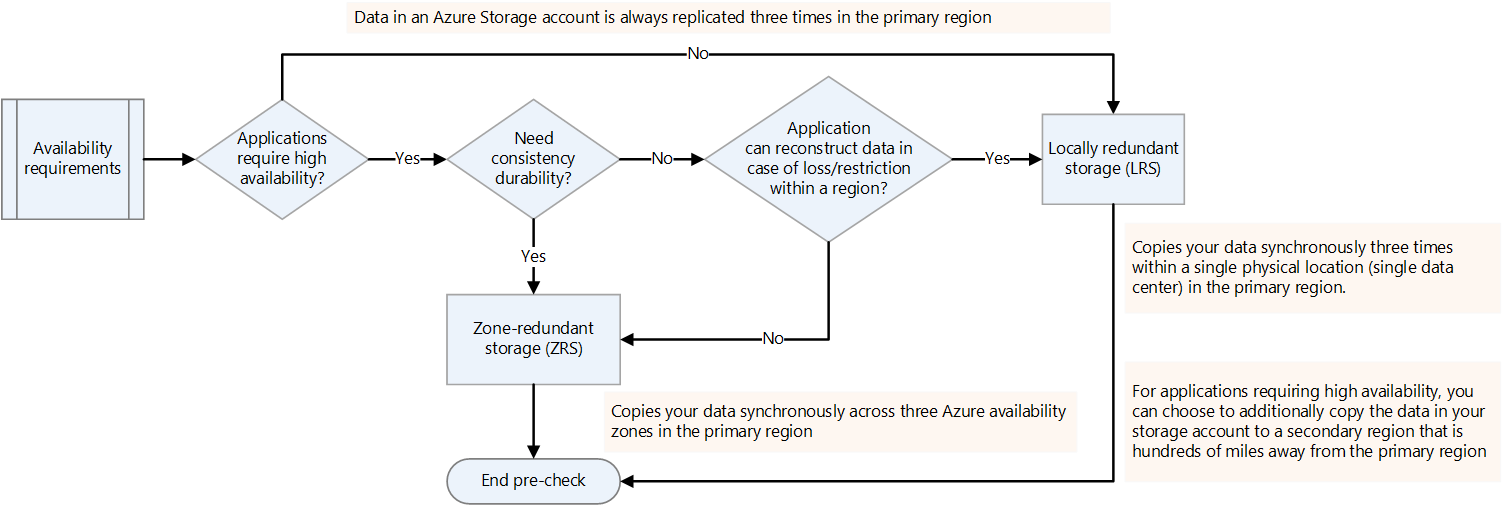
Kullanılabilirlik gereksinimlerine karar verin.
Hadoop platformları için çoğaltma faktörünü hdfs-site.xml veya dosya başına belirtebilirsiniz. Data Lake Depolama'da çoğaltmayı verilerin doğasına göre yapılandırabilirsiniz. Bir uygulama bir kayıp durumunda verilerin yeniden oluşturulmasını gerektiriyorsa, alanlar arası yedekli depolama (ZRS) bir seçenektir. Data Lake Depolama ZRS'de veriler, birincil bölgedeki üç kullanılabilirlik alanına zaman uyumlu olarak kopyalanır. Yüksek kullanılabilirlik gerektiren ve birden fazla bölgede çalışabilen uygulamalar için verileri ikincil bir bölgeye kopyalayın. Bu coğrafi olarak yedekli çoğaltmadır.
