Azure SQL 資料庫的無伺服器計算階層
適用於: ![]() Azure SQL 資料庫
Azure SQL 資料庫
無伺服器是適用於 Azure SQL Database 中單一資料庫的計算層,可根據工作負載需求自動擴縮計算,並以每秒使用的計算量來計費。 無伺服器計算層也會在只有儲存體仍在計費的資料庫非使用中期間自動暫停資料庫,並在有活動傳回時自動繼續執行資料庫。 無伺服器計算層在一般用途服務層級和超大規模資料庫服務層級中提供。
注意
一般用途服務層級目前只支援自動暫停和自動繼續。
概觀
計算自動調整範圍和自動暫停延遲是無伺服器計算層的重要參數。 這些參數的設定會形成資料庫的效能體驗和計算成本。
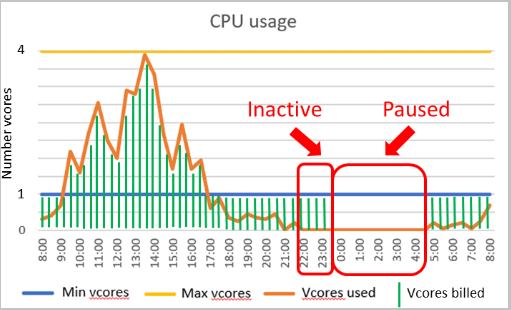
效能設定
- minimum vCores 和 maximum vCores 均為可設定的參數,其定義資料庫可用計算容量的範圍。 記憶體和 IO 限制會與指定的虛擬核心範圍成比例。
- 自動暫停延遲是可設定的參數,其定義資料庫在自動暫停前必須處於非使用中的時間期間。 資料庫會在下一個登入或其他活動發生時自動繼續。 或者,您也可以停用自動暫停。
成本
- 無伺服器資料庫的成本總計為計算成本和儲存體成本的加總。
- 當計算使用量介於所設定的下限和上限之間時,計算成本會以所使用的虛擬核心和記憶體為基礎。
- 當計算使用量低於所設定的下限時,計算成本會以所設定的最小虛擬核心和最小記憶體為基礎。
- 當資料庫暫停時,計算成本為零,而且只會產生儲存體成本。
- 儲存體成本的決定方式與已佈建的計算層相同。
如需更多的成本詳細資料,請參閱計費。
案例
無伺服器的性價針對採用間歇性、無法預測使用模式的單一資料庫最佳化,這些資料庫可接受在閒置使用期間之後,計算準備有些延遲。 相反地,已佈建計算層的性價已針對平均使用量較高的單一資料庫或彈性集區中的多個資料庫最佳化,這些資料庫無法接受計算準備有任何延遲。
適合用於無伺服器計算的案例
- 具有間歇性、無法預測使用模式的單一資料庫,其有一段時間的非使用狀態和較低的平均計算使用率。
- 已佈建計算層中的單一資料庫,經常重新調整,而客戶想要將計算重新調整委派給服務。
- 不使用記錄的新單一資料庫,在 Azure SQL 資料庫中部署之前很難計算或無法估計大小。
適合用於佈建計算的案例
- 具有更穩定、可預測使用模式的單一資料庫,且有一段時間內的平均計算使用率較高。
- 無法容忍以下情況造成效能妥協的資料庫:經常修剪記憶體或從暫停狀態繼續以致延遲。
- 採用間歇性、無法預測使用模式的多個資料庫,其可合併成彈性集區以獲得更好的性價比最佳化。
比較計算層
下表摘要說明無伺服器計算層級與佈建計算層級之間的差異:
| 無伺服器計算 | 佈建計算 | |
|---|---|---|
| 資料庫使用模式 | 間歇性、無法預測的使用量,且一段時間內的平均計算使用率較低。 | 更穩定的使用模式,且一段時間內的平均計算使用率較高,或是多個使用彈性集區的資料庫。 |
| 效能管理投入量 | 較低 | 較高 |
| 計算調整 | 自動 | 手動 |
| 計算回應性 | 在非使用期間後降低 | 立即 |
| 計費細微度 | 每秒 | 每小時 |
購買模型和服務層級
下表說明根據購買模型、服務層級和硬體的無伺服器支援:
| 類別 | 支援 | 不支援 |
|---|---|---|
| 購買模型 | 虛擬核心 | DTU |
| 服務層級 | 一般用途 超大規模資料庫 |
業務關鍵 |
| 硬體 | 標準系列 (Gen5) | 所有其他硬體 |
自動調整規模
調整回應性
