Model bileşenini değerlendirme
Bu makalede Azure Machine Learning tasarımcısındaki bir bileşen açıklanmaktadır.
Eğitilmiş bir modelin doğruluğunu ölçmek için bu bileşeni kullanın. Bir modelden oluşturulan puanları içeren bir veri kümesi sağlarsınız ve Modeli Değerlendir bileşeni bir dizi endüstri standardı değerlendirme ölçümünü hesaplar.
Modeli Değerlendir tarafından döndürülen ölçümler, değerlendirdiğiniz modelin türüne bağlıdır:
- Sınıflandırma Modelleri
- Regresyon Modelleri
- Kümeleme Modelleri
İpucu
Model değerlendirmede yeniyseniz, EdX'ten makine öğrenmesi kursunun bir parçası olarak Dr. Stephen Elston'ın video serisini öneririz.
Modeli Değerlendirme'yi kullanma
BağlanModeli Değerlendir'in sol giriş bağlantı noktasına Kümelere Veri Atama'nın Model Puanla veya Sonuç veri kümesi çıkışının puanlanmış veri kümesi çıkışı.
Not
Giriş veri kümesinin bir bölümünü seçmek için "Veri Kümesindeki Sütunları Seç" gibi bileşenler kullanıyorsanız, ikili sınıflandırma/anomali algılama için doğruluk gibi ölçümleri hesaplamak için gerçek etiket sütunu (eğitimde kullanılır), 'Puanlanan Olasılıklar' sütunu ve 'Puanlanan Etiketler' sütununun mevcut olduğundan emin olun. Çok sınıflı sınıflandırma/regresyon ölçümlerini hesaplamak için gerçek etiket sütunu olan 'Puanlanmış Etiketler' sütunu vardır. Kümeleme ölçümlerini hesaplamak için 'Atamalar' sütunu, 'DistancesToClusterCenter no.X' (X, 0, ..., Centroids-1 sayısı arasında değişen centroid dizinidir) sütunları vardır.
Önemli
- Sonuçları değerlendirmek için çıkış veri kümesinin Model Değerlendirme bileşeni gereksinimlerini karşılayan belirli puan sütun adlarını içermesi gerekir.
- Sütun
Labelsgerçek etiketler olarak kabul edilir. - Regresyon görevi için değerlendirilecek veri kümesinin puanlanmış etiketleri temsil eden adlı
Regression Scored Labelsbir sütunu olmalıdır. - İkili sınıflandırma görevi için değerlendirilecek veri kümesinin, puanlanmış etiketleri ve olasılıkları temsil eden adlı
Binary Class Scored LabelsBinary Class Scored Probabilitiesiki sütunu olmalıdır. - Çoklu sınıflandırma görevi için değerlendirilecek veri kümesinin puanlanmış etiketleri temsil eden adlı
Multi Class Scored Labelsbir sütunu olmalıdır. Yukarı akış bileşeninin çıkışlarında bu sütunlar yoksa, yukarıdaki gereksinimlere göre değiştirmeniz gerekir.
[İsteğe bağlı] BağlanModeli Değerlendir'in doğru giriş bağlantı noktasına ikinci model için Kümelere Veri Atama'nın Model Puanla veya Sonuç veri kümesi çıkışının puanlanmış veri kümesi çıktısı. Aynı verilerde iki farklı modelin sonuçlarını kolayca karşılaştırabilirsiniz. İki giriş algoritması aynı algoritma türünde olmalıdır. Alternatif olarak, aynı veriler üzerinde iki farklı çalıştırmanın puanlarını farklı parametrelerle karşılaştırabilirsiniz.
Not
Algoritma türü , 'Machine Learning Algoritmaları' altındaki 'İki Sınıflı Sınıflandırma', 'Çok Sınıflı Sınıflandırma', 'Regresyon', 'Kümeleme' anlamına gelir.
Değerlendirme puanlarını oluşturmak için işlem hattını gönderin.
Sonuçlar
Modeli Değerlendir'i çalıştırdıktan sonra sağ taraftaki Modeli Değerlendir gezinti panelini açmak için bileşeni seçin. Ardından Çıkışlar + Günlükler sekmesini seçin ve bu sekmede Veri Çıkışları bölümünde birkaç simge bulunur. Görselleştir simgesi bir çubuk grafik simgesine sahiptir ve sonuçları görmenin ilk yoludur.