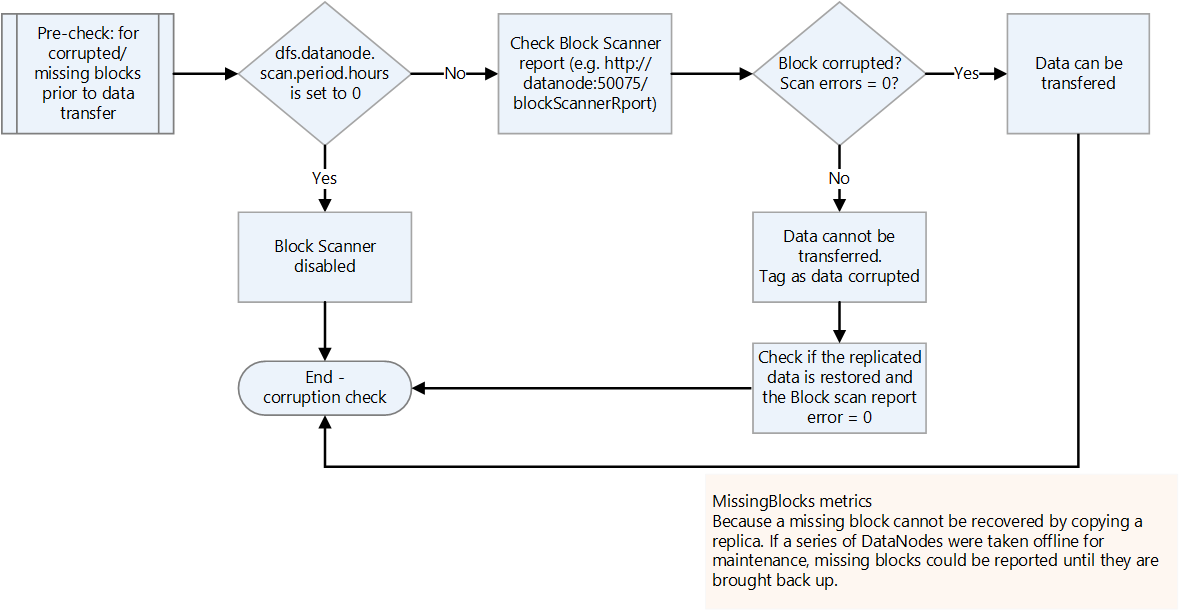
Bozuk veya eksik blokları denetleyin.
Bozuk veya eksik bloklar için blok tarayıcısı raporunu denetleyin. Varsa, aktarmadan önce dosyanın geri yüklenmesini bekleyin.
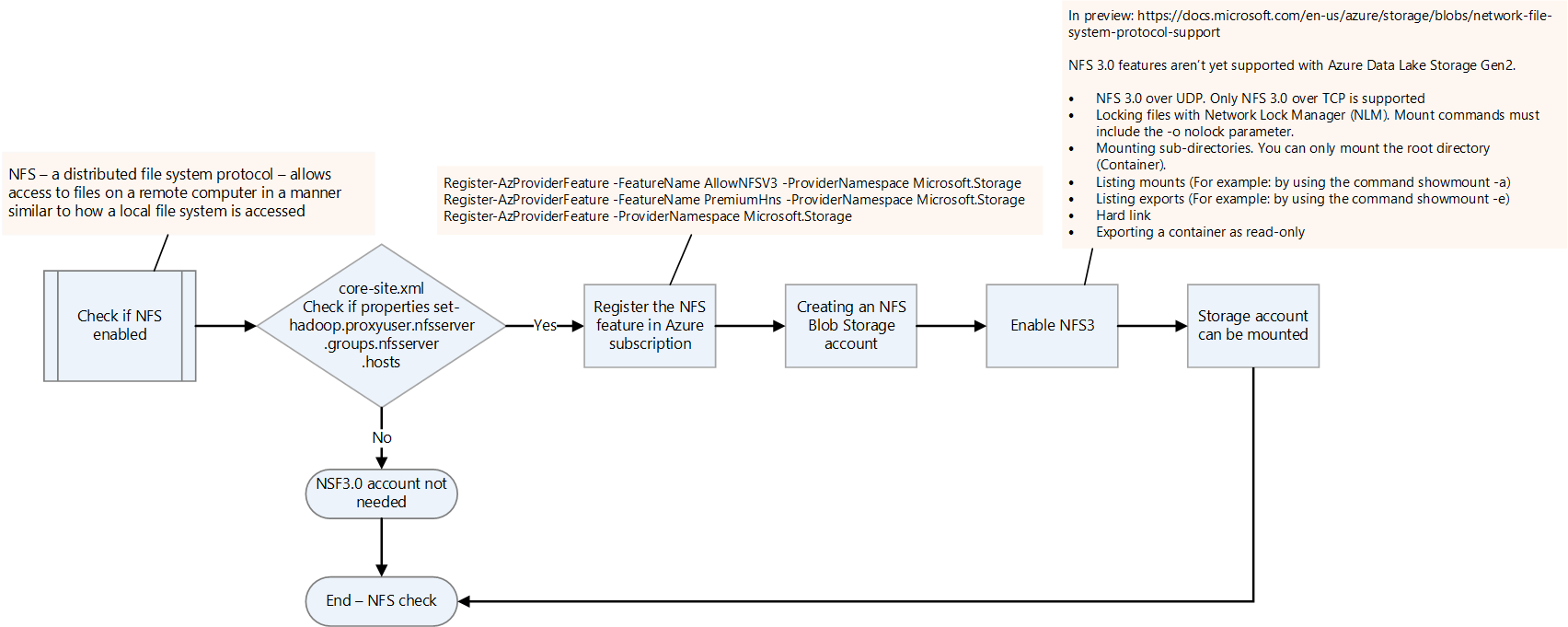
NFS'nin etkinleştirilip etkinleştirilmediğini denetleyin.
core-site.xml dosyasını denetleyerek şirket içi Hadoop platformunda NFS'nin etkinleştirilip etkinleştirilmediğini denetleyin. nfsserver.groups ve nfsserver.hosts özelliklerine sahiptir.
