本文概述了如何处理 M 查询并将其转换为数据源请求。
Power Query M 脚本
任何查询(无论是由 Power Query 创建、由高级编辑器手动编写还是使用空白文档输入)都由 Power Query M 公式语言中的函数和语法组成。 此查询由 Power Query 引擎解释和评估,以输出其结果。 M 脚本充当评估查询所需的指令集。
小窍门
可以将 M 脚本视为描述如何准备数据的食谱。
创建 M 脚本的最常见方法是使用 Power Query 编辑器。 例如,连接到数据源(如 SQL Server 数据库)时,请注意屏幕右侧有一个名为 “已应用步骤”的部分。 本部分显示查询中使用的所有步骤或转换。 从这个意义上说,Power Query 编辑器充当一个接口,可帮助你为之后的转换创建适当的 M 脚本,并确保所使用的代码有效。
注释
Power Query 编辑器中使用 M 脚本可以:
- 将查询显示为一系列步骤,并允许创建新步骤或修改。
- 显示关系图视图。

上图强调已应用的步骤部分,其中包含以下步骤:
- 源:与数据源建立连接。 在这种情况下,它是与 SQL Server 数据库的连接。
- 导航:导航到数据库中的特定表。
- 删除了其他列:选择要保留的表中的哪些列。
- 已排序的行:使用一个或多个列对表进行排序。
- 保留前几行:筛选表以仅保留表顶部的某些行。
这组步骤名称是查看 Power Query 为你创建的 M 脚本的友好方式。 可通过多种方式查看完整的 M 脚本。 在 Power Query 中,可以在“视图”选项卡中选择“高级编辑器”。还可以从“开始”选项卡中的“查询”组中选择“高级编辑器”。在某些版本的 Power Query 中,还可以更改公式栏视图,通过转到“视图”选项卡并从“布局”组中选择“脚本视图”来显示查询脚本。

