Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Bu öğreticide, Python, Scala ve R kullanarak health.data.ny.gov'den Unity Kataloğu biriminize bebek adı verileri içeren bir CSV dosyasından verileri içeri aktarmak için Azure Databricks not defteri kullanma konusunda size yol gösterilir. Ayrıca sütun adını değiştirmeyi, verileri görselleştirmeyi ve tabloya kaydetmeyi de öğrenirsiniz.
Uyarı
Databricks Free Edition kullanıyorsanız bu öğreticideki tüm kod örnekleri için Python sekmesini seçin. Ücretsiz Sürüm R veya Scala'ı desteklemez. Ayrıca, Free Edition giden internet erişimini kısıtlar, bu nedenle CSV dosyasını kodla indirmek yerine çalışma alanı kullanıcı arabirimini kullanarak yüklemeniz gerekir. Ayrıntılı yönergeler için bkz . 3. Adım .
Gereksinimler
Bu makaledeki görevleri tamamlamak için aşağıdaki gereksinimleri karşılamanız gerekir:
- Çalışma alanınızda Unity Kataloğu etkinleştirilmiş olmalıdır. Unity Kataloğu'nu kullanmaya başlama hakkında bilgi için bkz. Unity Kataloğu'nu kullanmaya başlama. Azure Databricks Free Edition ve ücretsiz deneme çalışma alanlarında Unity Kataloğu varsayılan olarak etkindir.
- Birimde
WRITE VOLUMEayrıcalığına, üst şemadaUSE SCHEMAayrıcalığına ve üst katalogdaUSE CATALOGayrıcalığına sahip olmalısınız. Free Edition kullanıcıları varsayılan olarak çalışma alanı kataloğunda vedefaultşemasında bu ayrıcalıklara sahiptir. - Mevcut bir işlem kaynağını kullanma veya yeni bir işlem kaynağı oluşturma izniniz olmalıdır. İşlem bölümüne bakın veya Azure Databricks yöneticinize başvurun.
İpucu
Bu makale için tamamlanmış bir not defteri görmek istiyorsanız, bkz Veri not defterlerini içeri aktarma ve görselleştirme.
1. Adım: Yeni not defteri oluşturma
Çalışma alanınızda not defteri oluşturmak için kenar ![]() çubuğunda Yeni'ye ve ardından Not Defteri'ne tıklayın. Çalışma alanında boş bir not defteri açılır.
çubuğunda Yeni'ye ve ardından Not Defteri'ne tıklayın. Çalışma alanında boş bir not defteri açılır.
Not defterlerini oluşturma ve yönetme hakkında daha fazla bilgi edinmek için bkz. Databricks not defterlerini yönetme.
2. Adım: Değişkenleri tanımlama
Bu adımda, bu makalede oluşturduğunuz örnek not defterinde kullanılacak değişkenleri tanımlarsınız. Unity Kataloğu'nun katalog, şema ve veri kümesi adlarına ihtiyaç vardır.
İpucu
Katalog ve şema adlarınızı bilmiyorsanız ![]() Kenar çubuğunda katalog. Çalışma alanı kataloğu, çalışma alanınızla bir ad paylaşır ve katalog panelinde listelenir. Kullanılabilir şemaları görmek için genişletin. Ücretsiz Sürüm ve ücretsiz deneme kullanıcıları çalışma alanı kataloğunu ve şemayı
Kenar çubuğunda katalog. Çalışma alanı kataloğu, çalışma alanınızla bir ad paylaşır ve katalog panelinde listelenir. Kullanılabilir şemaları görmek için genişletin. Ücretsiz Sürüm ve ücretsiz deneme kullanıcıları çalışma alanı kataloğunu ve şemayı default kullanabilir.
Bellek bölümünüz yoksa, notebook hücresinde aşağıdaki komutu çalıştırarak bir bellek bölümü oluşturun (ve <catalog_name> ile <schema_name> değerlerinizi değiştirin):
CREATE VOLUME IF NOT EXISTS <catalog_name>.<schema_name>.my_volume
Aşağıdaki kodu kopyalayıp yeni boş not defteri hücresine yapıştırın.