İkili sınıflandırma için Görselleştir simgesine tıkladıktan sonra ikili karışıklık matrisini görselleştirebilirsiniz. Çoklu sınıflandırma için, karışıklık matrisi çizim dosyasını Çıkışlar + Günlükler sekmesinin altında aşağıdaki gibi bulabilirsiniz:
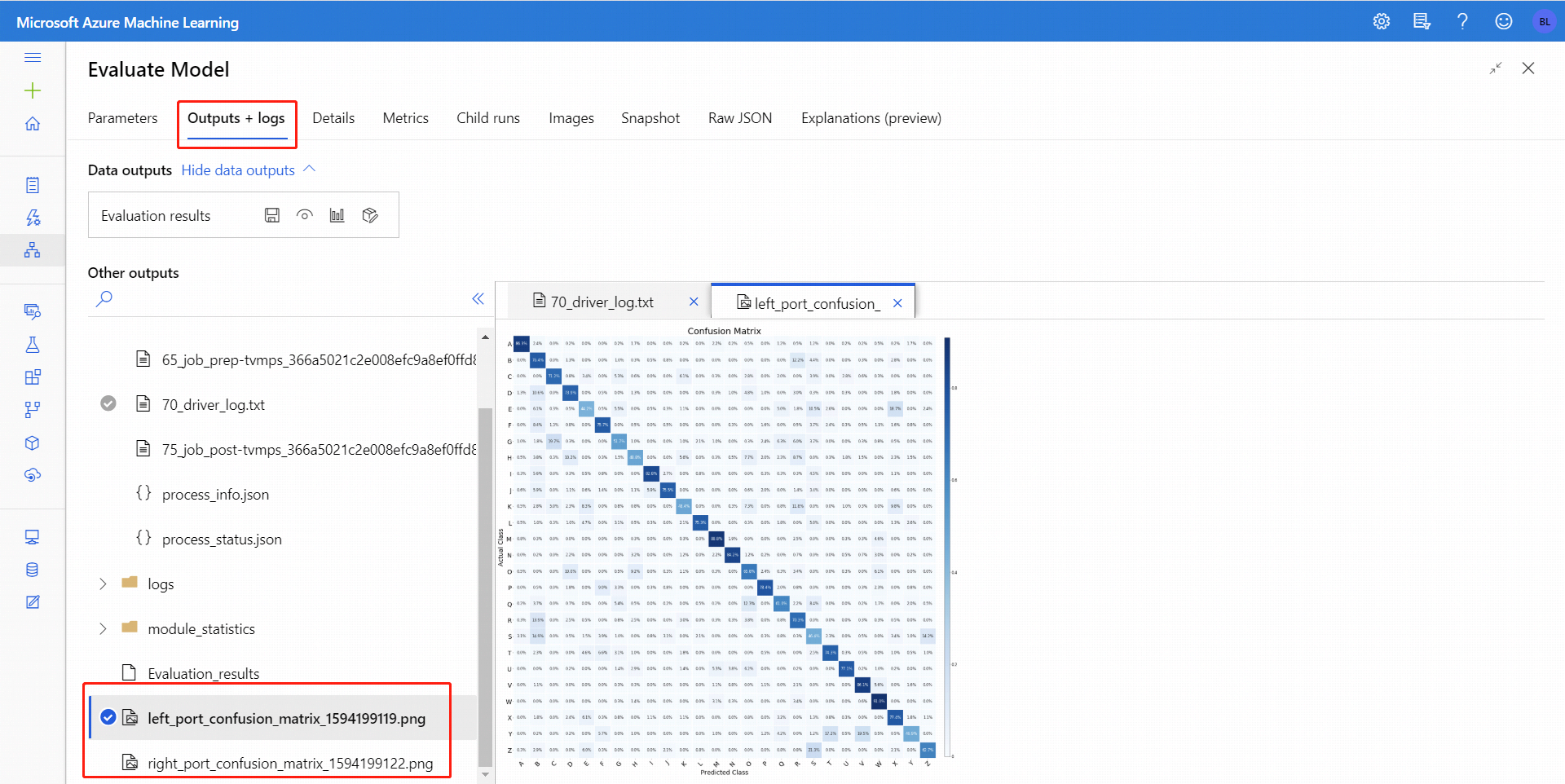
Veri kümelerini Modeli Değerlendir'in her iki girişine bağlarsanız, sonuçlar her iki veri kümesi veya her iki model için ölçümler içerir. Sol bağlantı noktasına eklenen model veya veriler önce raporda, ardından veri kümesi ölçümleri veya sağ bağlantı noktasına eklenen model gösterilir.
Örneğin, aşağıdaki görüntü aynı veriler üzerinde oluşturulmuş ancak farklı parametrelerle oluşturulmuş iki kümeleme modelinin sonuçlarının karşılaştırmasını temsil eder.