在“应用的步骤”窗格中找到的大多数名称也在 M 脚本中按原样使用。 查询的步骤是使用 M 语言中称为 标识符 的内容命名的。 有时候,步骤名称会被额外的字符包裹在 M 中,但这些字符不会出现在应用的步骤里。 例如 #"Kept top rows",由于这些额外的字符,它被归类为 带引号的标识符 。 引号标识符可用于允许将零个或多个 Unicode 字符的任何序列用作标识符,包括关键字、空格、注释、运算符和标点符号。 若要详细了解 M 语言中的 标识符 ,请转到 词法结构。
通过 Power Query 编辑器对查询所做的任何更改都会自动更新查询的 M 脚本。 例如,使用上一个图像作为起点,如果将 “保留前几行 ”步骤名称更改为 前 20 行,则此更改将在脚本视图中自动更新。

虽然我们建议使用 Power Query 编辑器为你创建所有或大部分 M 脚本,但可以手动添加或修改 M 脚本的片段。 若要了解有关 M 语言的详细信息,请转到 M 语言的官方文档网站。
注释
M 脚本(也称为 M 代码)是用于任何使用 Power Query M 语言的代码的术语。 在本文中,M 脚本还引用了 Power Query 查询中找到的代码,并通过高级编辑器窗口或编辑栏中的脚本视图进行访问。
Power Query 中的查询评估
下图探讨了在 Power Query 中计算查询时发生的过程。
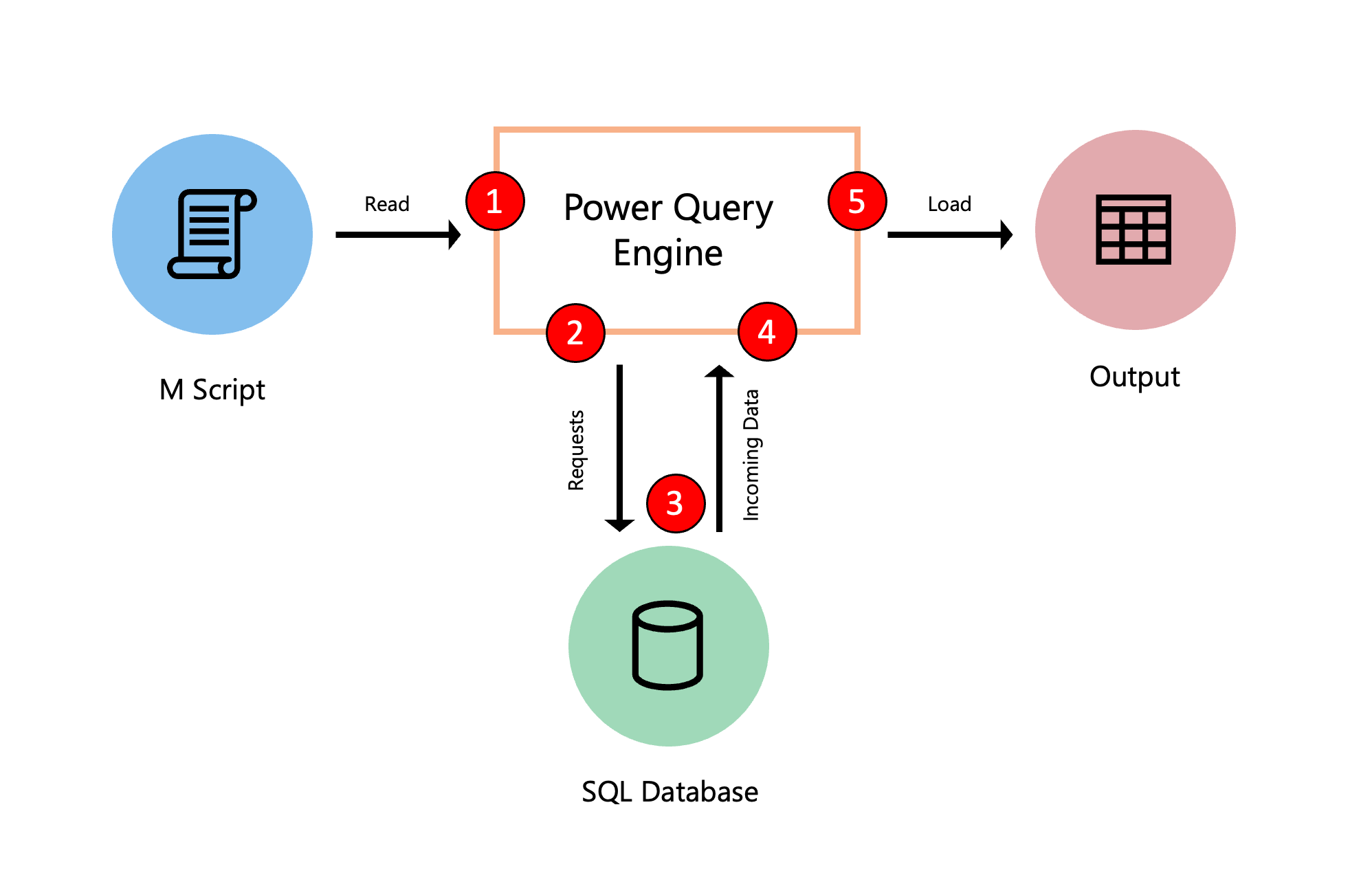
- 在高级编辑器中找到的 M 脚本将提交到 Power Query 引擎。 还包括其他重要信息,例如凭据和数据源隐私级别。
- Power Query 确定需要从数据源中提取哪些数据,并向数据源提交请求。
- 数据源通过将请求的数据传输到 Power Query 来响应来自 Power Query 的请求。
- Power Query 从数据源接收传入数据,并在必要时使用 Power Query 引擎执行任何转换。
- 从上一步派生的结果将加载到目的地。
注释
虽然此示例展示了将 SQL 数据库作为数据源的查询,但概念适用于具有或不带数据源的查询。
Power Query 读取 M 脚本时,它会通过优化过程运行脚本,以更有效地评估查询。 在此过程中,它会确定查询中的哪些步骤(转换)可转移给数据源。 它还确定需要使用 Power Query 引擎评估哪些其他步骤。 此优化过程称为 查询折叠,其中 Power Query 尝试将尽可能多的执行推送到数据源以优化查询的执行。