<catalog-name>,<schema-name>ve<volume-name>yerine Unity Kataloğu biriminin katalog, şema ve birim adlarını yazın. İsteğe bağlı olarak değerini seçtiğiniz bir tablo adıyla değiştirintable_name. Bebek adı verilerini bu makalenin devamında bu tabloya kaydedersiniz.Hücreyi çalıştırmak ve yeni bir boş hücre oluşturmak için basın
Shift+Enter.Piton
catalog = "<catalog_name>" schema = "<schema_name>" volume = "<volume_name>" download_url = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name = "baby_names.csv" table_name = "baby_names" path_volume = "/Volumes/" + catalog + "/" + schema + "/" + volume path_table = catalog + "." + schema print(path_table) # Show the complete path print(path_volume) # Show the complete pathScala programlama dili
val catalog = "<catalog_name>" val schema = "<schema_name>" val volume = "<volume_name>" val downloadUrl = "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" val fileName = "baby_names.csv" val tableName = "baby_names" val pathVolume = s"/Volumes/${catalog}/${schema}/${volume}" val pathTable = s"${catalog}.${schema}" print(pathVolume) // Show the complete path print(pathTable) // Show the complete pathR
catalog <- "<catalog_name>" schema <- "<schema_name>" volume <- "<volume_name>" download_url <- "https://health.data.ny.gov/api/views/jxy9-yhdk/rows.csv" file_name <- "baby_names.csv" table_name <- "baby_names" path_volume <- paste("/Volumes/", catalog, "/", schema, "/", volume, sep = "") path_table <- paste(catalog, ".", schema, sep = "") print(path_volume) # Show the complete path print(path_table) # Show the complete path
3. Adım: CSV dosyasını içeri aktarma
Bu adımda, health.data.ny.gov'deki bebek adı verilerini içeren bir CSV dosyasını Unity Kataloğu biriminize aktaracaksınız. Aşağıdaki yöntemlerden birini seçin:
- Çalışma alanı kullanıcı arabirimini kullanarak yükleme — Databricks Free Edition kullanıyorsanız veya B seçeneğindeki kod indirme işlemi bir ağ hatasıyla başarısız oluyorsa bu yöntemi tercih edin. Ücretsiz Sürüm ve diğer sunucusuz işlem ortamları giden İnternet erişimini kısıtlar, bu nedenle dosyayı yerel makinenizden yüklemeniz gerekir.
- Kodu kullanarak indirme — İşlem ortamınızda giden İnternet erişimi varsa bu yöntemi kullanın.
A Seçeneği: Çalışma alanı kullanıcı arabirimini kullanarak karşıya yükleme
- Yerel makinenizde tarayıcınızda health.data.ny.gov/api/views/jxy9-yhdk/rows.csv açın. Dosya
rows.csvolarak bilgisayarınıza indirilir. - İndirilen dosyayı bilgisayarınızda bulun ve olarak
rows.csvbaby_names.csvyeniden adlandırın. Bu, 2. Adımda tanımladığınız değişkenle eşleşirfile_name. - Azure Databricks çalışma alanınıza geri dönün. Kenar çubuğunda
 Yeni > Veri ekle veya karşıya yükle'ye tıklayın.
Yeni > Veri ekle veya karşıya yükle'ye tıklayın. - Dosyaları bir birime yükle'ye tıklayın.
-
Gözat düğmesine
baby_names.csvtıklayıp dosyayı seçin veya sürükleyip yükleme alanına bırakın. - Hedef birim'in altında, 2. Adımda belirttiğiniz birimi seçin.
- Karşıya yükleme tamamlandıktan sonra not defterinize dönün ve 4. Adımla devam edin.
Dosyaları karşıya yükleme hakkında daha fazla ayrıntı için bkz. Unity Kataloğu birimlerinde dosyalarla çalışma.
B Seçeneği: Kod kullanarak indirme
Aşağıdaki kodu kopyalayıp yeni boş not defteri hücresine yapıştırın. Bu kod,
rows.csvdosyasını health.data.ny.gov adresinden alarak Databricks dbutils komutunu kullanarak Unity Catalog biriminize kopyalar.Hücreyi çalıştırmak için basın
Shift+Enterve ardından sonraki hücreye geçin.Piton
dbutils.fs.cp(f"{download_url}", f"{path_volume}" + "/" + f"{file_name}")Scala programlama dili
dbutils.fs.cp(downloadUrl, s"${pathVolume}/${fileName}")R
dbutils.fs.cp(download_url, paste(path_volume, "/", file_name, sep = ""))
4. Adım: CSV verilerini DataFrame'e yükleme
Bu adımda, daha önce Unity Catalog hacminize yüklediğiniz CSV dosyasından df adlı bir DataFrame, spark.read.csv yöntemi kullanılarak oluşturulur.
