Apache Sqoop, Apache Hadoop kümeleri ve ilişkisel veritabanları arasında veri aktarımına yönelik bir araçtır. Komut satırı arabirimi vardır.
MySQL, PostgreSQL, Oracle ve SQL Server gibi ilişkisel veritabanlarından HDFS'ye veri aktarmak ve HDFS verilerini bu veritabanlarına aktarmak için Sqoop'u kullanabilirsiniz. Sqoop, Hadoop'ta verileri dönüştürmek için MapReduce ve Apache Hive kullanabilir. Gelişmiş özellikler artımlı yüklemeyi, SQL kullanarak biçimlendirmeyi ve veri kümelerini güncelleştirmeyi içerir. Sqoop, yüksek hızlı veri aktarımına ulaşmak için paralel olarak çalışır.
Not
Sqoop projesi kullanımdan kaldırıldı. Sqoop, Haziran 2021'de Apache Attic'e taşındı. Web sitesi, indirmeler ve sorun izleyicilerinin tümü açık kalır. Daha fazla bilgi için bkz . Apache Attic'teki Apache Sqoop.
Apache, Apache Spark®, Apache Hadoop®, Apache HBase, Apache Hive, Apache Ranger®, Apache Storm®, Apache Sqoop®, Apache Kafka® ve alev logosu Apache Software Foundation'ın Birleşik Devletler ve/veya diğer ülkelerdeki kayıtlı ticari markaları veya ticari markalarıdır.® Bu işaretlerin kullanılması Apache Software Foundation tarafından onaylanmamaktadır.
Sqoop mimarisi ve bileşenleri
Sqoop'un iki sürümü vardır: Sqoop1 ve Sqoop2. Sqoop1 basit bir istemci aracıdır, Sqoop2 ise bir istemci/sunucu mimarisine sahiptir. Bunlar birbiriyle uyumlu değildir ve kullanım açısından farklılık gösterir. Sqoop2 özellik tamamlamaz ve üretim dağıtımı için tasarlanmamıştır.
Sqoop1 mimarisi
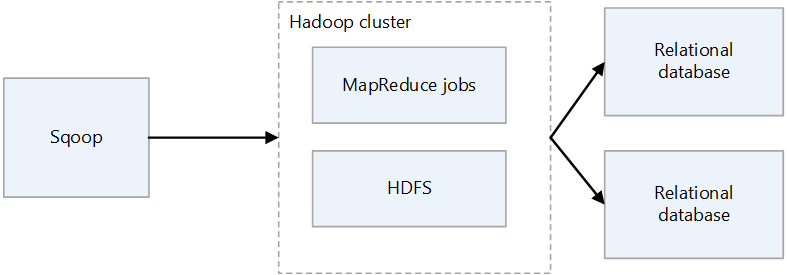
Sqoop1 içeri ve dışarı aktarma
İçeri Aktar
İlişkisel veritabanlarından verileri okur ve VERILERI HDFS'ye aktarır. İlişkisel veritabanları tablosundaki her kayıt, HDFS'de tek bir satır olarak çıkıştır. Text, SequenceFiles ve Avro, HDFS'ye yazılabilir dosya biçimleridir.
Dışarı aktarma
HDFS'den verileri okur ve ilişkisel veritabanlarına aktarır. Hedef ilişkisel veritabanları hem ekleme hem de güncelleştirmeyi destekler.
Sqoop2 mimarisi
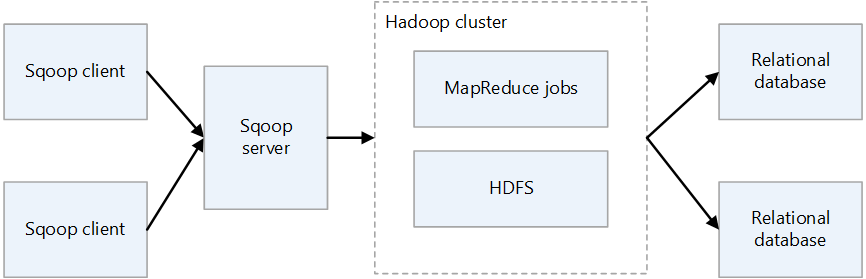
Sqoop sunucusu
Sqoop istemcileri için bir giriş noktası sağlar.
Sqoop istemcisi
Sqoop sunucusuyla etkileşim kurar. İstemcinin sunucuyla iletişim kurabilmesi koşuluyla, istemci herhangi bir düğümde olabilir. İstemcinin yalnızca sunucuyla iletişim kurması gerektiğinden, MapReduce ile yaptığınız gibi ayarları yapmanıza gerek yoktur.
