Not
Bu sayfaya erişim yetkilendirme gerektiriyor. Oturum açmayı veya dizinleri değiştirmeyi deneyebilirsiniz.
Bu sayfaya erişim yetkilendirme gerektiriyor. Dizinleri değiştirmeyi deneyebilirsiniz.
Şunlar için geçerlidir: SQL Server 2019 (15.x) ve sonraki sürümleri![]()
28 Şubat 2025'te SQL Server 2019 Büyük Veri Kümeleri kullanımdan kaldırıldı. Daha fazla bilgi için duyuru blog gönderisine bakın.
SQL Server'da PolyBase desteğindeki değişiklikler
SQL Server 2019 Büyük Veri Kümelerinin kullanımdan kaldırılmasıyla ilgili olarak, ölçeği genişletme sorguları ile ilgili bazı özellikler vardır.
Microsoft SQL Server'ın PolyBase ölçek genişletme grupları özelliği kullanımdan kaldırıldı. Sql Server 2022'de (16.x) ölçeği genişletme grubu işlevi üründen kaldırılır. SQL Server 2019, SQL Server 2017 ve SQL Server 2016'nın pazar içi sürümleri, bu ürünlerin kullanım ömrünün sonuna kadar olan işlevselliği desteklemeye devam eder. PolyBase veri sanallaştırması, SQL Server'da bir ölçek artırma özelliği olarak tam olarak desteklenmeye devam eder.
Cloudera (CDP) ve Hortonworks (HDP) Hadoop dış veri kaynakları da SQL Server'ın tüm pazar içi sürümleri için kullanımdan kaldırılacaktır ve SQL Server 2022'ye dahil değildir. Dış veri kaynaklarına yönelik destek, ilgili satıcının temel destek kapsamındaki ürün sürümleriyle sınırlıdır. SQL Server 2022'de (16.x) kullanılabilen yeni nesne depolama tümleştirmesini kullanmanız tavsiye edilir.
SQL Server 2022 (16.x) ve sonraki sürümlerinde, kullanıcıların Dış veri kaynaklarını Azure Depolama'ya bağlanırken yeni bağlayıcıları kullanacak şekilde yapılandırmaları gerekir. Aşağıdaki tabloda değişiklik özetlemektedir:
| Dış Veri Kaynağı | From | To |
|---|---|---|
| Azure Blob Saklama Alanı | wasb[s] |
abs |
| ADLS 2. Nesil | abfs[s] |
adls |
Note
Azure Blob Depolama (abs), veritabanı kapsamlı kimlik bilgilerindeki SECRET için Paylaşılan Erişim İmzası (SAS) kullanımını gerektirir. SQL Server 2019 ve önceki sürümlerinde, Azure Depolama hesabında kimlik doğrulaması yaparken wasb[s] bağlayıcı, veritabanı kapsamındaki kimlik bilgileri ile Depolama Hesabı Anahtarı'nı kullanıyordu.
