Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Note
Lakebase Değişiklik Veri Akışı özelliği Genel Önizleme aşamasındadır.
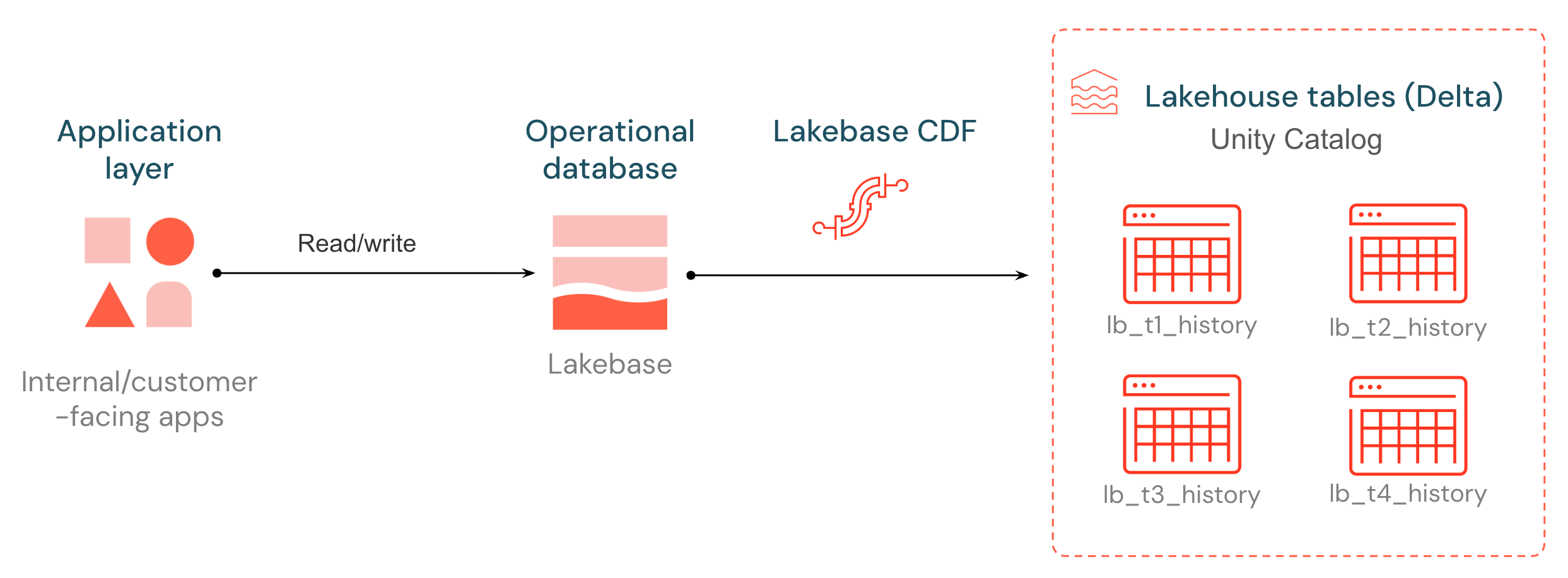
Lakebase Veri Değişikliği Akışı nedir?
Lakebase, aşağı akış işlem hatları, modeller ve uygulamalar için işletimsel verilerinizin kilidini açan yerel bir Değişiklik Veri Akışı (CDF) sunar. Lakebase Postgres tablosundaki her ekleme, güncelleştirme ve silme işlemi önceden yazma günlüğünden yakalanır ve Unity Kataloğu tarafından yönetilen Delta tablosunda yeni bir satır olarak depolanır ve yaklaşık 15 saniyede bir toplu olarak oluşturulur ve boşaltılır. Değişiklik geçmişi, herhangi bir işlem altyapısının okuyabileceği açık bir biçimde depolanır.
Hedef tablolar Delta Değişiklik Veri Akışı ile aynı şekli izler: her satır bir _pg_change_type, LSN, bir işlem kimliği ve bir zaman damgası taşır. Operasyonel değişiklikler, harici bir CDC altyapısı kurmadan ETL’de, denetimde ve alt akıştaki tüketiciler için birincil bir kaynak hâline gelir.