Şirket içi Sqoop'un zorlukları
Şirket içi Sqoop dağıtımının bazı yaygın zorlukları şunlardır:
- Donanıma ve veri merkezi kapasitesine bağlı olarak ölçeklendirmek zor olabilir.
- İsteğe bağlı olarak kolayca ölçeklendirilemez.
- Eskiyen altyapı desteği sona erdiğinde, değiştirmek ve yükseltmek zorunda kalabilirsiniz.
- Sağlayabilecek yerel araçlar yoktur:
- Maliyet şeffaflığı
- İzleme
- DevOps
- Otomasyon
Dikkat edilmesi gereken noktalar
- Sqoop'ı Azure'a geçirirken veri kaynağınız şirket içinde kalıyorsa bağlantısını göz önünde bulundurmanız gerekir. Azure ile mevcut şirket içi ağınız arasında İnternet üzerinden bir VPN bağlantısı kurabilir veya özel bağlantı oluşturmak için Azure ExpressRoute'u kullanabilirsiniz.
- Sqoop'u Azure HDInsight'a geçirirken Sqoop sürümünüzü göz önünde bulundurun. HDInsight yalnızca Sqoop1'i destekler. Bu nedenle şirket içi ortamınızda Sqoop2 kullanıyorsanız hdInsight'ta Sqoop1 ile değiştirmeniz veya Sqoop2'yi bağımsız tutmanız gerekir.
- Sqoop'ı Azure Data Factory'ye geçirirken veri dosyası biçimlerini göz önünde bulundurmanız gerekir. Data Factory, SequenceFile biçimini desteklemez. Sqoop uygulamanız verileri SequenceFile biçiminde içeri aktarıyorsa destek eksikliği sorun olabilir. Daha fazla bilgi için bkz . Dosya biçimi.
Geçiş yaklaşımı
Azure'da Apache Sqoop için çeşitli geçiş hedefleri vardır. Gereksinimlere ve ürün özelliklerine bağlı olarak Azure IaaS sanal makineleri (VM), Azure HDInsight ve Azure Data Factory arasında seçim yapabilirsiniz.
Geçiş hedefi seçmeye yönelik bir karar grafiği aşağıdadır:
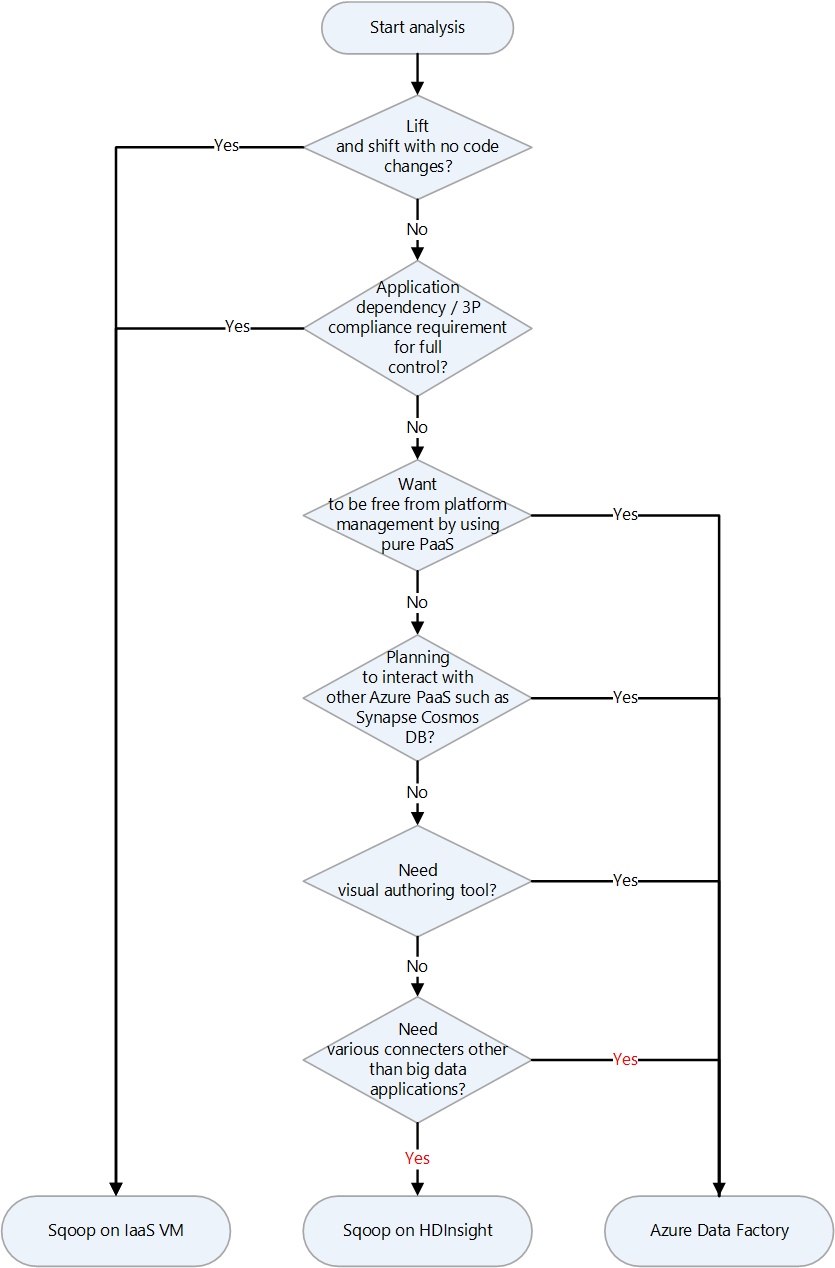
Geçiş hedefleri aşağıdaki bölümlerde açıklanmıştır:
Azure IaaS'ye lift and shift geçişi
Şirket içi Sqoop'unuzun geçiş hedefi olarak Azure IaaS VM'lerini seçerseniz, lift and shift geçişi yapabilirsiniz. Tamamen denetlenebilir bir ortam oluşturmak için Sqoop'un aynı sürümünü kullanırsınız. Bu nedenle, Sqoop yazılımında herhangi bir değişiklik yapmanız gerekmez. Sqoop bir Hadoop kümesiyle çalışır ve genellikle hadoop kümesiyle birlikte geçirilir. Aşağıdaki makaleler, Hadoop kümesinin lift and shift geçişi için kılavuzlardır. Geçirilecek hizmet için geçerli olan makaleyi seçin.
Geçiş hazırlığı
Geçişe hazırlanmak için, geçişi planlıyor ve bir ağ bağlantısı kuruyorsunuz.
Geçiş planı
