Databricks 支持使用不同的编程语言进行开发和数据工程。 本文概述了可用的选项、这些语言的使用场合及其限制。
建议
Databricks 为新项目推荐 Python 和 SQL:
- Python 是一种非常流行的通用编程语言。 PySpark DataFrames 可以轻松地创建可测试的模块化转换。 Python 生态系统还支持各种库,支持各种库来扩展解决方案。
-
SQL 是一种非常受欢迎的语言,通过执行查询、更新、插入和删除数据等操作来管理和操作关系数据集。 如果您的背景主要在数据库或数据仓库方面,那么选择 SQL 是一个不错的选择。 还可以使用
spark.sql在 Python 中嵌入 SQL。
以下语言的支持有限,因此 Databricks 不建议将其用于新的数据工程项目:
- Scala 是用于开发 Apache Spark™ 的语言。
- R 仅在 Databricks 笔记本中完全受支持。
语言支持也因用于生成数据管道和其他解决方案的功能而异。 例如,Lakeflow Spark 声明性管道支持 Python 和 SQL,而工作流允许使用 Python、SQL、Scala 和 Java 创建数据管道。
注意
其他语言可用于与 Databricks 交互以查询数据或执行数据转换。 但是,这些交互主要位于与外部系统的集成上下文中。 在这些情况下,开发人员几乎可以使用任何编程语言通过 Databricks REST API、ODBC/JDBC 驱动程序、具有 Databricks SQL 连接器 支持(Go、Python、Javascript/Node.js)或具有 Spark Connect 实现的语言(如 Go、Python、Javascript/Node.js)与 Databricks 进行交互。
工作区开发与本地开发
可以在本地计算机上使用 Databricks 工作区或 IDE(集成开发环境)开发数据项目和管道,但建议在 Databricks 工作区中启动新项目。 可以使用 Web 浏览器访问工作区,它提供对 Unity 目录中数据的轻松访问,并支持强大的调试功能和功能,例如 Genie Code。
使用 Databricks 笔记本或 SQL 编辑器在 Databricks 工作区中开发代码。 Databricks 笔记本即使在同一笔记本中也支持多种编程语言,因此可以使用 Python、SQL 和 Scala 进行开发。
在 Databricks 工作区中直接开发代码有几个优点:
- 反馈循环速度更快。 可以立即测试实际数据编写的代码。
- 内置的上下文感知 Genie Code 可以加快开发速度,并帮助解决问题。
- 可以直接从 Databricks 工作区安排笔记本和查询。
- 对于 Python 开发,可以通过在工作区中将文件用作 Python 包来正确构建 Python 代码。
但是,IDE 中的本地开发具有以下优势:
- IDE 有更好的工具可用于处理软件项目,例如导航、代码重构和静态代码分析。
- 可以选择如何管理你的源码,如果使用 Git,那么在本地提供的功能比在工作区使用 Git 文件夹时提供的功能更高级。
- 支持的语言范围更广。 例如,可以使用 Java 开发代码并将其部署为 JAR 任务。
- 对代码调试有更好的支持。
- 有更好的支持来处理单元测试。
语言选择示例
使用以下决策树可视化数据工程的语言选择:
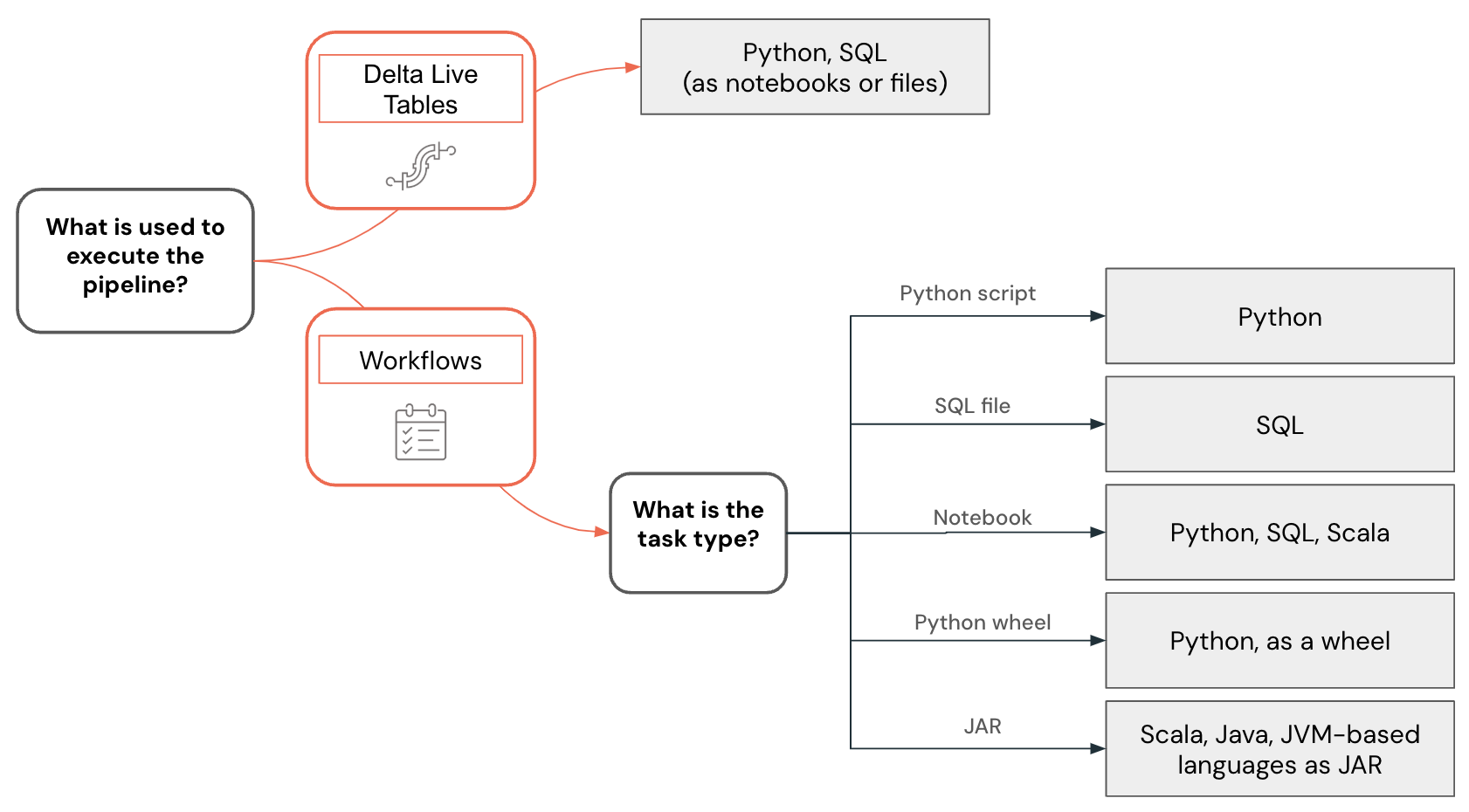
开发 Python 代码
Python 语言对 Databricks 具有一流的支持。 可以在 Databricks 笔记本、Lakeflow Spark 声明性管道和工作流中使用它来开发 UDF,并将其部署为 Python 脚本和轮子。
在 Databricks 工作区中开发 Python 项目时,无论是笔记本还是文件中,Databricks 都提供了诸如代码完成、导航、语法验证、使用 Genie Code 生成代码、交互式调试 等工具。 可以以交互方式执行开发代码,部署为 Databricks 工作流或 Lakeflow Spark 声明性管道,甚至可以作为 Unity Catalog 中的函数。 可以通过将其拆分为 单独的 Python 包来构建代码, 可在多个管道或作业中使用。
Databricks 为 Visual Studio Code 和 JetBrains 提供了 扩展,为 PyCharm 提供了一个 插件,使你可以在 IDE 中开发 Python 代码、将代码同步到 Databricks 工作区、在工作区内执行它,并使用 Databricks Connect执行分步调试。 然后,可以使用 声明性自动化捆绑包 将开发的代码部署为 Databricks 作业或管道。
开发 SQL 代码
SQL 语言可以在 Databricks 笔记本中使用,也可以使用 SQL 编辑器作为 Databricks 查询。 在这两种情况下,开发人员都可以访问如代码补全等工具,以及可用于代码生成和修复问题的上下文感知的 Genie Code。 开发的代码可以部署为任务或管道。
Databricks 工作流还允许执行存储在文件中的 SQL 代码。 可以使用 IDE 创建这些文件并将其上传到工作区。 另一种常用的 SQL 用途是在使用 dbt (数据生成工具)开发的数据工程管道中。 Databricks 工作流支持协调 dbt 项目。
开发 Scala 代码
Scala 是 Apache Spark™ 的原始语言。 这是一种强大的语言,但它有一个陡峭的学习曲线。 尽管 Scala 是 Databricks 笔记本 中受支持的语言,但存在一些与 Scala 类和对象创建和维护方式相关的限制,这可能会使复杂管道的开发更加困难。 通常,IDE 为开发 Scala 代码提供了更好的支持,然后可以使用 Databricks 工作流中的 JAR 任务进行部署。
后续步骤
- Databricks 上的开发 是有关 Databricks 不同开发选项的文档的入口点。
- 开发人员工具页介绍了可用于本地为 Databricks 开发的不同开发工具,包括 IDE 的声明性自动化捆绑包和插件。
- 在 Databricks 笔记本中开发代码 介绍了如何使用 Databricks 笔记本在 Databricks 工作区中进行开发。
- 在 SQL 编辑器中编写查询和浏览数据。 本文介绍如何使用 Databricks SQL 编辑器处理 SQL 代码。
- 开发 Lakeflow Spark 声明性管道 描述 Lakeflow Spark 声明性管道的开发过程。
- Databricks Connect 允许连接到 Databricks 群集并从本地环境执行代码。
- 了解如何使用 Genie Code 加快开发速度并解决代码问题。