Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Keşif veri analizi (EDA) gerçekleştirmek için Azure Databricks not defterinde Python kullanın: veri kümesini yükleyip temizleyin, özelliklerini keşfedin ve içgörü oluşturmak için eğilimleri görselleştirin.
Bu öğreticide kullanılan not defteri, küresel enerji ve emisyon verilerini inceler ve verileri yükleme, temizleme ve araştırmayı gösterir.
örnek not defterini kullanarak birlikte ilerleyebilir veya sıfırdan kendi not defterinizi oluşturabilirsiniz.
EDA nedir?
Keşif veri analizi (EDA), veri bilimi sürecinde verilerin analiz ve görselleştirilmesini içeren kritik bir başlangıç adımıdır:
- Ana özelliklerini ortaya çıkarın.
- Desenleri ve eğilimleri belirleme.
- Anomalileri algılama.
- Değişkenler arasındaki ilişkileri anlama.
EDA, daha fazla istatistiksel analiz veya modelleme hakkında bilinçli kararlar almayı kolaylaştırarak veri kümesiyle ilgili içgörüler sağlar.
Azure Databricks not defterleriyle veri bilimciler tanıdık araçları kullanarak EDA gerçekleştirebilir. Örneğin, bu öğreticide verileri işlemek ve çizmek için aşağıdakiler gibi bazı yaygın Python kitaplıkları kullanılır:
- Numpy: Bu veri yapıları üzerinde çalışacak diziler, matrisler ve çok çeşitli matematiksel işlevler için destek sağlayan sayısal bilgi işlem için temel bir kitaplık.
- pandas: Yapılandırılmış verileri verimli bir şekilde işlemek için DataFrames gibi veri yapıları sunan, NumPy'nin üzerine kurulmuş güçlü bir veri işleme ve analiz kitaplığı.
- Plotly: Veri analizi ve sunu için yüksek kaliteli, etkileşimli görselleştirmeler oluşturulmasını sağlayan etkileşimli bir grafik kitaplığı.
- Matplotlib: Python statik, animasyonlu ve etkileşimli görselleştirmeler oluşturmaya yönelik kapsamlı bir kitaplık.
Azure Databricks ayrıca tablolardaki verileri filtreleme ve arama ve görselleştirmeleri yakınlaştırma gibi not defteri çıkışındaki verilerinizi keşfetmenize yardımcı olacak yerleşik özellikler de sağlar. EDA için kod yazmanıza yardımcı olması için Genie Code da kullanabilirsiniz.
Başlamadan önce
Bu öğreticiyi tamamlamak için aşağıdakilere ihtiyacınız vardır:
- Mevcut bir işlem kaynağını kullanma veya yeni bir işlem kaynağı oluşturma izniniz olmalıdır. İşlem bkz.
- [İsteğe bağlı] Bu öğreticide kod oluşturmanıza yardımcı olması için Genie Code'un nasıl kullanılacağı açıklanmaktadır. Daha fazla bilgi için Genie Code kullanma bölümüne bkz.
Veri kümesini indirme ve CSV dosyasını içeri aktarma
Bu öğreticide, küresel enerji ve emisyon verilerini inceleyerek EDA teknikleri gösterilmektedir. Takip etmek için Kaggle'dan Our World in Data tarafından hazırlanan Enerji Tüketimi Veri Kümesi'ini indirin. Bu öğreticide owid-energy-data.csv dosyası kullanılır.
Veri kümesini Azure Databricks çalışma alanınıza aktarmak için:
Çalışma alanı tarayıcısına gitmek için çalışma alanının kenar çubuğunda Çalışma Alanı 'e tıklayın.
owid-energy-data.csvCSV dosyasını sürükleyip çalışma alanınıza bırakın.Bu, İçe Aktarma modali açar. Burada listelenen Hedef klasörü not edin. Bu, çalışma alanı tarayıcısında geçerli klasörünüz olarak ayarlanır ve içeri aktarılan dosyanın hedefi olur.
İçeri Aktar'ıtıklayın. Dosya çalışma alanınızdaki hedef klasörde görünmelidir.
Dosyayı daha sonra not defterinize yüklemek için dosya yoluna ihtiyacınız vardır. Dosyayı çalışma alanı tarayıcınızda bulun. Dosya yolunu panonuza kopyalamak için dosya adına sağ tıklayın ve URL/yolu kopyala seçin>Tam yol.
Yeni not defteri oluşturma
Kullanıcı ana klasörünüzde yeni bir not defteri oluşturmak için, kenar çubuğunda "![]() Yeni" üzerine tıklayın ve menüden "Not Defteri" seçin.
Yeni" üzerine tıklayın ve menüden "Not Defteri" seçin.
Üst kısımda, not defterinin adının yanında, not defteri için varsayılan dil olarak Python seçin.
Not defterlerini oluşturma ve yönetme hakkında daha fazla bilgi edinmek için bkz. Not defterlerini yönetme.
Bu makaledeki kod örneklerinin her birini not defterinizdeki yeni bir hücreye ekleyin. Veya sağlanan örnek not defterini kullanarak öğreticiyi takip edin.
CSV dosyasını yükleme
Yeni bir not defteri hücresinde CSV dosyasını yükleyin. Bunu yapmak için numpy ve pandas'i içeri aktarın. Bunlar veri bilimi ve analizi için yararlı Python kitaplıklarıdır.
Daha kolay işleme ve görselleştirme için veri kümesinden pandas DataFrame oluşturun. Aşağıdaki dosya yolunu daha önce kopyaladığınız dosyayla değiştirin.
import numpy as np
import pandas as pd # Data processing, CSV file I/O (e.g. pd.read_csv)
df=pd.read_csv('/Workspace/Users/demo@databricks.com/owid-energy-data.csv') # Replace the file path here with the workspace path you copied earlier
Hücreyi çalıştırın. Çıkış, her sütunun ve türünün bir listesi de dahil olmak üzere pandas DataFrame'i döndürmelidir.
