使用 Databricks Apps 模板生成和部署第一个 AI 代理。 在本教程中,你将:
- 从 Databricks 应用 UI 生成和部署代理。
- 使用预生成的聊天界面与代理聊天。
先决条件
在工作区中启用 Databricks 应用。 请参阅 设置 Databricks Apps 工作区和开发环境。
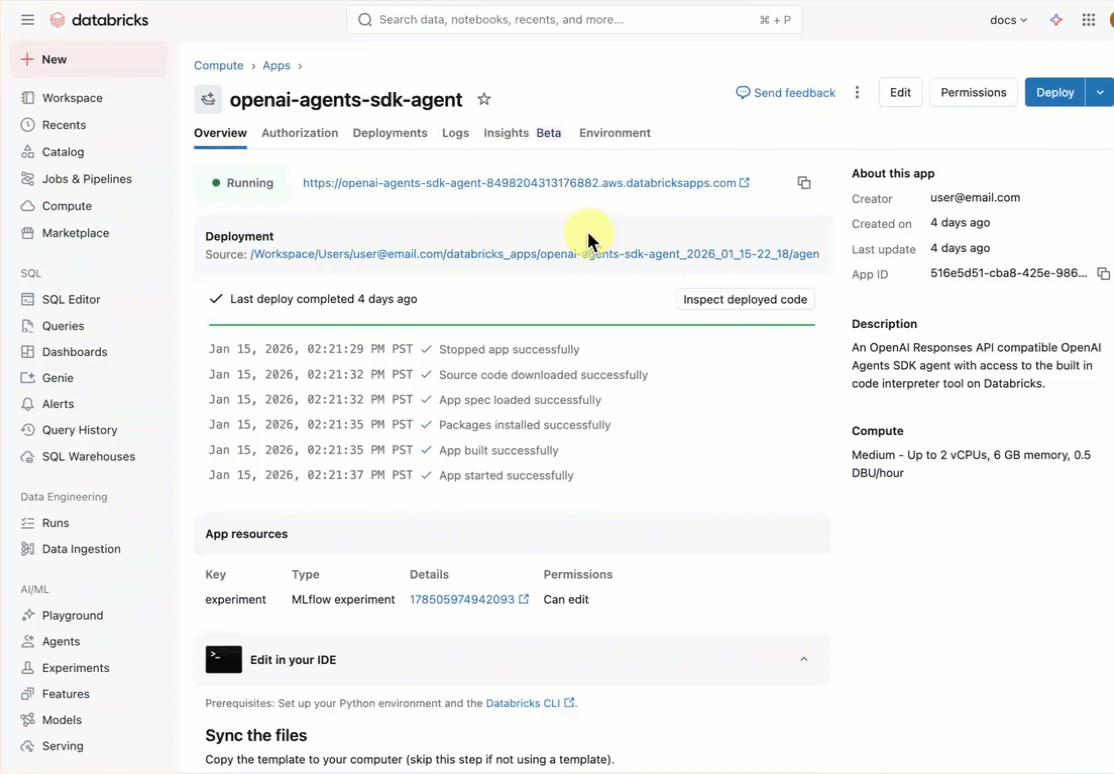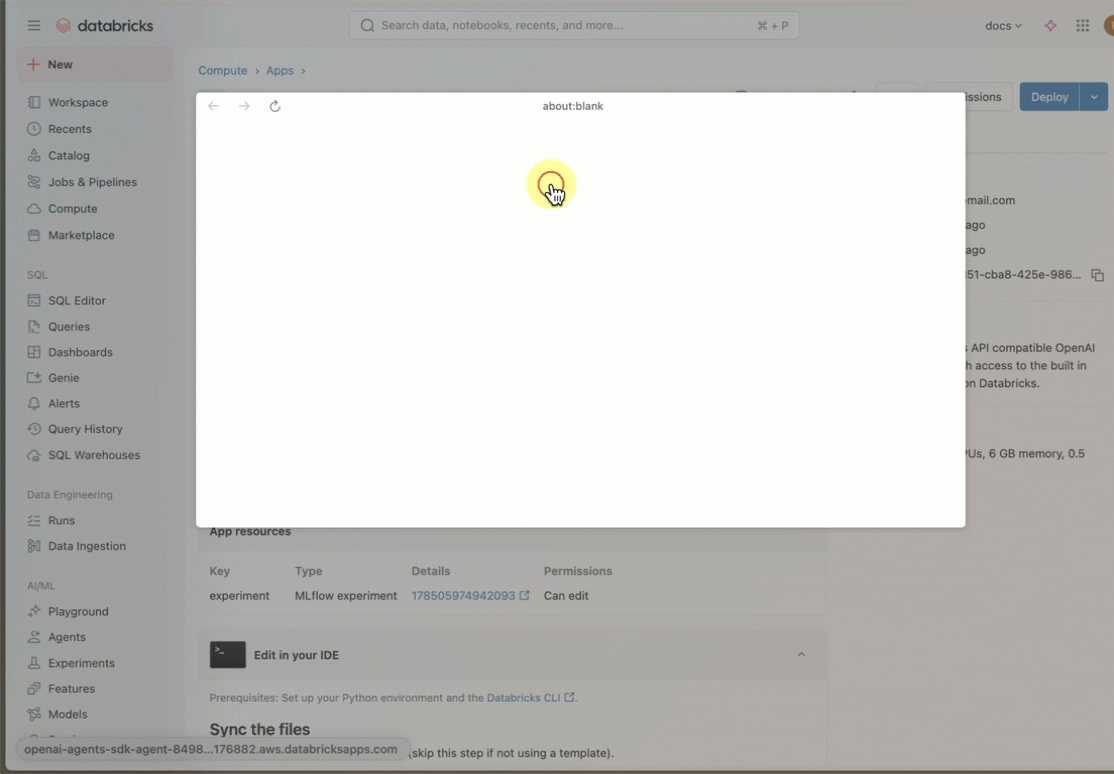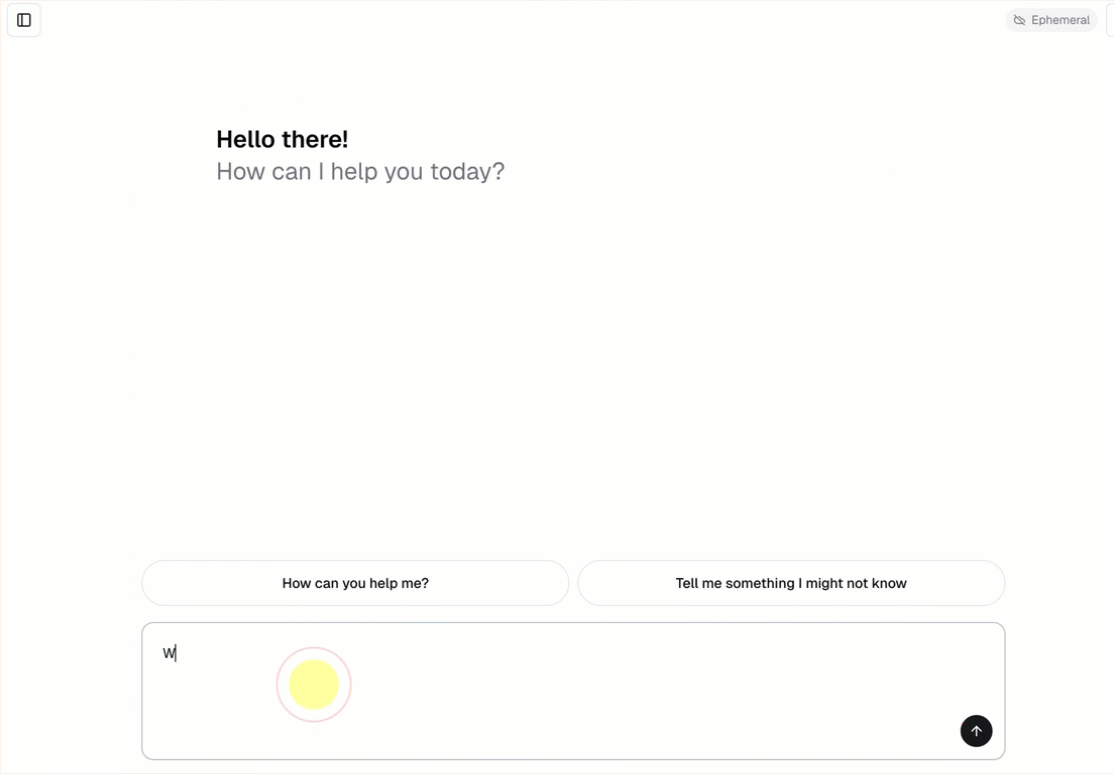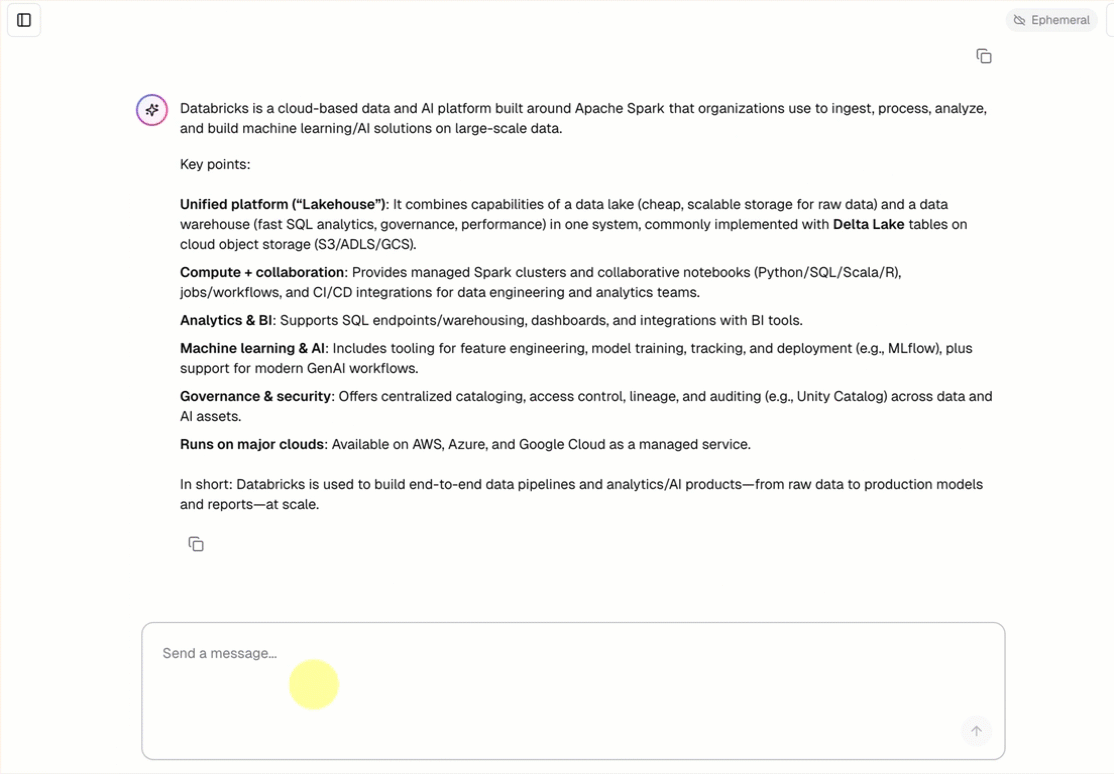
部署代理模板
开始使用 Databricks 应用模板存储库中的预生成代理模板。
本教程使用 agent-openai-agents-sdk 模板,其中包括:
- 使用 OpenAI 代理 SDK 创建的代理
- 适用于代理应用的基础代码,包含会话 REST API 和交互式聊天 UI。
- 使用 MLflow 评估代理的代码
使用工作区 UI 安装应用模板。 这会安装应用并将其部署到工作区中的计算资源。
在 Databricks 工作区中,单击“ + 新建>应用”。
单击 代理>代理 - OpenAI 代理 SDK。
使用名称
openai-agents-template创建新的 MLflow 试验,并完成设置的其余部分以安装模板。创建应用后,单击应用 URL 以打开聊天 UI。
了解代理应用程序
代理模板演示了具有以下关键组件的生产就绪体系结构:
MLflow AgentServer:处理具有内置跟踪和可观测性的代理请求的异步 FastAPI 服务器。 AgentServer 提供 /invocations 用于查询代理的终结点,并自动管理请求路由、日志记录和错误处理。
OpenAI 代理 SDK:模板使用 OpenAI 代理 SDK 作为聊天管理和工具业务流程的代理框架。 可以使用任何框架开发代理。 关键是使用 MLflow ResponsesAgent 接口对你的代理进行包装。
ResponsesAgent 接口:此接口可确保代理跨不同的框架工作,并与 Databricks 工具集成。 使用 OpenAI SDK、LangGraph、LangChain 或纯 Python 生成代理,然后将其包装在 ResponsesAgent 一起,以便与 AI Playground、代理评估和 Databricks Apps 部署自动兼容。
MCP(模型上下文协议)服务器:模板连接到 Databricks MCP 服务器,以访问工具和数据源的代理。 请参阅 Databricks 上的模型上下文协议(MCP)。

后续步骤
了解如何创作自定义代理:创作 AI 代理并将其部署到 Databricks 应用