分析 Azure AI 搜尋服務中的效能
本文描述在 Azure AI 搜尋服務中分析查詢和編製索引效能的工具、行為和方法。
開發基準編號
在任何大型實作中,請務必先對 Azure AI 搜尋服務執行效能基準測試,再將其合併到生產環境。 您應該測試所預期的搜尋查詢負載,但也應該測試預期的資料擷取工作負載 (盡可能同時執行這兩種負載)。 具有基準測試編號有助於驗證適當的搜尋層、服務設定以及預期的查詢延遲。
若要開發基準測試,建議使用 azure-search-performance-testing (GitHub) 工具。
若要隔離分散式服務架構的效果,請嘗試測試一個複本和一個分割區的服務設定。
注意
對於儲存體最佳化的階層 (L1 和 L2),與標準層相比,您應該預期較低的查詢輸送量和較高的延遲。
使用資源記錄
管理員處置最重要的診斷工具是資源記錄。 資源記錄是有關搜尋服務的作業資料和計量的集合。 資源記錄是透過 Azure 監視器所啟用。 使用 Azure 監視器以及儲存資料有其相關聨成本,但如果您為服務啟用,則調查效能問題時會有所幫助。
下圖顯示查詢要求和回應中的事件鏈結。 無論是在網路傳輸期間,或在處理應用程式服務層中或搜尋服務上的內容期間,其中任何一個可能會有發生延遲的機會。 資源記錄的主要優點是從搜尋服務觀點記錄活動,這表示記錄可協助您判斷效能問題是查詢或編製索引造成,還是某個其他失敗點所造成。
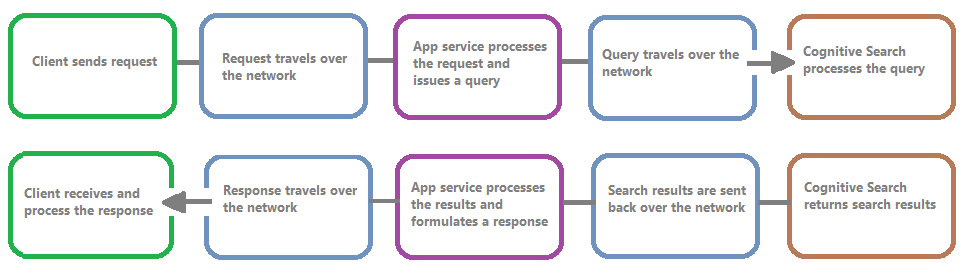
資源記錄可為您提供用於儲存已記錄資訊的選項。 建議使用 Log Analytics,以針對資料執行進階 Kusto 查詢,來回答許多使用和效能問題。
在搜尋服務入口網站頁面上,您可以選擇 [記錄],以透過 [診斷設定] 啟用記錄,然後針對 Log Analytics 發出 Kusto 查詢。 若要了解如何將資源記錄傳送至 Log Analytics 工作區,您可以在其中使用記錄查詢加以分析,請參閱從 Azure 資源收集和分析資源記錄。
