微服務之間的通訊必須有效率且健全。 透過許多與小型服務互動以完成單一商務活動,這可以是一項挑戰。 在本文中,我們將探討異步傳訊與同步 API 之間的取捨。 然後,我們探討設計彈性服務間通訊的一些挑戰。
以下是服務對服務通訊所產生的一些主要挑戰。 本文稍後所述的服務網格是設計來處理許多這些挑戰。
復原功能。 任何指定的微服務可能會有數十個甚至數百個實例。 實例可能會因為任何原因而失敗。 節點層級可能會失敗,例如硬體故障或 VM 重新啟動。 實例可能會當機,或因要求而無法處理任何新要求而不知所措。 上述任何事件都可能導致網路呼叫失敗。 有兩種設計模式可協助讓服務對服務網路呼叫更具彈性:
重試。 網路呼叫可能會失敗,因為暫時性錯誤會自行消失。 呼叫端通常應該重試作業一定次數,或直到設定逾時期間經過為止。 不過,如果作業不是等冪的,重試可能會導致非預期的副作用。 原始呼叫可能會成功,但呼叫端永遠不會取得回應。 如果呼叫端重試,可能會叫用作業兩次。 一般而言,重試 POST 或 PATCH 方法並不安全,因為這些方法不保證具有等冪性。
斷路器。 太多失敗的要求可能會導致瓶頸,因為擱置的要求會累積在佇列中。 這些封鎖的要求可能會保存重要的系統資源,例如記憶體、線程、資料庫連線等等,這可能會導致串聯失敗。 斷路器模式可以防止服務重複嘗試可能失敗的作業。
負載平衡。 當服務 「A」 呼叫服務 「B」 時,要求必須到達服務 「B」 的執行中實例。 在 Kubernetes 中 Service ,資源類型會為一組 Pod 提供穩定的 IP 位址。 透過iptable規則,將服務IP位址的網路流量轉送至Pod。 根據預設,會選擇隨機 Pod。 服務網格(如下所示)可以根據觀察到的延遲或其他計量,提供更智慧的負載平衡演算法。
分散式追蹤。 單一交易可能會跨越多個服務。 這會使難以監視系統的整體效能和健康情況。 即使每個服務都會產生記錄和計量,而不需要某種方式將它們系結在一起,它們仍會受到限制。
服務版本控制。 當小組部署新版本的服務時,他們必須避免中斷相依於服務的任何其他服務或外部用戶端。 此外,您可能想要並行執行多個版本的服務,並將要求路由傳送至特定版本。 如需此問題的詳細資訊,請參閱 API 版本控制 。
TLS 加密和相互 TLS 驗證。 基於安全性考慮,您可能想要使用 TLS 加密服務之間的流量,並使用相互 TLS 驗證來驗證呼叫端。
微服務可用來與其他微服務通訊的基本傳訊模式有兩種。
同步通訊。 在此模式中,服務會使用 HTTP 或 gRPC 等通訊協定呼叫另一個服務公開的 API。 此選項是同步傳訊模式,因為呼叫端會等候接收者的回應。
異步訊息傳遞。 在此模式中,服務會傳送訊息而不等待回應,而一或多個服務會以異步方式處理訊息。
請務必區分異步 I/O 和異步通訊協定。 異步 I/O 表示在 I/O 完成時,不會封鎖呼叫線程。 這對於效能很重要,但對於架構而言是實作詳細數據。 異步通訊協定表示傳送者不會等候回應。 HTTP 是同步通訊協定,即使 HTTP 用戶端在傳送要求時可能會使用異步 I/O。
每個模式都有取捨。 要求/回應是瞭解良好的範例,因此設計 API 可能比設計傳訊系統更自然。 不過,異步傳訊在微服務架構中具有一些優點:
減少結合。 訊息傳送者不需要知道取用者。
多個訂閱者。 使用 pub/sub 模型,多個取用者可以訂閱接收事件。 請參閱 事件驅動架構樣式。
失敗隔離。 如果取用者失敗,寄件者仍然可以傳送訊息。 取用者復原時,將會挑選訊息。 這項功能在微服務架構中特別有用,因為每個服務都有自己的生命週期。 服務可能會在任何指定時間變成無法使用或取代為較新版本。 異步傳訊可以處理間歇性的停機時間。 另一方面,同步 API 要求下游服務可供使用,或作業失敗。