無伺服器資料庫會在具有足夠容量的機器上執行,以滿足資源需求,而不會中斷在最大虛擬核心值所設定限制內要求的任何計算數量。 有時候,如果電腦無法在幾分鐘內滿足資源需求,負載平衡就會自動發生。 例如,如果資源需求為 4 個虛擬核心,但只有 2 個虛擬核心可供使用,則可能需要幾分鐘的時間來進行負載平衡,然後才能提供 4 個虛擬核心。 捨棄連線後,除了在作業結束時的短暫期間,資料庫都會在負載平衡期間保持線上狀態。
記憶體管理
在一般用途和超大規模資料庫服務層級中,無伺服器資料庫的記憶體回收會比已佈建的計算資料庫還要頻繁。 這種行為對於控制無伺服器的成本很重要,而且可能會影響效能。
快取回收
不同於已佈建的計算資料庫,當 CPU 或主動快取使用率很低時,就會從無伺服器資料庫回收 SQL 快取中的記憶體。
- 當最近使用的主動快取項目總大小低於閾值一段時間時,系統就會認為快取使用率偏低。
- 快取回收程序觸發時,目標快取大小會以累加方式縮減為其先前大小的一小部分,而且只有在使用量還是偏低時,才會繼續進行回收。
- 當快取回收程序發生時,用於選取所要收回快取項目的原則,與記憶體壓力偏高時已佈建的計算資料庫所用的選取原則相同。
- 快取大小永遠不會減到低於最小虛擬核心所定義的最小記憶體限制。
無論是在無伺服器還是已佈建的計算資料庫中,如果使用了所有可用記憶體,快取項目便可能遭到收回。
當 CPU 使用率偏低時,主動快取使用率可能會根據使用模式而維持很高,並防止記憶體回收。 此外,在進行記憶體回收之前,使用者活動停止後可能會有其他延遲,因為定期背景程序會回應先前的使用者活動。 例如,刪除作業和查詢存放區清除工作會產生標示為要刪除的准刪除記錄,但在准刪除清除程序執行之前,不會實際刪除。 準刪除清除可能牽涉到將資料頁面讀入快取中。
快取序列化
SQL 記憶體快取會在從磁碟中擷取資料時隨之成長,而且方式和速度都與已佈建的資料庫相同。 資料庫忙碌時,如果有可用的記憶體,則快取可以不受限制地成長。
磁碟快取管理
在無伺服器和已佈建計算層的超大規模資料庫服務層級中,每個計算複本都會使用復原緩衝集區延伸模組 (RBPEX) 快取,以在本機 SSD 上儲存資料分頁來改善 IO 效能。 不過,在超大規模資料庫的無伺服器計算層中,每個計算複本的 RBPEX 快取都會自動成長和縮減,以回應增加和減少的工作負載需求。 RBPEX 快取可成長的大小上限是針對資料庫所設定記憶體上限的三倍。 如需無伺服器中記憶體上限和 RBPEX 自動調整限制的詳細資料,請參閱無伺服器超大規模資料庫資源限制。
自動暫停與自動繼續
目前,一般用途層只支援無伺服器自動暫停和自動繼續。
自動暫停
如果下列條件在自動暫停延遲期間全部成立,就會觸發自動暫停:
- 工作階段數 = 0
- CPU = 0 適用於在使用者資源集區中執行的使用者工作負載
已提供視需要停用自動暫停的選項。
下列功能不支援自動暫停,但支援自動縮放比例。 如果使用下列任何一項功能,則必須停用自動暫停,而且不論資料庫閒置的持續時間,資料庫都將維持在線上狀態:
- 異地複寫 (主動式異地複寫和容錯移轉群組)。
- 長期備份保留 (LTR)。
- SQL 資料同步中使用的同步資料庫。與同步資料庫不同,中樞和成員資料庫支援自動暫停。
- 為包含無伺服器資料庫的邏輯伺服器建立的 DNS 別名。
- 彈性工作,不支援已啟用自動暫停的無伺服器資料庫作為工作資料庫。 彈性工作所鎖定的無伺服器資料庫支援自動暫停。 工作連線將會繼續執行資料庫。
在部署某些需要資料庫已上線的服務更新時,會暫時禁止自動暫停。 在這種情況下,當服務更新完成後,就會再次允許自動暫停。
自動暫停疑難排解
如果已啟用自動暫停且未使用可封鎖自動暫停的功能,但資料庫在延遲期間後未自動暫停,則應用程式或使用者工作階段可能在禁止自動暫停。
若要查看目前是否有任何應用程式或使用者工作階段連線到資料庫,請使用任何用戶端工具連線到資料庫,然後執行下列查詢:
SELECT session_id,
host_name,
program_name,
client_interface_name,