Değiştirme ve geçiş seçenekleri için Büyük Veri Kümeleri mimarisini anlama
Büyük Veri depolama ve işleme sistemi için yeni çözümünüzü oluşturmak için, hangi SQL Server 2019 Büyük Veri Kümeleri'nin sağlandığını ve mimarisinin seçimlerinizi bilgilendirmenize yardımcı olabileceğini anlamanız önemlidir. Büyük veri kümesinin mimarisi şöyleydi:

Bu mimari aşağıdaki işlevsellik eşlemesini sağladı:
| Component | Benefit |
|---|---|
| Kubernetes | Kapsayıcı tabanlı uygulamaları büyük ölçekte dağıtmak ve yönetmek için açık kaynak düzenleyici. Esnek ölçekle ortamın tamamı için dayanıklılık, yedeklilik ve taşınabilirlik oluşturmak ve denetlemek için bildirim temelli bir yöntem sağlar. |
| Büyük Veri Kümeleri Denetleyicisi | Küme için yönetim ve güvenlik sağlar. Denetim hizmetini, yapılandırma deposunu ve Kibana, Grafana ve Elastik Arama gibi küme düzeyindeki diğer hizmetleri içerir. |
| İşlem Havuzu | Kümeye işlem kaynakları sağlar. Linux podlarında SQL Server çalıştıran düğümleri içerir. İşlem havuzundaki podlar, belirli işleme görevleri için SQL İşlem örneklerine ayrılır. Bu bileşen, verileri taşımadan veya kopyalamadan dış veri kaynaklarını sorgulamak için PolyBase kullanarak Veri Sanallaştırma da sağlar. |
| Veri Havuzu | Küme için veri kalıcılığı sağlar. Veri havuzu, Linux üzerinde SQL Server çalıştıran bir veya daha fazla poddan oluşur. SQL sorgularından veya Spark işlerinden veri almak için kullanılır. |
| Depolama Havuzu | Depolama havuzu Linux, Spark ve HDFS üzerinde SQL Server'ın oluşturduğu depolama havuzu podlarından oluşur. Büyük veri kümesindeki tüm depolama düğümleri hdfs kümesinin üyeleridir. |
| Uygulama Havuzu | Uygulamaları oluşturmak, yönetmek ve çalıştırmak için arabirimler sağlayarak büyük bir veri kümesinde uygulamaların dağıtımını sağlar. |
Bu işlevler hakkında daha fazla bilgi için bkz. SQL Server Büyük Veri Kümelerine Giriş.
Büyük Veri ve SQL Server için işlevsellik değiştirme seçenekleri
Büyük Veri Kümeleri içindeki SQL Server tarafından kolaylaştırılan işletimsel veri işlevi, hibrit bir yapılandırmada veya Microsoft Azure platformu kullanılarak şirket içi SQL Server ile değiştirilebilir. Microsoft Azure, modern uygulama geliştiricilerinin gereksinimlerine uygun, özel ve açık kaynak altyapıları kapsayan, tam olarak yönetilen ilişkisel, NoSQL ve bellek içi veritabanlarından oluşan bir seçenek sunar. Ölçeklenebilirlik, kullanılabilirlik ve güvenlik de dahil olmak üzere altyapı yönetimi otomatiktir ve zamandan ve paradan tasarruf etmenizi sağlar ve Azure tarafından yönetilen veritabanları tümleşik zeka aracılığıyla performans içgörüleri elde ederek, sınırsız ölçeklendirme yaparak ve güvenlik tehditlerini yöneterek işinizi kolaylaştırırken uygulama oluşturmaya odaklanmanızı sağlar. Daha fazla bilgi için bkz. Azure veritabanları.
Bir sonraki karar noktası analiz için işlem ve veri depolama konumlarıdır. İki mimari seçeneği bulut içi ve karma dağıtımlardır. Analiz iş yüklerinin çoğu Microsoft Azure platformuna geçirilebilir. "Bulutta doğan" veriler (Bulut tabanlı uygulamalardan kaynaklanır) bu teknolojiler için en önemli adaylardır ve veri taşıma hizmetleri büyük ölçekli şirket içi verileri güvenli ve hızlı bir şekilde geçirebilir. Veri taşıma seçenekleri hakkında daha fazla bilgi için bkz. Veri aktarımı çözümleri.
Microsoft Azure, çeşitli araçlarda güvenli veri ve veri işlemeye olanak sağlayan sistemlere ve sertifikalara sahiptir. Bu sertifikalar hakkında daha fazla bilgi için bkz. Güven Merkezi.
