新式数据和 AI 平台框架
为了讨论 Databricks Data Intelligence Platform 的范围,首先要定义新式数据和 AI 平台的基本框架:
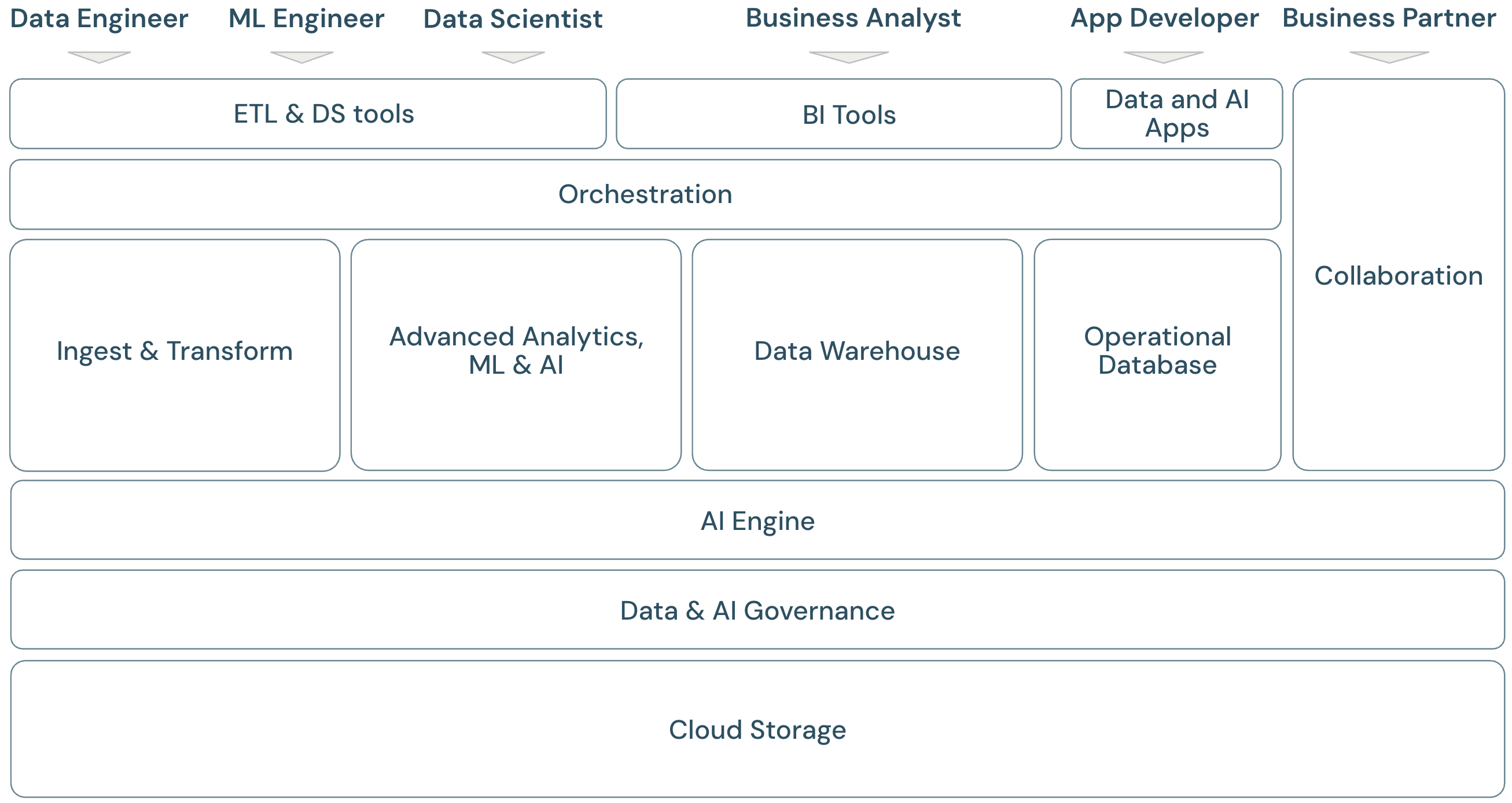
湖屋范围概述
Databricks Data Intelligence Platform 涵盖完整的新式数据平台框架。 它建立在湖屋体系结构之上,由数据智能引擎提供支持,该引擎可理解数据的独特之处。 它是 ETL、ML/AI 和 DWH/BI 工作负载的开放统一基础,并具有 Unity Catalog 作为中央数据和 AI 治理解决方案。
平台框架的角色
该框架涵盖在框架中处理应用程序的主要数据团队成员(角色):
- 数据工程师为数据科学家和业务分析师提供准确且可重现的数据,以便及时做出决策和提供实时见解。 他们实现高度统一且可靠的 ETL 过程,以增加用户对数据的信心和信任。 他们确保数据与业务的各个支柱很好地集成,并且通常遵循软件工程最佳做法。
- 数据科学家结合分析专长和业务理解,将数据转化为战略见解和预测模型。 他们善于将业务挑战转化为数据驱动的解决方案,即通过追溯分析见解或前瞻性预测建模。 利用数据建模和机器学习技术,他们设计、开发和部署模型,从数据中揭示模式、趋势和预测。 他们充当沟通的桥梁,将复杂的数据叙述转换为可理解的故事,确保业务利益干系人不仅理解,还可以处理数据驱动的建议采取行动,进而推动以数据为中心的方法来解决组织内部的问题。
- ML 工程师(机器学习工程师)通过构建、部署和维护机器学习模型,领导数据科学在产品和解决方案中的实际应用。 他们主要关注模型开发和部署的工程方面。 ML 工程师确保机器学习系统在实时环境中的稳健性、可靠性和可伸缩性,应对与数据质量、基础结构和性能相关的挑战。 通过将 AI 和 ML 模型集成到运营业务流程和面向用户的产品中,它们促进了利用数据科学来解决业务挑战,确保模型不仅仅是处于研究阶段,还能推动有形的业务价值。
- 业务分析师 和企业 用户:业务分析师为利益干系人和业务团队提供可作的数据。 它们通常解释数据,并使用标准 BI 工具创建报表或其他文档进行管理。 它们通常是非技术业务用户和运营同事的第一个联系点,用于快速分析问题。 业务用户可以直接使用 Databricks 平台上提供的仪表板和业务应用。