login_name,
status,
login_time,
last_request_start_time,
last_request_end_time
FROM sys.dm_exec_sessions AS s
INNER JOIN sys.dm_resource_governor_workload_groups AS wg
ON s.group_id = wg.group_id
WHERE s.session_id <> @@SPID
AND
(
(
wg.name like 'UserPrimaryGroup.DB%'
AND
TRY_CAST(RIGHT(wg.name, LEN(wg.name) - LEN('UserPrimaryGroup.DB') - 2) AS int) = DB_ID()
)
OR
wg.name = 'DACGroup'
);
提示
執行查詢之後,請務必中斷與資料庫的連線。 否則,查詢所使用的開啟工作階段將會防止自動暫停。
- 如果結果集不是空白的,則表示目前有工作階段阻礙自動暫停。
- 如果結果集是空白的,則仍有可能工作階段已開啟,時間可能很短,在自動暫停延遲期間的某個時間點之前。 若要查看延遲期間的活動,您可以使用 Azure SQL 稽核,並檢查相關期間的稽核資料。
重要
如果無伺服器資料庫無法如預期般自動暫停,最常見的原因是有開啟的工作階段 (不論在使用者資源集區中是否有並行使用 CPU)。
自動繼續
如果下列任一條件在任何時候成立,就會觸發自動繼續:
| 功能 | 自動繼續觸發程序 |
|---|---|
| 驗證和授權 | 登入 |
| 威脅偵測 | 啟用/停用資料庫或伺服器層級的威脅偵測設定。 修改資料庫或伺服器層級的威脅偵測設定。 |
| 資料探索與分類 | 新增、修改、刪除或檢視敏感度標籤 |
| 稽核 | 檢視稽核記錄。 更新或檢視稽核原則。 |
| 資料遮罩 | 新增、修改、刪除或檢視資料遮罩處理規則 |
| 透明資料加密 | 檢視透明資料加密的狀態 |
| 弱點評估 | 特定掃描和定期掃描 (如果已啟用) |
| 查詢 (效能) 資料存放區 | 修改或檢視查詢存放區設定 |
| 效能建議 | 檢視或套用效能建議 |
| 自動微調 | 自動微調建議的應用和驗證,例如自動編製索引 |
| 資料庫複製 | 建立資料庫作為複本。 匯出至 BACPAC 檔案。 |
| SQL 資料同步 | 按照可設定的排程執行或定期執行中樞與成員資料庫之間的同步 |
| 修改特定資料庫中繼資料 | 新增資料庫標籤。 變更最大虛擬核心數、最小虛擬核心數或自動暫停延遲。 |
| SQL Server Management Studio (SSMS) | 使用 18.1 版之前的 SSMS 並針對伺服器中的任何資料庫開啟新的查詢時段時,相同伺服器中任何自動暫停的資料庫會繼續執行。 如果使用 SSMS 18.1 版或更新版本,則不會發生此行為。 |
執行以上所列作業的監視、管理或其他解決方案都會觸發自動繼續。 在部署某些需要資料庫已上線的服務更新時,也會觸發自動繼續。
連線能力
如果無伺服器的資料庫已暫停,則第一個連線嘗試會繼續執行資料庫並傳回錯誤 (錯誤碼 40613),指出該資料庫無法使用。 資料庫繼續執行後,可以重試登入,建立連線。 遵循連線重試邏輯建議的資料庫用戶端應該不需要修改。 有關連線重試邏輯選項和建議的資訊,請參閱:
- SqlClient 中的連線重試邏輯
- SQL Database 中使用 Entity Framework Core 的連線重試邏輯
- SQL Database 中使用 Entity Framework 6 的連線重試邏輯
- SQL Database 中使用 ADO.NET 的連線重試邏輯
Latency
