本教程介绍如何训练多个机器学习模型以选择最佳模型,以便预测哪些银行客户可能离开。
在本教程中,你将:
- 训练 Random Forest 和 LightGBM 模型。
- 使用 Microsoft Fabric 与 MLflow 框架的本机集成来记录训练的机器学习模型、使用的超参数和评估指标。
- 注册训练的机器学习模型。
- 评估验证数据集上训练的机器学习模型的性能。
MLflow 是一个开源平台,用于使用跟踪、模型和模型注册表等功能管理机器学习生命周期。 MLflow 原生与 Fabric 数据科学体验集成。
先决条件
获取 Microsoft Fabric 订阅。 或者注册免费的 Microsoft Fabric 试用版。
登录 Microsoft Fabric。
使用主页左下侧的体验切换器切换到 Fabric。
显示在体验切换器菜单上选择 Fabric 的屏幕截图。
这是系列教程的第 3 部分(共 5 部分)。 若要完成本教程,请先完成:
在笔记本中继续操作
3-train-evaluate.ipynb 是本教程随附的笔记本。
要打开本教程配套的笔记本,请按照为数据科学准备系统教程中的说明操作,将笔记本导入工作区。
或者,如果要从此页面复制并粘贴代码,则可以创建新的笔记本。
在开始运行代码之前,请务必将湖屋连接到笔记本。
重要
附加第 1 部分和第 2 部分中使用的湖屋。
安装自定义库
对于此笔记本,你将使用 imblearn 安装不平衡学习(导入为 %pip install)。 不平衡学习是合成少数过采样技术 (SMOTE) 的库,在处理不平衡数据集时使用。 PySpark 内核将在 %pip install 之后重启,因此需要先安装库,然后才能运行任何其他单元格。
你将使用 imblearn 库访问 SMOTE。 现在使用内联安装功能(例如 %pip、%conda)进行安装。
# Install imblearn for SMOTE using pip
%pip install imblearn
%pip install scikit-learn==1.6.1
%pip install "mlflow==2.12.2"
重要
每次重启笔记本时,都要运行此安装。
在笔记本中安装库时,它将仅在笔记本会话期间可用,而不适用于工作区。 如果重新启动笔记本,则需要再次安装库。
如果有经常要使用的库,并且想要将其对工作区中的所有笔记本开放,则可以使用针对此用途的 Fabric 环境。 可以创建一个环境并在其中安装库,然后“工作区管理员”可以将该环境作为默认环境附加到工作区。 有关将环境设置为工作区默认值的详细信息,请参阅管理员设置工作区的默认库。
有关将现有工作区库和 Spark 属性迁移到环境的信息,请参阅将工作区库和 Spark 属性迁移到默认环境。
加载数据
在训练任何机器学习模型之前,需要从湖屋加载 delta 表,以便读取在上一笔记本中创建的清理数据。
import pandas as pd
SEED = 12345
df_clean = spark.read.format("delta").load("Tables/df_clean").toPandas()
使用 MLflow 生成用于跟踪和记录模型的试验
本部分演示如何生成试验、指定机器学习模型和训练参数以及评分指标、训练机器学习模型、记录这些模型,以及保存训练的模型供以后使用。
import mlflow
# Setup experiment name
EXPERIMENT_NAME = "bank-churn-experiment-SBM" # MLflow experiment name
自动记录扩展了 MLflow 自动记录功能,它的工作原理是在训练机器学习模型时自动捕获其输入参数和输出指标的值。 然后,该信息会记录到工作区。在那里,可以使用 MLflow API 或工作区中的相应试验对其进行访问和可视化。
所有具有各自名称的试验都将被记录下来,并且你能够跟踪其参数和性能指标。 若要详细了解自动记录,请参阅 Microsoft Fabric 中的自动记录。
设置试验和自动记录规范
mlflow.set_experiment(EXPERIMENT_NAME)
mlflow.autolog(exclusive=False)
导入 scikit-learn 和 LightGBM
准备好数据后,便可以定义机器学习模型。 你将在此笔记本中应用 Random Forest 和 LightGBM 模型。 使用 scikit-learn 和 lightgbm 通过短短几行代码实现模型。
# Import the required libraries for model training
from sklearn.model_selection import train_test_split
from lightgbm import LGBMClassifier
from sklearn.ensemble import RandomForestClassifier
from sklearn.metrics import accuracy_score, f1_score, precision_score, confusion_matrix, recall_score, roc_auc_score, classification_report
准备训练、验证和测试数据集
使用 train_test_split 中的 scikit-learn 函数将数据拆分为训练、验证和测试集。
y = df_clean["Exited"]
X = df_clean.drop("Exited",axis=1)
# Split the dataset to 60%, 20%, 20% for training, validation, and test datasets
# Train-Test Separation
X_train, X_test, y_train, y_test = train_test_split(X, y, test_size=0.20, random_state=SEED)
# Train-Validation Separation
X_train, X_val, y_train, y_val = train_test_split(X_train, y_train, test_size=0.25, random_state=SEED)
将测试数据保存到 delta 表
将测试数据保存到 delta 表,以便在下一个笔记本中使用。
table_name = "df_test"
# Create PySpark DataFrame from Pandas
df_test=spark.createDataFrame(X_test)
df_test.write.mode("overwrite").format("delta").save(f"Tables/{table_name}")
