你当前正在访问 Microsoft Azure Global Edition 技术文档网站。 如果需要访问由世纪互联运营的 Microsoft Azure 中国技术文档网站,请访问 https://docs.azure.cn。
矢量是以数学方式表示文本、图像和其他内容的高维嵌入。 Azure AI 搜索将矢量存储在字段级别,允许向量和非函数内容在同一搜索索引内共存。
定义矢量字段和矢量配置时,搜索 索引将成为矢量索引 。 若要填充向量字段,你可以将预计算的嵌入推送到其中,或者使用集成矢量化(Azure AI 搜索的一项内置功能,可在索引期间生成嵌入)。
在查询时,索引中的向量字段启用相似性搜索,其中系统检索其向量最类似于矢量查询的文档。 可以单独使用 矢量搜索 进行相似性匹配,也可以将 混合搜索 用于相似性和关键字匹配的组合。
本文介绍创建和管理矢量索引的关键概念,包括:
- 矢量检索模式
- 内容(矢量字段和配置)
- 物理数据结构
- 基本操作
小窍门
想要立即开始? 请参阅 “创建向量索引”。
矢量检索模式
Azure AI 搜索支持两种用于矢量检索的模式:
经典搜索。 此模式使用搜索栏、查询输入和呈现的结果。 在查询执行期间,搜索引擎或应用程序代码将向量化用户输入。 然后,搜索引擎对索引中的向量字段执行矢量搜索,并构建在客户端应用中呈现的响应。
在Azure AI 搜索中,结果将作为平展行集返回,你可以选择要包含在响应中的字段。 尽管搜索引擎在矢量上匹配,但索引应具有非可读内容来填充搜索结果。 经典搜索支持 矢量查询 和 混合查询。
生成搜索。 语言模型使用来自Azure AI 搜索的数据来响应用户查询。 业务流程层通常协调提示和维护上下文,将搜索结果馈送成 GPT 等聊天模型。 此模式基于 检索扩充的生成(RAG) 体系结构,其中搜索索引提供基础数据。
矢量索引的架构
矢量索引的架构需要以下各项:
- 名称
- 关键字段(字符串)
- 一个或多个向量字段
- 矢量配置
不需要非函数字段,但建议将其包括用于混合查询或返回不经过语言模型的逐字内容。 有关详细信息,请参阅创建矢量索引。
索引架构应反映 矢量检索模式。 本部分主要介绍经典搜索的字段组合,但它还提供生成搜索的架构指南。
基本矢量字段配置
矢量字段具有唯一的数据类型和属性。 下面是字段集合中矢量字段的显示方式:
{
"name": "content_vector",
"type": "Collection(Edm.Single)",
"searchable": true,
"retrievable": true,
"dimensions": 1536,
"vectorSearchProfile": "my-vector-profile"
}
矢量字段仅支持 某些数据类型 。 最常见的类型是 Collection(Edm.Single),但使用窄类型可以节省存储。
矢量字段必须可搜索和可检索,但不能筛选、可分面或可排序。 它们也不能具有分析器、规范化器或同义词映射分配。
该 dimensions 属性必须设置为嵌入模型生成的嵌入次数。 例如,text-embedding-ada-002 为每个文本区块生成 1,536 个嵌入。
矢量字段是使用 矢量搜索配置文件中指定的算法编制索引的,该算法在索引中的其他位置定义,在此示例中不显示。 有关详细信息,请参阅 添加矢量搜索配置。
基本矢量工作负载的字段集合
矢量索引需要的不仅仅是向量字段。 例如,所有索引都必须有一个键字段, id 如以下示例所示:
"name": "example-basic-vector-idx",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "key": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": null },
{ "name": "content", "type": "Edm.String", "searchable": true, "retrievable": true, "analyzer": null },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true }
]
其他字段(如 content 字段)提供了 content_vector 字段的人类可读等效。 如果你专门使用语言模型进行响应表述,则可以省略非矢量内容字段,但直接将搜索结果推送到客户端应用的解决方案应具有非矢量内容。
元数据字段对于筛选器非常有用,尤其是在它们包含有关源文档的源信息时。 虽然不能直接在矢量字段上进行筛选,但可以设置预筛选、后期筛选或严格的后期筛选(预览)模式,以在矢量查询执行之前或之后进行筛选。
导入向导生成的架构
建议使用 导入数据 向导 进行评估和概念证明测试。 该向导会在本部分中生成示例架构。
该向导将内容分块成较小的搜索文档,这有利于使用语言模型构建响应的 RAG 应用。 分块有助于你保持在语言模型的输入限制和语义排序器的标记限制之内。 它还通过将查询与从多个父文档中提取的区块进行匹配,从而提高相似性搜索的精度。 有关详细信息,请参阅“为矢量搜索解决方案将大型文档分块”。
对于以下示例中的每个搜索文档,有一个区块 ID、父 ID、区块、标题和矢量字段。 该向导:
使用 base64 编码的 blob 元数据(路径)填充
chunk_id字段和parent_id字段。从 Blob 内容和 blob 名称中分别提取
chunk和title字段。通过调用提供的 Azure OpenAI 嵌入模型来创建