Kullanım örnekleri
Lakebase CDF, aşağı akış işlem hatlarının ve uygulamaların gerçekleşen değişikliklere tepki verebilmesi için operasyonel verileri göle getirir.
| Kullanım örneği | Description |
|---|---|
| ETL veri işleme hatları | Madalyon işlem hatları için bronz kaynak olarak Lakebase kullanın. Değişiklik akışını temel alarak artımlı SDP veya Spark Structured Streaming işleri oluşturun ve alt akıştaki gümüş ve altın tabloları güncelleyin. |
| Denetim günlükleri | Uyumluluk ve adli tıp için Lakebase tablosundaki her ekleme, güncelleştirme ve silme işleminin eksiksiz, sorgulanabilir geçmişini koruyun. Geçmiş değiştirilemez Delta'dır. |
| Dış sistemler | Lakebase değişiklik verilerini, herhangi bir işleme motorunun kullanabileceği açık bir biçimde depolayın. Hedef, Unity Catalog'daki bir Delta tablosu olduğundan, dış sistemler ve Databricks dışındaki okuyucular veri akışına doğrudan erişebilir. |
Bu önizlemeyi etkinleştir
Çalışma alanı yöneticisinin çalışma alanı Önizlemeleri sayfasındanLakebase Veri Akışını Değiştir önizlemesini etkinleştirmesi gerekir.
Requirements
- Lakebase Otomatik Ölçeklendirme: Postgres 17 çalıştıran bir Lakebase Otomatik Ölçeklendirme projesi .
-
Kaynak veritabanı: Tabloların
databricks_postgresLakebase'deki veritabanında bulunması gerekir. Her proje bu varsayılan veritabanıyla oluşturulur. Bu bilinen bir sınırlamadır. - Unity Kataloğu: CDF’yi yapılandıran kimliğin hedef katalog ve şema üzerinde USE CATALOG, USE SCHEMA ve CREATE TABLE izinlerine sahip olması gerekir. Bkz. Bir nesne üzerinde izin verme.
- Varsayılan depolama alanı: Varsayılan depolama ile yapılandırılan hedef kataloglar desteklenmez.
- Lakebase projesi: Postgres rolünüz, Lakebase projesinde CAN MANAGE izinlerini gerektirir. Proje sahipleri, varsayılan olarak CAN MANAGE iznine sahiptir. Bkz. Proje izinlerini yönetme.
- Veri türleri: Bkz. Veri türü eşlemesi. Doğrudan Delta eşdeğeri olmayan türler STRING olarak depolanır.
Lakebase CDF'yi ayarlama
Başlamak için, akışta yer almasını istediğiniz tablolarda replica identity ayarını full olarak yapın (1. Adım), ardından Lakebase uygulamasında CDF’yi başlatın (2. Adım). Verileriniz Unity Kataloğu kataloğunda ve seçtiğiniz şemada Delta tabloları olarak lb_<table_name>_history görünür.
1. Adım: Çoğaltma kimliğini tam olarak ayarlama
Lakebase tablosunun CDF'ye katılması için ayarlanmış olması gerekir REPLICA IDENTITY FULL . Varsayılan olarak Postgres, bir satır güncellendiğinde veya silindiğinde yalnızca birincil anahtarı günlüğe kaydeder. Kimliği tam olarak ayarlamak, Postgres'in satırın değişiklik öncesi ve sonrası durumunun her ikisini de write-ahead log'a kaydetmesini sağlar; CDF'nin eksiksiz bir değişiklik geçmişi oluşturmak için buna ihtiyacı vardır.
Bu komutları Lakebase SQL Düzenleyicisi'nde veya herhangi bir Postgres istemcisinde çalıştırabilirsiniz.
