Microsoft Foundry on Windows是希望将本地 AI 功能集成到其Windows应用中的开发人员的首要解决方案。
Microsoft Foundry on Windows为开发人员提供...
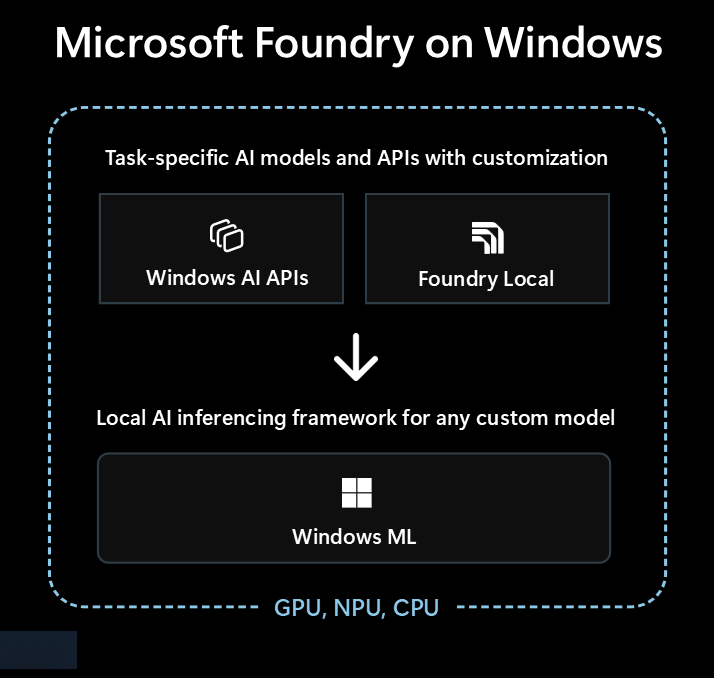
- 即用型 AI 模型和 API通过 Windows AI APIs 和 Foundry Local
- 用于通过本地运行任何模型的 AI 推理框架Windows ML
无论你是 AI 新手,还是经验丰富的Machine Learning(ML)专家,Microsoft Foundry on Windows都有一些适合你的东西。
现成的 AI 模型和 API
应用可以在不到一小时内轻松使用以下本地 AI 模型和 API。 模型文件的分发和运行时由Microsoft处理,模型跨应用共享。 使用这些模型和 API 只需几行代码,无需具备零 ML 专业知识。
| 模型类型或 API | 这是什么 | 选项和支持的设备 |
|---|---|---|
| 大型语言模型(LLM) | 生成文本模型 | Phi Silica 通过 AI APIs (支持微调)或 通过 Foundry Local 的 20 多个 OSS LLM 模型 请参阅 本地 LLM 了解详细信息。 |
| 图像说明 | 获取图像的自然语言文本说明 | 通过 AI APIs 图像描述(Copilot+ 电脑) |
| 图像前景提取工具 | 分割图像的前景 | Image Foreground Extractor via AI APIs (Copilot+ PC) |
| 图像生成 | 从文本生成图像 | 图像生成通过AI APIs(Copilot+ 电脑) |
| 图像对象擦除 | 擦除图像中的对象 | |
| 图像对象提取程序 | 对图像中的特定对象进行分段 | 图像对象提取器通过 AI APIs(Copilot+ PC) |
| 图像超分辨率 | 提高图像分辨率 | 图像超分辨率通过 AI APIs(Copilot+ 电脑) |
| 语义搜索 | 语义上搜索文本和图像 | 通过 AI APIs 应用内容搜索 (Copilot+ 电脑) |
| 语音识别 | 将语音转换为文本 | 通过 Whisper 或 Windows SDK 进行语音识别 有关详细信息,请参阅 语音识别 。 |
| 文本识别(OCR) | 识别图像中的文本 | OCR 通过 AI APIs (Copilot+ PC) |
| 视频超分辨率 (VSR) | 提高视频分辨率 | 视频超级分辨率通过AI APIs (Copilot+ 电脑) |
将其他模型与 Windows ML 配合使用
可以使用 Hugging Face 或其他来源的各种模型,甚至可以训练自己的模型,并在 Windows 10 及更高版本的 PC 上本地运行这些模型Windows ML(模型兼容性和性能因设备硬件而异)。
有关详细信息,请参阅 查找或训练模型以用于 Windows ML。
要从哪个选项开始
按照此决策树选择应用程序和方案的最佳方法:
检查内置 Windows AI APIs 是否涵盖你的场景,并且你的目标是 Copilot+ 电脑。 这是以最少的开发工作量进入市场最快的途径。
如果 Windows AI APIs 没有所需内容,或者需要支持 Windows 10 及更高版本,请考虑使用 LLM 或语音转文本方案Foundry Local。
如果需要自定义模型,想要利用拥抱人脸或其他源中的现有模型,或者具有上述选项未涵盖的特定模型要求,Windows ML让你能够灵活地查找或训练自己的模型(并支持Windows 10及更高版本)。
你的应用还可以结合使用这三种技术。
适用于本地 AI 的技术
