Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu öğreticide, temel vektör benzerliği arama kullanım örneğinde adım adım ilerleyeceğiz. En uygun eşleşmeyi bulmak için bir film veri kümesini sorgulamak için Azure OpenAI Hizmeti tarafından oluşturulan eklemeleri ve Azure Yönetilen Redis'in yerleşik vektör arama özelliklerini kullanırsınız.
Öğreticide, Wikipedia'dan 1901 ile 2017 yıllarını kapsayan 35.000'den fazla filmin çizim açıklamalarını içeren Wikipedia Film Çizimleri veri kümesi kullanılır. Veri kümesinde her film için bir çizim özeti, ayrıca filmin yayınlandığı yıl, yönetmenler, ana oyuncular ve tarz gibi meta veriler bulunur. Konu özetine dayalı yerleştirmeler oluşturmak ve karma sorgular çalıştırmak için diğer meta verileri kullanarak öğreticinin adımlarını izleyin.
Bu eğitimde şunları öğreniyorsunuz:
- Vektör araması için yapılandırılmış bir Azure Yönetilen Redis örneği oluşturma
- Azure OpenAI'yi ve diğer gerekli Python kitaplıklarını yükleyin.
- Film veri kümesini indirin ve analiz için hazırlayın.
- Eklemeler oluşturmak için text-embedding-ada-002 (Sürüm 2) modelini kullanın.
- Azure Yönetilen Redis'te vektör dizini oluşturma
- Arama sonuçlarını sıralamak için kosinüs benzerliğini kullanın.
- Verileri önceden filtrelemek ve vektör aramasını daha da güçlü hale getirmek için RediSearch aracılığıyla karma sorgu işlevselliğini kullanın.
Önemli
Bu öğreticide Jupyter Not Defteri oluşturma adımları gösterilmektedir. Bu öğreticiyi bir Python kod dosyasıyla (.py) izleyebilir ve benzer sonuçlar alabilirsiniz, ancak bu öğreticideki tüm kod bloklarını dosyaya .py eklemeniz ve sonuçları görmek için bir kez yürütmeniz gerekir. Başka bir deyişle, hücreler yürütülürken Jupyter Notebook ara sonuçlar sağlar, ancak bu, bir Python kod dosyasında çalışırken beklemeniz gereken bir davranış değildir.
Önemli
Bunun yerine tamamlanmış bir Jupyter not defterini takip etmek isterseniz tutorial.ipynb adlı Jupyter not defteri dosyasını indirin ve yeni redis-vector klasörüne kaydedin.
Önkoşullar
- Azure aboneliği - Ücretsiz bir tane oluşturun
- İstenen Azure aboneliğinde Azure OpenAI'ye erişim izni verilir. Şu anda Azure OpenAI'ye erişim için başvurmanız gerekir. adresinden formu https://aka.ms/oai/accesstamamlayarak Azure OpenAI'ye erişim için başvurabilirsiniz. <-- bilmem.
- Python 3.8 veya üzeri sürüm
- Jupyter Notebooks (isteğe bağlı)
- Text-embedding-ada-002 (Sürüm 2) modelinin dağıtıldığı bir Azure OpenAI kaynağı. Bu model şu anda yalnızca belirli bölgelerde kullanılabilir. Modeli dağıtma yönergeleri için kaynak dağıtım kılavuzuna bakın.
Azure Yönetilen Redis Örneği Oluştur
Hızlı Başlangıç: Önbellek oluşturmak için Azure Yönetilen Redis Örneği oluşturma kılavuzunu izleyin, ancak oluşturma sırasında RedisSearch modülünü eklediğinizden emin olun.
Gelişmiş sayfasında RediSearch modülünü eklediğinizden ve Kurumsal Küme İlkesi'ni seçtiğinizden emin olun. Diğer tüm ayarlar, hızlı başlangıçta açıklanan varsayılan ayarlarla eşleşebilir.
Önbelleğin oluşturulması birkaç dakika sürer. Bu arada bir sonraki adıma geçebilirsiniz.