NFS 3.0 özelliği Data Lake Depolama'da önizleme aşamasındadır. Birkaç özellik henüz desteklenmeyebilir. Daha fazla bilgi için bkz. Azure Blob Depolama için Ağ Dosya Sistemi (NFS) 3.0 protokol desteği.
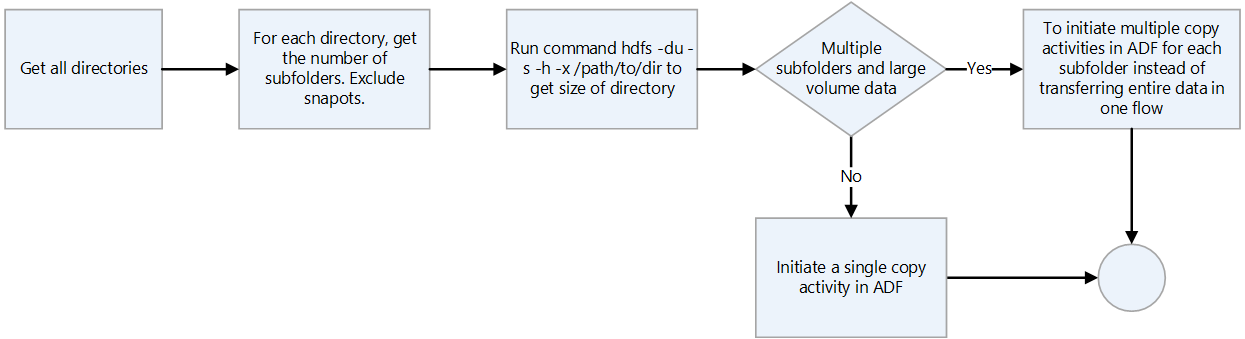
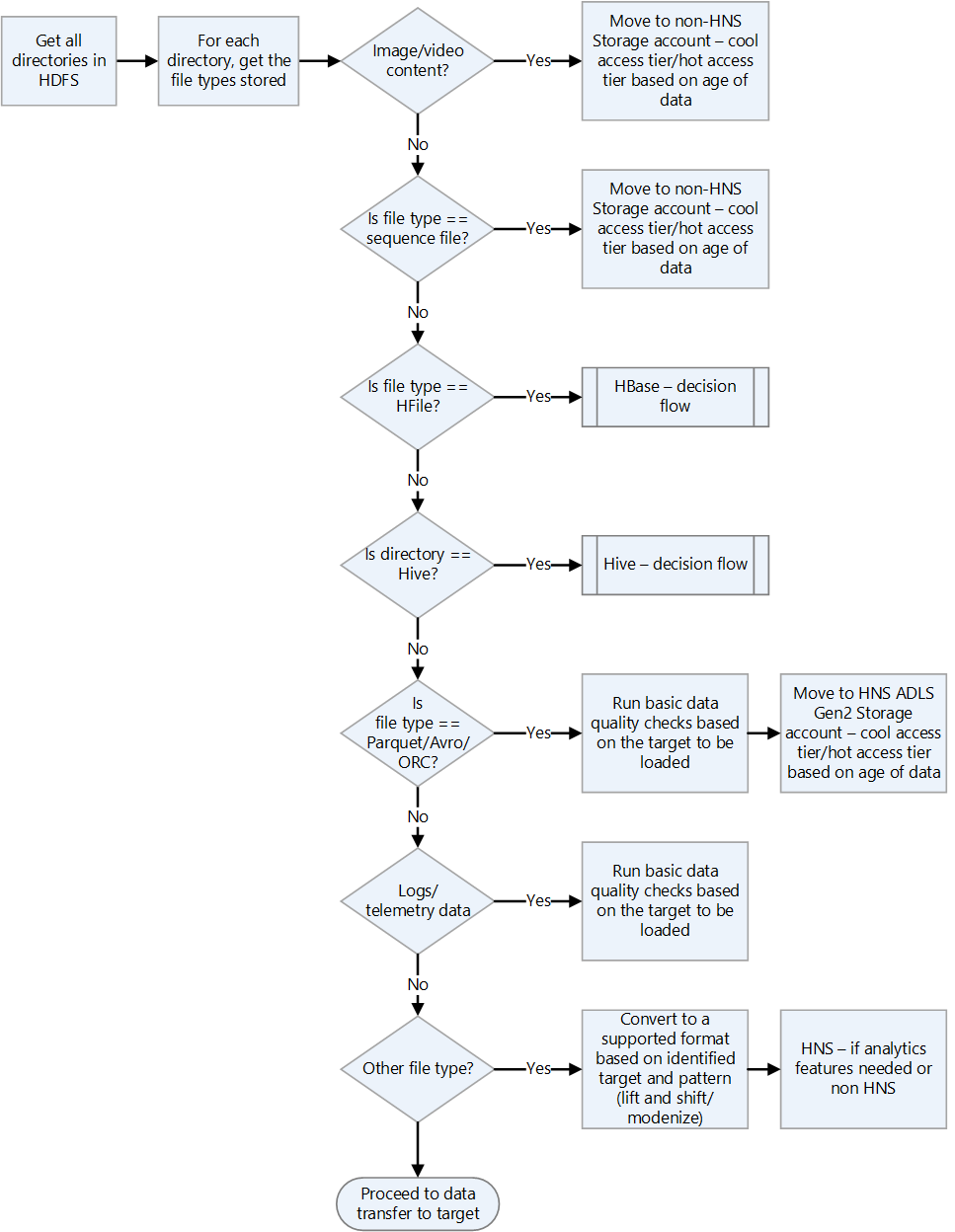
Hadoop dosya biçimlerini denetleyin.
Dosya biçimlerini işleme yönergeleri için aşağıdaki karar akış grafiğini kullanın.
Veri aktarımı için bir Azure çözümü seçin.
Veri aktarımı, fiziksel cihazlar kullanılarak ağ üzerinden çevrimiçi veya çevrimdışı olabilir. Hangi yöntemin kullanılacağı veri hacmine, ağ bant genişliğine ve veri aktarımının sıklığına bağlıdır. Geçmiş verilerin yalnızca bir kez aktarılması gerekir. Artımlı yüklemeler, sürekli tekrarlanan aktarımlar gerektirir.
Veri aktarım yöntemleri, aşağıdaki listede ele alınıyor. Veri aktarımı türlerini seçme hakkında daha fazla bilgi için bkz . Veri aktarımı için Azure çözümü seçme.
Azcopy
Azcopy, HDFS'den depolama hesabına dosya kopyalayabilen bir komut satırı yardımcı programıdır. Bu, yüksek bant genişliği aktarımları (1 GBPS'nin üzerinde) için bir seçenektir.
HdFS dizinini taşımak için örnek bir komut aşağıda verilmişti:
*azcopy copy "C:\local\path" "https://account.blob.core.windows.net/mycontainer1/?sv=2018-03-28&ss=bjqt&srt=sco&sp=rwddgcup&se=2019-05-01T05:01:17Z&st=2019-04-30T21:01:17Z&spr=https&sig=MGCXiyEzbtttkr3ewJIh2AR8KrghSy1DGM9ovN734bQF4%3D" --recursive=true*DistCp
