在本教程的上一阶段中,我们在计算机上安装了 PyTorch。 现在,我们将使用它来设置代码,其中包含用于构建模型的数据。
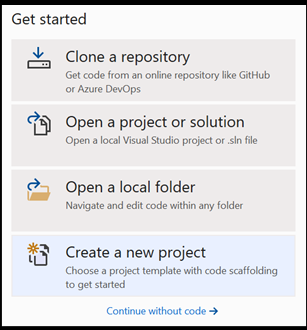
在 Visual Studio 内打开新项目。
- 打开 Visual Studio 并选择
create a new project。
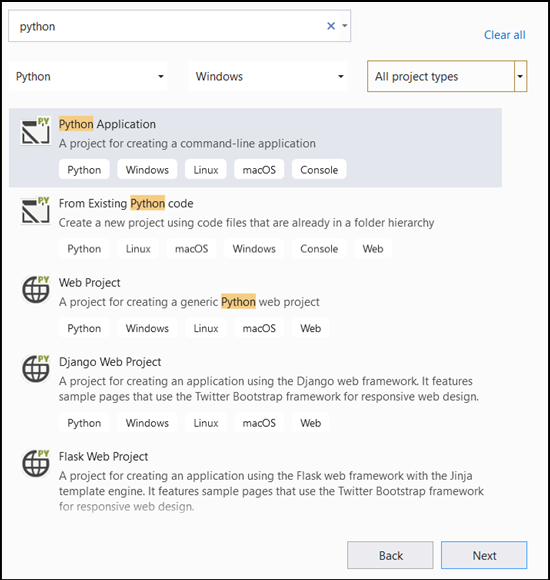
- 在搜索栏中,键入
Python然后选择Python Application作为项目模板。
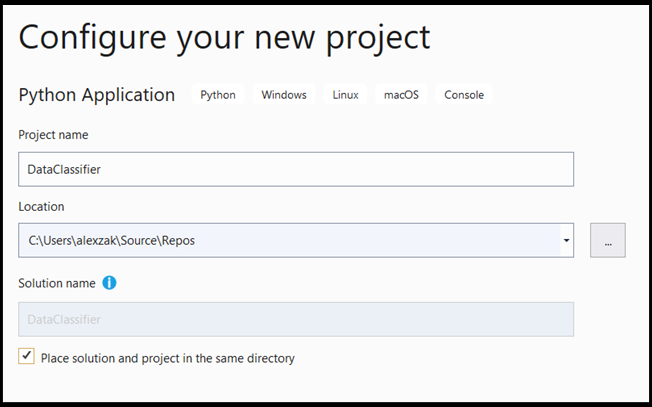
- 在配置窗口中:
- 为项目命名。 在这里,我们称之为 DataClassifier。
- 选择项目的位置。
- 如果使用的是 VS 2019,请确保选中
Create directory for solution。 - 如果使用的是 VS2017,请确保未勾选
Place solution and project in the same directory。
按键 create 创建项目。
创建 Python 解释器
现在,需要定义新的 Python 解释器。 这必须包括最近安装的 PyTorch 包。
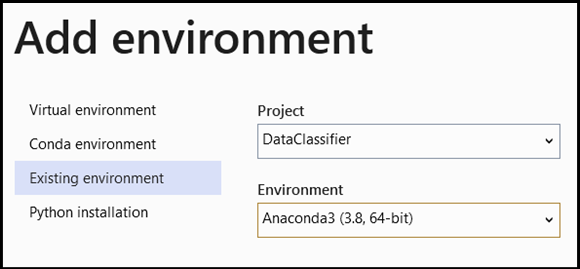
- 导航到解释器选择,然后选择
Add Environment:

- 在
Add Environment窗口中,选择Existing environment,然后选择Anaconda3 (3.6, 64-bit)。 其中包括 PyTorch 包。
若要测试新的 Python 解释器和 PyTorch 包,请在 DataClassifier.py 文件中输入以下代码:
from __future__ import print_function
import torch
x=torch.rand(2, 3)
print(x)
输出应为类似于以下内容的随机 5x3 张量。
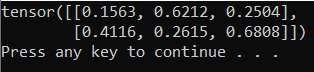
注释
想要了解更多内容? 请访问 PyTorch 官方网站。
了解数据
我们将使用 Fisher 鸢尾花数据集来训练机器学习模型。 鸢尾花有 Iris setosa、Iris virginica 和 Iris versicolor 三个品种,对于每个品种,这个著名的数据集都包含 50 条记录。
已发布多个版本的数据集。 你可在 UCI 机器学习库中找到鸢尾花数据集,直接从 Python Scikit-learn 库导入数据集,或者使用之前发布的任何其他版本。 若要了解鸢尾花数据集,请访问 其维基百科页面。
在本教程中,为了展示如何使用表格类型的输入内容来训练模型,你将使用导出到 Excel 文件的鸢尾花数据集。
