Lưu ý
Cần có ủy quyền mới truy nhập được vào trang này. Bạn có thể thử đăng nhập hoặc thay đổi thư mục.
Cần có ủy quyền mới truy nhập được vào trang này. Bạn có thể thử thay đổi thư mục.
Sử dụng Azure Synapse Liên kết để Dataverse xuất dữ liệu của bạn ở định dạng Delta Lake. Microsoft Dataverse Delta Lake là định dạng gốc cho Microsoft Fabric cũng như nhiều công cụ khác như Azure Databricks. Việc xuất dữ liệu theo định dạng Delta Lake trực tiếp từ Dataverse giúp bạn không cần phải có các quy trình chuyển đổi Delta Lake riêng biệt và rút ngắn thời gian tìm hiểu sâu hơn. Bài viết này cung cấp thông tin về tính năng này và hướng dẫn bạn cách thực hiện các tác vụ sau:
- Giải thích về Delta Lake và Parquet và lý do tại sao bạn nên xuất dữ liệu theo định dạng này.
- Xuất dữ liệu của bạn sang không gian làm việc ở định dạng Delta Lake bằng Dataverse Liên kết. Azure Synapse Analytics Azure Synapse
- Theo dõi liên kết và chuyển đổi dữ liệu của bạn. Azure Synapse
- Xem dữ liệu của bạn từ Azure Data Lake Storage Gen2.
- Xem dữ liệu của bạn từ Synapse Workspace.
- Xem dữ liệu của bạn trong Microsoft Fabric.
Hồ Delta là gì?
Delta Lake là một dự án nguồn mở cho phép xây dựng kiến trúc lakehouse trên các hồ dữ liệu. Delta Lake cung cấp các giao dịch ACID (tính nguyên tử, tính nhất quán, tính cô lập và tính bền vững), xử lý siêu dữ liệu có thể mở rộng và hợp nhất xử lý dữ liệu theo luồng và theo lô trên các hồ dữ liệu hiện có. Azure Synapse Analytics tương thích với Linux Foundation Delta Lake. Phiên bản hiện tại của Delta Lake đi kèm với Azure Synapse có hỗ trợ ngôn ngữ cho Scala, PySpark và .NET. Thông tin thêm: Hồ Delta là gì? Bạn cũng có thể tìm hiểu thêm từ video Giới thiệu về Bảng Delta.
Apache Parquet là định dạng cơ bản cho Delta Lake, cho phép bạn tận dụng các chương trình nén và mã hóa hiệu quả vốn có của định dạng này. Định dạng tệp Parquet sử dụng nén theo cột. Hiệu quả và tiết kiệm không gian lưu trữ. Các truy vấn lấy giá trị cột cụ thể không cần phải đọc toàn bộ dữ liệu hàng, do đó cải thiện hiệu suất. Do đó, nhóm SQL không máy chủ cần ít thời gian và ít yêu cầu lưu trữ hơn để đọc dữ liệu.
Tại sao nên sử dụng Delta Lake?
- Khả năng mở rộng: Delta Lake được xây dựng dựa trên giấy phép Apache nguồn mở, được thiết kế để đáp ứng các tiêu chuẩn của ngành về xử lý khối lượng công việc xử lý dữ liệu quy mô lớn.
- Độ tin cậy: Delta Lake cung cấp các giao dịch ACID, đảm bảo tính nhất quán và độ tin cậy của dữ liệu ngay cả khi xảy ra lỗi hoặc truy cập đồng thời.
- Hiệu suất: Delta Lake tận dụng định dạng lưu trữ dạng cột của Parquet, cung cấp các kỹ thuật nén và mã hóa tốt hơn, có thể cải thiện hiệu suất truy vấn so với truy vấn tệp CSV.
- Tiết kiệm chi phí: Định dạng tệp Delta Lake là công nghệ lưu trữ dữ liệu được nén ở mức cao, mang lại khả năng tiết kiệm lưu trữ đáng kể cho doanh nghiệp. Định dạng này được thiết kế riêng để tối ưu hóa việc xử lý dữ liệu và có khả năng giảm tổng lượng dữ liệu được xử lý hoặc thời gian chạy cần thiết cho việc tính toán theo yêu cầu.