vector字段,以便向量化chunk字段。 在这个过程中,只有向量场被完全生成。
"name": "example-index-from-import-wizard",
"fields": [
{ "name": "chunk_id", "type": "Edm.String", "key": true, "searchable": true, "filterable": true, "retrievable": true, "sortable": true, "facetable": true, "analyzer": "keyword"},
{ "name": "parent_id", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": true},
{ "name": "chunk", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true, "sortable": false},
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "sortable": false},
{ "name": "vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "vector-1707768500058-profile"}
]
生成式搜索的方案
如果要为 RAG 和聊天样式应用设计矢量存储,可以创建两个索引:
- 一个用于已索引和矢量化的静态内容。
- 一个用于可以在提示流中使用的对话。
为了说明目的,本部分使用 chat-with-your-data-solution-accelerator 创建 chat-index 和 conversations 索引。
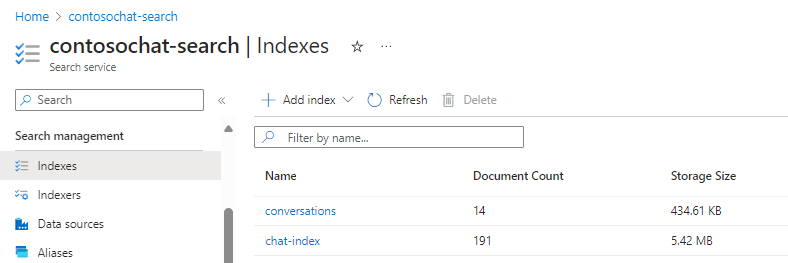
chat-index 中的以下字段支持生成式搜索体验:
"name": "example-index-from-accelerator",
"fields": [
{ "name": "id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "my-vector-profile"},
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "title", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true, "facetable": true },
{ "name": "source", "type": "Edm.String", "searchable": true, "filterable": true, "retrievable": true },
{ "name": "chunk", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "offset", "type": "Edm.Int32", "searchable": false, "filterable": true, "retrievable": true }
]
以下来自conversations的字段支持业务流程编排和聊天历史记录:
"fields": [
{ "name": "id", "type": "Edm.String", "key": true, "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": false },
{ "name": "conversation_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "content", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "content_vector", "type": "Collection(Edm.Single)", "searchable": true, "retrievable": true, "dimensions": 1536, "vectorSearchProfile": "default-profile" },
{ "name": "metadata", "type": "Edm.String", "searchable": true, "filterable": false, "retrievable": true },
{ "name": "type", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "user_id", "type": "Edm.String", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "sources", "type": "Collection(Edm.String)", "searchable": false, "filterable": true, "retrievable": true, "sortable": false, "facetable": true },
{ "name": "created_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true },