İçe aktarılan DataFrame'in 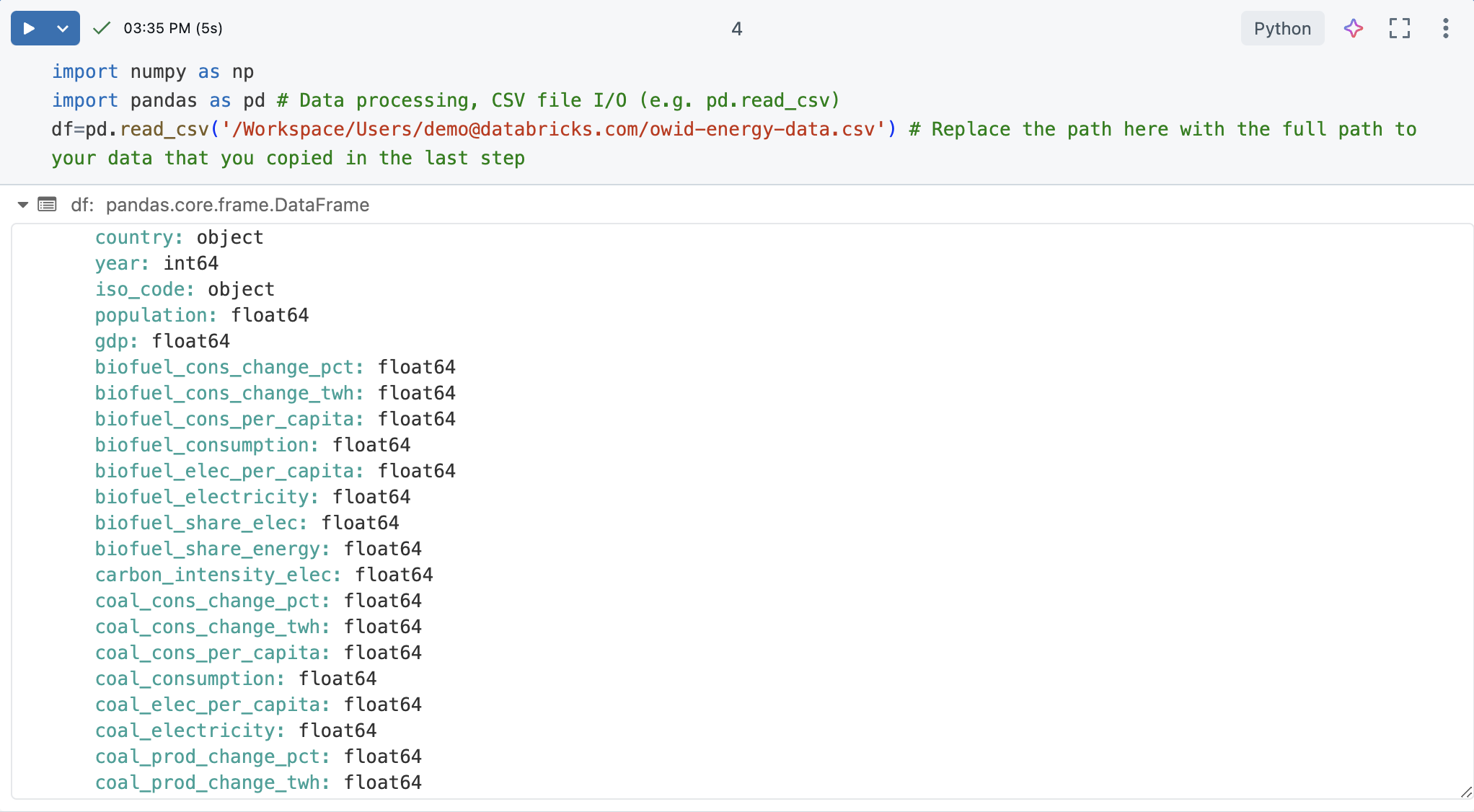
Verileri anlama
Veri kümesinin temellerini anlamak, tüm veri bilimi projeleri için çok önemlidir. Eldeki verilerin yapısı, türleri ve kalitesi hakkında bilgi sahibi olmak gerekir.
Azure Databricks not defterinde, veri kümesini görüntülemek için display(df) komutunu kullanabilirsiniz.
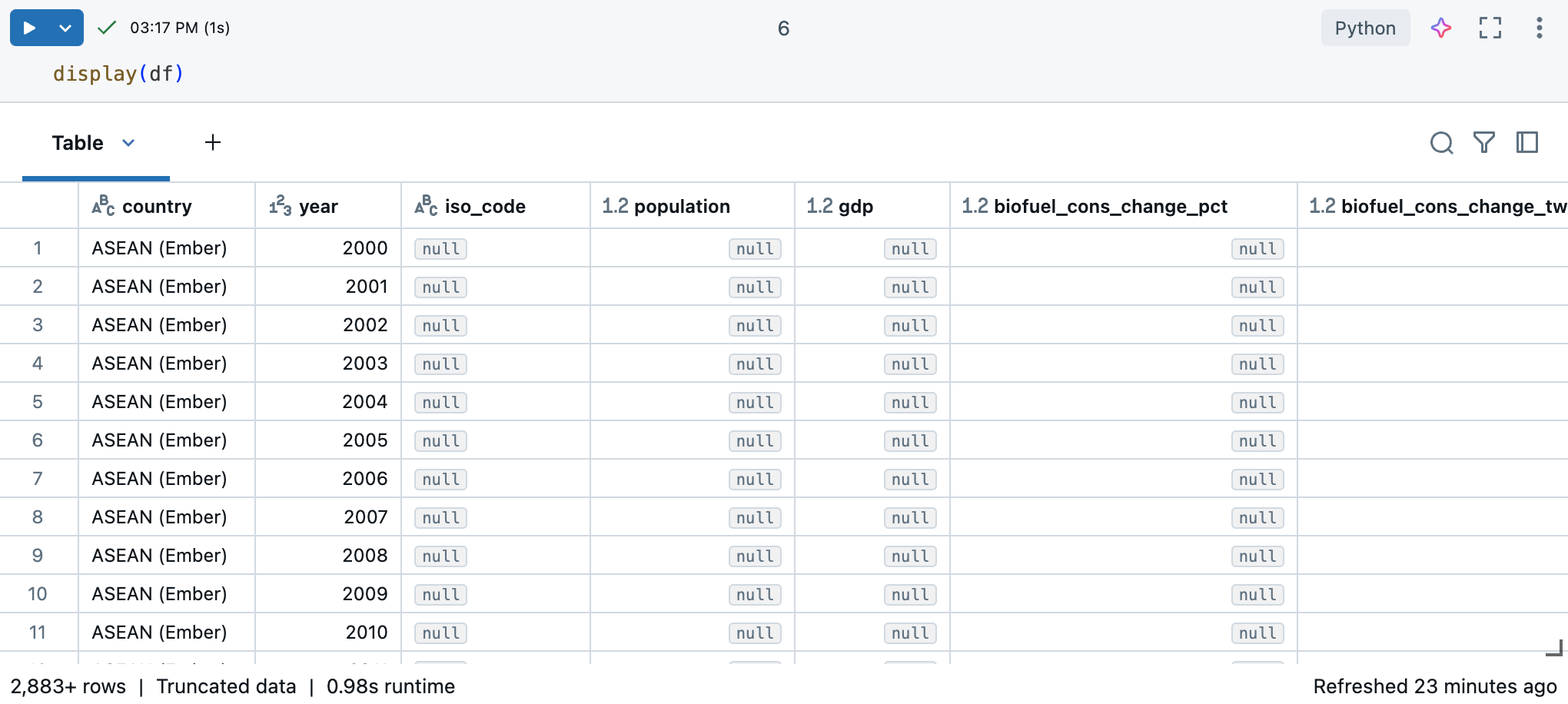
Veri kümesinin 10.000'den fazla satırı olduğundan, bu komut kesilmiş bir veri kümesi döndürür. Her sütunun sol tarafında sütunun veri türünü görebilirsiniz. Daha fazla bilgi edinmek için bakınız sütunları biçimlendirme.