回應性。 如果上游服務未等候下游服務,則其回復速度會更快。 這在微服務架構中特別有用。 如果有服務相依性鏈結(服務 A 呼叫 B、呼叫 C 等等),等候同步呼叫可能會增加無法接受的延遲量。
負載撫平。 佇列可以做為緩衝區來撫平工作負載,讓接收者可以自行處理訊息。
工作流程。 佇列可用來管理工作流程,方法是檢查工作流程中的每個步驟之後的訊息。
不過,使用異步傳訊也有一些挑戰。
結合傳訊基礎結構。 使用特定傳訊基礎結構可能會導致與該基礎結構緊密結合。 稍後將很難切換到另一個傳訊基礎結構。
延遲。 如果消息佇列填滿,作業的端對端延遲可能會變得很高。
成本。 在高輸送量時,傳訊基礎結構的貨幣成本可能相當重要。
複雜度。 處理異步傳訊不是簡單的工作。 例如,您必須藉由取消複製或讓作業等冪處理重複的訊息。 使用異步傳訊實作要求-回應語意也很難。 若要傳送回應,您需要另一個佇列,以及將要求和回應訊息相互關聯的方式。
輸送量。 如果訊息需要 佇列語意,佇列可能會成為系統中的瓶頸。 每個訊息至少需要一個佇列作業和一個清除佇列作業。 此外,佇列語意通常需要在傳訊基礎結構內進行某種鎖定。 如果佇列是受控服務,可能會有額外的延遲,因為佇列位於叢集虛擬網路外部。 您可以藉由批處理訊息來減輕這些問題,但這會使程式代碼複雜。 如果訊息不需要佇列語意,您可能可以使用事件 數據流 ,而不是佇列。 如需詳細資訊,請參閱 事件驅動架構樣式。
此解決方案使用無人機遞送範例。 它非常適合航空航太和飛機工業。
考慮到這些考慮,開發小組針對無人機遞送應用程式做了下列設計選擇:
擷取服務會公開用戶端應用程式用來排程、更新或取消傳遞的公用 REST API。
擷取服務會使用事件中樞將異步訊息傳送至排程器服務。 異步訊息是必要的,才能實作擷取所需的負載撫平。
帳戶、傳遞、套件、無人機和第三方傳輸服務都會公開內部 REST API。 排程器服務會呼叫這些 API 來執行使用者要求。 使用同步 API 的其中一個原因是排程器需要從每個下游服務取得回應。 任何下游服務的失敗表示整個作業都失敗。 不過,潛在的問題是呼叫後端服務所導入的延遲量。
如果有任何下游服務發生非交易失敗,則整個交易應該標示為失敗。 為了處理此情況,排程器服務會將異步訊息傳送給監督員,讓監督員可以排程補償交易。
傳遞服務會公開公用 API,用戶端可用來取得傳遞的狀態。 在 API 閘道一文 中,我們會討論 API 閘道如何隱藏客戶端的基礎服務,因此用戶端不需要知道哪些服務會公開哪些 API。
無人機在飛行時,無人機服務會傳送事件,其中包含無人機的目前位置和狀態。 傳遞服務會接聽這些事件,以追蹤傳遞的狀態。
當傳遞狀態變更時,傳遞服務會傳送傳遞狀態事件,例如
DeliveryCreated或DeliveryCompleted。 任何服務都可以訂閱這些事件。 在目前的設計中,「傳遞歷程記錄」服務是唯一的訂閱者,但稍後可能會有其他訂閱者。 例如,事件可能會移至即時分析服務。 而且,由於排程器不需要等候回應,因此新增更多訂閱者不會影響主要工作流程路徑。
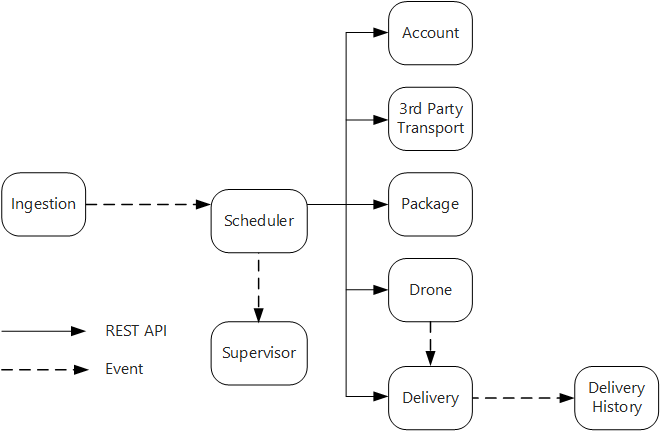
請注意,傳遞狀態事件衍生自無人機位置事件。 例如,當無人機到達遞送位置並卸除包裹時,傳遞服務會將此轉譯為 DeliveryCompleted 事件。 這是在領域模型方面思考的範例。 如先前所述,無人機管理屬於不同的限定內容。 無人機事件會傳達無人機的實體位置。 另一方面,傳遞事件代表傳遞狀態的變更,這是不同的商務實體。
服務網格是處理服務對服務通訊的軟體層。 服務網格的設計訴求是解決上一節所列的許多考慮,並將這些考慮的責任移出微服務本身和共用層。 服務網格可作為 Proxy,以攔截叢集中微服務之間的網路通訊。 目前,服務網格概念主要適用於容器協調器,而不是無伺服器架構。
注意
服務網格是大使模式的範例, 協助程式服務會代表應用程式傳送網路要求。