Geliştirme ortamınızı ayarlama
Yerel bilgisayarınızda, genellikle projelerinizi kaydettiğiniz konumda redis-vector adlı bir klasör oluşturun.
Klasörde yeni bir python dosyası (tutorial.py) veya Jupyter not defteri (tutorial.ipynb) oluşturun.
Gerekli Python paketlerini yükleyin:
pip install "openai==1.6.1" num2words matplotlib plotly scipy scikit-learn pandas tiktoken redis langchain
Veri kümesini indirme
Web tarayıcısında https://www.kaggle.com/datasets/jrobischon/wikipedia-movie-plots adresine gidin.
Kaggle ile oturum açın veya kaydolun. Dosyayı indirmek için kayıt gereklidir.
archive.zip dosyasını indirmek için Kaggle'da İndir bağlantısını seçin.
archive.zip dosyasını ayıklayın ve wiki_movie_plots_deduped.csvredis-vector klasörüne taşıyın.
Kitaplıkları içeri aktarma ve bağlantı bilgilerini ayarlama
Azure OpenAI'ye karşı başarılı bir şekilde çağrı yapmak için bir uç nokta ve anahtar gerekir. Azure Yönetilen Redis'e bağlanmak için bir uç nokta ve anahtara da ihtiyacınız vardır.
Azure portalında Azure OpenAI kaynağınıza gidin.
Kaynak Yönetimi bölümünde Uç Nokta ve Anahtarlar'ı bulun. Api çağrılarınızın kimliğini doğrulamak için ihtiyacınız olacak şekilde uç noktanızı ve erişim anahtarınızı kopyalayın. Örnek uç nokta:
https://docs-test-001.openai.azure.com.KEY1veyaKEY2kullanabilirsiniz.Azure portalında Azure Yönetilen Redis kaynağınızın Genel Bakış sayfasına gidin. Uç noktanızı kopyalayın.
Ayarlar bölümünde Erişim anahtarlarını bulun. Erişim anahtarınızı kopyalayın.
PrimaryveyaSecondarykullanabilirsiniz.Yeni bir kod hücresine aşağıdaki kodu ekleyin:
# Code cell 2 import re from num2words import num2words import os import pandas as pd import tiktoken from typing import List from langchain.embeddings import AzureOpenAIEmbeddings from langchain.vectorstores.redis import Redis as RedisVectorStore from langchain.document_loaders import DataFrameLoader API_KEY = "<your-azure-openai-key>" RESOURCE_ENDPOINT = "<your-azure-openai-endpoint>" DEPLOYMENT_NAME = "<name-of-your-model-deployment>" MODEL_NAME = "text-embedding-ada-002" REDIS_ENDPOINT = "<your-azure-redis-endpoint>" REDIS_PASSWORD = "<your-azure-redis-password>"API_KEYveRESOURCE_ENDPOINTdeğerlerini Azure OpenAI dağıtımınızdaki anahtar ve uç nokta değerleriyle güncelleyin.DEPLOYMENT_NAMEeklemeler modeli kullanılaraktext-embedding-ada-002 (Version 2)dağıtımınızın adına ayarlanmalıdır veMODEL_NAMEkullanılan belirli eklemeler modeli olmalıdır.REDIS_ENDPOINTveREDIS_PASSWORDöğelerini Azure Yönetilen Redis örneğinizdeki uç nokta ve anahtar değeriyle güncelleyin.Önemli
API anahtarı, uç nokta ve dağıtım adı bilgilerini geçirmek için ortam değişkenlerini veya Azure Key Vault gibi bir gizli dizi yöneticisini kullanmanızı kesinlikle öneririz. Bu değişkenler basitlik adına burada düz metin olarak ayarlanmıştır.
Kod hücresi 2'yi çalıştırın.
Veri kümesini pandas'a aktarma ve verileri işleme
Ardından csv dosyasını bir pandas DataFrame'de okuyacaksınız.
