Azure Databricks 工作流可协调 Databricks Data Intelligence 平台中的数据处理、机器学习和分析管道。 工作流具有与 Databricks 平台集成的完全托管的业务流程服务,包括用于在 Azure Databricks 工作区中运行非交互式代码的 Azure Databricks 作业,以及用于生成可靠且可维护的 ETL 管道的增量实时表。
要详细了解使用 Databricks 平台协调工作流的好处,请参阅《Databricks 工作流》。
Azure Databricks 工作流示例
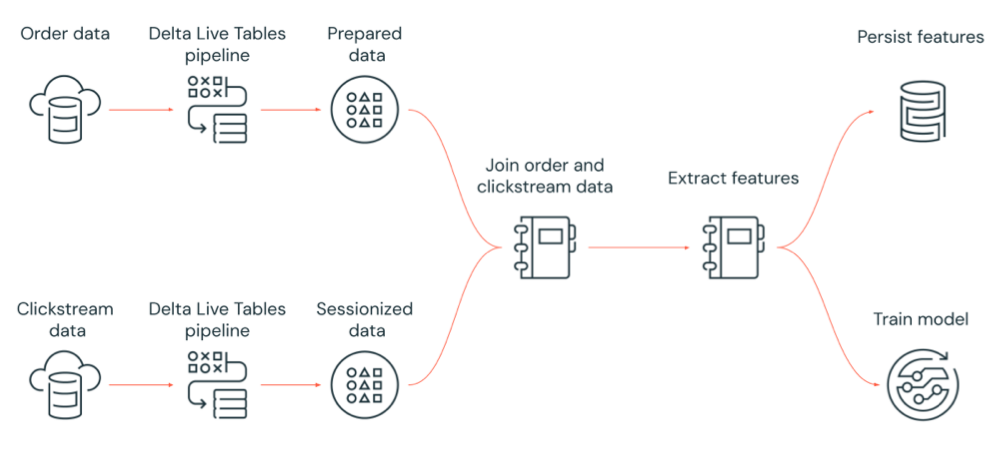
下图演示了由 Azure Databricks 作业协调的、可执行以下操作的工作流:
- 运行增量实时表管道,以便从云存储中引入原始点击流数据,清理和准备数据,会话化数据,并将最终的会话化数据集持久保存到 Delta Lake。
- 运行增量实时表管道,以便从云存储中引入订单数据,清理和转换数据以进行处理,并将最终数据集持久保存到 Delta Lake。
- 联接订单和会话化点击流数据以创建新的数据集进行分析。
- 从准备好的数据中提取特征。
- 并行执行任务,以持久保存特征并训练机器学习模型。
什么是 Azure Databricks 作业?
Azure Databricks 作业是用于在 Azure Databricks 工作区中运行数据处理和分析应用程序的一种方式。 作业可以只包含一个任务,或者也可以是一个具有复杂依赖项的大型多任务工作流。 Azure Databricks 可管理所有作业的任务业务流程、群集管理、监视和错误报告。 你可以立即运行作业,通过易于使用的调度系统定期运行,只要新文件到达外部位置就可以这样做;也可以连续运行以确保作业实例始终处于运行状态。 你还可以在笔记本 UI 中以交互方式运行作业。
可以使用作业 UI、Databricks CLI 或通过调用作业 API 来创建和运行作业。 可以使用 UI 或 API 修复并重新运行失败或取消的作业。 可以使用 UI、CLI、API 和通知(例如电子邮件、Webhook 目标或 Slack 通知)监视作业运行结果。
若要了解如何使用 Databricks CLI,请参阅什么是 Databricks CLI?。 若要了解如何使用作业 API,请参阅作业 API。
以下部分介绍 Azure Databricks 作业的重要功能。
重要
- 工作区仅限 1000 个并发任务运行。 在请求不能立即启动的运行时,将返回
429 Too Many Requests响应。 - 工作区在一小时内可以创建的作业数限制为 10000(包括“运行提交”)。 此限制还会影响 REST API 和笔记本工作流创建的作业。
使用作业任务实现数据处理和分析
可以使用任务来实现数据处理和分析工作流。 一个作业由一个或多个任务组成。 可以创建运行笔记本、JARS、增量实时表管道或者 Python、Scala、Spark 提交和 Java 应用程序的作业任务。 作业任务还可以协调 Databricks SQL 查询、警报和仪表板以创建分析和可视化效果,或者,你可以使用 dbt 任务在工作流中运行 dbt 转换。 还支持旧式 Spark Submit 应用程序。
还可以将任务添加到运行不同作业的作业。 此功能允许将大型进程分解为多个较小的作业,或创建可由多个作业重复使用的通用模块。
可以通过指定任务之间的依赖关系来控制任务的执行顺序。 可将任务配置为按顺序或并行运行。
以交互方式、连续方式或使用作业触发器运行作业
可以通过作业 UI、API 或 CLI 以交互方式运行作业,或者运行连续作业。 可以创建计划以定期运行作业,或者在新文件进入外部位置(例如 Amazon S3、Azure 存储或 Google 云存储)时运行作业。
使用通知监视作业进度
当作业或任务开始、完成或失败时,你可以接收通知。 可以向一个或多个电子邮件地址或系统目标(例如,webhook 目标或 Slack)发送通知。 请参阅针对作业事件添加电子邮件和系统通知。
使用系统表监视作业成本和活动
系统表包含一个 workflow 架构,你可以在其中查看与帐户中的作业活动相关的记录。 请参阅作业系统表参考。
你还可以将作业系统表与计费表相联接,以监视整个帐户中的作业成本。 请参阅使用系统表监视作业成本。
使用 Azure Databricks 计算资源运行作业
Databricks 群集和 SQL 仓库为作业提供计算资源。 可以使用作业群集、通用群集或 SQL 仓库运行作业:
- 作业群集是作业或各个作业任务的专用群集。 作业可以使用由所有任务共享的作业群集,或者你可以在创建或编辑任务时为各个任务配置一个群集。 作业群集在作业或任务开始时创建,在作业或任务结束时终止。
- 通用群集是手动启动和终止的共享群集,可由多个用户和作业共享。