Tek tablo
ALTER TABLE <table_name> REPLICA IDENTITY FULL;
Şemadaki tüm mevcut tablolar
Bir şemadaki mevcut tüm tablolarda çoğaltma kimliğini ayarlamak için (public bu örnekte) şunu çalıştırın:
DO $$
DECLARE r record;
BEGIN
FOR r IN
SELECT table_schema, table_name
FROM information_schema.tables
WHERE table_schema = 'public'
AND table_type = 'BASE TABLE'
LOOP
EXECUTE format(
'ALTER TABLE %I.%I REPLICA IDENTITY FULL;',
r.table_schema, r.table_name
);
END LOOP;
END $$;
Gelecekteki tablolara otomatik uygulama
Yeni oluşturulan her tablonun otomatik olarak almasını REPLICA IDENTITY FULLsağlamak için bir Postgres olay tetikleyicisi yükleyin. Her CREATE TABLE işleminden sonra çalışır ve yeni tabloda kimliği ayarlar:
CREATE OR REPLACE FUNCTION public.set_full_replica_identity()
RETURNS event_trigger
LANGUAGE plpgsql
AS $$
DECLARE
obj record;
BEGIN
FOR obj IN
SELECT * FROM pg_event_trigger_ddl_commands()
WHERE command_tag = 'CREATE TABLE'
LOOP
EXECUTE format(
'ALTER TABLE %s REPLICA IDENTITY FULL;',
obj.object_identity
);
END LOOP;
END $$;
CREATE EVENT TRIGGER set_full_replica_identity_on_create
ON ddl_command_end
WHEN TAG IN ('CREATE TABLE')
EXECUTE FUNCTION public.set_full_replica_identity();
Bir kurulumda hem mevcut hem de gelecekteki tabloları kapsayacak şekilde olay tetikleyicisini önceki sekmedeki döngüyle birleştirin.
Hangi tablolarda çoğaltma kimliğinin ayarlı olduğunu denetleyin
Şemadaki hangi tabloların çoğaltma kimliğinin yapılandırıldığını görmek için şunu çalıştırın:
SELECT n.nspname AS table_schema,
c.relname AS table_name,
CASE c.relreplident
WHEN 'd' THEN 'default'
WHEN 'n' THEN 'nothing'
WHEN 'f' THEN 'full'