Excel 表格的每一行将显示四个虹膜特征:花瓣长度(厘米)、花瓣宽度(厘米)和花瓣宽度(厘米)。这些功能将用作输入。 最后一列包含与这些参数相关的鸢尾花类型,并将表示回归输出。 该数据集对这四个特征总共包含 150 条输入,其中每个输入与相关的鸢尾花类型匹配。
回归分析查看输入变量与结果之间的关系。 根据输入,模型将学习预测正确的输出类型,即三种鸢尾花类型之一:山鸢尾、杂色鸢尾、维吉尼亚鸢尾。
重要
如果决定使用任何其他数据集创建自己的模型,则需要根据方案指定模型输入变量和输出。
加载数据集。
按 Excel 格式下载鸢尾花数据集。 你可以在此处找到它。
DataClassifier.py在解决方案资源管理器文件文件夹中,添加以下导入语句,以获取对我们需要的所有包的访问权限。
import torch
import pandas as pd
import torch.nn as nn
from torch.utils.data import random_split, DataLoader, TensorDataset
import torch.nn.functional as F
import numpy as np
import torch.optim as optim
from torch.optim import Adam
正如你所看到的,你将使用 pandas (Python 数据分析) 包来加载和处理数据,以及包含用于构建神经网络的模块和可扩展类的 torch.nn 包。
- 将数据加载到内存中并验证类数。 我们预计每种鸢尾花类型有 50 个项。 请务必指定电脑上数据集的位置。
将以下代码添加到 DataClassifier.py 文件。
# Loading the Data
df = pd.read_excel(r'C:…\Iris_dataset.xlsx')
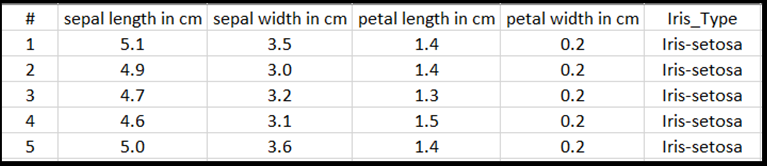
print('Take a look at sample from the dataset:')
print(df.head())
# Let's verify if our data is balanced and what types of species we have
print('\nOur dataset is balanced and has the following values to predict:')
print(df['Iris_Type'].value_counts())
运行此代码时,预期输出如下所示:
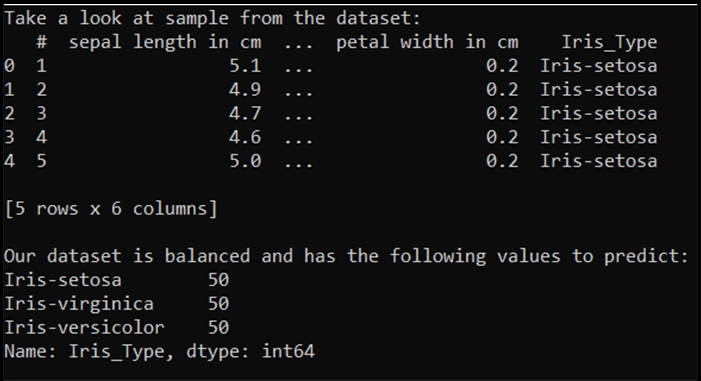
为了能够使用数据集并训练模型,我们需要定义输入和输出。 输入包含 150 行特征,输出是鸢尾花类型列。 我们将使用的神经网络需要数值变量,因此你将输出变量转换为数字格式。