print(f"Spark test DataFrame saved to delta table: {table_name}")
将 SMOTE 应用于训练数据,以合成少数类的新样本
第 2 部分的数据探索显示,在与 10,000 个客户对应的 10,000 个数据点中,只有 2,037 个客户(约 20%)离开银行。 这表示数据集高度不平衡。 分类不平衡的问题在于,少数类的示例太少,模型无法有效了解决策边界。 SMOTE 是为少数类合成新样本的最广泛使用的方法。 在此处和此处了解有关 SMOTE 的详细信息。
提示
请注意,SMOTE 应仅应用于训练数据集。 必须使测试数据集保留为其原始不平衡分布,以便获取有关机器学习模型在处理原始数据时的表现的有效近似值,这代表了生产环境中的情况。
from collections import Counter
from imblearn.over_sampling import SMOTE
sm = SMOTE(random_state=SEED)
X_res, y_res = sm.fit_resample(X_train, y_train)
new_train = pd.concat([X_res, y_res], axis=1)
提示
运行此单元格时显示的 MLflow 警告消息可以安全地忽略。
如果看到 ModuleNotFoundError 消息,则表示没有运行此笔记本中的第一个单元格,这会安装 imblearn 库。 每次重启笔记本时,都需要再次安装此库。 返回并从此笔记本中的第一个单元格开始重新运行所有单元格。
模型定型
- 使用随机林训练模型,最大深度为 4,具有 4 个特征
mlflow.sklearn.autolog(registered_model_name='rfc1_sm') # Register the trained model with autologging
rfc1_sm = RandomForestClassifier(max_depth=4, max_features=4, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc1_sm") as run:
rfc1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc1_sm_run_id, run.info.status))
# rfc1.fit(X_train,y_train) # Imbalanaced training data
rfc1_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc1_sm.score(X_val, y_val)
y_pred = rfc1_sm.predict(X_val)
cr_rfc1_sm = classification_report(y_val, y_pred)
cm_rfc1_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc1_sm = roc_auc_score(y_res, rfc1_sm.predict_proba(X_res)[:, 1])
- 使用随机林训练模型,最大深度为 8,具有 6 个特征
mlflow.sklearn.autolog(registered_model_name='rfc2_sm') # Register the trained model with autologging
rfc2_sm = RandomForestClassifier(max_depth=8, max_features=6, min_samples_split=3, random_state=1) # Pass hyperparameters
with mlflow.start_run(run_name="rfc2_sm") as run:
rfc2_sm_run_id = run.info.run_id # Capture run_id for model prediction later
print("run_id: {}; status: {}".format(rfc2_sm_run_id, run.info.status))
# rfc2.fit(X_train,y_train) # Imbalanced training data
rfc2_sm.fit(X_res, y_res.ravel()) # Balanced training data
rfc2_sm.score(X_val, y_val)
y_pred = rfc2_sm.predict(X_val)
cr_rfc2_sm = classification_report(y_val, y_pred)
cm_rfc2_sm = confusion_matrix(y_val, y_pred)
roc_auc_rfc2_sm = roc_auc_score(y_res, rfc2_sm.predict_proba(X_res)[:, 1])
- 使用 LightGBM 训练模型
# lgbm_model
mlflow.lightgbm.autolog(registered_model_name='lgbm_sm') # Register the trained model with autologging
lgbm_sm_model = LGBMClassifier(learning_rate = 0.07,
max_delta_step = 2,
n_estimators = 100,
max_depth = 10,
eval_metric = "logloss",
objective='binary',
random_state=42)
with mlflow.start_run(run_name="lgbm_sm") as run:
lgbm1_sm_run_id = run.info.run_id # Capture run_id for model prediction later
# lgbm_sm_model.fit(X_train,y_train) # Imbalanced training data
lgbm_sm_model.fit(X_res, y_res.ravel()) # Balanced training data
y_pred = lgbm_sm_model.predict(X_val)
accuracy = accuracy_score(y_val, y_pred)
cr_lgbm_sm = classification_report(y_val, y_pred)
cm_lgbm_sm = confusion_matrix(y_val, y_pred)
roc_auc_lgbm_sm = roc_auc_score(y_res, lgbm_sm_model.predict_proba(X_res)[:, 1])