Şirket içi Sqoop'unuzun geçişine hazırlanmak için aşağıdaki bilgileri toplayın. Bilgiler, hedef sanal makinenin boyutunu belirlemenize ve yazılım bileşenlerini ve ağ yapılandırmalarını planlamanıza yardımcı olur.
| Kalem | Background |
|---|---|
| Geçerli konak boyutu | Sqoop istemcisinin veya sunucusunun üzerinde çalıştığı konak veya sanal makinenin CPU, bellek, disk ve diğer bileşenleri hakkında bilgi edinin. Bu bilgileri, Azure sanal makineniz için gereken temel boyutu tahmin etmek için kullanırsınız. |
| Konak ve uygulama ölçümleri | Sqoop istemcisini çalıştıran makinenin kaynak kullanım bilgilerini (CPU, bellek, disk ve diğer bileşenler) alın ve gerçekte kullanılan kaynakları tahmin edin. Konağınıza ayrılan kaynaklardan daha az kaynak kullanıyorsanız Azure'a geçiş yaparken küçültmeyi göz önünde bulundurun. Gerekli kaynak miktarını belirledikten sonra, Azure sanal makine boyutuna başvurarak geçiş için sanal makine türünü seçin. |
| Sqoop sürümü | Azure sanal makinesine hangi Sqoop sürümünün yükleneceğini belirlemek için şirket içi Sqoop sürümünü denetleyin. Cloudera veya Hortonworks gibi bir dağıtım kullanıyorsanız, bileşenin sürümü bu dağıtımın sürümüne bağlıdır. |
| İşleri ve betikleri çalıştırma | Sqoop çalıştıran işleri ve bunları zamanlama yöntemlerini belirleyin. İşler ve yöntemler geçiş için adaydır. |
| Bağlanacak veritabanları | Sqoop işlerindeki içeri ve dışarı aktarma komutları tarafından belirtildiği gibi Sqoop'un bağlandığı veritabanlarını tanımlayın. Bunları tanımladıktan sonra Sqoop'u Azure sanal makinelerinize geçirdikten sonra bu veritabanlarına bağlanıp bağlanamadığını görmeniz gerekir. Bağlandığınız veritabanlarından bazıları hala şirket içindeyse, şirket içi ile Azure arasında bir ağ bağlantısına ihtiyacınız vardır. Daha fazla bilgi için Ağ bağlantısı oluşturma bölümüne bakın. |
| Eklentiler | Kullandığınız Sqoop eklentilerini belirleyin ve geçirip geçiremeyeceğinizi belirleyin. |
| Yüksek kullanılabilirlik, iş sürekliliği, olağanüstü durum kurtarma | Şirket içinde kullandığınız sorun giderme tekniklerinin Azure'da kullanılıp kullanılamayacağını belirleyin. Örneğin, iki düğümde etkin/bekleme yapılandırmasına sahipseniz, aynı yapılandırmaya sahip Sqoop istemcileri için iki Azure sanal makinesi hazırlayın. Olağanüstü durum kurtarma yapılandırırken de aynı durum geçerlidir. |
Ağ bağlantısı kurma
Bağlandığınız veritabanlarından bazıları şirket içinde kalıyorsa, şirket içi ile Azure arasında bir ağ bağlantısına ihtiyacınız vardır.