自動繼續和自動暫停無伺服器資料庫的延遲,一般順序大約是 1 分鐘後自動繼續,以及在延遲期間到期 1 到 10 分鐘後自動暫停。
客戶管理的透明資料加密 (BYOK)
金鑰刪除或撤銷
如果使用客戶管理的透明資料加密 (BYOK),而且無伺服器資料庫會在金鑰刪除或撤銷發生時自動暫停,則資料庫會保持在自動暫停狀態。 在此情況下,下次繼續資料庫之後,資料庫會在大約 10 分鐘內變成無法存取。 一旦資料庫變成無法存取,復原程序就與已佈建的計算資料庫相同。 如果在發生金鑰刪除或撤銷時,無伺服器資料庫在線上,則資料庫也會在大約 10 分鐘內變成無法存取,其方式與已佈建的計算資料庫相同。
金鑰輪替
如果使用客戶管理的透明資料加密 (BYOK) 並啟用無伺服器自動暫停,則每當金鑰變換時,資料庫就會自動繼續,並在符合自動暫停條件時自動暫停。
建立新的無伺服器資料庫
建立新資料庫或將現有資料庫移到無伺服器計算層級,遵循與在佈建計算層級中建立新資料庫相同的模式,其中包含下列兩個步驟:
指定服務目標。 服務目標可指定服務層級、硬體設定和最大虛擬核心數。 如需服務目標選項,請參閱無伺服器資源限制
選擇性地指定最小虛擬核心數和自動暫停延遲,以變更其預設值。 下表顯示這些參數的可用值。
參數 值選擇 預設值 最高 vCore 取決於已設定的最大虛擬核心數 - 請參閱資源限制。 0.5 個虛擬核心 自動暫停延遲 最小值:15 分鐘
最大值:10,080 分鐘 (7 天)
增量:1 分鐘
停用自動暫停:-160 Minuten
下列範例會在無伺服器計算層中建立新的資料庫。
使用 Azure 入口網站
請參閱快速入門:使用 Azure 入口網站在 Azure SQL Database 中建立單一資料庫。
使用 PowerShell
使用下列 PowerShell 範例,以建立新的無伺服器一般用途資料庫:
New-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 0.5 -MaxVcore 2 -AutoPauseDelayInMinutes 720
使用 Azure CLI
使用下列 Azure CLI 範例,以建立新的一般用途無伺服器資料庫:
az sql db create -g $resourceGroupName -s $serverName -n $databaseName `
-e GeneralPurpose --compute-model Serverless -f Gen5 `
--min-capacity 0.5 -c 2 --auto-pause-delay 720
使用 Transact-SQL (T-SQL)
使用 T-SQL 建立新的無伺服器資料庫時,會套用最低虛擬核心數和自動暫停延遲的預設值。 這些值隨後可以在 Azure 入口網站或透過 PowerShell、Azure CLI 和 REST 等 API 變更。
如需詳細資訊,請參閱建立資料庫。
使用下列 T-SQL 範例,以建立新的一般用途無伺服器資料庫:
CREATE DATABASE testdb
( EDITION = 'GeneralPurpose', SERVICE_OBJECTIVE = 'GP_S_Gen5_1' ) ;
在計算層級或服務層級之間移動資料庫
資料庫可以在布建的計算層級與無伺服器計算層級之間移動。
無伺服器資料庫也可以從一般用途服務層級移至超大規模資料庫服務層級。 若要深入了解,請檢閱管理超大規模資料庫。
如果是在計算層級之間移動資料庫,請提供計算模型參數作為 Serverless 或 Provisioned (使用 PowerShell 和 Azure CLI 時),或是 SERVICE_OBJECTIVE (使用 T-SQL 時)。 檢閱資源限制,以識別適當的服務目標。
下列範例中會將現有的資料庫從布建的計算層級移至無伺服器計算層級。