- 应用开发人员 在数据平台上创建安全数据和 AI 应用程序,并与业务用户共享这些应用。
- 业务合作伙伴 是日益网络的商业世界中的重要利益干系人。 他们的定义是与企业建立了正式关系以实现共同目标的公司或个人,可以包括销售商、供应商、分销商和其他第三方合作伙伴。 数据共享是业务伙伴关系的一个重要方面,因为它通过数据传输和交换数据来增强协作和数据驱动的决策。
平台框架的域
平台由多个域组成:
- 存储: 在云中,数据主要存储在云提供程序上的可缩放、高效和可复原的对象存储中。
- 统辖: 有关数据管理的功能,例如访问控制、审核、元数据管理、世系跟踪和监视所有数据和 AI 资产。
- AI 引擎: AI 引擎为整个平台提供生成 AI 功能。
- 引入和转换:ETL 工作负载的功能。
- 高级分析、ML 和 AI:所有围绕机器学习、AI、生成式 AI 的功能以及流分析。
- 数据仓库:支持 DWH 和 BI 用例的域。
- 自动化: 数据处理、机器学习、分析管道(包括 CI/CD 和 MLOps 支持)的工作流管理。
- ETL 和数据科学工具: 数据工程师、数据科学家和 ML 工程师主要用于工作的前端工具。
- BI 工具:BI 分析师在工作中主要使用的前端工具。
- 数据和 AI 应用 生成和托管使用基础平台管理的数据的应用程序的工具,并以安全且合规的方式利用其分析和 AI 功能。
- 协作:两个或多个参与方之间共享数据的功能。
Databricks 平台的范围
可通过以下方式将 Databricks Data Intelligence Platform 及其组件映射到框架:
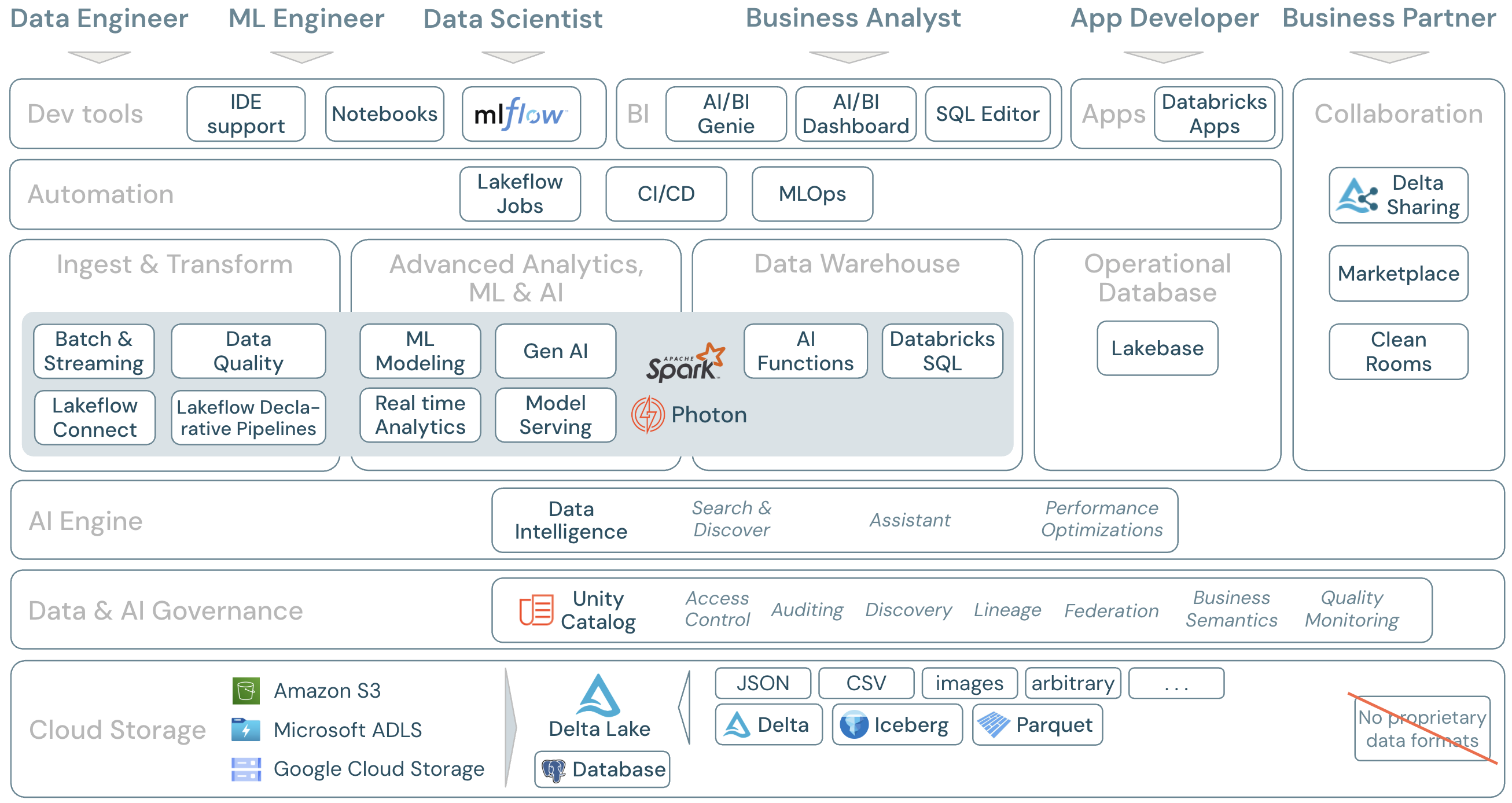
Azure Databricks 上的数据工作负荷
最重要的是,Databricks 数据智能平台涵盖一个平台中数据域的所有相关工作负载,Apache Spark/Photon 作为引擎:
引入和转换
Databricks 提供了多种数据引入方法:
- Databricks Lakeflow Connect 提供内置连接器,用于从企业应用程序和数据库引入。 生成的引入管道由 Unity 目录管理,由无服务器计算和 Lakeflow 声明性管道提供支持。
- 自动加载程序可在计划或连续作业中以增量方式自动处理存储在云存储中的文件,而无需管理状态信息。 引入后,需要立即转换原始数据,以便为 BI 和 ML/AI 做好准备。 Databricks 为数据工程师、数据科学家和分析师提供强大的 ETL 功能。
