适用于:✅SQL 分析终结点和 Microsoft Fabric 中的仓库
本教程介绍如何使用仓库中的笔记本分析数据。
创建 T-SQL 笔记本
在此任务中,了解如何创建 T-SQL 笔记本。
请确保在 第一个教程中创建的工作区 处于打开状态。
在
主页 功能区上,打开“新建 SQL 查询” 下拉列表,然后在笔记本中选择“新建 SQL 查询”。 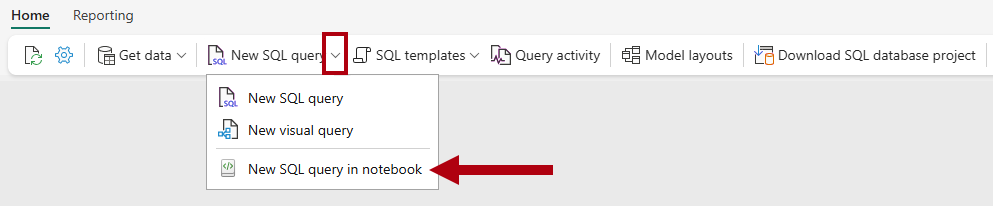
在 资源管理器 窗格中,选择 仓库 以显示
Wide World Importers仓库的对象。若要生成 SQL 模板以浏览数据,请在
dimension_city表右侧选择省略号(...),然后选择 SELECT TOP 100。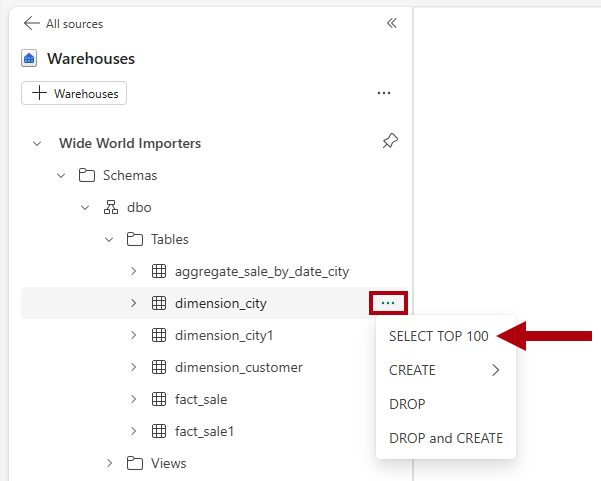
若要在此单元格中运行 T-SQL 代码,请选择代码单元的 运行单元 按钮。