使用 PowerShell
使用下列 PowerShell 範例,將已佈建的計算一般用途資料庫移至無伺服器計算層:
Set-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 1 -MaxVcore 4 -AutoPauseDelayInMinutes 1440
使用 Azure CLI
使用下列 Azure CLI 範例,將已佈建的計算一般用途資料庫移至無伺服器計算層:
az sql db update -g $resourceGroupName -s $serverName -n $databaseName `
--edition GeneralPurpose --compute-model Serverless --family Gen5 `
--min-capacity 1 --capacity 4 --auto-pause-delay 1440
使用 Transact-SQL (T-SQL)
使用 T-SQL 在計算層級之間移動資料庫時,會套用最低虛擬核心數和自動暫停延遲的預設值。 這些值隨後可以在 Azure 入口網站或透過 PowerShell、Azure CLI 和 REST 等 API 變更。 如需詳細資訊,請參閱 ALTER DATABASE。
使用下列 T-SQL 範例,將已佈建的計算一般用途資料庫移至無伺服器計算層:
ALTER DATABASE testdb
MODIFY ( SERVICE_OBJECTIVE = 'GP_S_Gen5_1') ;
修改無伺服器設定
使用 PowerShell
使用 Set-AzSqlDatabase 以修改最大或最小虛擬核心,以及自動暫停延遲。 使用 MaxVcore、MinVcore 和 AutoPauseDelayInMinutes 引數。 超大規模資料庫層目前不支援無伺服器自動暫停,因此自動暫停延遲引數只適用於一般用途層。
使用 Azure CLI
使用 az sql db update 以修改最大或最小虛擬核心,以及自動暫停延遲。 使用 capacity、min-capacity 和 auto-pause-delay 引數。 超大規模資料庫層目前不支援無伺服器自動暫停,因此自動暫停延遲引數只適用於一般用途層。
監視器
使用和計費的資源
無伺服器資料庫的資源包含應用程式套件、SQL 執行個體和使用者資源集區實體。
應用程式套件
不論資料庫是在無伺服器或佈建計算層級中,應用程式套件都是資料庫的最外層資源管理界限。 應用程式套件包含 SQL 執行個體和外部服務 (例如全文檢索搜尋),其可一起界定 SQL Database 中資料庫所用的所有使用者和系統資源。 SQL 執行個體通常會支配整個應用程式套件的整體資源使用率。
使用者資源集區
不論資料庫是在無伺服器或佈建計算層級中,使用者資源集區都是資料庫的內層資源管理界限。 使用者資源集區可界定 DDL 查詢 (例如,CREATE 和 ALTER) 和 DML 查詢 (例如,INSERT、UPDATE、DELETE、MERGE 和 SELECT) 所產生使用者工作負載的 CPU 和 IO 範圍。 這些查詢通常代表應用程式套件內很大的使用率比例。
計量
下表包含的計量用於監視無伺服器資料庫 (包括任何異地複本) 的應用程式套件和使用者資源集區的資源使用量:
| 實體 | 計量 | 描述 | 單位 |
|---|---|---|---|
| 應用程式套件 | app_cpu_percent | 應用程式所使用的虛擬核心百分比,相對於應用程式所允許的最大虛擬核心數。 針對無伺服器超大規模資料庫,會針對所有主要複本、具名複本和異地複本公開此計量。 | 百分比 |