現在,Kubernetes 中服務網格的主要選項是 Linkerd 和 Istio。 這兩種技術都在迅速發展。 不過,Linkerd 和 Istio 有一些共同的功能包括:
會話層級的負載平衡,根據觀察到的延遲或未完成的要求數目。 這可以改善 Kubernetes 所提供之第 4 層負載平衡的效能。
以 URL 路徑、主機標頭、API 版本或其他應用層級規則為基礎的第 7 層路由。
重試失敗的要求。 服務網格瞭解 HTTP 錯誤碼,並可自動重試失敗的要求。 您可以設定重試次數上限,以及逾時期間,以系結最大延遲。
斷路器。 如果實例一致失敗要求,服務網格會暫時將其標示為無法使用。 在輪詢期間之後,它會再次嘗試實例。 您可以根據各種準則來設定斷路器,例如連續失敗次數。
服務網格會擷取有關服務間呼叫的計量,例如要求磁碟區、延遲、錯誤和成功率,以及回應大小。 服務網格也會藉由在要求中為每個躍點新增相互關聯資訊,來啟用分散式追蹤。
服務對服務呼叫的相互 TLS 驗證。
您需要服務網格嗎? 要看情況而定。 如果沒有服務網格,您必須考慮本文開頭所述的每個挑戰。 您可以解決沒有服務網格的重試、斷路器和分散式追蹤等問題,但服務網狀結構會將這些考慮從個別服務移出,並進入專用層。 另一方面,服務網狀結構會增加叢集設定和組態的複雜性。 效能可能會造成影響,因為要求現在會透過服務網格 Proxy 路由傳送,而且因為額外的服務現在會在叢集中的每個節點上執行。 在生產環境中部署服務網格之前,您應該先進行徹底的效能和負載測試。
微服務中常見的挑戰是正確處理跨越多個服務的交易。 通常在此案例中,交易的成功是全部或根本沒有的,如果其中一個參與的服務失敗,則整個交易必須失敗。
有兩種情況需要考慮:
服務可能會遇到 暫時性 失敗,例如網路逾時。 只要重試呼叫,即可解決這些錯誤。 如果作業在一定數目的嘗試之後仍然失敗,它就會被視為非轉移失敗。
非轉移失敗是任何不太可能自行消失的失敗。 非轉譯失敗包括一般錯誤狀況,例如無效的輸入。 它們也會在應用程式程式代碼或行程當機中包含未處理的例外狀況。 如果發生這種類型的錯誤,整個商務交易必須標示為失敗。 可能需要復原相同交易中已經成功的其他步驟。
在非交易失敗之後,目前的交易可能處於 部分失敗 狀態,其中一或多個步驟已順利完成。 例如,如果無人機服務已經排程無人機,則必須取消無人機。 在此情況下,應用程式必須使用補償交易來復原成功的步驟。 在某些情況下,此動作必須由外部系統或甚至是手動程式來完成。 在您的設計中,請記住補償量值也會受限於失敗。
如果補償交易的邏輯很複雜,請考慮建立負責此程式的個別服務。 在無人機遞送應用程式中,排程器服務會將失敗的作業放入專用佇列。 名為「監督員」的個別微服務會從此佇列讀取,並在需要補償的服務上呼叫取消 API。 這是排程器代理程式監督員模式的變化。 監督員服務也可以採取其他動作,例如透過文字或電子郵件通知使用者,或將警示傳送至作業儀錶板。
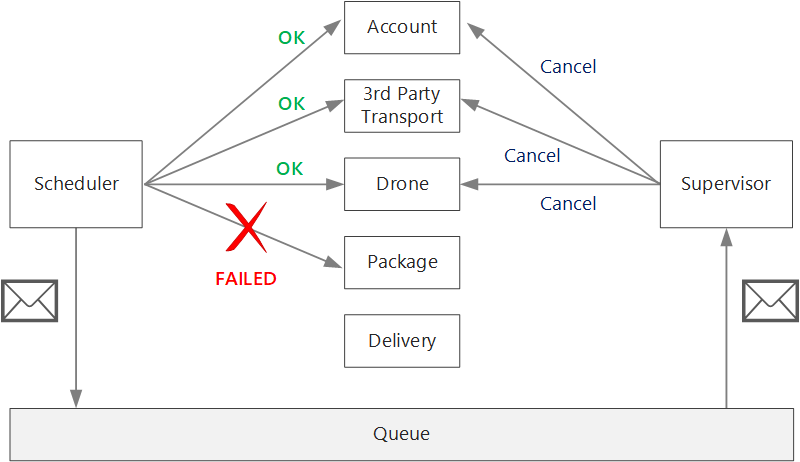
排程器服務本身可能會失敗(例如,因為節點當機)。 在此情況下,新的實例可以啟動並接管。 不過,必須繼續任何進行中的交易。
其中一種方法是在工作流程中的每個步驟完成之後,將檢查點儲存至永久性存放區。 如果排程器服務的實例在交易中間當機,新的實例可以使用檢查點繼續前一個實例離開的位置。 不過,撰寫檢查點可能會造成效能額外負荷。
另一個選項是將所有作業設計為等冪。 如果可以多次呼叫作業,而不在第一次呼叫之後產生額外的副作用,則作業是等冪的。 基本上,下游服務應該忽略重複的呼叫,這表示服務必須能夠偵測重複的呼叫。 實作等冪方法並不總是直接的。 如需詳細資訊,請參閱 等冪作業。
對於直接與彼此交談的微服務,請務必建立設計良好的 API。