Note
Microsoft Azure platformu, çok yüksek düzeyde güvenlik, çeşitli sektörler için birden fazla sertifika sağlar ve kamu gereksinimleri için veri hakimiyetini yerine getirir. Microsoft Azure ayrıca kamu iş yükleri için ayrılmış bir bulut platformuna sahiptir. Şirket içi sistemler için birincil karar noktası yalnızca güvenlik olmamalıdır. Büyük veri çözümlerinizi şirket içinde tutmaya karar vermeden önce Microsoft Azure tarafından sağlanan güvenlik düzeyini dikkatle değerlendirmeniz gerekir.
Bulut içi mimari seçeneğinde tüm bileşenler Microsoft Azure'da bulunur. Sizin sorumluluğunuzda, iş yüklerinizin depolanması ve işlenmesi için oluşturduğunuz veriler ve kodlar yer alır. Bu seçenekler bu makalede daha ayrıntılı olarak ele alınmıştır.
- Bu seçenek, verilerin depolanması ve işlenmesi için çok çeşitli bileşenler için ve altyapı yerine veri ve işleme yapılarına odaklanmak istediğinizde en iyi şekilde çalışır.
Karma mimari seçeneklerinde, bazı bileşenler şirket içinde tutulur ve diğerleri bir Bulut Sağlayıcısına yerleştirilir. İkisi arasındaki bağlantı, veri işlemenin en iyi şekilde konumlandırılması için tasarlanmıştır.
- Bu seçenek, şirket içi teknolojilere ve mimarilere önemli bir yatırım yaptığınızda ancak Microsoft Azure tekliflerini kullanmak istediğinizde veya şirket içinde veya dünya çapında bir hedef kitle için işleme ve uygulama hedefleriniz olduğunda en iyi sonucu verir.
Ölçeklenebilir mimariler oluşturma hakkında daha fazla bilgi için bkz. Çok büyük veriler için ölçeklenebilir bir sistem oluşturma.
In-cloud
Azure SQL ve Azure Machine Learning
İşletimsel veriler için bir veya daha fazla Azure SQL veritabanı seçeneğini ve tahmine dayalı iş yükleriniz için Microsoft Azure Machine Learning'i kullanarak SQL Server Büyük Veri Kümelerinin işlevselliğini değiştirebilirsiniz.
Azure Machine Learning, klasik ML'den derin öğrenme, denetimli ve denetimsiz öğrenmeye kadar her tür makine öğrenmesi için kullanılabilen bulut tabanlı bir hizmettir. İster SDK ile Python veya R kodu yazmayı tercih edin ister stüdyoda kod yok/düşük kod seçenekleriyle çalışın, Azure Machine Learning Çalışma Alanı'nda makine öğrenmesi ve derin öğrenme modelleri oluşturabilir, eğitebilir ve izleyebilirsiniz. Azure Machine Learning ile yerel makinenizde eğitime başlayabilir ve ardından ölçeği buluta genişletebilirsiniz. Hizmet ayrıca PyTorch, TensorFlow, scikit-learn ve Ray RLlib gibi popüler derin öğrenme ve pekiştirici açık kaynak araçlarıyla birlikte çalışıyor.
İhtiyacınız olduğunda SQL Server 2019 Büyük Veri Kümelerinin yerine Microsoft Azure Machine Learning'i kullanın:
- Machine Learning için tasarımcı tabanlı bir web ortamı: Denemelerinizi oluşturmak ve ardından işlem hatlarını düşük kodlu bir ortamda dağıtmak için modülleri sürükleyip bırakın.
- Jupyter not defterleri: Örnek not defterlerimizi kullanın veya makine öğrenmeniz için Python için SDK örneklerimizi kullanmak üzere kendi not defterlerinizi oluşturun.
- Kendi kodunuzu yazmak veya tasarımcıda R modüllerini kullanmak için R için SDK'sını kullandığınız R betikleri veya not defterleri.
- Çok Modelli Çözüm Hızlandırıcısı, Azure Machine Learning'i derler ve yüzlerce, hatta binlerce makine öğrenmesi modeli eğitip çalıştırmanızı ve yönetmenizi sağlar.