| 應用程式套件 | app_cpu_billed | 在報告期間內針對應用程式計費的計算數量。 在這段期間所支付的金額為此計量與虛擬核心單價的乘積。 彙總每秒使用的 CPU 與記憶體上限,即可判斷此計量的值。 如果使用的數量小於依照最小虛擬核心數與最小記憶體所設定的最小佈建數量,就會收取最小佈建數量的費用。 為了比較 CPU 與記憶體以供計費用途,記憶體會依每個虛擬核心 3 GB 重新調整記憶體量,藉此規範成虛擬核心單位。 針對無伺服器超大規模資料庫,會針對主要複本和任何具名複本公開此計量。 |
虛擬核心秒數 |
| 應用程式套件 | app_cpu_billed_HA_replicas | 僅適用於無伺服器超大規模資料庫。 在報告期間,針對 HA 複本的所有應用程式所計費的計算總和。 此總和的範圍限於屬於主要複本的 HA 複本或屬於指定具名複本的 HA 複本。 跨 HA 複本計算此總和之前,針對個別 HA 複本所計費的計算數量會以與主要複本或具名複本相同的方式來決定。 針對無伺服器超大規模資料庫,會針對所有主要複本、具名複本和異地複本公開此計量。 在報告期間所支付的金額為此計量與虛擬核心單價的乘積。 | 虛擬核心秒數 |
| 應用程式套件 | app_memory_percent | 應用程式所使用的記憶體百分比,相對於應用程式所允許的最大記憶體。 針對無伺服器超大規模資料庫,會針對所有主要複本、具名複本和異地複本公開此計量。 | 百分比 |
| 使用者資源集區 | cpu_percent | 使用者工作負載所使用的虛擬核心百分比,相對於使用者工作負載所允許的最大虛擬核心數。 | 百分比 |
| 使用者資源集區 | data_IO_percent | 使用者工作負載所使用的資料 IOPS 百分比,相對於使用者工作負載所允許的最大資料 IOPS。 | 百分比 |
| 使用者資源集區 | log_IO_percent | 使用者工作負載所使用的記錄 MB/s 百分比,相對於使用者工作負載所允許的最大記錄 MB/s。 | 百分比 |
| 使用者資源集區 | workers_percent | 使用者工作負載所使用的背景工作角色百分比,相對於使用者工作負載所允許的最大背景工作角色數。 | 百分比 |
| 使用者資源集區 | sessions_percent | 使用者工作負載所使用的工作階段百分比,相對於使用者工作負載所允許的最大工作階段數。 | 百分比 |
暫停與繼續狀態
如果已啟用自動暫停的無伺服器資料庫,報告的狀態包含下列值:
| 狀態 | 描述 |
|---|---|
| 線上存取 | 資料庫為上線狀態。 |
| 暫停中 | 資料庫正從上線轉換為暫停。 |
| 已暫停 | 資料庫已暫停。 |
| 繼續中 | 資料庫正從暫停轉換為上線。 |
使用 Azure 入口網站
在 Azure 入口網站,資料庫狀態顯示於資料庫的概觀頁面,及其伺服器的概觀頁面。 此外,在 Azure 入口網站,可以在活動記錄檢視無伺服器資料庫的暫停和繼續事件歷程記錄。
使用 PowerShell
請使用下列 PowerShell 範例檢視目前的資料庫狀態:
Get-AzSqlDatabase -ResourceGroupName $resourcegroupname -ServerName $servername -DatabaseName $databasename `
| Select -ExpandProperty "Status"
使用 Azure CLI
請使用下列 Azure CLI 範例檢視目前的資料庫狀態:
az sql db show --name $databasename --resource-group $resourcegroupname --server $servername --query 'status' -o json
資源限制
如需資源限制,請參閱無伺服器計算層。
計費