Şirket içi ve Azure'ı özel bir ağda bağlamak için iki ana seçenek vardır:
VPN Gateway
Azure SANAL Ağ Geçidi'ni kullanarak Azure sanal ağınızla şirket içi konumunuz arasında genel İnternet üzerinden şifrelenmiş trafik gönderebilirsiniz. Bu teknik ucuzdur ve kurulumu kolaydır. Ancak, İnternet üzerinden şifrelenmiş bağlantı nedeniyle iletişim bant genişliği garanti değildir. Bant genişliğini garanti etmeniz gerekiyorsa ikinci seçenek olan ExpressRoute'u seçmeniz gerekir. VPN seçeneği hakkında daha fazla bilgi için bkz . VPN Gateway nedir? ve VPN Gateway tasarımı.
ExpressRoute
ExpressRoute, bir bağlantı sağlayıcısı tarafından sağlanan özel bir bağlantı kullanarak şirket içi ağınızı Azure'a veya Microsoft 365'e bağlayabilir. ExpressRoute genel İnternet üzerinden gitmez, bu nedenle daha güvenli, daha güvenilirdir ve İnternet üzerinden yapılan bağlantılardan daha tutarlı gecikme sürelerine sahiptir. Buna ek olarak, satın aldığınız satırın bant genişliği seçenekleri kararlı gecikme sürelerini garanti edebilir. Daha fazla bilgi için bkz . Azure ExpressRoute nedir?.
Bu özel bağlantı yöntemleri gereksinimlerinizi karşılamıyorsa Azure Data Factory'yi geçiş hedefi olarak düşünün. Data Factory'de şirket içinde barındırılan tümleştirme çalışma zamanı, özel ağ yapılandırmanıza gerek kalmadan şirket içinden Azure'a veri aktarmanızı mümkün kılar.
Verileri ve ayarları geçirme
Şirket içi Sqoop'ı Azure sanal makinelerine geçirirken aşağıdaki verileri ve ayarları ekleyin:
Sqoop yapılandırma dosyaları: Ortamınıza bağlıdır, ancak genellikle aşağıdaki dosyalar dahil edilir:
sqoop-site.xmlsqoop-env.xmlpassword-fileoraoop-site.xml, Oraoop kullanıyorsanız
Kaydedilen işler: Sqoop meta veri deposundaki işleri komutunu kullanarak
sqoop job --createkaydettiyseniz, bunları geçirmeniz gerekir. Meta veri deposunun kaydetme hedefi sqoop-site.xml tanımlanır. Paylaşılan meta veri deposu ayarlı değilse, meta veri deposu çalıştıran kullanıcının giriş dizininin .sqoop alt dizininde kayıtlı işleri arayın.Kaydedilen işler hakkındaki bilgileri görmek için aşağıdaki komutları kullanabilirsiniz.
Kaydedilen iş listesini alın:
sqoop job --listKaydedilen işler için parametreleri görüntüleme
sqoop job --show <job-id>
Betikler: Sqoop çalıştıran betik dosyalarınız varsa bunları geçirmeniz gerekir.
Zamanlayıcı: Sqoop'un yürütülmesini zamanlarsanız Linux cron işi veya iş yönetimi aracı gibi zamanlayıcısını tanımlamanız gerekir. Ardından zamanlayıcının Azure'a geçirilip geçirilemeyeceğini düşünmeniz gerekir.
Eklentiler: Sqoop'ta dış veritabanına bağlayıcı gibi özel eklentiler kullanıyorsanız bunları geçirmeniz gerekir. Bir düzeltme eki dosyası oluşturduysanız, geçirilen Sqoop'a düzeltme ekini uygulayın.