節流行為
當搜尋服務達到最大容量時,就會發生節流。 節流可以在查詢或編製索引期間發生。 從用戶端中,API 呼叫會在進行節流時產生 503 HTTP 回應。 在編製索引期間,也可能會收到 207 HTTP 回應,這指出無法編製一或多個項目的索引。 此錯誤是搜尋服務接近容量的指標。
根據經驗法則,請嘗試將節流的數量和任何模式量化。 例如,如果 500,000 個搜尋查詢中有一個受到節流,則可能不值得調查。 不過,如果將查詢的大量百分比節流一段時間,則這需要進一步考量。 查看一段時間的節流,也有助於識別更可能發生節流的時間範圍,並協助您決定如何最恰當地進行節流。
大部分節流問題的簡單修正都是在搜尋服務擲回更多資源 (通常是用於查詢型節流的複本,或用於編製索引型節流的分割區)。 不過,增加複本或分割區會增加成本,因此請務必了解節流發生原因。 接下來幾節將說明調查可造成節流的條件。
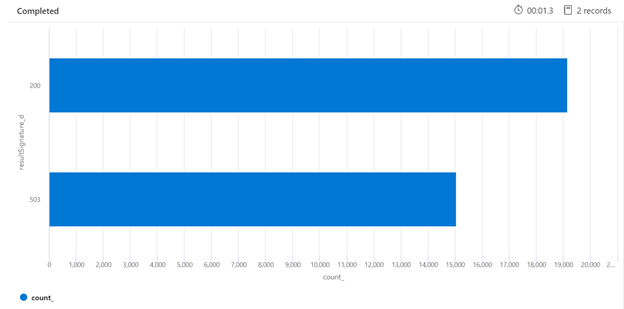
下面是 Kusto 查詢範例,可識別已低於負載之搜尋服務的 HTTP 回應明細。 在 7 天的期間內,與成功回應數目 (200) 相比,轉譯的長條圖顯示已節流相對較大比例的搜尋查詢。
AzureDiagnostics
| where TimeGenerated > ago(7d)
| summarize count() by resultSignature_d
| render barchart
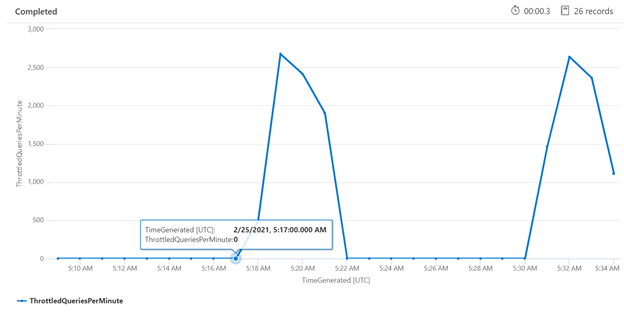
檢查特定時段的節流,可協助您識別可能更頻繁進行節流的時間。 在下面的範例中,使用時間序列圖來顯示在指定時間範圍內發生的已節流查詢數目。 在此情況下,會執行與時間和效能基準相互關聯的已節流查詢。
let ['_startTime']=datetime('2021-02-25T20:45:07Z');
let ['_endTime']=datetime('2021-03-03T20:45:07Z');