重要
Power Query M 公式语言(也称为 M 语言)中的所有规则都遵循。 最值得注意的是, 延迟评估 在优化过程中起着重要作用。 在此过程中,Power Query 了解查询中的哪些特定转换需要进行评估。 Power Query 能够识别哪些其他转换不需要被评估,因为它们对查询结果没有影响。
此外,当涉及多个源时,评估查询时,将考虑每个数据源的数据隐私级别。 详细信息: 数据隐私防火墙的幕后
下图演示了在此优化过程中执行的步骤。
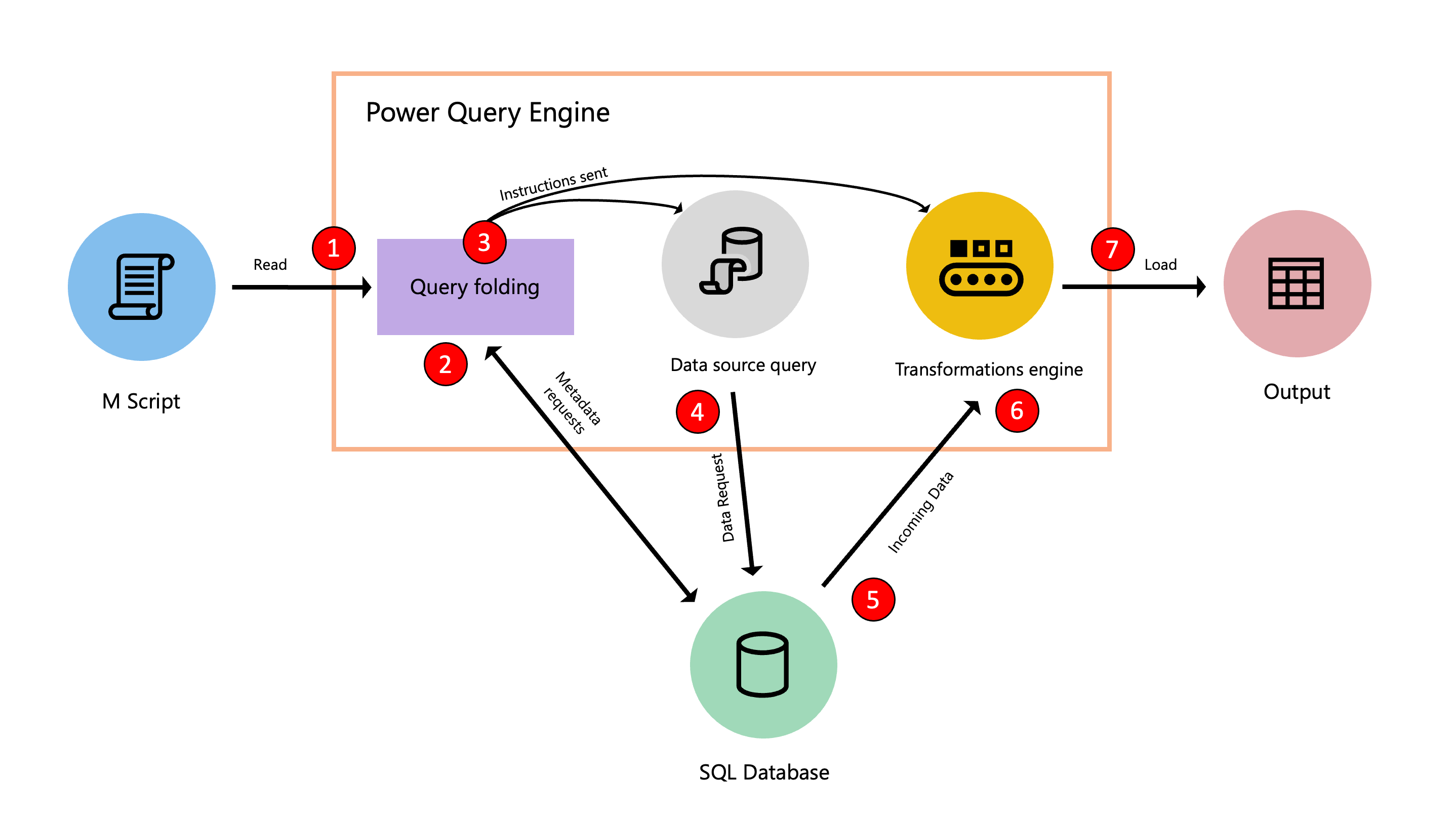
- 在高级编辑器中找到的 M 脚本将提交到 Power Query 引擎。 还提供了其他重要信息,例如凭据和数据源隐私级别。
- 查询折叠机制将元数据请求提交到数据源,以确定数据源、表架构、数据源中不同表之间的关系等的功能。
- 根据收到的元数据,查询折叠机制确定要从数据源中提取哪些信息,以及 Power Query 引擎内需要执行哪些转换集。 它将指令发送到另外两个组件,这些组件负责从数据源检索数据,并在必要时转换 Power Query 引擎中的传入数据。
- Power Query 的内部组件收到说明后,Power Query 会使用数据源查询向数据源发送请求。
- 数据源从 Power Query 接收请求,并将数据传输到 Power Query 引擎。
- 数据进入 Power Query 后,Power Query(也称为糅合引擎)中的转换引擎会进行无法往回折叠或转移给数据源的转换。
- 从上一个点派生的结果将加载到目标。
注释
根据 M 脚本中使用的转换和数据源,Power Query 确定它是否流式传输或缓冲传入数据。
查询折叠概述
查询折叠的目标是将查询的大部分计算转移或推送给可以计算查询转换的数据源。
查询折叠机制通过将 M 脚本转换为数据源可以解释和执行的语言来实现此目标。 然后,它将评估推送到数据源,并将该评估的结果发送到 Power Query。