HDInsight'a geçiş
HDInsight, Apache Hadoop bileşenlerini ve HDInsight platformunu bir kümeye dağıtılan bir pakette paketler. Sqoop'un kendisini Azure'a geçirmek yerine HDInsight kümesinde Sqoop çalıştırmak daha normaldir. Hadoop ve Spark gibi açık kaynak çerçeveleri çalıştırmak için HDInsight kullanma hakkında daha fazla bilgi için bkz . Azure HDInsight nedir? ve Büyük Veri İş Yüklerini Azure HDInsight'a Geçirme Kılavuzu.
HDInsight'taki bileşen sürümleri için aşağıdaki makalelere bakın.
Data Factory'ye geçiş
Azure Data Factory tam olarak yönetilen, sunucusuz bir veri tümleştirme hizmetidir. Veri hacmi gibi faktörlere göre isteğe bağlı olarak ölçeklendirilebilir. Python, .NET ve Azure Resource Manager şablonlarını (ARM şablonları) kullanarak sezgisel düzenleme ve geliştirme için bir GUI'ye sahiptir.
Veri kaynaklarına bağlantı
Standart Sqoop bağlayıcılarının listesi için uygun makaleye bakın:
Data Factory'nin çok sayıda bağlayıcısı vardır. Daha fazla bilgi için bkz . Azure Data Factory ve Azure Synapse Analytics bağlayıcıya genel bakış.
Aşağıdaki tablo, Sqoop1 sürüm 1.4.7 ve Sqoop2 sürüm 1.99.7 için kullanılacak Data Factory bağlayıcılarını gösteren bir örnektir. Desteklenen sürümlerin listesi değişebileceğinden en son belgelere başvurabilirsiniz.
| Sqoop1 - 1.4.7 | Sqoop2 - 1.99.7 | Data Factory | Dikkat edilmesi gereken noktalar |
|---|---|---|---|
| MySQL JDBC Bağlayıcısı | Genel JDBC Bağlayıcısı | MySQL, MySQL için Azure Veritabanı | |
| MySQL Doğrudan Bağlayıcısı | Yok | Yok | Doğrudan Bağlayıcı, JDBC'ye gitmeden verileri giriş ve çıkış yapmak için mysqldump kullanır. Yöntemi Data Factory'de farklıdır, ancak bunun yerine MySQL bağlayıcısı kullanılabilir. |
| Microsoft SQL Bağlayıcısı | Genel JDBC Bağlayıcısı | SQL Server, Azure SQL Veritabanı Azure SQL Yönetilen Örneği | |
| PostgreSQL Bağlayıcısı | PostgreSQL, Genel JDBC Bağlayıcısı | PostgreSQL için Azure Veritabanı | |
| PostgreSQL Doğrudan Bağlayıcısı | Yok | Yok | Doğrudan Bağlayıcı JDBC üzerinden gitmez ve verileri girmek ve çıktısını almak için COPY komutunu kullanır. Data Factory'de yöntemi farklıdır, ancak bunun yerine PostgreSQL bağlayıcısı kullanılabilir. |
| pg_bulkload bağlayıcısı | Yok | Yok | pg_bulkload kullanarak PostgreSQL'e yükleyin. Data Factory'de yöntemi farklıdır, ancak bunun yerine PostgreSQL bağlayıcısı kullanılabilir. |
| Netezza Bağlayıcısı | Genel JDBC Bağlayıcısı | Netteza | |
| Oracle ve Hadoop için Veri Bağlayıcısı | Genel JDBC Bağlayıcısı | Oracle | |
| Yok | FTP Bağlayıcısı | FTP | |
| Yok | SFTP Bağlayıcısı | SFTP | |
| Yok | Kafka Bağlayıcısı | Yok | Data Factory doğrudan Kafka'ya bağlanamıyor. Kafka'ya bağlanmak için Azure Databricks veya HDInsight gibi Spark Akışlarını kullanmayı göz önünde bulundurun. |
| Yok | Uçurtma Bağlayıcısı | Yok | Data Factory doğrudan Uçurtma'ya bağlanamıyor. |
| HDFS | HDFS | HDFS | Data Factory, HDFS'yi kaynak olarak destekler, ancak havuz olarak desteklemez. |
Şirket içi veritabanlarına bağlanma
Sqoop'ı Data Factory'ye geçirdikten sonra da şirket içi ağınızdaki ve Azure'daki bir veri deposu arasında veri kopyalamanız gerekiyorsa şu yöntemleri kullanmayı göz önünde bulundurun:
Şirket içinde barındırılan integration runtime
Verileri genel bulut ortamından doğrudan iletişim yolunun olmadığı bir özel ağ ortamında tümleştirmeye çalışıyorsanız, güvenliği geliştirmek için aşağıdakileri yapabilirsiniz:
- Şirket içi ortamda, iç güvenlik duvarında veya sanal özel ağda şirket içinde barındırılan bir tümleştirme çalışma zamanı yükleyin.