WHEN 'i' THEN 'index'
END AS replica_identity
FROM pg_class c
JOIN pg_namespace n ON n.oid = c.relnamespace
WHERE c.relkind = 'r'
AND n.nspname = 'public'
ORDER BY n.nspname, c.relname;
Yalnızca replica_identity = 'full' içeren satırlar CDF için hazırdır.
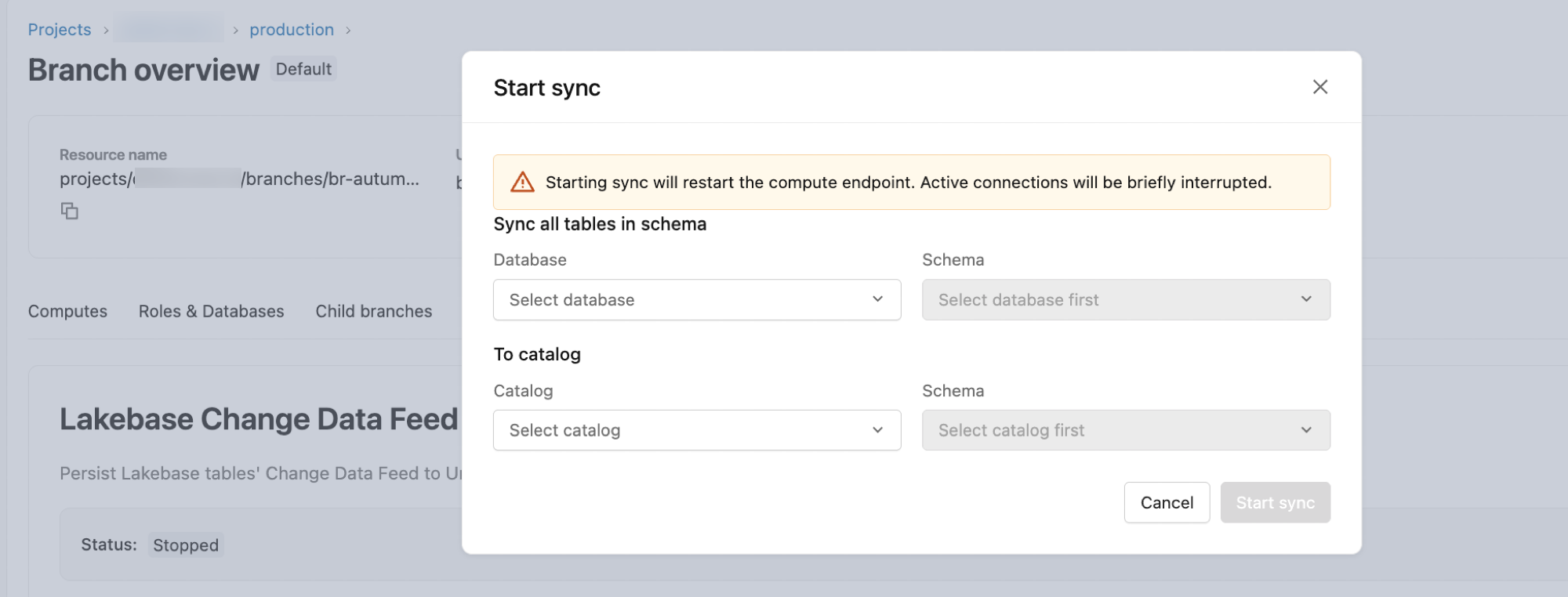
2. Adım: Değişiklik veri akışını başlatma
Lakebase CDF şema düzeyinde yapılandırılır. Başlatıldıktan sonra, kaynak şemadaki her geçerli ve gelecekteki tablo akışa eklenir.
- Azure Databricks çalışma alanınızda, uygulama değiştiriciden (sağ üst) Lakebase Postgres açın.
- Lakebase projenizi ve kullanmak istediğiniz dalı (örneğin, üretim veya ana) seçin.
- Dala genel bakış'ı açın ve Veri Akışını Değiştir sekmesine tıklayın.
- Başlat'a tıklayın.
- Yapılandırma iletişim kutusunda:
-
Veritabanı: Varsayılan olarak
databricks_postgreskullanılır. - Şema: Kaynak Postgres şemasını seçin.
- Katalog: Hedef Unity Catalog kataloğunu seçin.
- Şema: Hedef Unity Kataloğu şemasını seçin.
-
Veritabanı: Varsayılan olarak
- Akışı başlatmak için Başlat'a tıklayın.
Tablolar hedefte lb_<table_name>_history olarak görünür. Bunları bulmak için kenar çubuğunda Katalog'u açın, hedef kataloğa ve şemaya gidin ve Tablolar sekmesini açın.
Lakebase'deki Veri Akışını Değiştir sekmesinde iki alt sekme vardır:
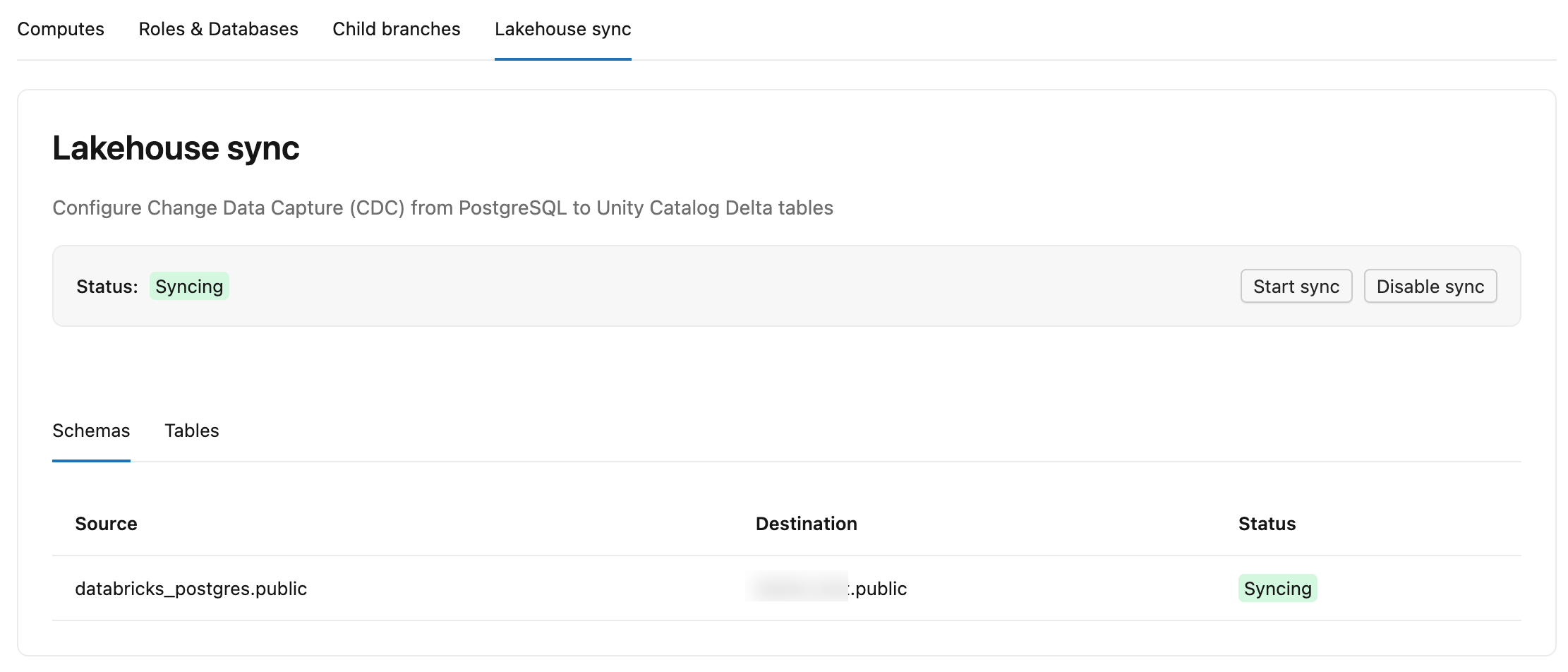
- Şemalar: Her kaynak şemayı, Unity Catalog’daki hedef katalog ve şemasını ve durumunu listeler.
-
Tablolar: Her bir kaynak tabloyu, hedef
lb_<table_name>_historytablosunu, durumunu (StreamingveyaSnapshotting), Committed LSN'yi (akışın Delta'ya ne kadar yazdığını; hâlâ ilk anlık görüntü aşamasındayken-olarak gösterilir) ve Last update'i (tablonun en son ne zaman değişiklik aldığını) listeler.