針對無伺服器資料庫所計費的計算數量是每秒使用的最大 CPU 和記憶體。 如果使用的 CPU 和使用的記憶體數量小於每個資源的最小已佈建數量,則會收取已佈建數量的費用。 為了比較 CPU 與記憶體以供計費用途,記憶體會依每個虛擬核心 3 GB 來重新調整 GB 數目,以規範成虛擬核心單位。
- 計費資源:CPU 和記憶體
- 計費金額:虛擬核心單價 * 最大值 (最小虛擬核心數, 使用的虛擬核心, 最小記憶體 GB * 1/3, 使用的記憶體 GB * 1/3)
- 帳單週期:每秒
虛擬核心單價是每一虛擬核心每秒的成本。
如需指定區域中的特定單位價格,請參閱 Azure SQL Database 定價頁面。
下列計量會公開一般用途資料庫或超大規模資料庫主要或具名複本的無伺服器中所計費的計算數量:
- 計量:app_cpu_billed (虛擬核心秒數)
- 定義:最大值 (最小虛擬核心數, 使用的虛擬核心, 最小記憶體 GB * 1/3, 使用的記憶體 GB * 1/3)
- 報告頻率:根據 1 分鐘所彙總每秒度量的每分鐘。
下列計量會公開屬於主要複本或任何具名複本之超大規模資料庫 HA 複本的無伺服器中所計費的計算數量:
- 計量:app_cpu_billed_HA_replicas (虛擬核心秒數)
- 定義:屬於其父代資源之任何 HA 複本的最大值 (虛擬核心數下限, 使用的虛擬核心, 記憶體下限 GB * 1/3, 使用的記憶體 GB * 1/3) 的總和。
- 父代資源和計量端點:主要複本和任何具名複本都會個別公開此計量,以測量針對任何相關聯 HA 複本所計費的計算。
- 報告頻率:根據 1 分鐘所彙總每秒度量的每分鐘。
最小計算帳單
如果無伺服器資料庫已暫停,則計算帳單為零。 如果無伺服器資料庫未暫停,則最小計算帳單不低於以最大值 (最小虛擬核心, 最小記憶體 GB * 1/3) 為基礎的虛擬核心數量。
範例:
- 假設一般用途層中的無伺服器資料庫未暫停,並且已設定最多 8 個虛擬核心和最少 1 個虛擬核心對應至 3.0 GB 最小記憶體。 然後,最小計算帳單是以最大值 (1 個虛擬核心, 3.0 GB * 1 個虛擬核心/3 GB) = 1 個虛擬核心為基礎。
- 假設一般用途層中的無伺服器資料庫未暫停,並且已設定最多 4 個虛擬核心和最少 0.5 個虛擬核心對應至 2.1 GB 最小記憶體。 然後,最小計算帳單是以最大值 (0.5 個虛擬核心, 2.1 GB * 1 個虛擬核心/3 GB) = 0.7 個虛擬核心為基礎。
- 假設超大規模資料庫層中的無伺服器資料庫具有含一個 HA 複本的主要複本,以及一個沒有 HA 複本的具名複本。 假設每個複本都已設定最多 8 個虛擬核心和最小 1 個虛擬核心對應至 3 GB 的最小記憶體。 則主要複本、HA 複本和具名複本的最小計算帳單都會個別以最大值 (1 個虛擬核心, 3 GB * 1 個虛擬核心/3 GB) = 1 個虛擬核心為基礎。
適用於無伺服器的 Azure SQL 資料庫定價計算機可用來根據所設定的最大和最小虛擬核心數,判斷可設定的最小記憶體。 做為規則,如果所設定的最小虛擬核心大於 0.5 個虛擬核心,則最小計算帳單與所設定的最小記憶體無關,且只會根據所設定的最小虛擬核心數。
案例範例
請考慮使用一般用途層中已設定最少 1 個虛擬核心和最多 4 個虛擬核心的無伺服器資料庫。 此設定對應到大約 3 GB 的最小記憶體和 12 GB 的最大記憶體。 假設自動暫停延遲設定為 6 小時,且資料庫工作負載在 24 小時期間的前 2 小時內為使用中,其他時間則為非使用中。
在此情況下,前 8 個小時會針對資料庫的計算和儲存體計費。 即使在第二個小時之後資料庫就開始處於非使用中狀態,在資料庫仍上線時,還是會根據已佈建的最小計算,針對後 6 個小時的計算來計費。 而在資料庫暫停時,24 小時期間的剩餘時間就只會針對儲存體來計費。