用于跟踪模型性能的试验项目
试验运行会自动保存在可从工作区中找到的试验项目中。 它们根据用于设置试验的名称进行命名。 记录所有经过训练的机器学习模型及其运行、性能指标和模型参数。
查看试验:
在左侧面板中,选择工作区。
在右上角可进行筛选,使其仅显示试验,以便更轻松地查找所需的试验。
查找并选择试验名称,在本例中为 bank-churn-experiment。 如果在工作区中未看到试验,请刷新浏览器。


评估验证数据集上训练的模型的性能
完成机器学习模型训练后,可以通过两种方式评估已训练模型的性能。
从工作区打开保存的试验,加载机器学习模型,然后在验证数据集上评估加载的模型的性能。
# Define run_uri to fetch the model # mlflow client: mlflow.model.url, list model load_model_rfc1_sm = mlflow.sklearn.load_model(f"runs:/{rfc1_sm_run_id}/model") load_model_rfc2_sm = mlflow.sklearn.load_model(f"runs:/{rfc2_sm_run_id}/model") load_model_lgbm1_sm = mlflow.lightgbm.load_model(f"runs:/{lgbm1_sm_run_id}/model") # Assess the performance of the loaded model on validation dataset ypred_rfc1_sm_v1 = load_model_rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v1 = load_model_rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v1 = load_model_lgbm1_sm.predict(X_val) # LightGBM直接评估验证数据集上训练的机器学习模型的性能。
ypred_rfc1_sm_v2 = rfc1_sm.predict(X_val) # Random Forest with max depth of 4 and 4 features ypred_rfc2_sm_v2 = rfc2_sm.predict(X_val) # Random Forest with max depth of 8 and 6 features ypred_lgbm1_sm_v2 = lgbm_sm_model.predict(X_val) # LightGBM
根据偏好,任一方法都是正常的,应提供相同的性能。 在此笔记本中,你将选择第一种方法,以便更好地演示 Microsoft Fabric 中的 MLflow 自动记录功能。
使用混淆矩阵显示真正、假正、真负和假负
接下来,你将开发一个脚本来绘制混淆矩阵,以便使用验证数据集评估分类的准确性。 还可以使用 SynapseML 工具绘制混淆矩阵,如此处可用的欺诈检测示例中所示。
import seaborn as sns
sns.set_theme(style="whitegrid", palette="tab10", rc = {'figure.figsize':(9,6)})
import matplotlib.pyplot as plt
import matplotlib.ticker as mticker
from matplotlib import rc, rcParams
import numpy as np
import itertools
def plot_confusion_matrix(cm, classes,
normalize=False,
title='Confusion matrix',
cmap=plt.cm.Blues):
print(cm)
plt.figure(figsize=(4,4))
plt.rcParams.update({'font.size': 10})
plt.imshow(cm, interpolation='nearest', cmap=cmap)
plt.title(title)
plt.colorbar()
tick_marks = np.arange(len(classes))
plt.xticks(tick_marks, classes, rotation=45, color="blue")
plt.yticks(tick_marks, classes, color="blue")
fmt = '.2f' if normalize else 'd'
thresh = cm.max() / 2.
for i, j in itertools.product(range(cm.shape[0]), range(cm.shape[1])):
plt.text(j, i, format(cm[i, j], fmt),
horizontalalignment="center",
color="red" if cm[i, j] > thresh else "black")
plt.tight_layout()
plt.ylabel('True label')
plt.xlabel('Predicted label')
- 随机林分类器的混淆矩阵,最大深度为 4,具有 4 个特征
cfm = confusion_matrix(y_val, y_pred=ypred_rfc1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 4')
tn, fp, fn, tp = cfm.ravel()
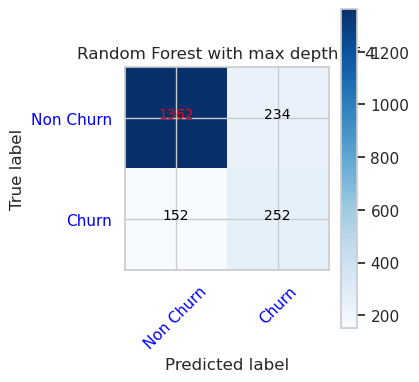
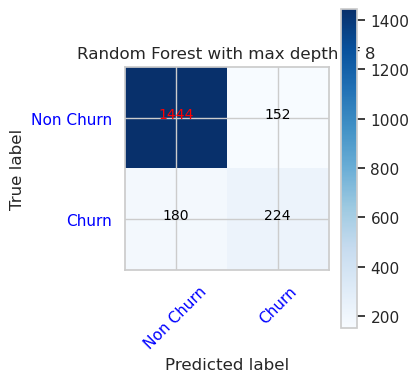
- 随机林分类器的混淆矩阵,最大深度为 8,具有 6 个特征
cfm = confusion_matrix(y_val, y_pred=ypred_rfc2_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='Random Forest with max depth of 8')
tn, fp, fn, tp = cfm.ravel()
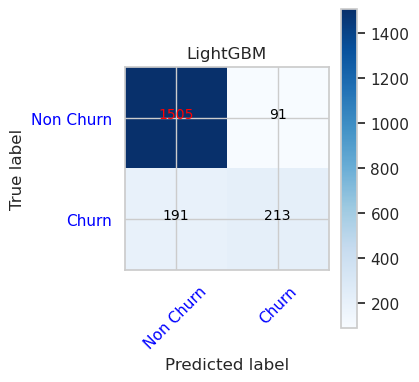
- LightGBM 的混淆矩阵
cfm = confusion_matrix(y_val, y_pred=ypred_lgbm1_sm_v1)
plot_confusion_matrix(cfm, classes=['Non Churn','Churn'],
title='LightGBM')
tn, fp, fn, tp = cfm.ravel()