Bunu Lakebase SQL Düzenleyicisi'nde çalıştırarak Postgres'ten akış durumunu da inceleyebilirsiniz:
SELECT * FROM wal2delta.tables;
Sonuç, tablo başına table_oid, status (STREAMING veya SNAPSHOTTING), committed_lsn ve last_write_time içerir.
Important
wal2delta nedir? Lakebase CDF, Lakebase işleminin içinde çalışan wal2delta Postgres uzantısıyla desteklenir. Write-ahead log (WAL) değişikliklerini yakalamak için mantıksal çözümleme kullanır ve bunları Unity Catalog’daki Delta tablolarına yazar.
Hedef tablo şeması
CDF, hedef kataloğunuzda ve şemanızda adlı lb_<table_name>_history kaynak tablo başına bir Delta tablosu yazar. Kaynak sütunlarınıza ek olarak, her satır şu sistem sütunlarını taşır:
| Column | Türü | Description |
|---|---|---|
_pg_change_type |
METİN | İşlem türü: insert, delete, update_preimageveya update_postimage. |
_pg_lsn |
BIGINT | Postgres Günlük Sırası Numarası. |
_pg_xid |
INTEGER | Postgres İşlem Kimliği. |
_timestamp |
TIMESTAMP | Değişikliğin işlendiği zaman damgası (saat dilimi olmadan). |
_sort_by |
BIGINT | Tüm değişiklikleri sıralamak için kullanılan monoton sıralama anahtarı. |
Yaygın değişiklik desenleri
-
Başlangıç anlık görüntüsü: CDF mevcut bir Lakebase tablosunda ilk kez çalıştığında, mevcut her satır
_pg_change_type = 'insert'ile yazılır. -
Güncelleştirme: Güncelleştirme iki satır oluşturur: biri
_pg_change_type = 'update_preimage'(eski satır) ve biri de (yeni satır) ile_pg_change_type = 'update_postimage'. -
Silmeler: Bir silme işlemi,
_pg_change_type = 'delete'içeren bir satır oluşturur.