- Veri taşıma için bir bağlantı kurmak için şirket içinde barındırılan tümleştirme çalışma zamanından Azure'a HTTPS tabanlı bir giden bağlantı oluşturun.
Şirket içinde barındırılan tümleştirme çalışma zamanı yalnızca Windows'ta desteklenir. Ayrıca, birden çok makineye şirket içinde barındırılan tümleştirme çalışma zamanlarını yükleyip ilişkilendirerek ölçeklenebilirlik ve yüksek kullanılabilirlik elde edebilirsiniz. Şirket içinde barındırılan tümleştirme çalışma zamanı, şirket içinde veya Azure sanal ağında olmayan kaynaklara veri dönüştürme etkinlikleri göndermekle de sorumludur.
Şirket içinde barındırılan tümleştirme çalışma zamanını ayarlama hakkında bilgi için bkz . Şirket içinde barındırılan tümleştirme çalışma zamanı oluşturma ve yapılandırma.
Özel uç nokta kullanarak yönetilen sanal ağ
Şirket içi ile Azure (ExpressRoute veya VPN Gateway gibi) arasında özel bir bağlantınız varsa, şirket içi veritabanlarınıza özel bağlantı oluşturmak için Data Factory'de yönetilen sanal ağı ve özel uç noktayı kullanabilirsiniz. İnternet'e gitmeden şirket içi kaynaklarınıza erişmek için aşağıdaki diyagramda gösterildiği gibi trafiği şirket içi kaynaklarınıza iletmek için sanal ağları kullanabilirsiniz.

Bu mimarinin bir Visio dosyasını indirin.
Daha fazla bilgi için bkz . Öğretici: Özel Uç Nokta kullanarak Data Factory Yönetilen Sanal Ağından şirket içi SQL Server'a erişme.
Ağ seçenekleri
Data Factory'nin iki ağ seçeneği vardır:
Her ikisi de özel bir ağ oluşturur ve veri tümleştirme işleminin güvenliğini sağlamaya yardımcı olur. Aynı anda kullanılabilirler.
Yönetilen sanal ağ
Data Factory çalışma zamanı olan tümleştirme çalışma zamanını yönetilen bir sanal ağ içinde dağıtabilirsiniz. Yönetilen sanal ağa bağlanan bir veri deposu gibi özel bir uç nokta dağıtarak, kapalı bir özel ağ içinde veri tümleştirme güvenliğini geliştirebilirsiniz.

Bu mimarinin bir Visio dosyasını indirin.
Daha fazla bilgi için bkz . Azure Data Factory yönetilen sanal ağı.
Özel bağlantı
Data Factory'ye bağlanmak için Azure Data Factory için Azure Özel Bağlantı kullanabilirsiniz.

Bu mimarinin bir Visio dosyasını indirin.
Daha fazla bilgi için bkz. Özel uç nokta nedir? ve Özel Bağlantı belgeleri.
Veri kopyalama performansı
Sqoop, paralel işleme için MapReduce kullanarak veri aktarımı performansını geliştirir. Sqoop'ı geçirdikten sonra Data Factory, büyük ölçekli veri geçişleri gerçekleştiren senaryolar için performansı ve ölçeklenebilirliği ayarlayabilir.
Veri tümleştirme birimi (DIU), Data Factory performans birimidir. CPU, bellek ve ağ kaynağı ayırmanın bir birleşimidir. Data Factory, Azure tümleştirme çalışma zamanını kullanan kopyalama etkinlikleri için en fazla 256 DIU ayarlayabilir. Daha fazla bilgi için bkz. Veri Entegrasyonu Birimleri.
Şirket içinde barındırılan tümleştirme çalışma zamanı kullanıyorsanız, şirket içinde barındırılan tümleştirme çalışma zamanını barındıran makineyi ölçeklendirerek performansı geliştirebilirsiniz. Ölçeği genişletme üst sınırı dört düğümdür.
İstediğiniz performansı elde etmek için ayarlamalar yapma hakkında daha fazla bilgi için Kopyalama etkinliği performans ve ölçeklenebilirlik kılavuzuna bakın.