DistCp , Hadoop kümesinde dağıtılmış kopyalama işlemleri yapabilen Hadoop'taki bir komut satırı yardımcı programıdır. DistCp, kaynaktan havuza veri kopyalamak için Hadoop kümesinde birkaç eşleme görevi oluşturur. Bu gönderme yaklaşımı, yeterli ağ bant genişliği olduğunda iyidir ve veri geçişi için ek işlem kaynaklarının sağlanmasını gerektirmez. Ancak, kaynak HDFS kümesinin kapasitesi zaten tükeniyorsa ve ek işlem eklenemediyse, dosyaları göndermek yerine çekmek için DistCp kopyalama etkinliğiyle Data Factory kullanmayı göz önünde bulundurun.
*hadoop distcp -D fs.azure.account.key.<account name>.blob.core.windows.net=<Key> wasb://<container>@<account>.blob.core.windows.net<path to wasb file> hdfs://<hdfs path>*Büyük veri aktarımları için Azure Data Box
Azure Data Box, Microsoft'tan sipariş edilen fiziksel bir cihazdır. Büyük ölçekli veri aktarımları sağlar ve ağ bant genişliği sınırlı olduğunda ve veri hacmi yüksek olduğunda (örneğin, birim birkaç terabayt ile petabayt arasında olduğunda) çevrimdışı veri aktarımı seçeneğidir.
Bir Data Box'ı LAN'a bağlayarak veri aktarırsınız. Ardından microsoft mühendisleri tarafından verilerin yapılandırılan depolama hesabına aktarıldığı Microsoft veri merkezine geri gönderirsiniz.