Veri içgörüleri için pandas kullanma
Veri kümenizi etkili bir şekilde anlamak için aşağıdaki pandas komutlarını kullanın:
df.shapekomutu DataFrame'in boyutlarını döndürerek satır ve sütun sayısına hızlı bir genel bakış sağlar.
df.dtypeskomutu, her sütunun veri türlerini sağlayarak ilgilendiğiniz veri türünü anlamanıza yardımcı olur. Sonuç tablosundaki her sütunun veri türünü de görebilirsiniz.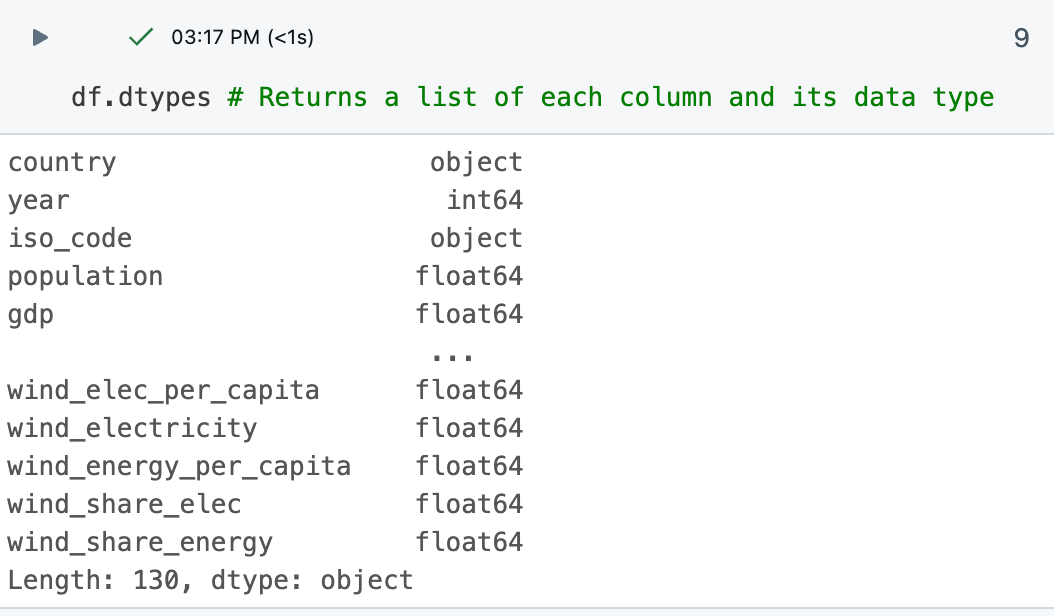
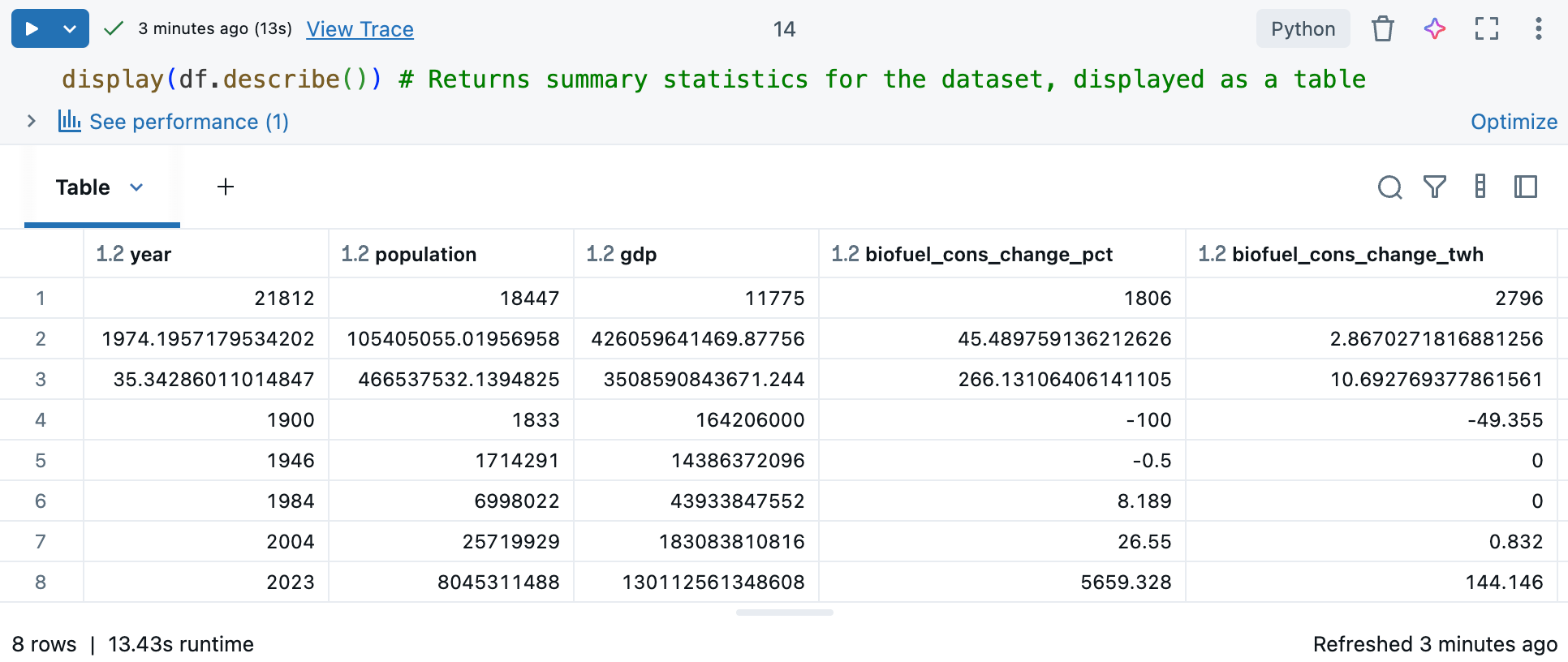
df.describe()komutu ortalama, standart sapma ve yüzdebirlik değerleri gibi sayısal sütunlar için açıklayıcı istatistikler oluşturur. Bu istatistikler desenleri belirlemenize, anomalileri algılamanıza ve verilerinizin dağılımını anlamanıza yardımcı olabilir.display()ile birlikte kullanarak etkileşimli tablo formatında özet istatistikleri görebilirsiniz. Bkz . Databricks not defteri çıkış tablosunu kullanarak verileri keşfetme.df.describe çıktısını görüntüleyen hücre çıktısı
Veri profili oluşturma
Uyarı
Databricks Runtime 9.1 LTS ve üzerinde kullanılabilir.
Azure Databricks not defterleri yerleşik veri profili oluşturma özelliklerini içerir. bir DataFrame'i Azure Databricks görüntüleme işleviyle görüntülerken, tablo çıkışından bir veri profili oluşturabilirsiniz.
# Display the DataFrame, then click "+ > Data Profile" to generate a data profile
display(df)
Çıktıdaki + yanındaki >Veri Profili'e tıklayın. Bu, DataFrame'deki verilerin profilini oluşturan yeni bir komut çalıştırır.