Aşağıdaki kodu kopyalayıp yeni boş not defteri hücresine yapıştırın. Bu kod, CSV dosyasından DataFrame'e
dfbebek adı verilerini yükler.Hücreyi çalıştırmak için basın
Shift+Enterve ardından sonraki hücreye geçin.Piton
df = spark.read.csv(f"{path_volume}/{file_name}", header=True, inferSchema=True, sep=",")Scala programlama dili
val df = spark.read .option("header", "true") .option("inferSchema", "true") .option("delimiter", ",") .csv(s"${pathVolume}/${fileName}")R
# Load the SparkR package that is already preinstalled on the cluster. library(SparkR) df <- read.df(paste(path_volume, "/", file_name, sep=""), source="csv", header = TRUE, inferSchema = TRUE, delimiter = ",")
Desteklenen birçok dosya biçiminden veri yükleyebilirsiniz.
5. Adım: Not defterinden verileri görselleştirme
Bu adımda, DataFrame'in içeriğini not defterindeki bir tabloda görüntülemek ve ardından verileri not defterindeki bir sözcük bulut grafiğinde görselleştirmek için yöntemini kullanırsınız display() .
Aşağıdaki kodu kopyalayıp yeni boş not defteri hücresine yapıştırın ve ardından Verileri tabloda görüntülemek için Hücreyi çalıştır'a tıklayın.
Piton
display(df)Scala programlama dili
display(df)R
display(df)Tablodaki sonuçları gözden geçirin.
Tablo sekmesinin yanındaki + alanına tıklayın ve ardından Görselleştirme'ye tıklayın.
Görselleştirme düzenleyicisinde Görselleştirme Türü'ne tıklayın ve Word bulutunun seçili olduğunu doğrulayın.
Sözcükler sütununda,
First Nameöğesinin seçili olduğunu doğrulayın.Frekanslar Limiti'nde tıklayın.
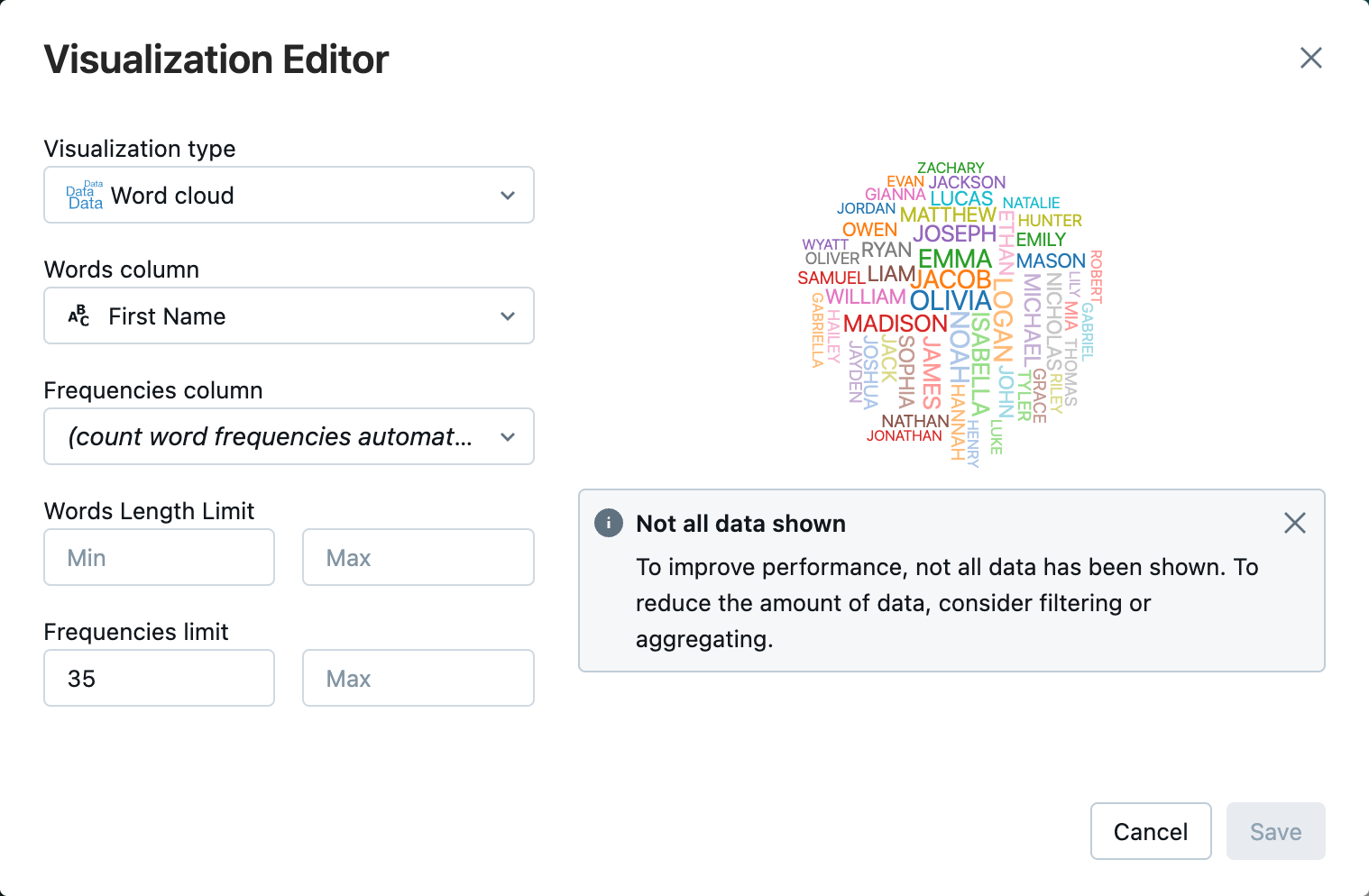
Kaydet'e tıklayın.