Microsoft Foundry on Windows中提供了以下技术:
| Windows AI APIs | Foundry Local | Windows ML | |
|---|---|---|---|
| 这是什么 | 适用于各种任务类型的现成 AI 模型和 API,针对 Copilot+ 电脑进行优化 | 现成的 LLM 和语音转文本模型 | ONNX Runtime 用于运行查找或训练的模型的框架 |
| 支持的设备 | Copilot+ 电脑 | Windows 10及更高版本的电脑及跨平台 (性能因可用硬件而异,并非所有可用的模型) |
Windows 10 及更高版本的电脑,以及通过开源实现的跨平台功能 (性能因可用硬件而异) |
| 可用的模型类型和 API |
LLM 图像说明 图像前景提取工具 图像生成 图像对象擦除 图像对象提取程序 图像超分辨率 语义搜索 文本识别(OCR) 视频超分辨率 |
LLM (多个) 语音转文本 浏览 20 多个可用模型 |
查找或训练自己的模型 |
| 模型分布 | 由Microsoft托管,在运行时获取,并在应用之间共享 | 由Microsoft托管,在运行时获取,并在应用之间共享 | 由应用处理的分发(应用库可以 跨应用共享模型) |
| 了解详细信息 | 阅读该文档AI APIs | 阅读该文档Foundry Local | 阅读该文档Windows ML |
Microsoft Foundry on Windows还包括开发人员工具,例如 Foundry Toolkit for Visual Studio Code 和 AI 开发库,可帮助你成功生成 AI 功能。
Foundry Toolkit for Visual Studio Code 是一个 VS Code 扩展,可用于在本地下载和运行 AI 模型,包括访问硬件加速以提高性能和通过 DirectML 进行缩放。 Foundry Toolkit 还可以帮助你:
- 使用 REST API 在直观的测试环境或应用程序中测试模型。
- 微调 AI 模型(在本地或云中)以创建新技能,提高响应的可靠性,设置响应的基调和格式。
- 微调流行的小型语言模型(SLM),如 Phi-3 和 Mistral。
- 将 AI 功能部署到云或使用在设备上运行的应用程序。
- 使用 DirectML 利用硬件加速提高 AI 功能的性能。 DirectML 是一种低级别 API,使Windows设备硬件能够使用设备 GPU 或 NPU 加速 ML 模型的性能。 将 DirectML 与 ONNX Runtime 配对通常是开发人员大规模为用户带来硬件加速 AI 的最直接方法。 了解详细信息:DirectML 概述。
- 使用模型转换功能量化和验证用于 NPU 的模型
利用本地 AI 的想法
Windows应用可以利用本地 AI 增强其功能和用户体验的几种方法包括:
- 应用 可以使用生成 AI LLM 模型 来了解复杂主题,以汇总、重写、报告或展开。
- 应用 可以使用 LLM 模型 将自由格式的内容转换为应用可以理解的结构化格式。
- 应用 可以使用语义搜索模型 ,允许用户通过含义搜索内容并快速查找相关内容。
- 应用可以使用自然语言处理模型来推理复杂的自然语言要求,并规划和执行作来完成用户的要求。
- 应用可以使用图像作模型智能修改图像、擦除或添加主题、纵向扩展或生成新内容。
- 应用可以使用预测诊断模型来帮助识别和预测问题,并帮助指导用户或为其执行此作。
使用云 AI 模型
如果使用本地 AI 功能并不是正确的路径, 那么使用云 AI 模型和资源 可能是一种解决方案。
使用负责任的 AI 做法
每当在 Windows 应用中采用 AI 功能时,我们强烈建议遵循 在 Windows 上开发负责任的生成式 AI 应用程序和功能的指南。