更精確地說,此範例中的計算費用算法如下:
| 時間間隔 | 每秒使用的虛擬核心數 | 每秒使用的 GB 數 | 計費的計算維度 | 時間間隔內計費的虛擬核心秒數 |
|---|---|---|---|---|
| 0:00-1:00 | 4 | 9 | 使用的虛擬核心數 | 4 個虛擬核心 * 3600 秒 = 14400 虛擬核心秒數 |
| 1:00-2:00 | 1 | 12 | 使用的記憶體 | 12 GB * 1/3 * 3600 秒數 = 14400 虛擬核心秒數 |
| 2:00-8:00 | 0 | 0 | 已佈建的最小記憶體 | 3 GB * 1/3 * 21600 秒 = 21600 虛擬核心秒數 |
| 8:00-24:00 | 0 | 0 | 暫停時不會針對計算來計費 | 0 虛擬核心秒數 |
| 過去 24 小時內的計費虛擬核心秒數總計 | 50,400 虛擬核心秒數 |
假設計算單價為 $0.000145/虛擬核心/秒。 然後,此 24 小時期間所計費的計算,就是計算單價和已計費的虛擬核心秒數相乘:$0.000145/虛擬核心/秒 * 50400 虛擬核心秒數 ~ $7.31。
Azure Hybrid Benefit 及保留容量
Azure Hybrid Benefit (AHB) 和保留容量折扣不適用於無伺服器計算層。
可用區域
除了下列區域以外,全球可提供支援最多 40 個虛擬核心的無伺服器一般用途和超大規模資料庫層:
- 中國東部
- 中國北部
- 德國中部
- 德國東北部
- 美國政府中部 (愛荷華州)
針對一般用途和超大規模資料庫支援不含可用性區域的最多 80 個虛擬核心的區域
下列區域目前支援最多 80 個虛擬核心的無伺服器一般用途和超大規模資料庫層:
- 澳大利亞中部 1
- 澳大利亞中部 2
- 澳大利亞東部
- 澳大利亞東南部
- 巴西南部
- 巴西東南部
- 加拿大中部
- 加拿大東部
- 美國中部
- 中國東部 2
- 中國東部 3
- 中國北部 2
- 中國北部 3
- 東亞
- 美國東部
- 美國東部 2
- 法國中部
- 法國南部
- 德國北部
- 德國中西部
- 印度中部
- 印度南部
- 以色列中部
- 義大利北部
- 日本東部
- 日本西部
- Jio 印度中部
- Jio 印度西部
- 南韓中部
- 南韓南部
- Maylaysia South
- 墨西哥中部
- 美國中北部
- 北歐
- 挪威東部
- 挪威西部
- 波蘭中部
- 卡達中部
- 南非北部
- 南非西部
- 美國中南部
- 東南亞
- 西班牙中部
- 瑞典中部
- 瑞典南部
- 瑞士北部
- 瑞士西部
- 台灣北部
- 台灣西北部
- 阿拉伯聯合大公國中部
- 阿拉伯聯合大公國北部
- 英國南部
- 英國西部
- US Gov East
- US Gov Southcentral
- US Gov Southwest
- 西歐
- 美國中西部
- 美國西部
- 美國西部 2
- 美國西部 3
針對一般用途和超大規模資料庫支援含可用性區域的最多 80 個虛擬核心的區域
目前,下列區域在無伺服器一般用途層及超大規模資料庫支援具有可用性區域的最多 80 個虛擬核心,並且已規劃更多區域:
- 澳大利亞東部
- 巴西南部
- 加拿大中部
- 美國中部
- 東亞
- 美國東部
- 美國東部 2
- 法國中部
- 德國中西部
- 印度中部
- 日本東部
- 南韓中部
- 北歐
- 南非北部
- 美國中南部
- 東南亞
- 瑞典中部
- 阿拉伯聯合大公國北部
- 英國南部
- US Gov East
- 西歐
- 美國西部 2
- 美國西部 3
相關內容
- 若要開始使用,請參閱快速入門:建立單一資料庫 - Azure SQL 資料庫。
- 如需無伺服器服務層級選項,請參閱一般用途和超大規模資料庫。