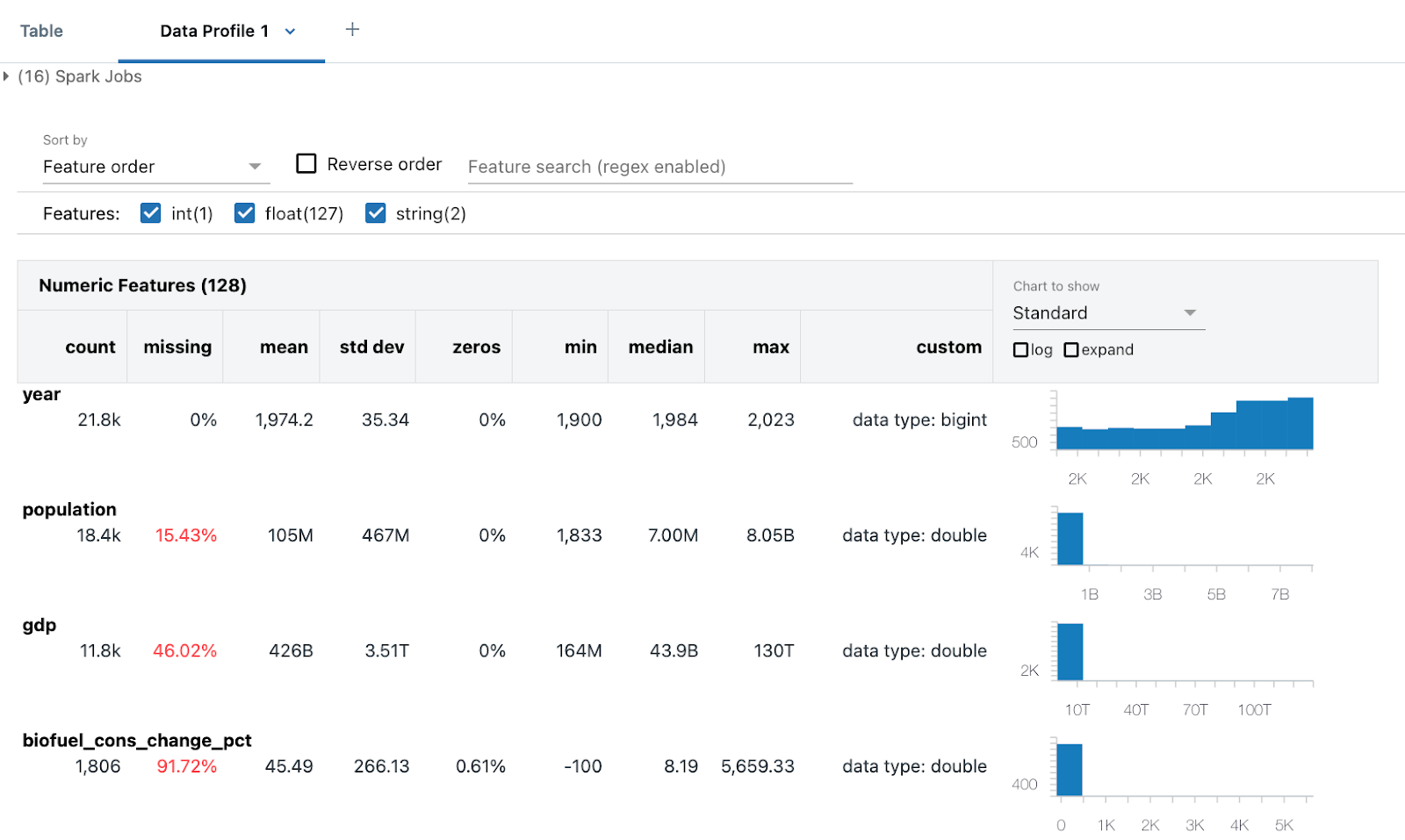
Veri profili, sayısal, dize ve tarih sütunlarının özet istatistiklerinin yanı sıra her sütun için değer dağılımlarının histogramlarını içerir. Veri profillerini program aracılığıyla da oluşturabilirsiniz; bkz. summarize komutu (dbutils.data.summarize).
Verileri temizleme
Veri kümesinin doğru, tutarlı ve anlamlı analize hazır olduğundan emin olmak için verilerin temizlenmesi EDA'da önemli bir adımdır. Bu işlem, verilerin analize hazır olduğundan emin olmak için aşağıdakiler dahil olmak üzere çeşitli temel görevleri içerir:
- Yinelenen verileri tanımlama ve kaldırma.
- Eksik değerleri işleme, bunları belirli bir değerle değiştirmeyi veya etkilenen satırları kaldırmayı içerebilir.
- Tutarlılık sağlamak için dönüştürmeler ve dönüşümler aracılığıyla veri türlerini standartlaştırma (örneğin, dizeleri
datetime'e dönüştürme). Ayrıca, verileri daha kolay çalışabileceğiniz bir biçime dönüştürmek isteyebilirsiniz.
Bu temizleme aşaması, verilerin kalitesini ve güvenilirliğini artırarak daha doğru ve içgörüye dayalı analize olanak sağladığından önemlidir.
İpucu: Veri temizleme görevlerine yardımcı olması için Genie Code kullanma
Kod oluşturmanıza yardımcı olması için Genie Code kullanabilirsiniz. Yeni bir kod hücresi oluşturun ve oluştur bağlantısına tıklayın veya genie Code'u açmak için sağ üstteki Genie Code simgesini kullanın. Genie Code için bir sorgu girin. Genie Code Python veya SQL kodu oluşturabilir veya bir metin açıklaması oluşturabilir. Farklı sonuçlar için Yeniden Oluşturöğesine tıklayın.
Örneğin, verileri temizlemenize yardımcı olması için Genie Code'u kullanmak için aşağıdaki istemleri deneyin:
-
dfyinelenen sütun veya satır içerip içermediğini denetleyin. Yinelenenleri yazdırın. Ardından yinelenenleri silin. - Tarih sütunları hangi biçimdedir?
'YYYY-MM-DD'olarak değiştirin. -
XXXsütununu kullanmayacağım. Sil.
Bkz. Genie Code'dan kodlama yardımı alma.
Yinelenen verileri kaldırma
Verilerde yinelenen satır veya sütun olup olmadığını denetleyin. Öyleyse kaldırın.
İpucu
Sizin için kod oluşturmak için Genie Code kullanın.
Şu istemi girmeyi deneyin: "df'nin yinelenen sütun veya satır içerip içermediğini denetleyin. Yinelenenleri yazdırın. Ardından yinelenenleri silin." Genie Code aşağıdaki örneğe benzer bir kod oluşturabilir.
# Check for duplicate rows
duplicate_rows = df.duplicated().sum()
# Check for duplicate columns
duplicate_columns = df.columns[df.columns.duplicated()].tolist()
# Print the duplicates
print("Duplicate rows count:", duplicate_rows)
print("Duplicate columns:", duplicate_columns)
# Drop duplicate rows
df = df.drop_duplicates()
# Drop duplicate columns
df = df.loc[:, ~df.columns.duplicated()]
Bu durumda, veri kümesinin yinelenen verileri yoktur.
Null veya eksik değerleri işleme
NaN veya Null değerleri işlemenin yaygın yollarından biri, daha kolay matematiksel işlem için bunları 0 ile değiştirmektir.
df = df.fillna(0) # Replace all NaN (Not a Number) values with 0
Bu, DataFrame'deki eksik verilerin 0 ile değiştirilmesini sağlar. Bu, eksik değerlerin sorunlara neden olabileceği sonraki veri analizi veya işleme adımları için yararlı olabilir.
Tarihleri yeniden biçimlendirme
Tarihler genellikle farklı veri kümelerinde çeşitli şekillerde biçimlendirilir. Bunlar tarih biçiminde, dizelerde veya tamsayılarda olabilir.
Bu çözümleme için year sütununu tamsayı olarak değerlendirin. Aşağıdaki kod, bunu yapmak için bir yoldur:
# Ensure the 'year' column is converted to the correct data type (integer for year)
df['year'] = pd.to_datetime(df['year'], format='%Y', errors='coerce').dt.year
# Confirm the changes
df.year.dtype
Bu, year sütununun yalnızca tamsayı yılı değerleri içermesini ve geçersiz girişlerin NaT (Saat Değil) olarak dönüştürülmesini sağlar.