SQL uygulama
Sqoop, bu örnekte gösterildiği gibi bir SQL sorgusunun sonuç kümesini içeri aktarabilir:
$ sqoop import \
--query 'SELECT a.*, b.* FROM a JOIN b on (a.id == b.id) WHERE $CONDITIONS' \
--split-by a.id --target-dir /user/foo/joinresults
Data Factory ayrıca veritabanını sorgulayabilir ve sonuç kümesini kopyalayabilir:
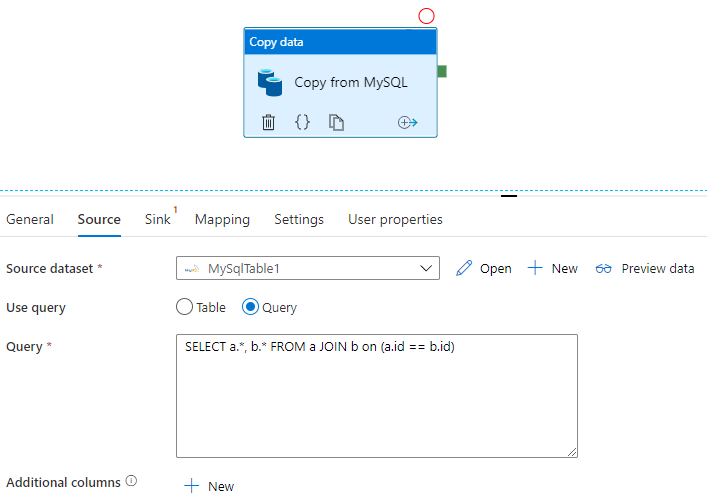
MySQL veritabanındaki sorgunun sonuç kümesini alan bir örnek için bkz. Kopyalama etkinliği özellikleri.
Veri dönüştürme
Hem Data Factory hem de HDInsight çeşitli veri dönüştürme etkinlikleri gerçekleştirebilir.
Data Factory etkinliklerini kullanarak verileri dönüştürme
Data Factory, veri akışı ve veri düzenleme gibi çeşitli veri dönüştürme etkinlikleri gerçekleştirebilir. Her ikisi için de, bir görsel kullanıcı arabirimi kullanarak dönüştürmeleri tanımlarsınız. HDInsight, Databricks, saklı yordamlar ve diğer özel etkinliklerin çeşitli Hadoop bileşenlerinin etkinliklerini de kullanabilirsiniz. Sqoop'ı geçirirken ve sürece veri dönüştürmeleri eklemek istediğinizde bu etkinlikleri kullanmayı göz önünde bulundurun. Daha fazla bilgi için bkz . Azure Data Factory'de verileri dönüştürme.
HDInsight etkinliklerini kullanarak verileri dönüştürme
Bir Azure Data Factory işlem hattındaki Hive, Pig, MapReduce, Streaming ve Spark gibi çeşitli HDInsight etkinlikleri kendi kümenizde veya isteğe bağlı bir HDInsight kümesinde program ve sorgu çalıştırabilir. Hadoop ekosisteminin veri dönüştürme mantığını kullanan bir Sqoop uygulamasını geçirirseniz, dönüştürmeleri HDInsight etkinliklerine geçirmek kolaydır. Ayrıntılar için aşağıdaki makalelere bakın.
- Azure Data Factory veya Synapse Analytics'te Hadoop Hive etkinliğini kullanarak verileri dönüştürme
- Azure Data Factory veya Synapse Analytics'te Hadoop MapReduce etkinliğini kullanarak verileri dönüştürme
- Azure Data Factory veya Synapse Analytics'te Hadoop Pig etkinliğini kullanarak verileri dönüştürme
- Azure Data Factory ve Synapse Analytics'te Spark etkinliğini kullanarak verileri dönüştürme
- Azure Data Factory veya Synapse Analytics'te Hadoop Akış etkinliğini kullanarak verileri dönüştürme
Dosya biçimi
Sqoop, verileri HDFS'ye aktarırken dosya biçimleri olarak metin, SequenceFile ve Avro'yu destekler. Data Factory veri havuzu olarak HDFS'yi desteklemez, ancak Azure Data Lake Storage'ı veya dosya depolama alanı olarak Azure Blob Depolama kullanır. HDFS geçişi hakkında daha fazla bilgi için bkz . Apache HDFS geçişi.