- Visual Studio Code (önizleme) için makine öğrenmesi uzantıları, makine öğrenmesi projelerinizi oluşturmaya ve yönetmeye yönelik tam özellikli bir geliştirme ortamı sağlar.
- Makine öğrenmesi Command-Line Arabirimi (CLI), Azure Machine Learning, komut satırından Azure Machine Learning kaynaklarıyla yönetmeye yönelik komutlar sağlayan bir Azure CLI uzantısı içerir.
- PyTorch, TensorFlow ve scikit-learn gibi açık kaynaklı çerçevelerle entegrasyon ve daha birçoklarıyla uçtan uca makine öğrenmesi sürecini eğitmek, dağıtmak ve yönetmek.
- Ray RLlib ile pekiştirici öğrenme.
- MLflow'u, ölçümleri izlemek ve modelleri dağıtmak için veya uçtan uca iş akışı işlem hatları oluşturmak için Kubeflow'u kullanın.
Microsoft Azure Machine Learning dağıtımının mimarisi aşağıdaki gibidir:

Microsoft Azure Machine Learning hakkında daha fazla bilgi için bkz. Azure Machine Learning nasıl çalışır?
Databricks'ten Azure SQL
İşletimsel veriler için bir veya daha fazla Azure SQL veritabanı seçeneğini ve analitik iş yükleriniz için Microsoft Azure Databricks'i kullanarak SQL Server Büyük Veri Kümelerinin işlevselliğini değiştirebilirsiniz.
Azure Databricks, Microsoft Azure bulut hizmetleri platformu için iyileştirilmiş bir veri analizi platformudur. Azure Databricks, yoğun veri gerektiren uygulamalar geliştirmek için iki ortam sunar: Azure Databricks SQL Analytics ve Azure Databricks Çalışma Alanı.
Azure Databricks SQL Analytics, veri gölünde SQL sorguları çalıştırmak, farklı perspektiflerden sorgu sonuçlarını keşfetmek için birden çok görselleştirme türü oluşturmak ve pano oluşturup paylaşmak isteyen analistler için kullanımı kolay bir platform sağlar.
Azure Databricks Çalışma Alanı, veri mühendisleri, veri bilimciler ve makine öğrenmesi mühendisleri arasında işbirliğine olanak tanıyan etkileşimli bir çalışma alanı sağlar. Büyük bir veri süreci için, veriler (ham veya yapılandırılmış) Azure Data Factory aracılığıyla toplu olarak Azure'a alınır veya Apache Kafka, Event Hubs ya da IoT Hub kullanılarak gerçek zamanlıya yakın olarak aktarılır. Bu veriler, Azure Blob Depolama veya Azure Data Lake Storage'da uzun süreli kalıcı depolama için bir veri gölüne iner. Analiz iş akışınızın bir parçası olarak Azure Databricks'i kullanarak birden çok veri kaynağından verileri okuyun ve Spark kullanarak bu verileri çığır açan içgörülere dönüştürün.
İhtiyacınız olduğunda SQL Server 2019 Büyük Veri Kümelerinin yerine Microsoft Azure Databricks'i kullanın:
- Spark SQL ve DataFrames ile tam olarak yönetilen Spark kümeleri.
- Gerçek zamanlı veri işleme ve analiz açısından akış, analitik ve etkileşimli uygulamalar için; HDFS, Flume ve Kafka ile entegrasyon sağlar.
- Sınıflandırma, regresyon, kümeleme, işbirliğine dayalı filtreleme, boyut azaltma ve temel iyileştirme temelleri gibi yaygın öğrenme algoritmaları ve yardımcı programlarından oluşan MLlib kitaplığına erişim.
- R, Python, Scala veya SQL'deki not defterlerinde ilerleme durumunuzla ilgili belgeler.
- Matplotlib, ggplot veya d3 gibi tanıdık araçları kullanarak birkaç adımda verilerin görselleştirilmesi.