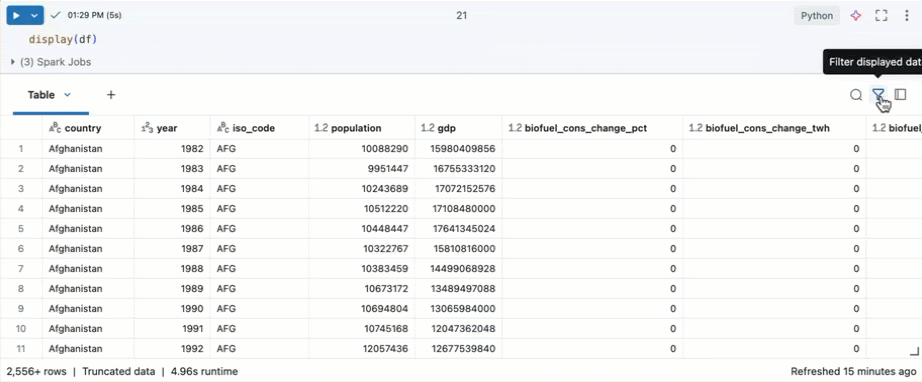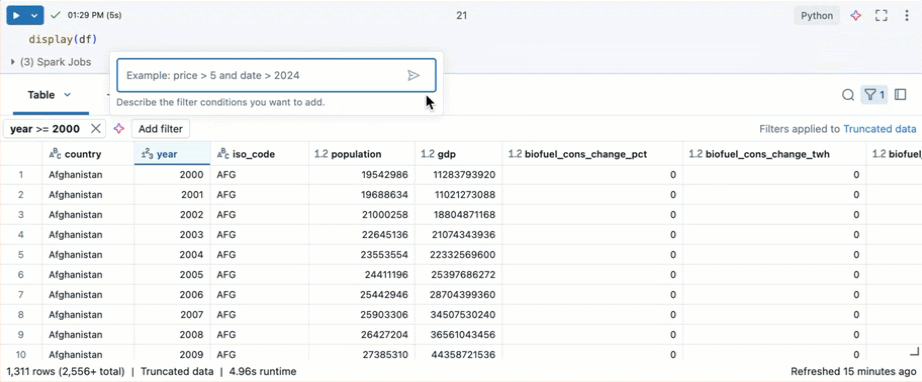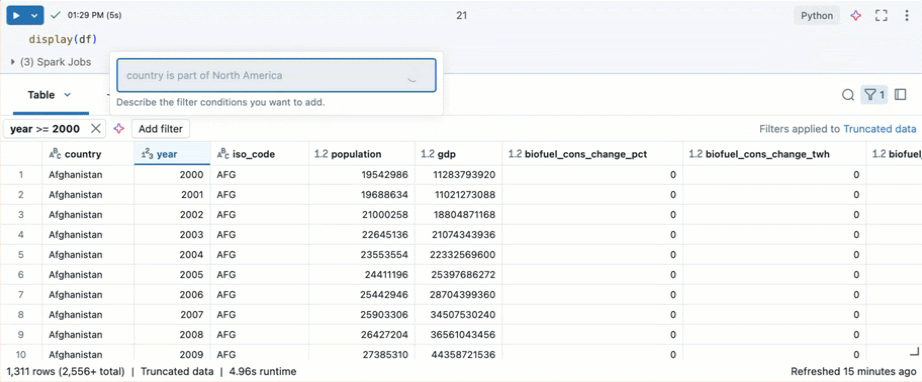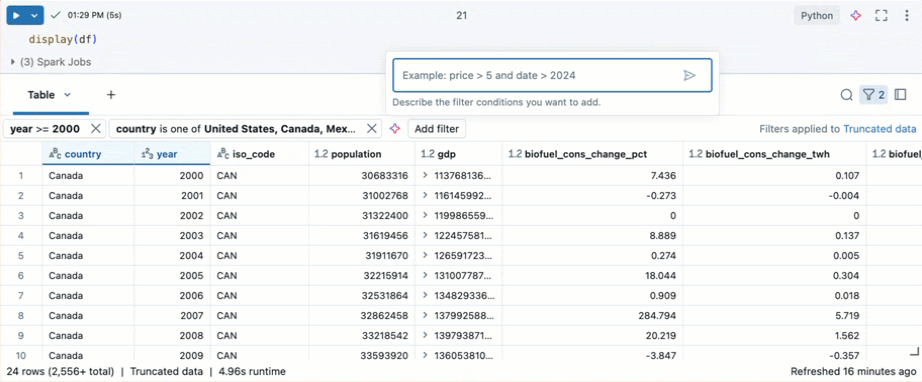
Databricks not defteri çıkış tablosunu kullanarak verileri keşfetme
Azure Databricks, çıktı tablosunu kullanarak verilerinizi keşfetmenize yardımcı olacak yerleşik özellikler sağlar.
Yeni bir hücrede veri kümesini tablo olarak görüntülemek için display(df) kullanın.
Çıkış tablosunu kullanarak verilerinizi çeşitli yollarla keşfedebilirsiniz:
- Belirli bir dize veya değer için verilerde arama
- Belirli koşullar için filtre
- Veri kümesi kullanarak görselleştirmeler oluşturma
Belirli bir dize veya değer için verilerde arama
Tablonun sağ üst kısmındaki arama simgesine tıklayın ve aramanızı girin.
Belirli koşullar için filtre uygulama
Sütunlarınızı belirli koşullar için filtrelemek için yerleşik tablo filtrelerini kullanabilirsiniz. Filtre oluşturmanın birkaç yolu vardır. Bkz. sonuçları filtreleme.
İpucu
Filtre oluşturmak için Genie Code kullanın. Tablonun sağ üst köşesindeki filtre simgesine tıklayın. Filtre koşulunuzu girin. Genie Code sizin için otomatik olarak bir filtre oluşturur.
Veri kümesini kullanarak görselleştirmeler oluşturma
Çıktı tablosunun üst kısmında Görselleştirme+>'e tıklayarak görselleştirme düzenleyicisini açın.
Görselleştirmek istediğiniz görselleştirme türünü ve sütunları seçin. Düzenleyici, yapılandırmanıza göre grafiğin önizlemesini görüntüler. Örneğin, aşağıdaki resimde çeşitli yenilenebilir enerji kaynaklarının zaman içindeki tüketimini görüntülemek için birden çok çizgi grafiğin nasıl ekleneceği gösterilmektedir.