Lakeflow 声明性管道 允许以声明方式编写 ETL 作业,从而简化整个实现过程。 可以通过定义 数据预期来提高数据质量。
高级分析、ML 和 AI
该平台包括 Databricks 马赛克 AI、一组完全集成的机器学习和 AI 工具,用于传统机器学习和深度学习,以及生成 AI 和大型语言模型(LLM)。 它涵盖整个工作流,从 准备数据 到生成 机器学习 和 深度学习 模型,到 马赛克 AI 模型服务。
Spark 结构化流式处理 和 Lakeflow 声明性管道 支持实时分析。
数据仓库
Databricks Data Intelligence Platform 还有一个完整的数据仓库解决方案,其中 Databricks SQL 由 Unity 目录 集中管理,具有精细的访问控制。
AI 函数 是内置的 SQL 函数,可用于直接从 SQL 对数据应用 AI。 将 AI 集成到分析作业可提供以前无法访问的信息的访问权限,并使他们能够通过数据驱动的创新和效率做出更明智的决策、管理风险并保持竞争优势。
Azure Databricks 功能区域的概述
这是 Databricks Data Intelligence Platform 功能从下到上映射到框架的其他层:
云存储
湖屋的所有数据都存储在云提供商的对象存储中。 Databricks 支持三个云提供商:AWS、Azure 和 GCP。 采用各种结构化和半结构化格式(例如 Parquet、CSV、JSON 和 Avro)以及非结构化格式(如图像和文档)的文件使用批处理或流式处理进行引入和转换。
Delta Lake 是 Lakehouse 的建议数据格式(文件事务、可靠性、一致性、更新等)。 还可以 使用 Apache Iceberg 客户端读取 Delta 表。
Databricks 数据智能平台中不使用专有数据格式: Delta Lake 和 Iceberg 是开源的,以避免供应商锁定。
数据和 AI 治理
在存储层之上, Unity 目录 提供广泛的数据和 AI 治理功能,包括元存储中的 元数据管理 、 访问控制、 审核、 数据发现和数据 世系。
Lakehouse 监控 为数据和 AI 资产提供开箱即用的质量指标,以及自动生成的仪表板用于可视化这些指标。