- Tuân thủ bảo vệ dữ liệu: Delta Lake với Azure Synapse Link cung cấp các công cụ và tính năng bao gồm xóa mềm và xóa cứng để tuân thủ nhiều quy định về quyền riêng tư dữ liệu, bao gồm Quy định bảo vệ dữ liệu chung (GDPR).
Delta Lake hoạt động như thế nào với Azure Synapse Liên kết cho Dataverse?
Khi thiết lập Azure Synapse Liên kết cho Dataverse, bạn có thể bật tính năng xuất sang Delta Lake và kết nối với không gian làm việc Synapse và nhóm Spark. Azure Synapse Liên kết xuất các bảng đã chọn ở định dạng CSV theo các khoảng thời gian được chỉ định, xử lý chúng thông qua tác vụ chuyển đổi Delta Lake Spark. Dataverse Sau khi hoàn tất quá trình chuyển đổi này, dữ liệu CSV sẽ được dọn sạch để lưu trữ. Ngoài ra, một loạt các công việc bảo trì được lên lịch chạy hàng ngày, tự động thực hiện các quy trình nén và hút bụi để hợp nhất và dọn dẹp các tệp dữ liệu nhằm tối ưu hóa lưu trữ và cải thiện hiệu suất truy vấn.
Quan trọng
- Nếu bạn đang nâng cấp từ CSV lên Delta Lake với chế độ xem tùy chỉnh hiện có, chúng tôi khuyên bạn nên cập nhật tập lệnh để thay thế tất cả các bảng được phân vùng thành không được phân vùng. Thực hiện việc này bằng cách tìm kiếm các trường hợp của
_partitionedvà thay thế chúng bằng một chuỗi trống. - Đối với cấu hình Dataverse , chế độ chỉ thêm vào được bật theo mặc định để xuất dữ liệu CSV ở chế độ
appendonly. Bảng Delta Lake sẽ có cấu trúc cập nhật tại chỗ vì quá trình chuyển đổi Delta Lake đi kèm với quy trình hợp nhất định kỳ. - Bạn cần cung cấp một nhóm Spark (tài nguyên tính toán) trong đăng ký Azure của riêng bạn để chuyển đổi Delta. Nhóm Spark này được sử dụng để thực hiện chuyển đổi Delta định kỳ dựa trên khoảng thời gian do bạn chọn.
- Không có chi phí nào phát sinh khi tạo nhóm Spark. Phí chỉ phát sinh khi tác vụ Spark được thực thi trên nhóm Spark mục tiêu và phiên bản Spark được khởi tạo theo yêu cầu. Các chi phí này liên quan đến việc sử dụng Azure Synapse workspace Spark và được thanh toán hàng tháng. Chi phí thực hiện tính toán Spark chủ yếu phụ thuộc vào khoảng thời gian cập nhật gia tăng và khối lượng dữ liệu. Thông tin thêm: Azure Synapse Analytics giá cả
- Bạn cần tạo một nhóm Spark với phiên bản 3.4. Nếu bạn đang sử dụng tính năng này với Spark phiên bản 3.3, bạn cần thực hiện nâng cấp tại chỗ cho các cấu hình hiện có của mình. Thông tin thêm: Nâng cấp tại chỗ lên Apache Spark 3.4 với Delta Lake 2.4
Lưu ý
Trạng thái liên kết trong Azure Synapse (make.powerapps.com) phản ánh trạng thái chuyển đổi Delta Lake: Power Apps
-
Counthiển thị số lượng bản ghi trong bảng Delta Lake. -
Last synchronized onDatetime biểu thị dấu thời gian chuyển đổi thành công cuối cùng. -
Sync statusđược hiển thị là hoạt động sau khi quá trình đồng bộ hóa dữ liệu và chuyển đổi Delta Lake hoàn tất, cho biết dữ liệu đã sẵn sàng để sử dụng.
Điều kiện tiên quyết
- Dataverse: Bạn phải có vai trò bảo mật là Dataverse quản trị viên hệ thống . Ngoài ra, các bảng bạn muốn xuất qua Azure Synapse Liên kết phải bật thuộc tính Theo dõi thay đổi . Thông tin thêm: Tùy chọn nâng cao
- Azure Data Lake Storage Gen2: Bạn phải có quyền truy cập vào Azure Data Lake Storage tài khoản Gen2 và Chủ sở hữu và Người đóng góp dữ liệu Blob lưu trữ . Tài khoản lưu trữ của bạn phải bật Không gian tên phân cấp và quyền truy cập mạng công cộng cho cả thiết lập ban đầu và đồng bộ hóa delta. Cho phép truy cập khóa tài khoản lưu trữ chỉ được yêu cầu cho thiết lập ban đầu.