Data Factory'nin dosya depolamaya yazması için desteklenen biçimler metin, ikili, Avro, JSON, ORC ve Parquet'dir, ancak SequenceFile değildir. Kullanarak saveAsSequenceFilebir dosyayı SequenceFile'a dönüştürmek için Spark gibi bir etkinlik kullanabilirsiniz:
data.saveAsSequenceFile(<path>)
İşleri zamanlama
Sqoop zamanlayıcı işlevselliği sağlamaz. Sqoop işlerini bir zamanlayıcıda çalıştırıyorsanız bu işlevi Data Factory'ye geçirmeniz gerekir. Data Factory, veri işlem hattının yürütülmesini zamanlamak için tetikleyicileri kullanabilir. Mevcut zamanlama yapılandırmanıza göre bir Data Factory tetikleyicisi seçin. Tetikleyici türleri aşağıdadır.
- Zamanlama tetikleyicisi: Zamanlama tetikleyicisi işlem hattını duvar saati zamanlaması üzerinde çalıştırır.
- Atlayan pencere tetikleyicisi: Atlayan pencere tetikleyicisi, durumunu korurken belirli bir başlangıç zamanından itibaren düzenli aralıklarla çalışır.
- Olay tabanlı tetikleyici: Olay tabanlı tetikleyici, olaya yanıt olarak işlem hattını tetikler. İki tür olay tabanlı tetikleyici vardır:
- Depolama olayı tetikleyicisi: Depolama olayı tetikleyicisi, dosya oluşturma, silme veya dosyaya yazma gibi bir depolama olayına yanıt olarak işlem hattını tetikler.
- Özel olay tetikleyicisi: Özel olay tetikleyicisi, olay kılavuzundaki özel bir konuya gönderilen bir olaya yanıt olarak işlem hattını tetikler. Özel konular hakkında bilgi için bkz . Azure Event Grid'de özel konular.
Tetikleyiciler hakkında daha fazla bilgi için bkz . Azure Data Factory veya Azure Synapse Analytics'te işlem hattı yürütme ve tetikleyiciler.
Katkıda Bulunanlar
Bu makale Microsoft tarafından yönetilir. Başlangıçta aşağıdaki katkıda bulunanlar tarafından yazılmıştır.
Asıl yazarlar:
- Namrata Maheshwary | Üst Düzey Bulut Çözümü Mimarı
- Raja N | Müdür, Müşteri Başarısı
- Hideo Takagi | Bulut Çözümü Mimarı
- Ram Yerrabotu | Üst Düzey Bulut Çözümü Mimarı
Diğer katkıda bulunanlar:
- Ram Başkaran | Üst Düzey Bulut Çözümü Mimarı
- Jason Bouska | Kıdemli Yazılım Mühendisi
- Eugene Chung | Üst Düzey Bulut Çözümü Mimarı
- Pawan Hosatti | Üst Düzey Bulut Çözümü Mimarı - Mühendislik
- Daman Kaur | Bulut Çözümü Mimarı
- Danny Liu | Üst Düzey Bulut Çözümü Mimarı - Mühendislik
- Jose Mendez Kıdemli Bulut Çözümü Mimarı
- Ben Sadeghi | Kıdemli Uzman
- Sunil Sattiraju | Üst Düzey Bulut Çözümü Mimarı
- Amanjeet Singh | Asıl Program Yöneticisi
- Nagaraj Seeplapudur Venkatesan | Üst Düzey Bulut Çözümü Mimarı - Mühendislik
Genel olmayan LinkedIn profillerini görmek için LinkedIn'de oturum açın.
Sonraki adımlar
Azure ürün tanıtımları
- Azure Data Lake Storage 2. Nesil'e giriş
- Azure HDInsight'ta Apache Spark nedir?
- Azure HDInsight'ta Apache Hadoop nedir?
- Azure HDInsight'ta Apache HBase nedir?
- Azure HDInsight'ta Apache Kafka nedir?
- Azure HDInsight'ta kurumsal güvenliğe genel bakış
Azure ürün başvurusu
- Microsoft Entra belgeleri
- Azure Cosmos DB belgeleri
- Azure Data Factory belgeleri
- Azure Databricks belgeleri
- Azure Event Hubs belgeleri
- Azure İşlevleri belgeleri
- Azure HDInsight belgeleri
- Microsoft Purview veri idaresi belgeleri
- Azure Stream Analytics belgeleri
- Azure Synapse Analytics
Diğer
- Azure HDInsight için Kurumsal Güvenlik Paketi
- HDInsight üzerinde Apache Hadoop için Java MapReduce programları geliştirme
- HDInsight'ta Hadoop ile Apache Sqoop'u kullanma
- Apache Spark Akışına Genel Bakış
- Yapılandırılmış Akış öğreticisi
- Apache Kafka uygulamalarından Azure Event Hubs kullanma