为了优化资源使用,Databricks 建议为作业使用作业群集。 若要减少等待群集启动的时间,请考虑使用通用群集。 请参阅将 Azure Databricks 计算用于作业。
使用 SQL 仓库运行查询、仪表板或警报等 Databricks SQL 任务。 还可以使用 SQL 仓库通过 dbt 任务运行 dbt 转换。
后续步骤
若要开始使用 Azure Databricks 作业,请执行以下操作:
利用快速入门创建你的第一个 Azure Databricks 作业。
了解如何使用 Azure Databricks 作业用户界面来创建并运行工作流。
了解如何在不使用无服务器工作流配置 Azure Databricks 计算资源的情况下运行作业。
了解如何在 Azure Databricks 作业用户界面中监视作业运行。
了解作业的配置选项。
详细了解如何使用 Azure Databricks 作业生成和管理工作流及排查其问题:
- 了解如何使用任务值在 Azure Databricks 作业中的任务之间传达信息。
- 了解如何使用任务参数变量将有关作业运行的上下文传递到作业任务中。
- 了解如何根据任务依赖项的状态将作业任务配置为有条件地运行。
- 了解如何排查和修复失败的作业。
- 当作业运行开始、完成或失败时通过作业运行通知接收通知。
- 按自定义计划触发作业,或运行连续作业。
- 了解如何在新数据到达时通过文件到达触发器运行 Azure Databricks 作业。
- 了解如何使用 Databricks 计算资源运行作业。
- 了解用于支持使用 Azure Databricks 作业来创建和管理工作流的作业 API 更新。
- 在操作指南和教程中详细了解如何使用 Azure Databricks 作业实现数据工作流。
什么是增量实时表?
注意
增量实时表需要高级计划。 有关详细信息,请联系 Databricks 客户团队。
增量实时表是一个简化 ETL 和数据流式处理的框架。 增量实时表内置了对自动加载程序的支持,提供支持以声明方式实现数据转换的 SQL 和 Python 接口,并支持将转换的数据写入 Delta Lake,可让用户高效引入数据。 你定义要对数据执行的转换,而增量实时表管理任务业务流程、群集管理、监视、数据质量和错误处理。
若要开始使用,请参阅什么是增量实时表?。
Azure Databricks 作业和增量实时表
Azure Databricks 作业和增量实时表为生成和部署端到端数据处理与分析工作流提供一个综合性框架。
增量实时表可用于所有数据引入和转换操作。 使用 Azure Databricks 作业可以在 Databricks 平台中协调由单个任务或多个数据处理和分析任务组成的工作负载,包括增量实时表引入和转换。
作为一个工作流业务流程系统,Azure Databricks 作业还支持:
- 触发式运行作业,例如,按计划运行工作流。
- 通过 SQL 查询、机器学习、笔记本、脚本或外部库等进行数据分析。
- 运行由单个任务组成的作业,例如运行 JAR 中打包的 Apache Spark 作业。
使用 Apache AirFlow 协调工作流
尽管 Databricks 建议使用 Azure Databricks 作业来协调数据工作流,但你也可以使用 Apache Airflow 来管理和计划数据工作流。 使用 Airflow 可以在 Python 文件中定义工作流,Airflow 将管理工作流的计划和运行。 请参阅使用 Apache Airflow 协调 Azure Databricks 作业。
使用 Azure 数据工厂协调工作流
Azure 数据工厂 (ADF) 是一项云数据集成服务,可用于将数据存储、移动和处理服务组合到自动化数据管道中。 可以使用 ADF 将 Azure Databricks 作业协调为 ADF 管道的一部分。
若要了解如何使用 ADF Web 活动运行作业,包括如何从 ADF 向 Azure Databricks 进行身份验证,请参阅利用 Azure 数据工厂的 Azure Databricks 作业编排。
ADF 还提供内置支持来运行 ADF 管道中以 JAR 打包的 Databricks 笔记本、Python 脚本或代码。
若要了解如何在 ADF 管道中运行 Databricks 笔记本,请参阅在 Azure 数据工厂中使用 Databricks 笔记本活动运行 Databricks 笔记本,然后参阅通过运行 Databricks 笔记本来转换数据。
若要了解如何在 ADF 管道中运行 Python 脚本,请参阅通过在 Azure Databricks 中运行 Python 活动来转换数据。
若要了解如何在 ADF 管道中运行打包在 JAR 中的代码,请参阅通过在 Azure Databricks 中运行 JAR 活动来转换数据。