在结果窗格中查看查询结果。


使用笔记本创建湖屋快捷方式并分析数据
在此任务中,了解如何使用笔记本创建湖屋快捷方式并分析数据。
打开
Data Warehouse Tutorial工作区登陆页。选择“+ 新建项 以显示可用项类型的完整列表。
在列表的“存储数据”部分中,选择“湖屋”项类型。
在“新建湖屋”窗口中,输入名称
Shortcut_Exercise。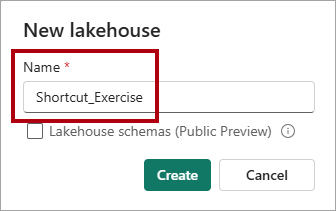
选择创建。
当新的湖屋打开时,在登陆页面中选择“新建快捷方式”选项。
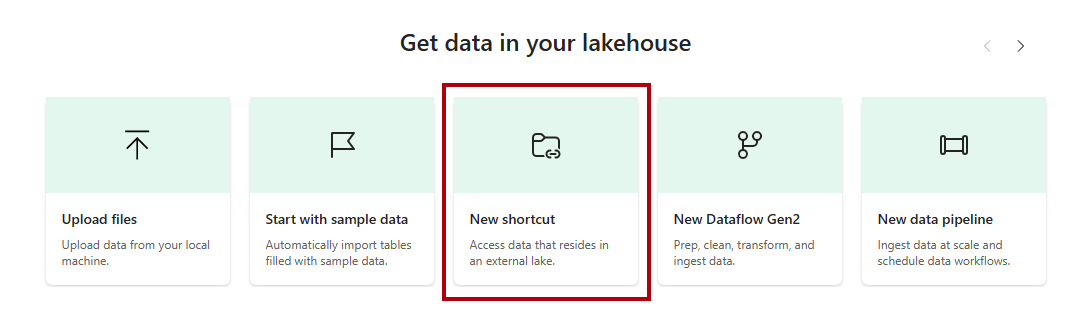
在 “新建快捷方式”窗口中,选择 Microsoft OneLake 选项。
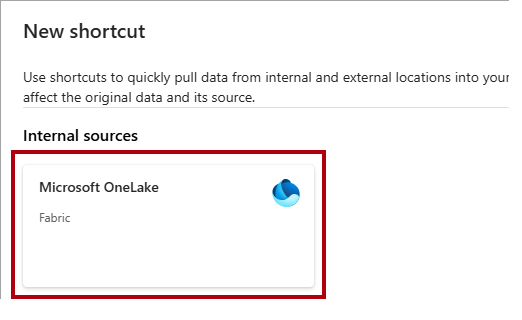
Wide World Importers在“选择数据源类型”窗口中,选择在创建数据仓库教程中创建的数据仓库,然后选择“下一步”。在 OneLake 对象浏览器中,展开“表”,展开
dbo架构,然后选中dimension_customer表的复选框。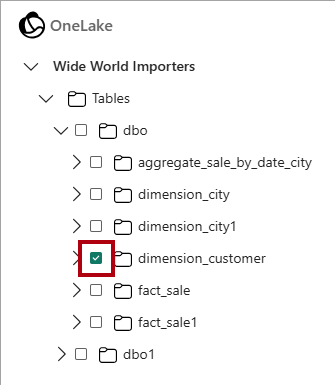
选择下一步。
选择创建。
在 资源管理器 窗格中,选择
dimension_customer表预览数据,然后查看从仓库中的dimension_customer表中检索的数据。若要创建用于查询
dimension_customer表的笔记本,请在 主页 功能区中的 “打开笔记本” 下拉列表中,选择 “新建笔记本”。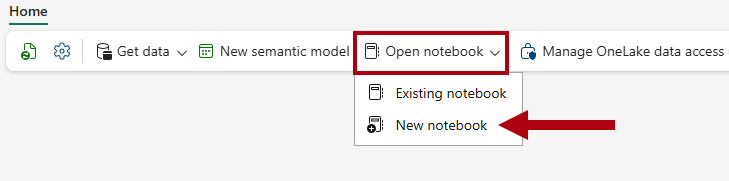
在资源管理器窗格中,选择“湖屋”。
将
dimension_customer表格拖到已打开的笔记本单元格中。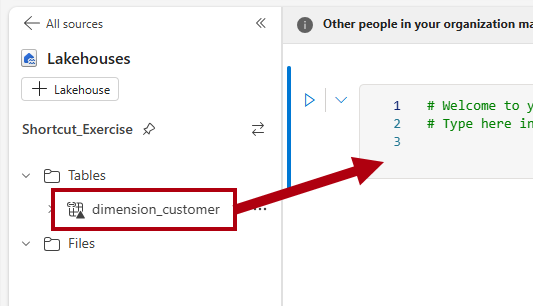
请注意添加到笔记本单元格的 PySpark 查询。 此查询从
Shortcut_Exercise.dimension_customer快捷方式检索前 1,000 行。 此笔记本体验类似于 Visual Studio Code Jupyter 笔记本体验。 还可以在 VS Code 中打开笔记本。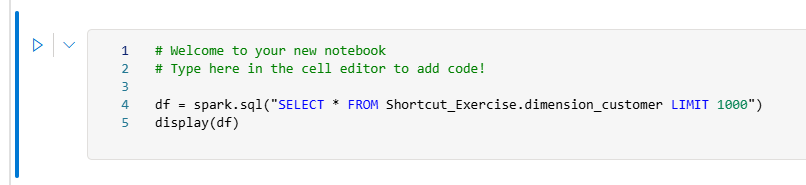
在“主页”功能区上,选择“全部运行”按钮。

在结果窗格中查看查询结果。


下一步
教程:在仓库 中创建跨仓库查询