- Dinamik raporlar oluşturmak için etkileşimli panolar.
- GraphX, bilişsel analizden veri keşfetmeye kadar geniş bir kullanım örnekleri kapsamına yönelik Grafikler ve graf hesaplaması için.
- Dinamik otomatik ölçeklendirme kümeleriyle saniyeler içinde küme oluşturma ve bunları ekipler arasında paylaşma.
- REST API'lerini kullanarak programlı küme erişimi.
- Her sürümde en son Apache Spark özelliklerine anında erişim.
- Spark Core API'si: R, SQL, Python, Scala ve Java desteği içerir.
- Keşif ve görselleştirme için etkileşimli bir çalışma alanı.
- Bulutta tam olarak yönetilen SQL uç noktaları.
- Sorgu gecikme süresine ve eşzamanlı kullanıcı sayısına göre boyutlandırılmış, tam olarak yönetilen SQL uç noktaları üzerinde çalışan SQL sorguları.
- Microsoft Entra Id (eski adıyla Azure Active Directory) ile tümleştirme.
- Not defterleri, kümeler, işler ve veriler için ayrıntılı kullanıcı izinleri için rol tabanlı erişim.
- Kurumsal sınıf SLA'lar.
- İçgörüleri paylaşma, sorgularınızdan alınan içgörüleri paylaşmak için görselleştirmeleri ve metinleri birleştirmeye yönelik panolar.
- Uyarılar, bir sorgu tarafından döndürülen bir alan belirli bir eşik seviyesine ulaştığında bunu izlemenize, entegre etmenize ve bildirim almanıza yardımcı olur. Uyarıları, işinizi izlemek için kullanın veya bunları araçlarla tümleştirerek kullanıcı ekleme ya da destek biletleri gibi iş akışlarını başlatın.
- Microsoft Entra ID tümleştirmesi, rol tabanlı denetimler ve verilerinizi ve işletmenizi koruyan SLA'lar dahil olmak üzere kurumsal güvenlik.
- Synapse Analytics, Cosmos DB, Data Lake Store ve Blob depolama gibi Azure hizmetleri ve Azure veritabanları ve depolarıyla tümleştirme.
- Power BI ve Tableau Software gibi diğer BI araçlarıyla tümleştirme.
Microsoft Azure Databricks dağıtımının mimarisi aşağıdaki gibidir:
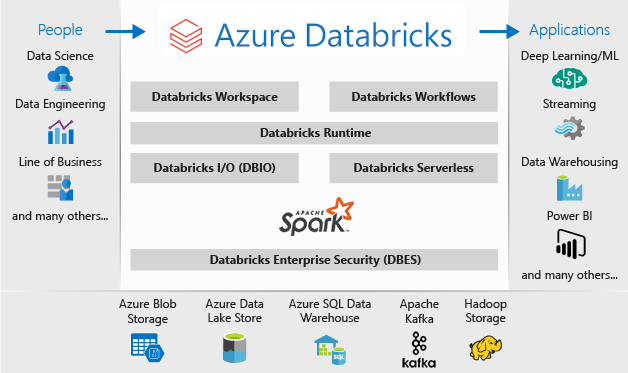
Microsoft Azure Databricks hakkında daha fazla bilgi için bkz. Databricks Veri Bilimi ve Mühendisliği nedir?
Hybrid
Microsoft Fabric'te yansıtma işlemi
Veri çoğaltma deneyimi olarak Dokuda Veritabanı Yansıtma , çeşitli sistemlerdeki verileri tek bir analiz platformunda bir araya getiren düşük maliyetli ve düşük gecikme süreli bir çözümdür. SQL Server 2016+, Azure SQL Veritabanı, Azure SQL Yönetilen Örneği, Oracle, Snowflake, Cosmos DB ve daha fazlası dahil olmak üzere mevcut veri varlığınızı doğrudan Fabric'in OneLake'ine çoğaltabilirsiniz.