let intervalsize = 1m;
AzureDiagnostics
| where TimeGenerated > ago(7d)
| where resultSignature_d != 403 and resultSignature_d != 404 and OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete")
| summarize
ThrottledQueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete") and resultSignature_d == 503)/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
測量個別查詢
在某些情況下,測試個別查詢來查看其執行方式十分有用。 若要這樣做,請務必了解搜尋服務完成工作所需的時間,以及用戶端提出往返要求且送回用戶端所需的時間。 診斷記錄可以用來查閱個別作業,但透過 REST 用戶端執行此作業可能較為簡單。
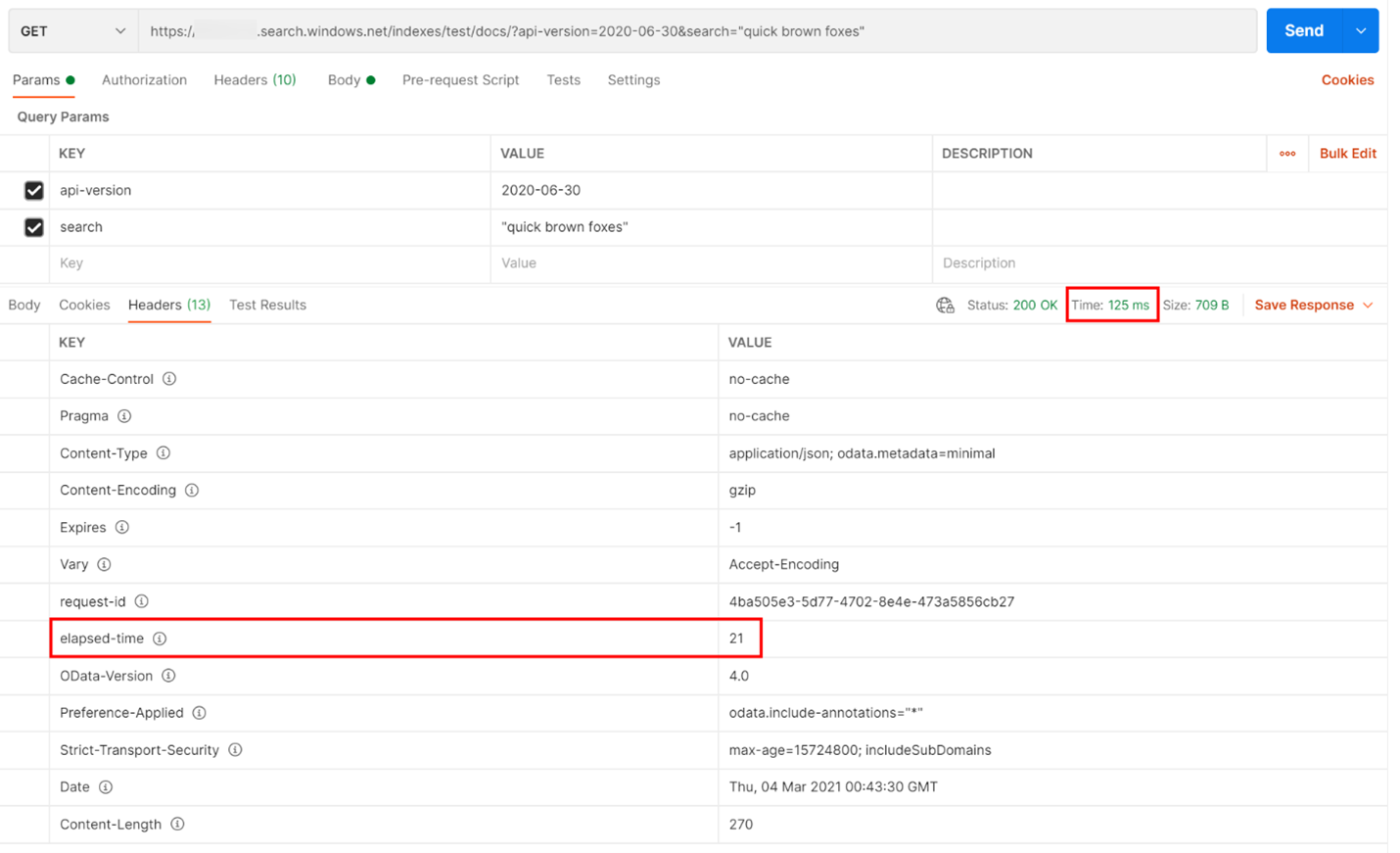
在下面的範例中,已執行 REST 型搜尋查詢。 Azure AI 搜尋服務會在每個回應中包括完成查詢所需的毫秒數,而這會顯示在 [標頭] 索引標籤的 [經過時間] 中。 在回應頂端的 [狀態] 旁邊,您會發現往返持續時間,在本案例中為 418 毫秒 (ms)。 在 [結果] 區段中,已選擇 [標頭] 索引標籤。 使用下圖中這兩個以紅色方塊醒目提示的值,我們會看到搜尋服務花 21 毫秒的時間來完成搜尋查詢,而整個用戶端往返要求則花 125 毫秒的時間。 將這兩個數字相減,即可判斷需要 104 毫秒的額外時間將搜尋查詢傳輸至搜尋服務,並將搜尋結果傳輸回用戶端。
這項技術可協助您將網路延遲與影響查詢效能的其他因素隔離。
查詢速率