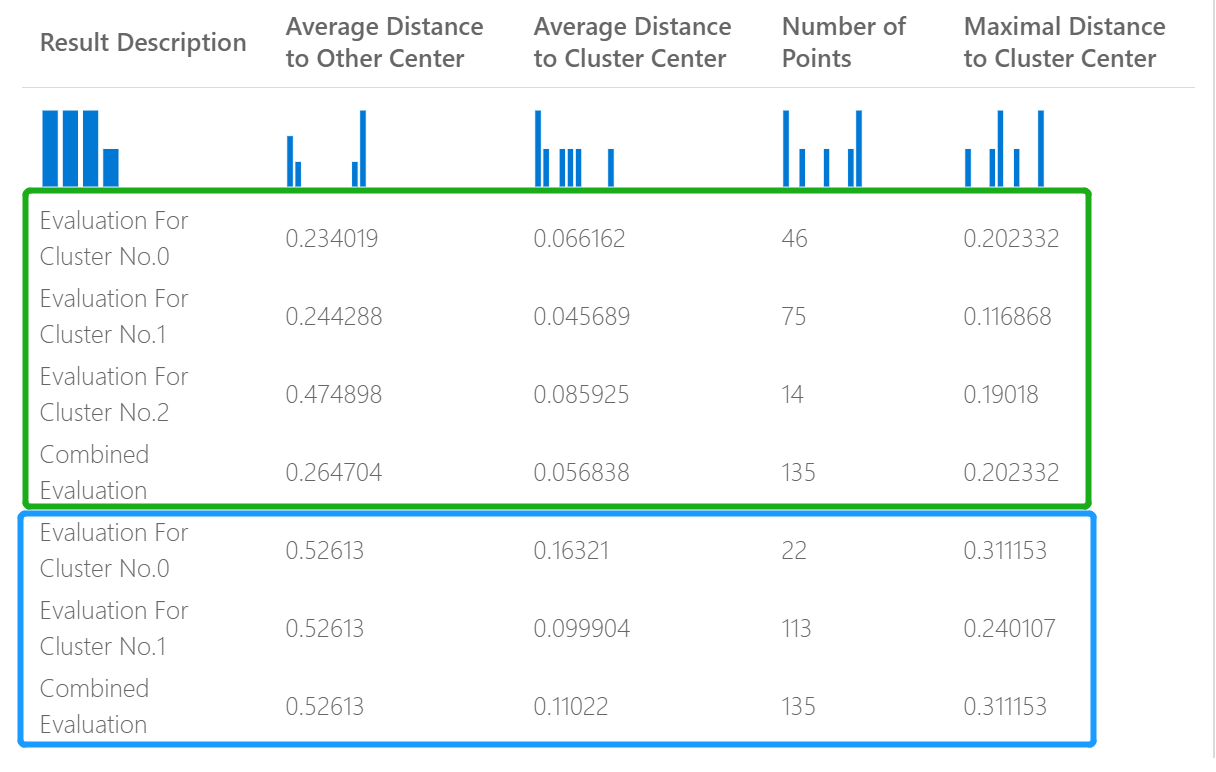
Bu bir kümeleme modeli olduğundan değerlendirme sonuçları, iki regresyon modelindeki puanları karşılaştırdığınızdan veya iki sınıflandırma modelini karşılaştırdığınızdan farklıdır. Ancak, genel sunu aynıdır.
Ölçümler
Bu bölümde, Modeli Değerlendir ile kullanılmak üzere desteklenen belirli model türleri için döndürülen ölçümler açıklanmaktadır:
Sınıflandırma modelleri için ölçümler
İkili sınıflandırma modelleri değerlendirilirken aşağıdaki ölçümler bildirilir.
Doğruluk , bir sınıflandırma modelinin iyiliğini, gerçek sonuçların toplam vakalara oranı olarak ölçer.
Duyarlık , tüm pozitif sonuçlara göre gerçek sonuçların oranıdır. Duyarlık = TP/(TP+FP)
Geri çağırma , gerçekten alınan ilgili örneklerin toplam miktarının bölümüdür. Geri çağırma = TP/(TP+FN)
F1 puanı, ideal F1 puan değerinin 1 olduğu 0 ile 1 arasında ağırlıklı duyarlık ve yakalama ortalaması olarak hesaplanır.