Bunlar Delta Değişiklik Veri Akışı ile aynı değişiklik olaylarıdır, bu nedenle aynı aşağı akış desenleri uygulanır.
İşletimsel davranış
-
Adlandırma çakışmaları: İki kaynak tablo aynı hedef ada eşlenirse (örneğin,
sales.usersvemarketing.usersher ikisi delb_users_historyöğesine eşleniyorsa), CDF ilkinilb_users_historyolarak yazar ve ikinciye otomatik olaraklb_users_history_1soneki ekler. Unity Kataloğu'nda hedef tablolardan birini yeniden adlandırabilirsiniz ve akış çalışmaya devam eder. - Şema düzeyi kapsamı: CDF'yi bir Lakebase şemasında başlattığınızda, bu şemadaki geçerli ve gelecekteki tüm tablolar eklenir. Boş tablolar atlanır; tablonun hedefte görünmesi için en az bir satır olması gerekir.
- Bırakılan kaynak tablolar: Lakebase'e bir tablo bırakırsanız Unity Kataloğu'ndaki hedef Delta tablosu korunur.
Alt iş hatları oluşturma
Lakebase CDF, operasyonel değişikliklere tepki veren aşağı akış işlem hatları için tasarlanmıştır. Aşağıdaki örüntüler, akışı kullanmanın en basitten en esneğe doğru sıralanan üç yolunu gösterir.
Örnek senaryo. Bir e-ticaret uygulaması, siparişleri bir Postgres orders tablosuna kaydeder; her satır da bir item_id ve quantity içerir. Lojistik ekibinin canlı envanter seviyesine ihtiyacı var. CDF ile, orders üzerindeki her değişiklik Unity Catalog’daki lb_orders_history Delta tablosunda depolanır. Aşağı akış işlem hatları bu değişiklik akışını okur ve sipariş inventory_levels verildiğinde, düzenlendiğinde veya iptal edilildiğinde tabloyu güncelleştirir.
Somutlaştırılmış görünümle mevcut envanteri hesaplama
En basit kalıp, geçmiş tablosu üzerinde bir SQL somutlaştırılmış görünümüdür. Yeni değişiklik olayları geldikçe MV artımlı biçimde yenilenir ve aşağı akıştaki tüketiciler onu diğer herhangi bir tablo gibi sorgular.
CREATE MATERIALIZED VIEW inventory_levels AS
SELECT
item_id,
SUM(
CASE
-- New orders (and the "new half" of updates) decrement inventory
WHEN _pg_change_type IN ('insert', 'update_postimage') THEN -quantity
-- Cancellations (and the "old half" of updates) restore inventory
WHEN _pg_change_type IN ('delete', 'update_preimage') THEN quantity
ELSE 0
END
) AS current_inventory,
MAX(_timestamp) AS last_transaction_ts,
MAX(_pg_lsn) AS last_lsn
FROM lb_orders_history
GROUP BY item_id;
Her güncelleştirme için üretilen iki satır, net değişiklik dışında birbirini iptal eder, böylece siparişler düzenlenirken çalışan toplam doğru kalır.
Spark Declarative Pipelines ile değişiklikleri akış olarak işleyin
Yapılandırılmış bir madalyon mimarisi için Spark Bildirimli İşlem Hatlarını (SDP) kullanarak bronz, gümüş ve altın tabloları bildirin. SDP, bunları denetim noktaları ve bağımlılık yönetimini sizin için üstlenerek birbirine bağlı bir işlem hattı olarak çalıştırır.
import dlt
from pyspark.sql import functions as F
@dlt.table
def inventory_adjustments():
return (
spark.readStream.table("<catalog>.<schema>.lb_orders_history")
.withColumn(
"delta",
F.when(F.col("_pg_change_type").isin("insert", "update_postimage"), -F.col("quantity"))
.when(F.col("_pg_change_type").isin("delete", "update_preimage"), F.col("quantity"))
.otherwise(0),
)
.select("item_id", "delta", "_timestamp")
)
@dlt.expect_or_drop("non_negative_stock", "on_hand >= 0")
@dlt.table
def inventory_levels():
return (
spark.read.table("LIVE.inventory_adjustments")
.groupBy("item_id")
.agg(F.sum("delta").alias("on_hand"))
)
inventory_adjustments, readStream ile lb_orders_history'i artımlı olarak okur ve olay başına bir delta üretir.
inventory_levels, mevcut stoku hesaplamak için item_id’e göre toplar. Sistem, stok seviyesini negatife düşürecek satırları eler; bu da önceki aşamalarda bir hataya işaret eder.