Yeni bir kod hücresine aşağıdaki kodu ekleyin:
# Code cell 3 df=pd.read_csv(os.path.join(os.getcwd(),'wiki_movie_plots_deduped.csv')) dfKod hücresi 3'ü çalıştır. Aşağıdaki çıkışı görmeniz gerekir:

Ardından, dizin
idekleyerek, sütun başlıklarından boşlukları kaldırarak verileri işleyin ve filmleri yalnızca 1970'ten sonra ve İngilizce konuşan ülkelerden veya bölgelerden yapılan filmleri alacak şekilde filtreleyin. Bu filtreleme adımı, veri kümesindeki film sayısını azaltarak eklemeler oluşturmak için gereken maliyeti ve süreyi azaltır. Tercihlerinize göre filtre parametrelerini değiştirebilir veya kaldırabilirsiniz.Verileri filtrelemek için aşağıdaki kodu yeni bir kod hücresine ekleyin:
# Code cell 4 df.insert(0, 'id', range(0, len(df))) df['year'] = df['Release Year'].astype(int) df['origin'] = df['Origin/Ethnicity'].astype(str) del df['Release Year'] del df['Origin/Ethnicity'] df = df[df.year > 1970] # only movies made after 1970 df = df[df.origin.isin(['American','British','Canadian'])] # only movies from English-speaking cinema dfKod hücresi 4'ü çalıştırın. Aşağıdaki sonuçları görmeniz gerekir:

Boşluk ve noktalama işaretlerini kaldırarak verileri temizlemek için bir işlev oluşturun, ardından çizimi içeren veri çerçevesine karşı kullanın.
Yeni bir kod hücresine aşağıdaki kodu ekleyin ve çalıştırın.
# Code cell 5 pd.options.mode.chained_assignment = None # s is input text def normalize_text(s, sep_token = " \n "): s = re.sub(r'\s+', ' ', s).strip() s = re.sub(r". ,","",s) # remove all instances of multiple spaces s = s.replace("..",".") s = s.replace(". .",".") s = s.replace("\n", "") s = s.strip() return s df['Plot']= df['Plot'].apply(lambda x : normalize_text(x))Son olarak, ekleme modeli için çok uzun çizim açıklamaları içeren tüm girdileri kaldırın. (Başka bir deyişle, 8192 belirteç sınırından daha fazla belirteç gerektirir.) ve ardından ekleme oluşturmak için gereken belirteç sayısını hesaplayın. Bu, ekleme oluşturma fiyatlandırmasını da etkilemektedir.
Yeni bir kod hücresine aşağıdaki kodu ekleyin:
# Code cell 6 tokenizer = tiktoken.get_encoding("cl100k_base") df['n_tokens'] = df["Plot"].apply(lambda x: len(tokenizer.encode(x))) df = df[df.n_tokens<8192] print('Number of movies: ' + str(len(df))) print('Number of tokens required:' + str(df['n_tokens'].sum()))6 numaralı kod hücresini çalıştır. Şu çıktıyı görmelisiniz:
Number of movies: 11125 Number of tokens required:7044844


DataFrame'i LangChain'e yükleme
DataFrame'i DataFrameLoader sınıfını kullanarak LangChain'e yükleyin. Veriler LangChain belgelerine eklendikten sonra eklemeler oluşturmak ve benzerlik aramaları yapmak için LangChain kitaplıklarını kullanmak çok daha kolaydır.
Çizim'i, eklemelerin bu sütunda oluşturulması için page_content_column olarak ayarlayın.
Yeni bir kod hücresine aşağıdaki kodu ekleyin ve çalıştırın.
# Code cell 7 loader = DataFrameLoader(df, page_content_column="Plot" ) movie_list = loader.load()
Eklemeler oluşturma ve bunları Redis'e yükleme
Artık veriler filtrelendiğine ve LangChain'e yüklendiğine göre, her filmin senaryosu üzerinde sorgulama yapabileceğiniz yerleştirmeler oluşturacaksınız. Aşağıdaki kod Azure OpenAI'yi yapılandırarak eklemeler oluşturur ve ekleme vektörlerini Azure Managed Redis'e yükler.