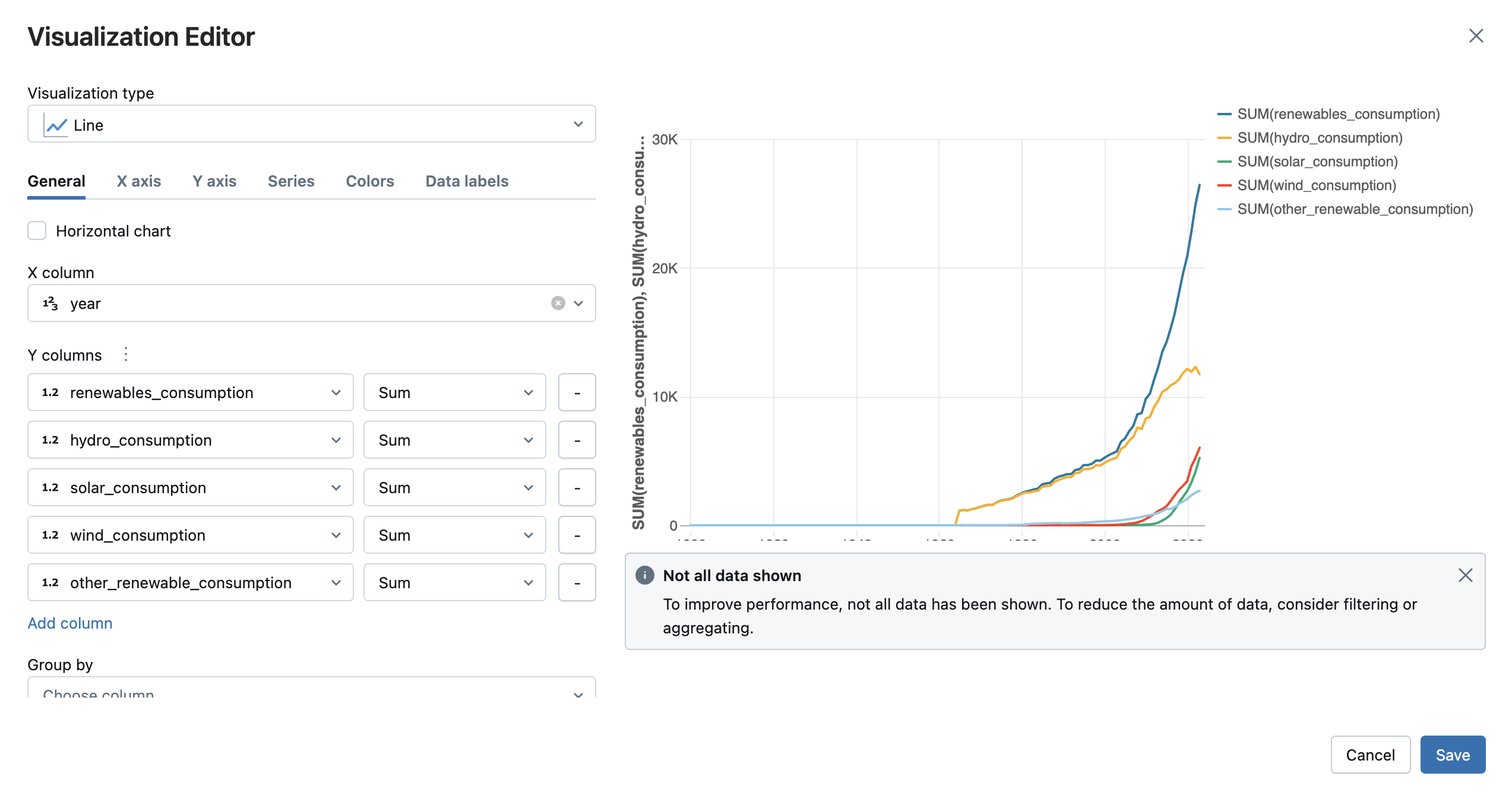
Görselleştirmeyi hücre çıktısında bir sekme olarak eklemek için Kaydet'e tıklayın.
Yeni bir görselleştirme oluşturma için 'e bakın.
Python kitaplıklarını kullanarak verileri keşfetme ve görselleştirme
Görselleştirmeleri kullanarak verileri keşfetmek EDA'nın temel bir yönüdür. Görselleştirmeler, yalnızca sayısal analizle hemen görünür olmayabilecek verilerdeki desenleri, eğilimleri ve ilişkileri ortaya çıkarmanıza yardımcı olur. Dağılım çizimleri, çubuk grafikler, çizgi grafikler ve histogramlar gibi yaygın görselleştirme teknikleri için Plotly veya Matplotlib gibi kitaplıkları kullanın. Bu görsel araçlar veri bilim adamlarının anomalileri tanımlamasına, veri dağıtımlarını anlamasına ve değişkenler arasındaki bağıntıları gözlemlesine olanak sağlar. Örneğin dağılım çizimleri aykırı değerleri vurgularken zaman serisi çizimleri eğilimleri ve mevsimselliği ortaya çıkarabiliyor.
- Benzersiz ülkeler için dizi oluşturma
- İlk 10 yayıcı için grafik emisyon eğilimleri (2000-2022)
- Emisyonları bölgeye göre filtrele ve grafikle
- Yenilenebilir enerji payının büyümesini hesaplama ve grafiği oluşturma
- Serpme grafiği: En fazla yayıcılar için yenilenebilir enerjinin etkisini göster
- Model öngörülen küresel enerji tüketimi
Benzersiz ülkeler için dizi oluşturma
Benzersiz ülkeler için bir dizi oluşturarak veri kümesine dahil olan ülkeleri inceleyin. Dizi oluşturma, countryolarak listelenen varlıkları gösterir.
# Get the unique countries
unique_countries = df['country'].unique()
unique_countries
Çıkışı:

Insight:
country sütunu Dünya, Yüksek gelirli ülkeler, Asya ve Birleşik Devletler gibi her zaman doğrudan karşılaştırılamayan çeşitli varlıkları içerir. Verileri bölgeye göre filtrelemek daha yararlı olabilir.
İlk 10 yayıcı için grafik emisyon eğilimleri (2000-2022)
Araştırmanızı 2000'lerde en yüksek sera gazı emisyonu olan 10 ülkeye odaklamak istediğinizi varsayalım. Bakmak istediğiniz yıllara ve en çok emisyona sahip ilk 10 ülkeye ilişkin verileri filtreleyebilir, ardından zaman içindeki emisyonlarını gösteren bir çizgi grafik oluşturmak için çizim grafiğini kullanabilirsiniz.
import plotly.express as px
# Filter data to include only years from 2000 to 2022
filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
# Get the top 10 countries with the highest emissions in the filtered data
top_countries = filtered_data.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
# Filter the data for those top countries
top_countries_data = filtered_data[filtered_data['country'].isin(top_countries)]
# Plot emissions trends over time for these countries
fig = px.line(top_countries_data, x='year', y='greenhouse_gas_emissions', color='country',
title="Greenhouse Gas Emissions Trends for Top 10 Countries (2000 - 2022)")
fig.show()
Çıkışı:
2000'den 2022'ye kadar ilk 10 yayıcı için sera gazı emisyon eğilimlerini gösteren 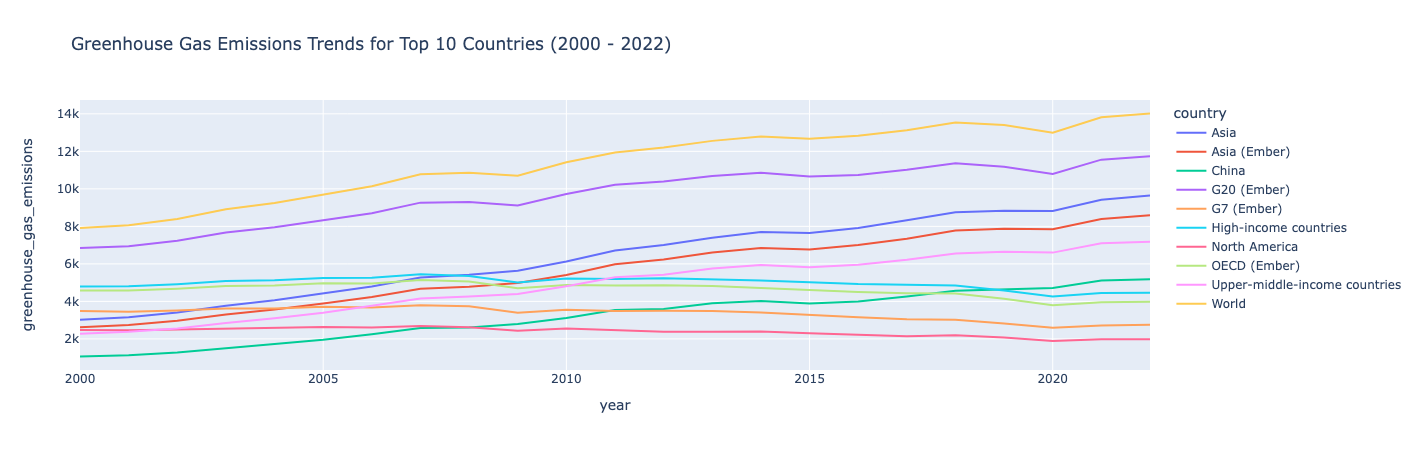
Insight:
Sera gazı emisyonları 2000-2022 arasında yukarı doğru eğilim gösterirken, emisyonların bu zaman diliminde hafif bir düşüşle nispeten kararlı olduğu birkaç ülke dışında.