- 在数据集中创建一个新列,该列将以数字格式表示输出,并定义回归输入和输出。
将以下代码添加到 DataClassifier.py 文件。
# Convert Iris species into numeric types: Iris-setosa=0, Iris-versicolor=1, Iris-virginica=2.
labels = {'Iris-setosa':0, 'Iris-versicolor':1, 'Iris-virginica':2}
df['IrisType_num'] = df['Iris_Type'] # Create a new column "IrisType_num"
df.IrisType_num = [labels[item] for item in df.IrisType_num] # Convert the values to numeric ones
# Define input and output datasets
input = df.iloc[:, 1:-2] # We drop the first column and the two last ones.
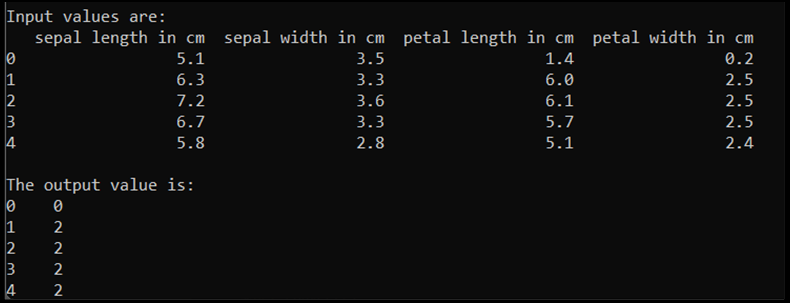
print('\nInput values are:')
print(input.head())
output = df.loc[:, 'IrisType_num'] # Output Y is the last column
print('\nThe output value is:')
print(output.head())
运行此代码时,预期输出如下所示:
若要训练模型,需要将模型输入和输出转换为 Tensor 格式:
- 转换为 Tensor:
将以下代码添加到 DataClassifier.py 文件。
# Convert Input and Output data to Tensors and create a TensorDataset
input = torch.Tensor(input.to_numpy()) # Create tensor of type torch.float32
print('\nInput format: ', input.shape, input.dtype) # Input format: torch.Size([150, 4]) torch.float32
output = torch.tensor(output.to_numpy()) # Create tensor type torch.int64
print('Output format: ', output.shape, output.dtype) # Output format: torch.Size([150]) torch.int64
data = TensorDataset(input, output) # Create a torch.utils.data.TensorDataset object for further data manipulation
如果运行代码,预期输出将显示输入和输出格式,如下所示:

有 150 个输入值。 其中大约 60% 是模型训练数据。 你将保留 20 个% 进行验证,并将 30 个% 用于测试。
在本教程中,训练数据集的批大小定义为 10。 训练集中有 95 个项目,这意味着平均有 9 个完整批次遍历训练集一次(一个周期)。 将验证和测试集的批大小保留为 1。
- 拆分数据以训练、验证和测试集:
将以下代码添加到 DataClassifier.py 文件。
# Split to Train, Validate and Test sets using random_split
train_batch_size = 10
number_rows = len(input) # The size of our dataset or the number of rows in excel table.
test_split = int(number_rows*0.3)
validate_split = int(number_rows*0.2)
train_split = number_rows - test_split - validate_split
train_set, validate_set, test_set = random_split(
data, [train_split, validate_split, test_split])
# Create Dataloader to read the data within batch sizes and put into memory.
train_loader = DataLoader(train_set, batch_size = train_batch_size, shuffle = True)
validate_loader = DataLoader(validate_set, batch_size = 1)
test_loader = DataLoader(test_set, batch_size = 1)
后续步骤
数据准备就绪后,即可训练 PyTorch 模型