- Không gian làm việc Synapse: Bạn phải có không gian làm việc Synapse và vai trò Chủ sở hữu trong kiểm soát truy cập (IAM) và vai trò Quản trị viên Synapse truy cập trong Synapse Studio. Không gian làm việc Synapse phải ở cùng khu vực với tài khoản Azure Data Lake Storage Gen2 của bạn. Tài khoản lưu trữ phải được thêm vào dưới dạng dịch vụ được liên kết trong Synapse Studio. Để tạo không gian làm việc Synapse, hãy truy cập Tạo không gian làm việc Synapse.
- Một Apache Spark nhóm trong không gian làm việc được kết nối với Azure Synapse Phiên bản 3.4 Apache Spark sử dụng cấu hình Spark Pool được khuyến nghị này . Để biết thông tin về cách tạo Spark Pool, hãy truy cập Tạo Apache Spark poolmới.
- Yêu cầu phiên bản tối thiểu Microsoft Dynamics 365 để sử dụng tính năng này là 9.2.22082. Thông tin thêm: Chọn tham gia cập nhật quyền truy cập sớm
Cấu hình Spark Pool được đề xuất
Cấu hình này có thể được coi là bước khởi động cho các trường hợp sử dụng trung bình.
- Kích thước nút: nhỏ (4 vCore / 32 GB)
- Tự động thay đổi tỷ lệ: Đã bật
- Số lượng nút: 3 đến 10 (hoặc 20 nếu cần. 1Thông tin thêm bên dưới.)
- Tự động tạm dừng: Đã bật
- Số phút không hoạt động: 5
- Apache Spark: 3.4
- Phân bổ động các trình thực thi: Đã bật
- Số lượng người thực hiện mặc định: 1 đến 9
Quan trọng
- Sử dụng Spark pool dành riêng cho hoạt động trò chuyện Delta Lake với Synapse Link Dataverse. Để có độ tin cậy và hiệu suất tối ưu, hãy tránh chạy các tác vụ Spark khác bằng cùng một nhóm Spark.
- Bạn có thể cần tăng số lượng nút của nhóm Spark nếu bạn muốn xử lý số lượng lớn hàng. Nếu kích thước của nhóm Spark không đủ, các tác vụ chuyển đổi Delta có thể không thành công
- Hệ thống sử dụng cùng một nhóm Spark để chạy tác vụ hàng đêm nhằm nén các tệp Delta trong hồ từ 11 giờ đêm đến 6 giờ sáng theo giờ địa phương. Hệ thống xác định thời gian ban đêm để thực hiện công việc này dựa trên vị trí môi trường của bạn. Dataverse Bạn không thể cung cấp khung thời gian cụ thể. Tùy chọn này làm giảm kích thước của các tệp Delta bằng cách hợp nhất các tệp được gọi là "nén". Trong một số trường hợp hiếm hoi, tác vụ này có thể ảnh hưởng đến tác vụ chuyển đổi gia tăng. Bạn có thể tăng số lượng nút lên 20 trong trường hợp bạn nhận thấy những lỗi này.
- Bạn chỉ bị tính phí cho các nút spark pool thực sự được sử dụng. Việc tăng số lượng nút có thể không làm tăng chi phí.
Kết nối Dataverse với không gian làm việc Synapse và xuất dữ liệu theo định dạng Delta Lake
đăng nhập vào Power Apps và chọn môi trường bạn muốn.
Trên ngăn điều hướng bên trái, chọn Azure Synapse Liên kết. Nếu mục không có trong ngăn bảng điều khiển bên, hãy chọn …Thêm rồi chọn mục bạn muốn.
Trên thanh lệnh, chọn + Liên kết mới
Chọn Kết nối với Azure Synapse Analytics không gian làm việc của bạn, sau đó chọn Đăng ký, Nhóm tài nguyên và Tên không gian làm việc.
Chọn Sử dụng Spark pool để xử lý, sau đó chọn Spark pool và tài khoản lưu trữ được tạo trước.