OneLake'de sorgulanabilir biçimdeki en güncel verilerle artık Spark ile analiz çalıştırma, not defterlerini yürütme, veri mühendisliği, Power BI Raporları aracılığıyla görselleştirme ve daha fazlası gibi Doku'daki tüm farklı hizmetleri kullanabilirsiniz.
Fabric'te Yansıtma, veri taşımak için pahalı Ayıklama, Dönüştürme ve Yükleme (ETL) işlemleri geliştirmeden, teknoloji çözümleri arasındaki veri silolarını ortadan kaldırmak ve içgörüler ile kararlar için değer elde etme süresini hızlandıran kolay bir deneyim sağlar.
Fabric'in Mirroring özelliği ile birden çok satıcıdan farklı hizmetleri bir araya getirmenize gerek yok. Bunun yerine, analiz ihtiyaçlarınızı basitleştirmek için tasarlanmış ve açık kaynak Delta Lake tablo biçimini okuyabilen teknoloji çözümleri arasında açıklık ve işbirliği için oluşturulmuş yüksek oranda tümleşik, uçtan uca ve kullanımı kolay bir ürünün keyfini çıkarabilirsiniz.
Daha fazla bilgi için bakınız:
- Microsoft Fabric yansıma veritabanları
- Microsoft Fabric aynalanmış veritabanları izleme
- Microsoft Fabric kullanarak Yansıtılmış veritabanınızdaki verileri keşfetme
- Microsoft Fabric nedir?
- Microsoft Fabric'te varsayılan Power BI anlam modelinde verileri modelleme
- Lakehouse için SQL analiz uç noktası nedir?
- Direct Lake
Windows üzerinde Microsoft SQL Server, Apache Spark ve şirket içi nesne depolama
Sql Server'ı Windows veya Linux'a yükleyebilir ve SQL Server 2022 (16.x) nesne depolama sorgu özelliğini ve PolyBase özelliğini kullanarak sisteminizdeki tüm veriler arasında sorguları etkinleştirerek donanım mimarisinin ölçeğini artırabilirsiniz.
Apache Hadoop veya Apache Spark gibi bir genişleme platformu yüklemek ve yapılandırmak, ilişkisel olmayan verilerin büyük ölçekte sorgulanabilmesini sağlar. S3-API destekleyen merkezi bir Object-Storage sistemi kümesi kullanmak hem SQL Server 2022 (16.x) hem de Spark'ın tüm sistemlerde aynı veri kümesine erişmesine olanak tanır.
Dağıtımınız için Kubernetes kapsayıcı düzenleme sistemini de kullanabilirsiniz. Bu, şirket içinde veya Kubernetes'i veya Red Hat OpenShift platformunu destekleyen herhangi bir Bulutta çalışabilen bildirim temelli mimariye olanak tanır. SQL Server'ı Kubernetes ortamına dağıtma hakkında daha fazla bilgi edinmek için bkz. Azure'da SQL Server kapsayıcı kümesi dağıtma veya Kubernetes'te SQL Server 2019 dağıtma.
Aşağıdaki durumlarda SQL Server 2019 Büyük Veri Kümelerinin yerine SQL Server ve Hadoop/Spark şirket içi kullanın:
- Çözümün tamamını şirket içinde tutma
- Çözümün tüm bölümleri için ayrılmış donanım kullanma
- Her iki yönde de aynı mimariden ilişkisel ve ilişkisel olmayan verilere erişme
- SQL Server ve ölçeklenebilir ilişkisel olmayan sistem arasında tek bir ilişkisel olmayan veri kümesi paylaşın
Geçişi gerçekleştirme
Geçişiniz için bir konum (In-Cloud veya Karma) seçtikten sonra, kapalı kalma süresi ve maliyet unsurlarını değerlendirerek, yeni bir sistemi çalıştırıp önceki sistemdeki verileri gerçek zamanlı olarak yeni sisteme taşımak (yan yana geçiş), yedekleme ve geri yükleme yapmak veya mevcut veri kaynaklarından sistemi sıfırdan başlatmak (yerinde geçiş) arasında karar vermelisiniz.