Aşağıdaki kodu yeni bir kod hücresi ekleyin:
# Code cell 8 embedding = AzureOpenAIEmbeddings( deployment=DEPLOYMENT_NAME, model=MODEL_NAME, azure_endpoint=RESOURCE_ENDPOINT, openai_api_type="azure", openai_api_key=API_KEY, openai_api_version="2023-05-15", show_progress_bar=True, chunk_size=16 # current limit with Azure OpenAI service. This will likely increase in the future. ) # name of the Redis search index to create index_name = "movieindex" # create a connection string for the Redis Vector Store. Uses Redis-py format: https://redis-py.readthedocs.io/en/stable/connections.html#redis.Redis.from_url # This example assumes TLS is enabled. If not, use "redis://" instead of "rediss:// redis_url = "rediss://:" + REDIS_PASSWORD + "@"+ REDIS_ENDPOINT # create and load redis with documents vectorstore = RedisVectorStore.from_documents( documents=movie_list, embedding=embedding, index_name=index_name, redis_url=redis_url ) # save index schema so you can reload in the future without re-generating embeddings vectorstore.write_schema("redis_schema.yaml")Kod hücresi 8'i çalıştır. Bu işlemin tamamlanması 30 dakikadan fazla sürebilir. Bir
redis_schema.yamldosya da oluşturulur. Eklemeleri yeniden oluşturmadan Azure Yönetilen Redis örneğindeki dizininize bağlanmak istiyorsanız bu dosya kullanışlıdır.
Önemli
Eklemelerin oluşturulma hızı, Azure OpenAI Modeli için kullanılabilir kotaya bağlıdır. Dakikada 240 bin belirteç kotasıyla, veri kümesindeki 7M belirteçlerin işlenmesi yaklaşık 30 dakika sürer.
Vektör arama sorgularını çalıştırma
Veri kümeniz, Azure OpenAI hizmet API'niz ve Redis örneğiniz ayarlandıktan sonra vektörleri kullanarak arama yapabilirsiniz. Bu örnekte, belirli bir sorgu için ilk 10 sonuç döndürülür.
Python kod dosyanıza aşağıdaki kodu ekleyin:
# Code cell 9 query = "Spaceships, aliens, and heroes saving America" results = vectorstore.similarity_search_with_score(query, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')9. kod hücresini çalıştır. Aşağıdaki çıkışı görmeniz gerekir:
Independence Day (Score: 0.8348) The Flying Machine (Score: 0.8332) Remote Control (Score: 0.8301) Bravestarr: The Legend (Score: 0.83) Xenogenesis (Score: 0.8291) Invaders from Mars (Score: 0.8291) Apocalypse Earth (Score: 0.8287) Invasion from Inner Earth (Score: 0.8287) Thru the Moebius Strip (Score: 0.8283) Solar Crisis (Score: 0.828)Benzerlik puanı, filmlerin benzerliklere göre sıralı sıralamasıyla birlikte döndürülür. Daha belirli sorguların benzerlik puanlarının listede daha hızlı azaldığını göreceksiniz.
Karma aramalar
RediSearch ayrıca vektör aramasının yanı sıra zengin arama işlevlerine de sahip olduğundan sonuçları film türü, yayın yılı veya yönetmen gibi veri kümesindeki meta verilere göre filtrelemek mümkündür. Bu durumda, türüne göre filtreleyin
comedy.Yeni bir kod hücresine aşağıdaki kodu ekleyin:
# Code cell 10 from langchain.vectorstores.redis import RedisText query = "Spaceships, aliens, and heroes saving America" genre_filter = RedisText("Genre") == "comedy" results = vectorstore.similarity_search_with_score(query, filter=genre_filter, k=10) for i, j in enumerate(results): movie_title = str(results[i][0].metadata['Title']) similarity_score = str(round((1 - results[i][1]),4)) print(movie_title + ' (Score: ' + similarity_score + ')')Kod hücresi 10'u çalıştır. Aşağıdaki çıkışı görmeniz gerekir:
Remote Control (Score: 0.8301) Meet Dave (Score: 0.8236) Elf-Man (Score: 0.8208) Fifty/Fifty (Score: 0.8167) Mars Attacks! (Score: 0.8165) Strange Invaders (Score: 0.8143) Amanda and the Alien (Score: 0.8136) Suburban Commando (Score: 0.8129) Coneheads (Score: 0.8129) Morons from Outer Space (Score: 0.8121)
Azure Yönetilen Redis ve Azure OpenAI Hizmeti ile uygulamanıza güçlü arama özellikleri eklemek için eklemeleri ve vektör aramasını kullanabilirsiniz.