Eksiksiz bir uçtan uca anlatım için bkz. Öğretici: Değişiklik verisi yakalamayı kullanarak bir ETL işlem hattı oluşturma.
Spark Yapılandırılmış Akış ile özel işleme
Tam denetime ihtiyaç duyduğunuzda — örneğin özel birleştirmeler, yan etkiler veya birden çok hedef için — geçmiş tablosunu doğrudan Spark Structured Streaming ile okuyun ve hedefinize yazmak için foreachBatch kullanın.
from pyspark.sql import functions as F
from delta.tables import DeltaTable
def update_inventory(batch_df, batch_id):
deltas = (
batch_df
.withColumn(
"delta",
F.when(F.col("_pg_change_type").isin("insert", "update_postimage"), -F.col("quantity"))
.when(F.col("_pg_change_type").isin("delete", "update_preimage"), F.col("quantity"))
.otherwise(0),
)
.groupBy("item_id")
.agg(F.sum("delta").alias("delta"))
)
target = DeltaTable.forName(spark, "<catalog>.<schema>.inventory_levels")
(target.alias("t")
.merge(deltas.alias("s"), "t.item_id = s.item_id")
.whenMatchedUpdate(set={"on_hand": F.expr("t.on_hand + s.delta")})
.whenNotMatchedInsert(values={"item_id": "s.item_id", "on_hand": "s.delta"})
.execute())
(spark.readStream.table("<catalog>.<schema>.lb_orders_history")
.writeStream
.foreachBatch(update_inventory)
.option("checkpointLocation", "/Volumes/<catalog>/<schema>/checkpoints/inventory_levels")
.start())
Her mikro grup, değişiklik olaylarını item_id'a göre toplar ve net deltaları inventory_levels içinde birleştirir.
Tasarıma göre artımlı. Her lb_<table_name>_history tablo, yalnızca eklemeli bir Delta tablosudur. Her kaynak değişikliği, işlemi işaretleyen _pg_change_type ile yeni bir satır olarak kaydedilir. Databricks SQL somutlaştırılmış görünümleri, Lakeflow Spark Declarative Pipelines akışları ve Spark Structured Streaming işlerinin tümü Delta işlem günlüğündeki yeni satırları artımlı olarak işler; bu nedenle sonraki işlem hatları yalnızca değişen miktarla orantılı kadar işlem yapar. Değişiklik semantiği satır verilerinde zaten kodlanmış olduğundan geçmiş tablosunda Delta Değişiklik Veri Akışı'nı etkinleştirmeniz gerekmez.
Veri türü eşlemesi
CDF çoğu standart PostgreSQL temel türünü destekler. Doğrudan Delta eşdeğeri olmayan türler STRING olarak depolanır.