Bir sonraki kararınız, yeni mimari seçimini kullanarak sisteminizdeki geçerli işlevselliği yeniden yazmak veya kodun mümkün olduğunca çoğunu yeni sisteme taşımaktır. Önceki seçim daha uzun sürebilir ancak yeni mimarinin sağladığı yeni yöntemleri, kavramları ve avantajları kullanmanıza olanak tanır. Bu durumda, veri erişimi ve işlev haritaları odaklanmanız gereken birincil planlama çalışmalarıdır.
Geçerli sistemi mümkün olduğunca az kod değişikliğiyle geçirmeyi planlıyorsanız, planlama için birincil odak noktanız dil uyumluluğudur.
Kod geçişi
Sonraki adımınız, geçerli sistemin kullandığı kodu ve yeni ortamda çalıştırılması gereken değişiklikleri denetlemektir.
Kod geçişi için dikkate alınması gereken iki birincil vektör vardır:
- Kaynaklar ve havuzlar
- İşlevsellik geçişi
Kaynaklar ve havuzlar
Kod geçişinin ilk görevi, kodun içeri aktarılan verilere, yoluna ve nihai hedefine erişmek için kullandığı veri kaynağı bağlantı yöntemlerini, dizelerini veya API'lerini tanımlamaktır. Bu kaynakları belgeleyin ve yeni mimarinin konumlarına bir harita oluşturun.
- Geçerli çözüm verileri sistem üzerinden taşımak için bir işlem hattı sistemi kullanıyorsa, yeni mimari kaynaklarını, adımlarını ve havuzlarını işlem hattının bileşenleriyle eşleyin.
- Yeni çözüm aynı zamanda işlem hattı mimarisinin yerini alıyorsa, donanım veya bulut platformunu yeniden kullanıyor olsanız bile planlama amacıyla sistemi yeni bir yükleme olarak değerlendirin.
İşlevsellik geçişi
Geçişte gereken en karmaşık iş, geçerli sistemin işlevselliğine başvurmak, güncelleştirmek veya belgeleri oluşturmaktır. Yerinde yükseltme planlıyorsanız ve kod yeniden yazma miktarını mümkün olduğunca azaltmaya çalışırsanız, bu adım en çok zaman alır.
Ancak, önceki bir teknolojiden geçiş genellikle teknolojideki en son gelişmeler hakkında kendinizi güncelleştirmek ve sağladığı yapılardan yararlanmak için en uygun zamandır. Genellikle geçerli sisteminizi yeniden yazarak daha fazla güvenlik, performans, özellik seçeneği ve hatta maliyet iyileştirmeleri kazanabilirsiniz.
Her iki durumda da geçişte iki temel faktör vardır: yeni sistemin desteklediği kod ve diller ve veri taşımayla ilgili seçenekler. Genellikle, bağlantı dizelerini geçerli büyük veri kümesinden SQL Server örneğine ve Spark ortamına değiştirebilmeniz gerekir. Herhangi bir veri bağlantısı bilgi ve kod geçişi minimal olmalıdır.
Mevcut işlevinizin yeniden yazılmasını düşünüyorsanız, yeni kitaplıkları, paketleri ve DLL'leri seçtiğiniz yeni mimariye uyarlayın. Her çözümün sunduğu kitaplıkların, dillerin ve işlevlerin listesini önceki bölümlerde gösterilen belge başvurularında bulabilirsiniz. Şüpheli veya desteklenmeyen dillerin haritasını çıkarın ve seçilen mimariyle değiştirme planı yapın.