Kaynakları temizle
Bu makalede oluşturduğunuz kaynakları kullanmaya devam etmek istiyorsanız kaynak grubunu koruyun.
Aksi takdirde, kaynaklarla işiniz bittiyse ücretlerden kaçınmak için oluşturduğunuz Azure kaynak grubunu silebilirsiniz.
Önemli
Bir kaynak grubunu silmek geri alınamaz. Kaynak grubunu sildiğinizde, içindeki tüm kaynaklar kalıcı olarak silinir. Yanlış kaynak grubunu veya kaynakları yanlışlıkla silmediğinizden emin olun. Tutmak istediğiniz kaynakları içeren mevcut bir kaynak grubunun içinde kaynakları oluşturduysanız, kaynak grubunu silmek yerine her kaynağı tek tek silebilirsiniz.
Kaynak grubunu silmek için
Azure portalında oturum açın ve Kaynak grupları’nı seçin.
Silmek istediğiniz kaynak grubunu seçin.
Çok sayıda kaynak grubu varsa Herhangi bir alan için filtre uygula... kutusunu kullanın, bu makale için oluşturduğunuz kaynak grubunuzun adını yazın. Sonuçlar listesinden kaynak grubunu seçin.
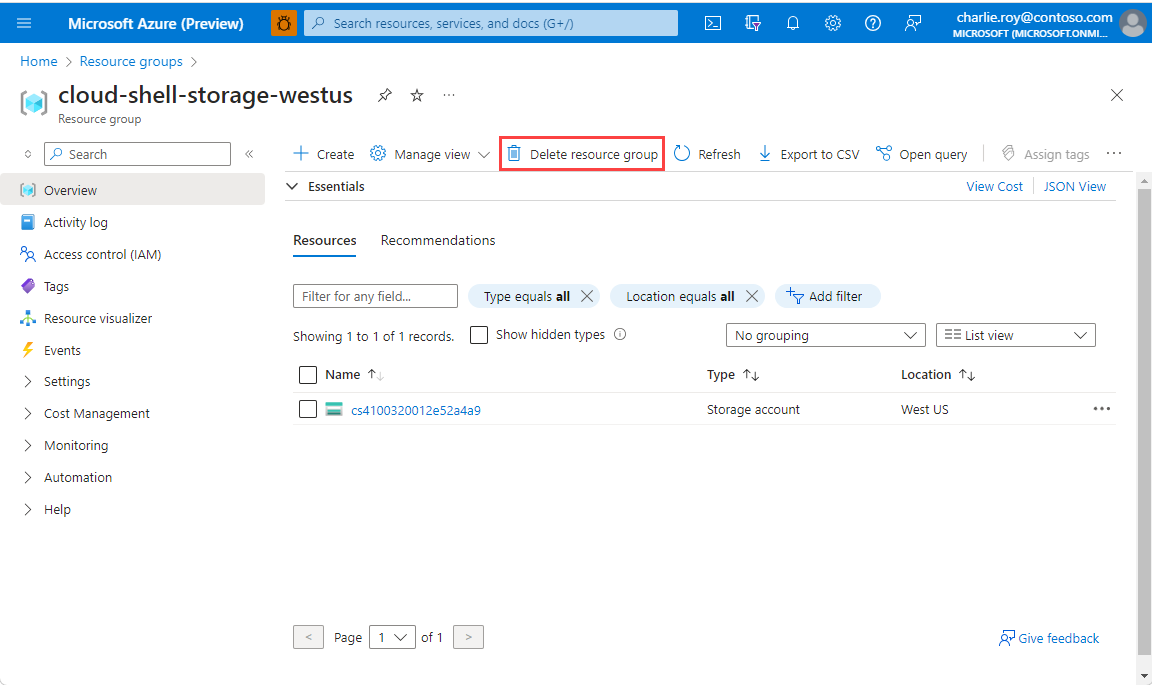
Kaynak grubunu sil seçeneğini seçin.