此操作通常提供比直接从数据源提取所有所需数据并在 Power Query 引擎中执行所有必要转换更快的查询执行速度。
使用 获取数据功能时,Power Query 会指导你完成连接到数据源的整个过程。 执行此作时,Power Query 使用 M 语言中分类为 访问数据函数的一系列函数。 这些特定函数使用机制和协议通过数据源可以理解的语言连接到数据源。
但是,查询中执行的步骤是查询折叠机制尝试优化的步骤或转换。 然后,它会检查是否可以将其卸载到数据源,而不是使用 Power Query 引擎进行处理。
重要
所有数据源函数(通常显示为查询的 源 步骤)以本机语言查询数据源中的数据。 查询折叠机制应用于数据源函数之后对查询执行的所有转换。 然后,这些转换可转换和合并为单个数据源查询,也可以转换和合并为可转移到数据源的任意数量的转换。
根据查询的结构,查询折叠机制可能有三种可能的结果:
- 完整查询折叠:当所有查询转换被推送回数据源且在 Power Query 引擎中进行的处理最少时。
- 部分查询折叠:仅当查询中的部分转换(而不是全部)可以推送回数据源时。 在这种情况下,只有一部分转换在数据源中完成,其余查询转换发生在 Power Query 引擎中。
- 无查询折叠:当查询包含无法转换为数据源特定查询语言的转换时,要么因为不支持这些转换,要么连接器不支持查询折叠。 在这种情况下,Power Query 从数据源获取原始数据,并使用 Power Query 引擎通过处理 Power Query 引擎级别的所需转换来实现所需的输出。
注释
查询折叠机制在连接器中主要可用于结构化数据源,例如(但不限于)Microsoft SQL Server 和 OData 源。 在优化阶段,引擎有时可能会在查询中重新排序步骤。
使用具有更多处理资源的数据源并具有查询折叠功能可以加快查询加载时间,因为处理发生在数据源而不是 Power Query 引擎。
相关内容
有关查询折叠机制的三个可能结果的详细示例,请转到 查询折叠示例。
有关在“应用步骤”窗格中找到的查询折叠指示器的信息,请转到“查询折叠指示器”