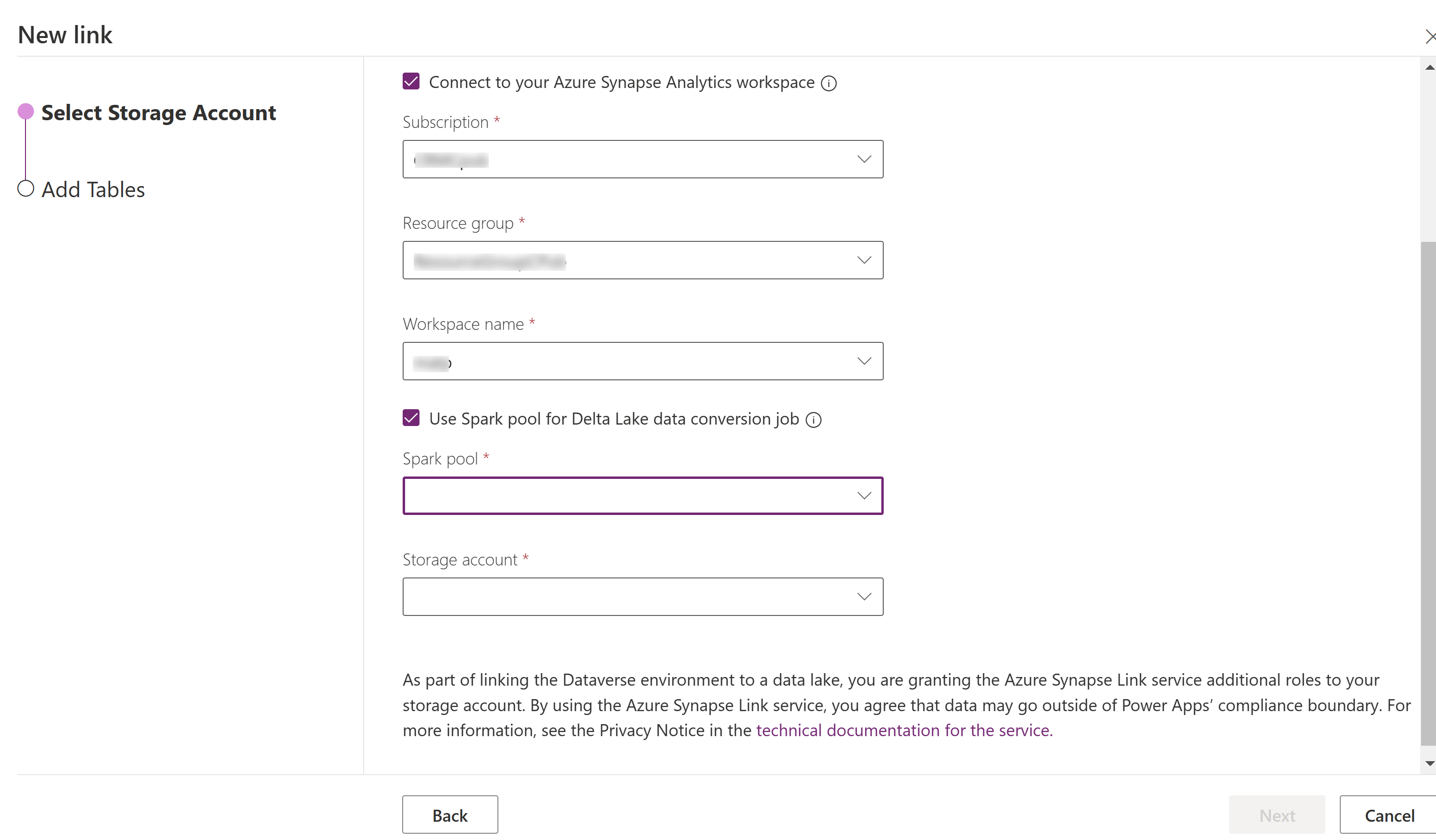
Chọn Tiếp theo.
Thêm các bảng bạn muốn xuất, sau đó chọn Nâng cao.
Tùy chọn, chọn Hiển thị cài đặt cấu hình nâng cao và nhập khoảng thời gian, tính bằng phút, cho tần suất cập nhật gia tăng cần được ghi lại.
Chọn Lưu.
Theo dõi Azure Synapse Liên kết và chuyển đổi dữ liệu của bạn
- Chọn Azure Synapse Liên kết bạn muốn, sau đó chọn Đi tới Azure Synapse Analytics không gian làm việc trên thanh lệnh.