Bölgeye göre filtre ve grafik emisyonları
Verileri bölgeye göre filtreleyin ve her bölgenin toplam emisyonlarını hesaplayın. Ardından verileri çubuk grafik olarak çizin:
# Filter out regional entities
regions = ['Africa', 'Asia', 'Europe', 'North America', 'South America', 'Oceania']
# Calculate total emissions for each region
regional_emissions = df[df['country'].isin(regions)].groupby('country')['greenhouse_gas_emissions'].sum()
# Plot the comparison
fig = px.bar(regional_emissions, title="Greenhouse Gas Emissions by Region")
fig.show()
Çıkışı:
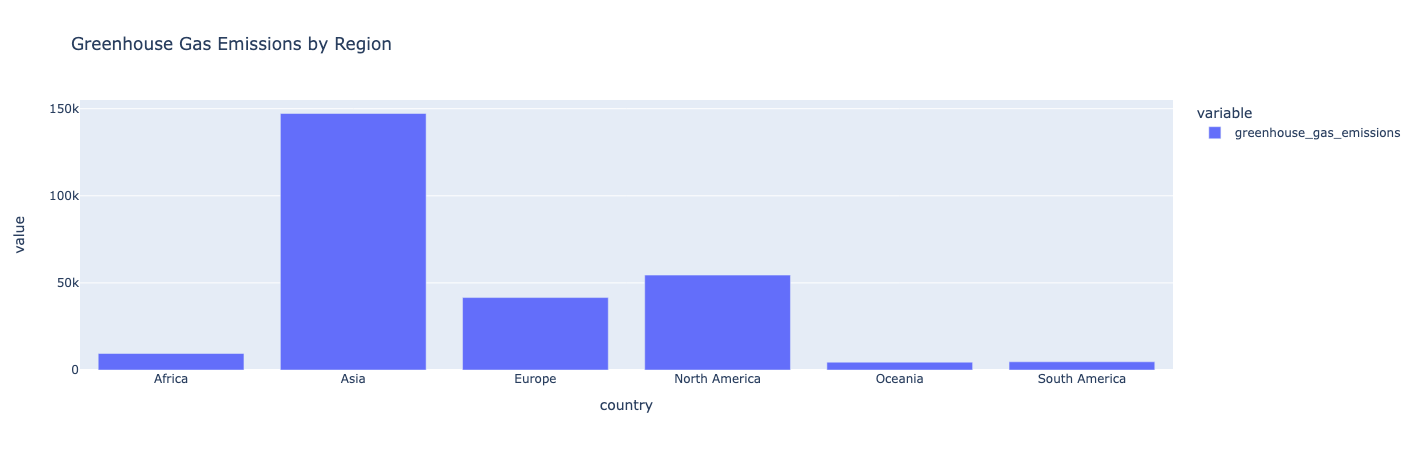
İçgörü:
Asya en yüksek sera gazı emisyonlarına sahiptir. Okyanusya, Güney Amerika ve Afrika en düşük sera gazı emisyonlarını üretir.
Yenilenebilir enerji payı büyümesini hesaplama ve grafı oluşturma
Yenilenebilir enerji payını, yenilenebilir enerji tüketiminin birincil enerji tüketimine oranı olarak hesaplayan yeni bir özellik/sütun oluşturun. Ardından, ülkeleri ortalama yenilenebilir enerji paylarına göre sıralayın. İlk 10 ülke için, zaman içinde yenilenebilir enerji paylarını çizin:
# Calculate the renewable energy share and save it as a new column called "renewable_share"
df['renewable_share'] = df['renewables_consumption'] / df['primary_energy_consumption']
# Rank countries by their average renewable energy share
renewable_ranking = df.groupby('country')['renewable_share'].mean().sort_values(ascending=False)
# Filter for countries leading in renewable energy share
leading_renewable_countries = renewable_ranking.head(10).index
leading_renewable_data = df[df['country'].isin(leading_renewable_countries)]
# filtered_data = df[(df['year'] >= 2000) & (df['year'] <= 2022)]
leading_renewable_data_filter=leading_renewable_data[(leading_renewable_data['year'] >= 2000) & (leading_renewable_data['year'] <= 2022)]
# Plot renewable share over time for top renewable countries
fig = px.line(leading_renewable_data_filter, x='year', y='renewable_share', color='country',
title="Renewable Energy Share Growth Over Time for Leading Countries")
fig.show()
Çıkışı:
Yenilenebilir enerjide lider 10 ülke için zaman içinde yenilenebilir enerji payının büyümesini gösteren 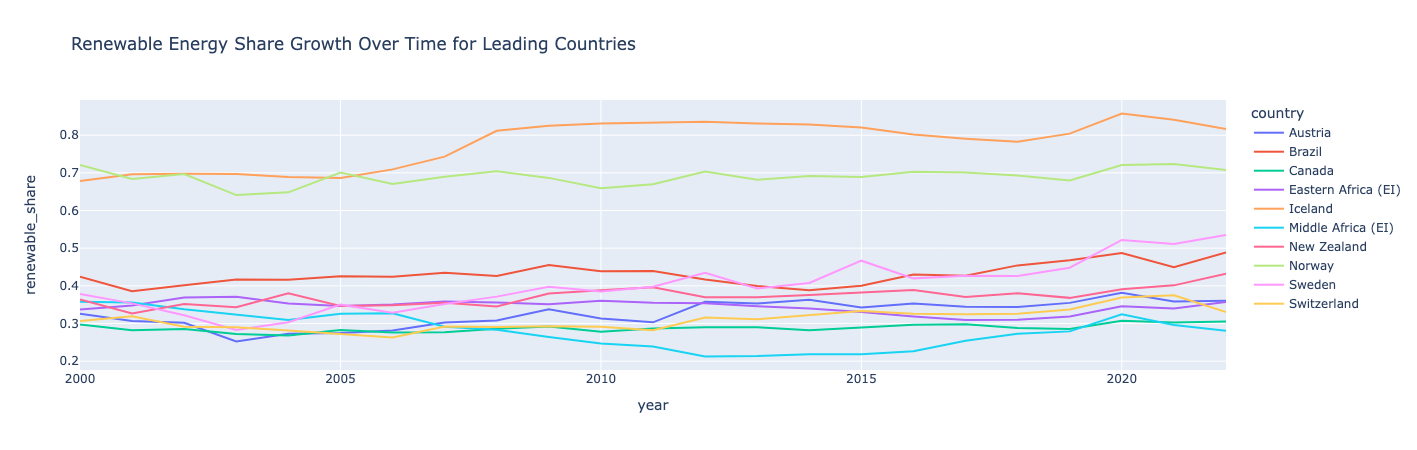
Insight:
Norveç ve İzlanda, tüketimin yarısından fazlasının yenilenebilir enerjiden gelmesiyle yenilenebilir enerjide dünya lideridir.