İşleyebilecekleri veri birimlerine göre farklılık gösteren birden çok Data Box seçeneği vardır. Data Box yaklaşımı hakkında daha fazla bilgi için bkz . Azure Data Box belgeleri - Çevrimdışı aktarım.
Data Factory
Data Factory, veri taşımayı ve veri dönüştürmeyi düzenleyen ve otomatik hale getiren veri odaklı iş akışları oluşturmaya yardımcı olan bir veri tümleştirme hizmetidir. Yeterli ağ bant genişliği olduğunda ve veri geçişlerini düzenleme ve izleme gereksinimi olduğunda bunu kullanabilirsiniz. Artımlı veriler şirket içi sisteme ilk atlama olarak ulaştığında ve güvenlik kısıtlamaları nedeniyle doğrudan Azure depolama hesabına aktarılamadığında Data Factory'yi düzenli olarak artımlı veri yüklemeleri için kullanabilirsiniz.
Çeşitli aktarım yaklaşımları hakkında daha fazla bilgi için bkz . Orta ve yüksek ağ bant genişliğine sahip büyük veri kümeleri için veri aktarımı.
HDFS'den veri kopyalamak için Data Factory kullanma hakkında bilgi için bkz . Azure Data Factory veya Synapse Analytics kullanarak HDFS sunucusundan veri kopyalama
WANdisco LiveData geçişi gibi iş ortağı çözümleri
Azure için WANdisco LiveData Platformu, Hadoop'tan Azure'a geçişler için Microsoft'un tercih ettiği çözümlerden biridir. Azure portalını ve Azure CLI'yi kullanarak özelliklerine erişebilirsiniz. Daha fazla bilgi için bkz . Azure için WANdisco LiveData Platformu ile Hadoop veri göllerinizi geçirme.
Katkıda Bulunanlar
Bu makale Microsoft tarafından yönetilir. Başlangıçta aşağıdaki katkıda bulunanlar tarafından yazılmıştır.
Asıl yazarlar:
- Namrata Maheshwary | Üst Düzey Bulut Çözümü Mimarı
- Raja N | Müdür, Müşteri Başarısı
- Hideo Takagi | Bulut Çözümü Mimarı
- Ram Yerrabotu | Üst Düzey Bulut Çözümü Mimarı
Diğer katkıda bulunanlar:
- Ram Başkaran | Üst Düzey Bulut Çözümü Mimarı
- Jason Bouska | Kıdemli Yazılım Mühendisi
- Eugene Chung | Üst Düzey Bulut Çözümü Mimarı
- Pawan Hosatti | Üst Düzey Bulut Çözümü Mimarı - Mühendislik
- Daman Kaur | Bulut Çözümü Mimarı
- Danny Liu | Üst Düzey Bulut Çözümü Mimarı - Mühendislik
- Jose Mendez Kıdemli Bulut Çözümü Mimarı
- Ben Sadeghi | Kıdemli Uzman
- Sunil Sattiraju | Üst Düzey Bulut Çözümü Mimarı
- Amanjeet Singh | Asıl Program Yöneticisi
- Nagaraj Seeplapudur Venkatesan | Üst Düzey Bulut Çözümü Mimarı - Mühendislik
Genel olmayan LinkedIn profillerini görmek için LinkedIn'de oturum açın.
Sonraki adımlar
Azure ürün tanıtımları
- Azure Data Lake Storage 2. Nesil'e giriş
- Azure HDInsight'taki Apache Spark nedir
- Azure HDInsight'ta Apache Hadoop nedir?
- Azure HDInsight'ta Apache HBase nedir?
- Azure HDInsight'ta Apache Kafka nedir?
Azure ürün başvurusu
- Microsoft Entra belgeleri
- Azure Cosmos DB belgeleri
- Azure Data Factory belgeleri
- Azure Databricks belgeleri
- Azure Event Hubs belgeleri
- Azure İşlevleri belgeleri
- Azure HDInsight belgeleri
- Microsoft Purview veri idaresi belgeleri
- Azure Stream Analytics belgeleri
- Azure Synapse Analytics
Diğer
- Azure HDInsight için Kurumsal Güvenlik Paketi
- HDInsight üzerinde Apache Hadoop için Java MapReduce programları geliştirme
- HDInsight'ta Hadoop ile Apache Sqoop'u kullanma
- Apache Spark Akışına Genel Bakış
- Yapılandırılmış Akış öğreticisi
- Apache Kafka uygulamalarından Azure Event Hubs kullanma