| PostgreSQL türü | Azure Databricks Delta türü | Notlar |
|---|---|---|
| BOOLEAN | BOOLEAN | |
| INT, SMALLINT, BIGINT | INT, SMALLINT, BIGINT | |
| METIN, VARCHAR, KARAKTER | STRING | |
| JSONB | STRING | JSON dizesi olarak depolanır. |
| ENUM | STRING | Enum etiketi olarak depolanır. |
| SAYıSAL / ONDALıK | ONDALIK veya DİZE | Mümkün olduğunda kaynak duyarlığı/ölçeğini kullanır. Uyumsuz duyarlık/ölçek değerleri için kayıpsız yeniden ölçeklendirme gerçekleştirir. Duyarlık 38'i aştığında veya duyarlık/ölçek tanımsız olduğunda (sınırsız NUMERIC) STRING'e geri döner. NaN değerleri NULL ile eşlendiğinden, tüm NUMERIC/DECIMAL sütunları null olabilir. Bkz. PostgreSQL sayısal türleri. |
| DATE | DATE | |
| TIMESTAMP | TIMESTAMP_NTZ | |
| TIMESTAMPTZ | TIMESTAMP | |
| FLOAT, DOUBLE | FLOAT, DOUBLE |
STRING olarak depolanan türler:
-
Coğrafya/Geometri (PostGIS): PostGIS uzantısından türler (örneğin,
geometry,geography). -
Vektör (pgvector): pgvector uzantısındaki
vectortürü. -
Bileşik/yapı türleri: ile
CREATE TYPE ... AS (field_name type, ...)tanımlanan özel türler. Bunlar, adlandırılmış alanlara sahip satır benzeri türlerdir. -
Harita:hstore gibi harita benzeri anahtar-değer türleri (
hstoreuzantısından). Postgres'te yerleşik bir map veri tipi bulunmaz.hstoreanahtar-değer çiftlerini bir sütunda depolamanın yaygın yoludur.
Şema değişikliklerini yönetme
- Postgres'te bir tabloyu yeniden adlandırmak (örneğin,
ALTER TABLE users RENAME TO customers) akışın devam etmesi sağlar. Hedef Delta tablosu adı değişmez; kalırlb_users_history. - Şema değişiklikleri (sütun ekleme, sütunu bırakma veya sütunun veri türünü değiştirme) etkilenen tablonun yeniden anlık görüntüsünü tetikler. CDF, Postgres'ten tablonun tamamını yeniden okur ve hedef Delta tablosuna yeniden yazar.
Lakebase CDF'yi devre dışı bırakma
CDF'nin devre dışı bırakılması, projedeki tüm Lakebase şemaları için akışı durdurur.
- Azure Databricks çalışma alanınızda, uygulama değiştiriciden (sağ üst) Lakebase Postgres açın.
- Lakebase projenizi ve CDF'yi yapılandırdığınız dalı seçin.
- Dala genel bakış'ı açın ve Veri Akışını Değiştir sekmesine tıklayın.
- Devre Dışı Bırak'a tıklayın. Onay iletişim kutusunda değişikliklerin Delta tablolarına akışının durdurulacağı uyarısını gözden geçirin ve onaylamak için yeniden Devre Dışı Bırak'a tıklayın.
CDF'yi devre dışı bırakmak işleminizi yeniden başlatmaz.
Warning
CDF'yi daha sonra yeniden etkinleştirirseniz, sistem tam yeniden anlık görüntü alma işlemi gerçekleştirmez. CDF devre dışı bırakıldığında yapılan tüm değişiklikler, hedef Delta tablolarında kalıcı olarak eksiktir.
Sınırlamalar ve sorun giderme
Her tablonun durumunu (anlık görüntü alma, atlandı veya akış) Change Data Feed sekmesinde ya da Lakebase'de bunu çalıştırarak görebilirsiniz:
SELECT * FROM wal2delta.tables;
Bir tablonun akışta görünmemesiyle ilgili yaygın nedenler:
-
REPLICA IDENTITY FULLayarlanmadı: Tablo içinALTER TABLE <table_name> REPLICA IDENTITY FULL;komutunu çalıştırın. Bkz . 1. Adım: Çoğaltma kimliğini tam olarak ayarlama. - Bölümlenmiş tablolar: Lakebase bölümlenmiş tabloları desteklenmez. Bölümlenmiş tablolar içeren bir şema, bu tabloların başarısız olmasına neden olur.
- Boş tablolar: Sıfır satır içeren bir tablo, en az bir satır var olana kadar atlanır.
Sonraki Adımlar
- Spark Bildirimli İşlem Hatları ile artımlı ETL oluşturun. Ayrıntılı yönergeler için Öğretici: Değişiklik verisi yakalamayı kullanarak ETL işlem hattı oluşturma bölümüne bakın.
- Databricks SQL ile bronz katmanı sorgula. Bkz. Databricks SQL kullanarak veri ambarını kullanmaya başlama.
- Hedef Delta tablolarında zaman yolculuğu sorguları ile denetim geçmişi.