- Chọn Giám sát>Apache Spark ứng dụng. Thông tin thêm: Sử dụng Synapse Studio để giám sát Apache Spark ứng dụng của bạn
Xem dữ liệu của bạn từ không gian làm việc Synapse
- Chọn Azure Synapse Liên kết bạn muốn, sau đó chọn Đi tới Azure Synapse Analytics không gian làm việc trên thanh lệnh.
- Mở rộng Cơ sở dữ liệu hồ trên ngăn bên trái, chọn dataverse-environmentNameorganizationUniqueName, rồi mở rộng Bảng. Tất cả các bảng Parquet đều được liệt kê và có thể phân tích theo quy ước đặt tên DataverseTableName.(Non_partitioned Table).
Lưu ý
Không sử dụng bảng có quy ước đặt tên _partitioned. Khi bạn chọn Delta parquet làm định dạng, các bảng có quy ước đặt tên _partition sẽ được sử dụng làm bảng trung gian và sẽ bị xóa sau khi hệ thống sử dụng.
Xem dữ liệu của bạn từ Azure Data Lake Storage Gen2
- Chọn Azure Synapse Liên kết bạn muốn, sau đó chọn Đi tới Azure data lake trên thanh lệnh.
- Chọn Vùng chứa trong Bộ lưu trữ dữ liệu.
- Chọn *dataverse- *environmentName-organizationUniqueName. Tất cả các tập tin parquet được lưu trữ trong thư mục deltalake .
Nâng cấp tại chỗ lên Apache Spark 3.4 với Delta Lake 2.4
Theo chính sách vòng đời của thời gian chạy Synapse, thời gian chạy cho Apache Spark 3.3 sẽ ngừng hoạt động và bị vô hiệu hóa kể từ ngày 31 tháng 3 năm 2025. Azure Synapse Apache Spark Sau ngày kết thúc hỗ trợ, thời gian chạy đã ngừng hoạt động sẽ không khả dụng cho nhóm Spark mới và quy trình làm việc hiện tại với nhóm Spark 3.3 sẽ không được thực thi trong khi siêu dữ liệu sẽ tạm thời vẫn nằm trong không gian làm việc Synapse. Thông tin thêm: Azure Synapse Thời gian chạy cho Apache Spark 3.3 (EOSA).
Để đảm bảo rằng các cấu hình Synapse Link hiện tại của bạn tiếp tục xử lý dữ liệu, bạn cần nâng cấp các cấu hình Synapse Link để sử dụng nhóm Spark 3.4 bằng "quy trình nâng cấp tại chỗ".
Điều kiện tiên quyết để nâng cấp tại chỗ
- Bạn phải có Azure Synapse Liên kết hiện tại cho Dataverse hồ Delta đang chạy với Synapse Spark phiên bản 3.3.
- Bạn phải tạo một nhóm Synapse Spark mới với Spark phiên bản 3.4, bằng cách sử dụng cấu hình phần cứng của cùng một nút hoặc cao hơn trong cùng một không gian làm việc Synapse. Để biết thông tin về cách tạo nhóm Spark, hãy truy cập Tạo nhóm Apache Spark mới. Nhóm Spark này phải được tạo độc lập với nhóm 3.3 hiện tại - không xóa nhóm Spark 3.3 của bạn hoặc tạo nhóm Spark 34 có cùng tên
Nâng cấp tại chỗ lên Spark 3.4
- đăng nhập vào Power Apps và chọn môi trường bạn thích.
- Trên ngăn điều hướng bên trái, chọn Azure Synapse Liên kết. Nếu mục không có trong ngăn điều hướng bên trái, hãy chọn …Thêm rồi chọn mục bạn muốn.
- Mở Azure Synapse Hồ sơ liên kết, sau đó chọn Nâng cấp lên Apache Spark 3.4 với Delta Lake 2.4.
- Chọn nhóm Spark có sẵn từ danh sách, sau đó chọn Cập nhật.
Lưu ý
- Việc nâng cấp nhóm Spark chỉ diễn ra khi tác vụ Spark chuyển đổi hồ Delta mới được kích hoạt. Đảm bảo rằng bạn có ít nhất một thay đổi dữ liệu sau khi chọn Cập nhật.
- Bạn có thể xóa nhóm Spark 3.3 cũ hơn sau khi xác minh rằng các tác vụ chuyển đổi Delta sử dụng nhóm mới.