您搜尋服務可節流要求的其中一個潛在原因是執行大量查詢所造成,其中會依每秒查詢數 (QPS) 或每分鐘查詢數 (QPM) 來擷取磁碟區。 當您的搜尋服務收到更多 QPS 時,通常需要較長的時間來回應這些查詢,直到無法再繼續,因為其將傳回節流 503 HTTP 回應。
下列 Kusto 查詢會顯示以 QPM 為單位測量的查詢磁碟區,以及以毫秒為單位的平均查詢持續時間 (AvgDurationMS),以及每個查詢中所傳回的平均文件數目 (AvgDocCountReturned)。
AzureDiagnostics
| where OperationName == "Query.Search" and TimeGenerated > ago(1d)
| extend MinuteOfDay = substring(TimeGenerated, 0, 16)
| project MinuteOfDay, DurationMs, Documents_d, IndexName_s
| summarize QPM=count(), AvgDuractionMs=avg(DurationMs), AvgDocCountReturned=avg(Documents_d) by MinuteOfDay
| order by MinuteOfDay desc
| render timechart
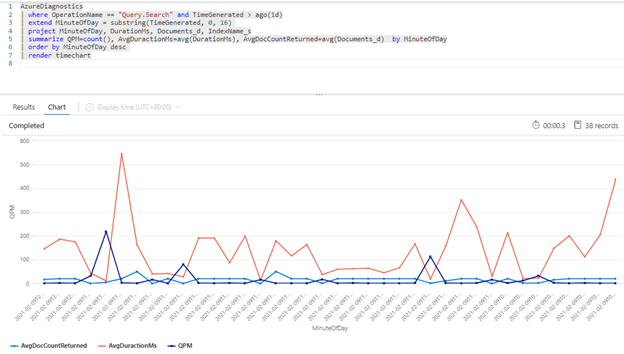
提示
若要顯示此圖表背後的資料,請移除 | render timechart 行,然後重新執行查詢。
編製索引對查詢的影響
查看效能時考慮的重要因素是編製索引使用與搜尋查詢相同的資源。 如果您要編製大量內容的索引,則在服務嘗試容納這兩個工作負載時,可能預期會看到延遲成長。
如果查詢速度變慢,則請查看索引編製活動的時機,以查看其是否與查詢降低一致。 例如,索引子可能正在執行每日或每小時作業,而此作業與搜尋查詢的效能降低相互關聯。
本節提供一組查詢,可協助您視覺化搜尋和編製索引速率。 在這些範例中,是在查詢中設定時間範圍。 在 Azure 入口網站中執行查詢時,請務必指出 [在查詢中設定]。