{ "name": "updated_at", "type": "Edm.DateTimeOffset", "searchable": false, "filterable": true, "retrievable": true }
]
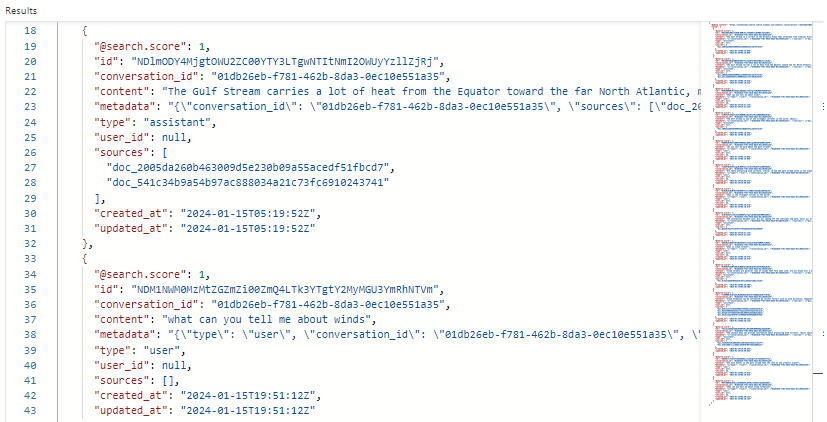
在我们的示例中,搜索评分为 1.00,因为搜索不合格。 多个字段支持编排和提示流:
-
conversation_id标识每个聊天会话。 -
type可指示内容是来自用户还是助手。 -
created_at和updated_at会从历史记录中删除过期的聊天。
物理结构和大小
在Azure AI 搜索中,索引的物理结构主要是内部实现。 可以访问其架构、加载和查询其内容、监视其大小和管理其容量。 但是,微软管理与您的搜索服务一起存储的基础设施和物理数据结构。
索引的大小和实质内容由以下项决定:
文档的数量和构成。
单个字段的属性。 例如,可筛选字段需要更多存储。
索引配置,包括指定如何创建内部导航结构的矢量配置。 可以选择 HNSW 或详尽的 KNN 进行相似性搜索。
Azure AI 搜索对矢量存储施加限制,这有助于为所有工作负荷维护均衡稳定的系统。 为了帮助你保持在限制范围内,系统会在 Azure 门户中单独跟踪和报告矢量使用情况,并通过服务和索引统计信息通过编程方式跟踪和报告。
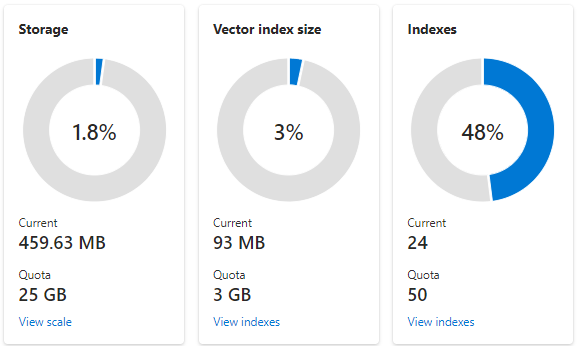
以下屏幕截图显示了配置有一个分区和一个副本的 S1 服务。 此服务有 24 个小索引,每个索引平均包含 1,536 个嵌入的向量字段。 第二个磁贴则显示矢量索引的配额和使用情况。 由于向量索引是为每个向量字段创建的内部数据结构,因此,矢量索引的存储始终是索引使用的总体存储的一小部分。 非向量场和其他数据结构消耗其余部分。
另 一篇文章介绍了矢量索引限制和估计,但需要强调的两点是,最大存储取决于搜索服务的创建日期和定价层。 较新的同层服务可为矢量索引提供显著的更多容量。 出于这些原因,你应:
检查搜索服务的创建日期。 如果它在 2024 年 4 月 3 日之前创建,则可以 升级服务 以提升容量。
如果预计矢量存储要求会发生波动,请选择可缩放层。 对于较旧的搜索服务,基本层固定在一个分区中。 考虑标准 1(S1)和更高版本,以提高灵活性和更快的性能。 还可以在基本层和标准层(S1、S2 和 S3)之间切换。
基本操作和交互
本部分介绍矢量运行时作,包括连接到和保护单个索引。
注意
没有门户或 API 支持移动或复制索引。 通常,可以将应用程序部署指向其他搜索服务(使用相同的索引名称)或修改名称以在当前搜索服务上创建副本,然后生成它。
索引隔离
在Azure AI 搜索中,一次处理一个索引。 所有与索引相关的操作都以单个索引为目标。 无论是编制索引还是查询,都不存在“相关索引”的概念或独立索引的联接。
持续可用
索引在索引第一个文档后立即可供查询使用,但在对所有文档编制索引之前,该索引不会完全正常运行。 在内部,索引跨分区分布,并针对副本执行。 物理索引由内部管理。 你管理逻辑索引。
索引持续可用,无法暂停或脱机。 由于它是为连续操作而设计的,因此内容更新和对索引本身的添加都是实时进行的。 如果请求与文档更新相吻合,查询可能会暂时返回不完整的结果。
文档操作(例如刷新或删除)以及不影响索引现有结构或完整性的修改(如添加新字段)都具有查询连续性。 结构更新(如更改现有字段)通常在开发环境中使用拖放和重新生成工作流进行管理,或者通过在生产服务上创建新版本的索引来管理。
为了避免索引重新生成,一些进行小更改的客户会通过创建与先前版本共存的新字段来“版本化”字段。 随着时间的推移,这会导致过时的字段和过时的自定义分析器定义产生孤立的内容,尤其是在复制成本高昂的生产索引中。 在索引生命周期管理过程中,可以在对索引进行计划内更新期间解决这些问题。
终结点连接
所有矢量索引和查询请求均以索引为目标。 终结点通常是以下其中一项:
| 终结点 | 连接和访问控制 |
|---|---|
<your-service>.search.windows.net/indexes |
以索引集合为目标。 在创建、列出或删除索引时使用。 这些作需要管理员权限,并且可通过管理员 API 密钥 或 搜索参与者角色获得。 |
<your-service>.search.windows.net/indexes/<your-index>/docs |
以单个索引的文档集合为目标。 在查询索引或数据刷新时使用。 对于查询,读取权限足够,可通过查询 API 密钥或数据读取者角色获得。 对于数据刷新,需要管理员权限。 |
如何连接到Azure AI 搜索
请确保你拥有权限或 API 访问密钥。 除非正在查询现有索引,否则需要管理员权限或参与者角色分配来管理和查看搜索服务上的内容。
使用 Azure 门户启动。 创建搜索服务的人员可以查看和管理它,包括授予对 访问控制(IAM) 页上其他人的访问权限。
到其他客户端进行编程访问。 对于第一步,我们推荐快速入门:使用 REST 的矢量搜索和azure-search-vector-samples代码库。
管理矢量存储
Azure提供监视平台,其中包括诊断日志记录和警报。 建议:
保护对矢量数据的访问
Azure AI 搜索 实现数据加密、适用于无互联网场景的专用连接,并通过 Microsoft Entra ID 的角色分配提供安全访问。 有关企业安全功能的详细信息,请参阅 数据、隐私和内置保护。