Kaynak grubunun silinmesini onaylamanız istenir. Onaylamak için kaynak grubunuzun adını yazın ve ardından Sil’i seçin.
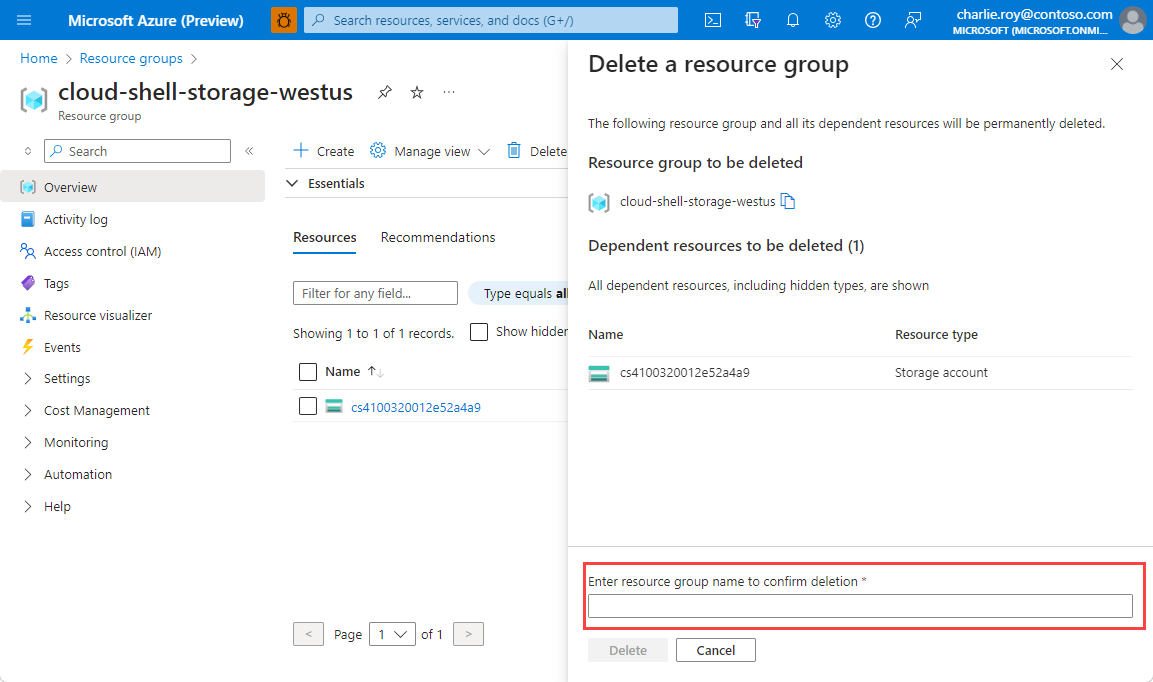
Birkaç dakika sonra kaynak grubu ve bu gruptaki kaynakların tümü silinir.
İlgili İçerik
- Azure Yönetilen Redis hakkında daha fazla bilgi edinin
- Azure OpenAI Hizmeti tarafından oluşturulan eklemeler hakkında daha fazla bilgi edinin
- Kosinüs benzerliği hakkında daha fazla bilgi edinin
- OpenAI ve Redis ile yapay zeka destekli uygulama derlemeyi öğrenin
- Anlamsal yanıtlarla soru-cevap uygulaması oluşturma