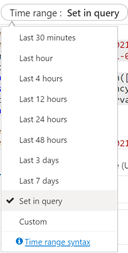
平均查詢延遲
在下面的查詢中,使用間隔大小 1 分鐘來顯示搜尋查詢的平均延遲。 從圖表中,我們可以看到平均延遲在下午 5:45 之前很低,並持續到下午 5:53。
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime']..['_endTime']) // Time range filtering
| summarize AverageQueryLatency = avgif(DurationMs, OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))
by bin(TimeGenerated, intervalsize)
| render timechart
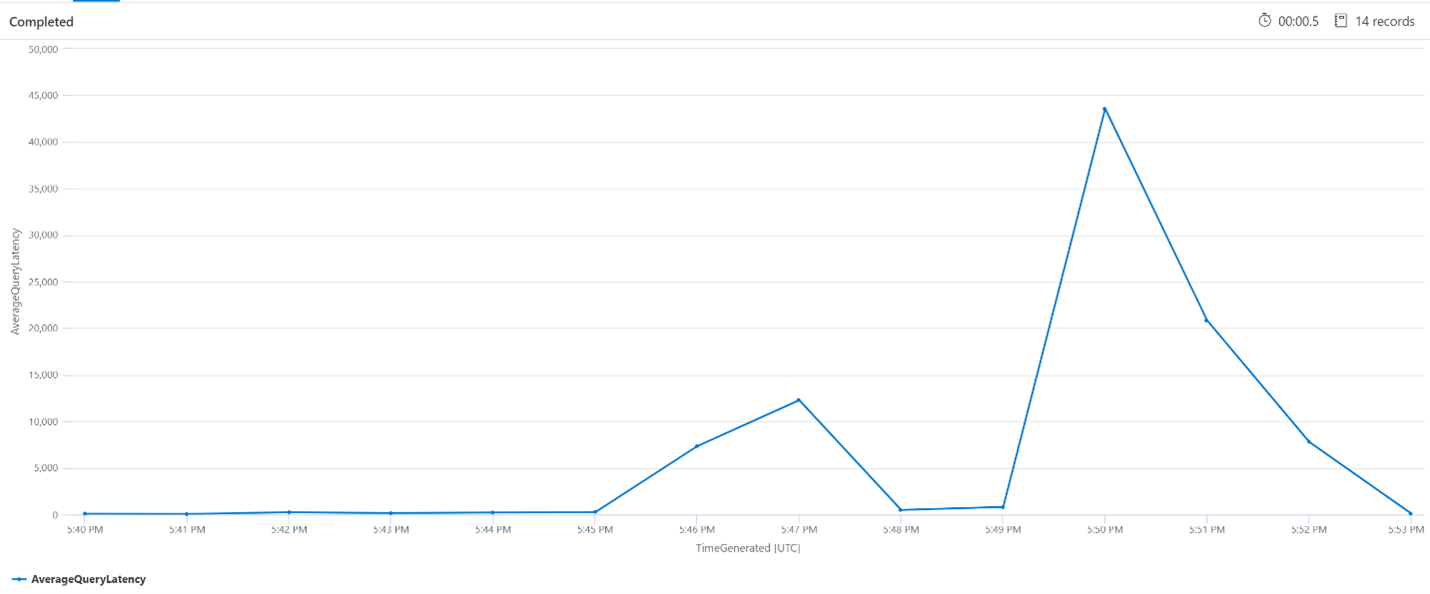
每分鐘平均查詢 (QPM)
下列查詢可查看每分鐘的平均查詢數,以確保搜尋要求中沒有某種可能已影響延遲的尖峰。 從圖表中,我們可以看到有某個差異,但沒有任何跡象指出要求計數的尖峰。
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize QueriesPerMinute=bin(countif(OperationName in ("Query.Search", "Query.Suggest", "Query.Lookup", "Query.Autocomplete"))/(intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
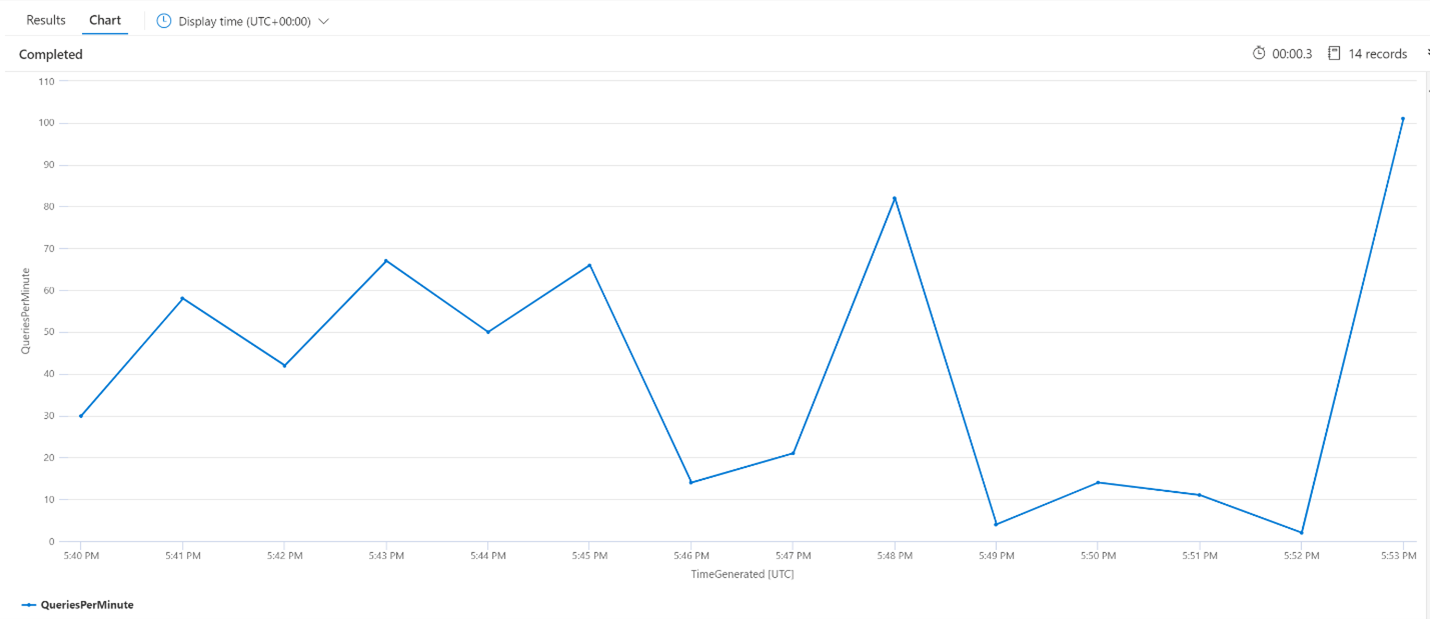
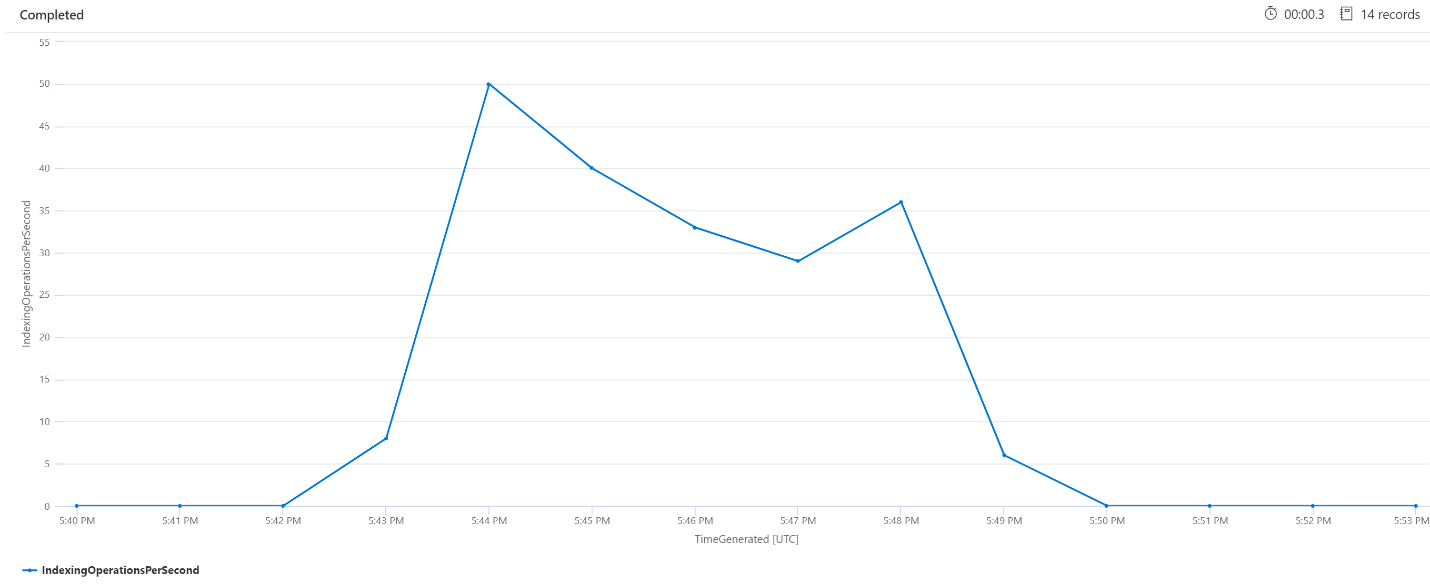
每分鐘編制索引作業 (OPM)