Veri geçişi seçenekleri
Büyük ölçekli bir analiz sisteminde veri taşımaya yönelik iki yaygın yaklaşım vardır. Birincisi, özgün sistemin verileri işlemeye devam ettiği ve verilerin daha küçük bir toplu rapor veri kaynağı kümesine toplandığı bir "tam geçiş" işlemi oluşturmaktır. Yeni sistem daha sonra yeni verilerle başlar ve geçiş tarihinden itibaren kullanılır.
Bazı durumlarda tüm verilerin eski sistemden yeni sisteme taşınması gerekir. Bu durumda, yeni sistem destekliyorsa SQL Server Büyük Veri Kümelerinden özgün dosya depolarını bağlayabilir ve ardından verileri parçalı olarak yeni sisteme kopyalayabilir veya fiziksel bir taşıma oluşturabilirsiniz.
Geçerli verilerinizi SQL Server 2019 Büyük Veri Kümelerinden başka bir sisteme geçirmek, geçerli verilerinizin konumu ve hedefin şirket içinde veya bulutta olması olmak üzere iki faktöre bağımlıdır.
Şirket içi veri geçişi
Şirket içi ortamdan şirket içi geçişler için SQL Server verilerini yedekleme ve geri yükleme stratejisiyle taşıyabilir veya ilişkisel verilerinizin bir kısmını veya tamamını aktarmak için replikasyon ayarlayabilirsiniz. SQL Server Integration Services, SQL Server'dan başka bir konuma veri kopyalamak için de kullanılabilir. SSIS ile veri taşıma hakkında daha fazla bilgi için bkz. SQL Server Integration Services.
Geçerli SQL Server Büyük Veri Kümesi ortamınızdaki HDFS verileri için standart yaklaşım, verileri bağımsız bir Spark Kümesine bağlamak ve SQL Server 2022 (16.x) örneğinin erişebilmesi için Nesne Depolama işlemini kullanarak verileri taşımak veya veriyi olduğu gibi bırakıp Spark İşleri ile işlemeye devam etmektir.
Bulut içi veri geçişi
Bulut depolama alanında veya şirket içinde bulunan veriler için zamanlama, izleme, uyarı ve diğer hizmetlerle birlikte tam aktarım işlem hattı için 90'ın üzerinde bağlayıcısı olan Azure Data Factory'yi kullanabilirsiniz. Azure Data Factory hakkında daha fazla bilgi için bkz. Azure Data Factory nedir?
Büyük miktarda veriyi yerel veri varlığınızdan Microsoft Azure'a güvenli ve hızlı bir şekilde taşımak istiyorsanız Azure İçeri/Dışarı Aktarma Hizmeti'ni kullanabilirsiniz. Azure İçeri/Dışarı Aktarma hizmeti, disk sürücülerini bir Azure veri merkezine göndererek büyük miktarda veriyi Azure Blob depolamaya ve Azure Dosyalar'a güvenli bir şekilde içeri aktarmak için kullanılır. Bu hizmeti ayrıca Azure Blob depolama alanınızdaki verileri disk sürücülerine aktarıp şirket içi ortamınıza göndermek için de kullanabilirsiniz. Bir veya daha fazla disk sürücüsündeki veriler Azure Blob depolama alanına veya Azure Dosyalar aktarılabilir. Son derece büyük miktarda veri için bu hizmetin kullanılması en hızlı yol olabilir.
Microsoft tarafından sağlanan disk sürücülerini kullanarak veri aktarmak istiyorsanız Azure Data Box Disk'i kullanarak verileri Azure'a aktarabilirsiniz. Daha fazla bilgi için bkz. Azure İçeri/Dışarı Aktarma hizmeti nedir?
Bu seçenekler ve bunlara eşlik eden kararlar hakkında daha fazla bilgi için bkz. Büyük veri gereksinimleri için Azure Data Lake Storage 1. Nesil'i kullanma.