İzlanda ve İsveç, yenilenebilir enerji paylarında en büyük büyümeyi gördü. Tüm ülkelerde zaman zaman düşüşler ve artışlar görüldü ve yenilenebilir enerji payının büyümesinin doğrusal olması şart değildir. Orta Afrika, 2010'ların başında bir düşüş gördü ancak 2020'de geri döndü.
Dağılım çizimi: En yüksek yayıcılar için yenilenebilir enerjinin etkisini göster
İlk 10 yayıcının verilerini filtreleyin, ardından zaman içindeki sera gazı emisyonlarına karşı yenilenebilir enerji paylaşımına bakmak için bir dağılım grafiği kullanın.
# Select top emitters and calculate renewable share vs. emissions
top_emitters = df.groupby('country')['greenhouse_gas_emissions'].sum().nlargest(10).index
top_emitters_data = df[df['country'].isin(top_emitters)]
# Plot renewable share vs. greenhouse gas emissions over time
fig = px.scatter(top_emitters_data, x='renewable_share', y='greenhouse_gas_emissions',
color='country', title="Impact of Renewable Energy on Emissions for Top Emitters")
fig.show()
Çıkışı:
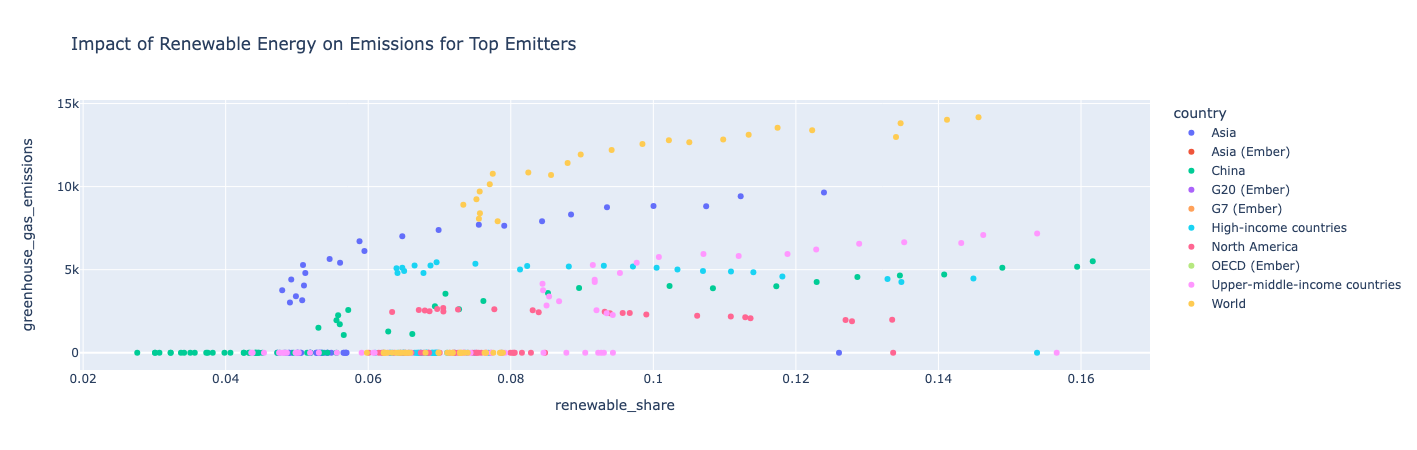
Insight:
Bir ülke daha fazla yenilenebilir enerji kullandığından, sera gazı emisyonları da daha fazladır, yani toplam enerji tüketimi yenilenebilir tüketiminden daha hızlı artar. Kuzey Amerika, sera gazı emisyonlarının yıllar boyunca yenilenebilir payı artmaya devam ettikçe nispeten sabit kalması bir istisnadır.
Modelle öngörülen küresel enerji tüketimi
Küresel birincil enerji tüketimini yıla göre bir araya getirir, ardından sonraki birkaç yıl boyunca toplam küresel enerji tüketimini yansıtmak için otomatik girişli entegre hareketli ortalama (ARIMA) modeli oluşturur. Matplotlib kullanarak geçmiş ve tahmin edilen enerji tüketimini çizin.
import pandas as pd
from statsmodels.tsa.arima.model import ARIMA
import matplotlib.pyplot as plt
# Aggregate global primary energy consumption by year
global_energy = df[df['country'] == 'World'].groupby('year')['primary_energy_consumption'].sum()
# Build an ARIMA model for projection
model = ARIMA(global_energy, order=(1, 1, 1))
model_fit = model.fit()
forecast = model_fit.forecast(steps=10) # Projecting for 10 years
# Plot historical and forecasted energy consumption
plt.plot(global_energy, label='Historical')
plt.plot(range(global_energy.index[-1] + 1, global_energy.index[-1] + 11), forecast, label='Forecast')
plt.xlabel("Year")
plt.ylabel("Primary Energy Consumption")
plt.title("Projected Global Energy Consumption")
plt.legend()
plt.show()
Çıkışı:
Geçmiş ve öngörülen küresel enerji tüketimini gösteren 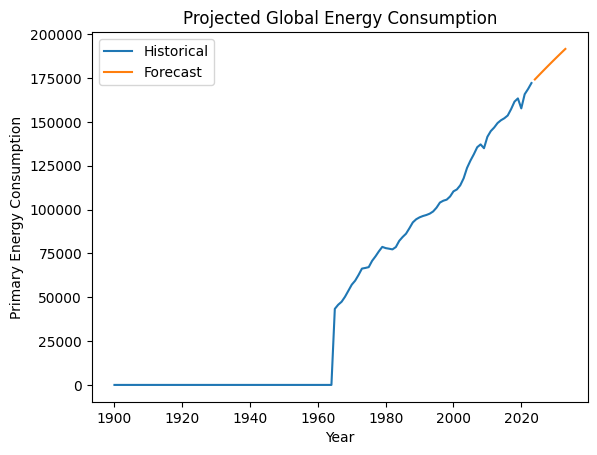
Insight:
Bu model, küresel enerji tüketiminin artmaya devam edeceğine dair projeler sunar.
Örnek not defteri
Bu makaledeki adımları gerçekleştirmek için aşağıdaki not defterini kullanın. Not defterini Azure Databricks çalışma alanına aktarma yönergeleri için bkz. Not defterini içeri aktarma.
Kılavuz: Küresel enerji verileriyle Keşifsel Veri Analizi (EDA)
not defteri alma
Sonraki adımlar
Veri kümenizde ilk keşif veri analizini gerçekleştirdiğinize göre aşağıdaki sonraki adımları deneyin:
- Ek EDA görselleştirme örnekleri için örnek not defteri Ek'e bakın.
- Bu öğreticide herhangi bir hatayla karşılaştıysanız, kodunuzda adım adım ilerleyebilmek için yerleşik hata ayıklayıcısını kullanmayı deneyin. bkz. hata ayıklama not defterleri.
- Analizinizi anlayabilmeleri için not defterinizi ekibinizle paylaşın. Onlara verdiğiniz izinlere bağlı olarak, analiz için kod geliştirmenize veya daha fazla araştırma için açıklamalar ve öneriler eklemenize yardımcı olabilir.
- Analizinizi tamamladıktan sonra paydaşlarla paylaşabileceğiniz önemli görselleştirmeleri içeren bir not defteri panosu veya AI/BI panosu oluşturun.