在這裡,我們將查看每分鐘的編製索引作業數目。 從圖表中,我們可以看到已在下午 5:42 開始編製大量資料的索引,並在下午 5:50 結束。 此編製索引已在搜尋查詢開始變成延遲之前的 3 分鐘開始,並在搜尋查詢不再延遲之前的 3 分鐘結束。
從這個深入解析中,我們可以看到搜尋服務大約需要 3 分鐘的時間才會變得忙碌,導致編製索引影響查詢延遲。 我們也可以看到在編製索引完成之後,搜尋服務需要另外 3 分鐘的時間才能完成新編製索引內容的所有工作,並解決查詢延遲。
let intervalsize = 1m;
let _startTime = datetime('2021-02-23 17:40');
let _endTime = datetime('2021-02-23 18:00');
AzureDiagnostics
| where TimeGenerated between(['_startTime'] .. ['_endTime']) // Time range filtering
| summarize IndexingOperationsPerSecond=bin(countif(OperationName == "Indexing.Index")/ (intervalsize/1m), 0.01)
by bin(TimeGenerated, intervalsize)
| render timechart
背景服務處理
查詢或編製索引延遲出現週期性尖峰並不罕見。 尖峰可能會因應編製索引或高查詢速率而發生,但也可能會在合併作業期間發生。 搜尋索引會以區塊或分區形式儲存。 系統會定期將較小的分區合併成大型分區,以協助將服務效能最佳化。 此合併程序也會清除先前標示為要從索引中刪除的文件,進而復原儲存體空間。
合併分區的速度很快,但也需要大量資源,因此可能會降低服務效能。 如果您看到查詢延遲有短暫高載,而且這些高載與最近已編製索引內容的變更一致,則可以假設該延遲是分區合併作業所造成。
下一步
請檢閱這些與服務效能分析相關的文章。