外部 SQL 源可以通过 Lakehouse 联邦 集成到 lakehouse 和 Unity Catalog 中。
AI 引擎
数据智能平台基于湖仓体系结构构建,并通过Databricks AI 支持的功能进行增强。 Databricks AI 将生成 AI 与 Lakehouse 体系结构的统一优势相结合,以了解数据的独特语义。 智能搜索和 Databricks 助手 是 AI 提供支持的服务示例,可简化每个用户的平台使用。
业务流程
Lakeflow 作业 使你能够在任何云上运行各种工作负载,以实现完整的数据和 AI 生命周期。 它们允许你协调作业以及适用于 SQL、Spark、笔记本、DBT、ML 模型等的 Lakeflow 声明性管道。
ETL 和 DS 工具
在消费层,数据工程师和 ML 工程师通常使用 IDE 来处理平台。 数据科学家通常更喜欢 笔记本 并使用 ML 和 AI 运行时,以及机器学习工作流系统 MLflow 来跟踪试验和管理模型生命周期。
BI 工具
业务分析师通常使用他们的首选 BI 工具来访问 Databricks 数据仓库。 Databricks SQL 可以通过不同的分析和 BI 工具进行查询,请参阅 BI 和可视化
此外,该平台提供现成的查询和分析工具:
- AI/BI 仪表板 ,用于拖放数据可视化效果并共享见解。
- 域专家(如数据分析师)使用数据集、示例查询和文本指南配置 AI/BI Genie 空间 ,以帮助 Genie 将业务问题转换为分析查询。 设置后,业务用户可以提出问题并生成可视化效果以了解操作数据。
- 专为 SQL 分析师设计的 SQL 编辑器用于分析数据。
数据和 AI 应用
Databricks 应用允许开发人员在 Databricks 平台上创建安全数据和 AI 应用程序,并与用户共享这些应用。
协作
Delta Sharing 是由 Databricks 开发的 开放协议 ,用于与其他组织安全共享数据,无论使用哪种计算平台。
Databricks 市场 是交换数据产品的开放论坛。 它利用 Delta Sharing 为数据提供者提供可安全共享数据产品的工具,并让数据使用者能够发现和扩展对所需数据和数据服务的访问权限。
清洁室 使用 Delta Sharing 和无服务器计算提供安全且隐私保护的环境,让多个参与方可以协同处理敏感企业数据,而无需直接访问彼此的数据。