AUC , y ekseninde gerçek pozitifler ve x ekseninde yanlış pozitiflerle çizilen eğrinin altındaki alanı ölçer. Bu ölçüm, farklı türlerdeki modelleri karşılaştırmanıza olanak tanıyan tek bir sayı sağladığından kullanışlıdır. AUC, sınıflandırma-eşik sabitidir. Hangi sınıflandırma eşiğinin seçildiğinden bağımsız olarak modelin tahminlerinin kalitesini ölçer.
Regresyon modelleri için ölçümler
Regresyon modelleri için döndürülen ölçümler hata miktarını tahmin etmek üzere tasarlanmıştır. Gözlemlenen ve tahmin edilen değerler arasındaki fark küçükse modelin verilere uygun olduğu kabul edilir. Ancak artıkların desenine (tahmin edilen herhangi bir nokta ile karşılık gelen gerçek değer arasındaki fark) bakmak, modeldeki olası sapmalar hakkında size çok şey söyleyebilir.
Doğrusal regresyon modellerini değerlendirmek için aşağıdaki ölçümler bildirilmiştir. Fast Forest Quantile Regression gibi diğer yeniden gression modellerinin farklı ölçümleri olabilir.
Ortalama mutlak hata (MAE), tahminlerin gerçek sonuçlara ne kadar yakın olduğunu ölçer; bu nedenle daha düşük bir puan daha iyidir.
Kök ortalama kare hatası (RMSE), modeldeki hatayı özetleyen tek bir değer oluşturur. Ölçüm, farkın karesini alarak fazla tahmin ile düşük tahmin arasındaki farkı göz ardı eder.
Göreli mutlak hata (RAE), beklenen ve gerçek değerler arasındaki göreli mutlak farktır; görelidir çünkü ortalama farkı aritmetik ortalamaya bölünür.
Göreli kare hatası (RSE), tahmin edilen değerlerin toplam kare hatasını, gerçek değerlerin toplam kare hatasına bölerek benzer şekilde normalleştirir.
Genellikle R2 olarak adlandırılan belirleme katsayısı, modelin tahmin gücünü 0 ile 1 arasında bir değer olarak temsil eder. Sıfır, modelin rastgele olduğu anlamına gelir (hiçbir şeyi açıklamaz); 1, mükemmel bir uyum olduğu anlamına gelir. Ancak, düşük değerler tamamen normal olabileceğinden ve yüksek değerler şüpheli olabileceğinden R2 değerlerinin yorumlanmasında dikkatli olunmalıdır.
Kümeleme modelleri için ölçümler
Kümeleme modelleri sınıflandırma ve regresyon modellerinden birçok açıdan önemli ölçüde farklı olduğundan, Modeli Değerlendir, kümeleme modelleri için farklı bir istatistik kümesi de döndürür.
Kümeleme modeli için döndürülen istatistikler, her kümeye kaç veri noktası atandığını, kümeler arasındaki ayrım miktarını ve veri noktalarının her küme içinde ne kadar sıkı bir şekilde toplandığını açıklar.
Kümeleme modelinin istatistikleri, küme başına istatistikleri içeren ek satırlarla tüm veri kümesinin ortalamasını alır.
Kümeleme modellerini değerlendirmek için aşağıdaki ölçümler bildirilir.
Diğer Merkeze Ortalama Uzaklık sütunundaki puanlar, kümedeki her bir noktanın diğer tüm kümelerin centroid'lerine ne kadar yakın olduğunu gösterir.
Küme Merkezi'ne Ortalama Uzaklık sütunundaki puanlar, kümedeki tüm noktaların bu kümenin merkezine yakınlığını temsil eder.
Nokta Sayısı sütunu, her kümeye kaç veri noktası atandığını ve tüm kümelerdeki toplam veri noktası sayısını gösterir.
Kümelere atanan veri noktası sayısı kullanılabilir toplam veri noktası sayısından azsa, bu veri noktalarının bir kümeye atanamadığı anlamına gelir.
Küme Merkezine En Yüksek Uzaklık sütunundaki puanlar, her nokta ile bu noktanın kümesinin merkezi arasındaki uzaklıkların maksimumunu temsil eder.
Bu sayı yüksekse, kümenin geniş ölçüde dağınık olduğu anlamına gelebilir. Kümenin yayılmasını belirlemek için bu istatistiği Küme Merkezi'ne Ortalama Uzaklık ile birlikte gözden geçirmelisiniz.
Sonuçların her bölümünün altındaki Birleşik Değerlendirme puanı, söz konusu modelde oluşturulan kümeler için ortalama puanlar listeler.
Sonraki adımlar
Bkz. Azure Machine Learning için kullanılabilen bileşenler kümesi.