6. Adım: DataFrame'i tabloya kaydetme
Önemli
DataFrame'inizi Unity Kataloğu'na kaydetmek için katalog ve şemada tablo ayrıcalıklarına sahip CREATE olmanız gerekir. Unity Kataloğu'ndaki izinler hakkında bilgi için bkz. Unity Kataloğu'nda Ayrıcalıklar ve güvenliği sağlanabilir nesneler ve Unity Kataloğu'nda ayrıcalıkları yönetme.
Aşağıdaki kodu kopyalayıp boş bir not defteri hücresine yapıştırın. Bu kod, sütun adındaki bir boşluğun yerini alır. Özel karakterler, boşluklar gibi sütun adlarında izin verilmez. Bu kod Apache Spark
withColumnRenamed()yöntemini kullanır.Piton
df = df.withColumnRenamed("First Name", "First_Name") df.printSchemaScala programlama dili
val dfRenamedColumn = df.withColumnRenamed("First Name", "First_Name") // when modifying a DataFrame in Scala, you must assign it to a new variable dfRenamedColumn.printSchema()R
df <- withColumnRenamed(df, "First Name", "First_Name") printSchema(df)Aşağıdaki kodu kopyalayıp boş bir not defteri hücresine yapıştırın. Bu kod, bu makalenin başında tanımladığınız tablo adı değişkenini kullanarak DataFrame'in içeriğini Unity Kataloğu'ndaki bir tabloya kaydeder.
Piton
df.write.mode("overwrite").saveAsTable(f"{path_table}" + "." + f"{table_name}")Scala programlama dili
dfRenamedColumn.write.mode("overwrite").saveAsTable(s"${pathTable}.${tableName}")R
saveAsTable(df, paste(path_table, ".", table_name), mode = "overwrite")Tablonun kaydedildiğini doğrulamak için sol kenar çubuğunda Katalog'a tıklayarak Katalog Gezgini kullanıcı arabirimini açın. Tablonun göründüğünü doğrulamak için kataloğunuzu ve ardından şemanızı açın.
Genel Bakış sekmesinde tablo şemasını görüntülemek için tablonuza tıklayın.
Tablodan 100 veri satırı görüntülemek için Örnek Veri'ye tıklayın.
Veri not defterlerini içeri aktarma ve görselleştirme
Bu makaledeki adımları gerçekleştirmek için aşağıdaki not defterlerinden birini kullanın.
<catalog-name>, <schema-name>ve <volume-name> yerine Unity Kataloğu biriminin katalog, şema ve birim adlarını yazın. İsteğe bağlı olarak değerini seçtiğiniz bir tablo adıyla değiştirin table_name .
Piton
Python kullanarak CSV'den veri içeri aktarma
Scala programlama dili
Scala kullanarak CSV'den verileri içeri aktarma
R
R kullanarak CSV'den verileri içeri aktarma
Sonraki adımlar
- Keşif veri analizi (EDA) teknikleri hakkında bilgi edinmek için Öğretici: Databricks not defterlerini kullanarak EDA teknikleri bölümüne bakın.
- ETL (çıkarma, dönüştürme ve yükleme) işlem hattının nasıl oluşturulacağını öğrenmek için bkz. Öğretici: Lakeflow Pipelines ile ETL işlem hattı oluşturma ve Öğretici: Databricks platformunda Apache Spark ile ETL işlem hattı oluşturma