Azure Data Factory 和 Azure Synapse Analytics 中的分隔符號文字格式
適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
試用 Microsoft Fabric 中的 Data Factory,這是適用於企業的全方位分析解決方案。 Microsoft Fabric 涵蓋從資料移動到資料科學、即時分析、商業智慧和報告的所有項目。 了解如何免費開始新的試用!
當您想要剖析分隔符號文字檔,或將資料寫入分隔符號文字格式時,請遵循本文來進行作業。
下列連接器支援分隔符號文字格式:
- Amazon S3
- Amazon S3 相容儲存體
- Azure Blob
- Azure Data Lake Storage Gen1
- Azure Data Lake Storage Gen2 \(部分機器翻譯\)
- Azure 檔案
- 檔案系統
- FTP
- Google Cloud Storage
- HDFS
- HTTP
- Oracle 雲端儲存空間
- SFTP
資料集屬性
如需可用來定義資料集的區段和屬性完整清單,請參閱資料集一文。 本節提供分隔符號文字資料集所支援的屬性清單。
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 資料集的 type 屬性必須設定為 DelimitedText。 | Yes |
| location | 檔案的位置設定。 每個檔案型連接器都包含專屬的位置類型,並支援 location 下的屬性。 |
Yes |
| columnDelimiter | 用來分隔檔案中的資料行的字元。 預設值是逗號 ,。 當資料行分隔符號定義為空字串時,表示沒有分隔符號,會將整行視為單一資料行。目前只有對應資料流支援資料行分隔符號做為空字串,複製活動不支援。 |
No |
| rowDelimiter | 針對複製活動,用來分隔檔案中資料列的單一字元或 "\r\n"。 預設值是下列任一值 讀取時:["\r\n", "\r", "\n"];寫入時:"\r\n"。 只有在 copy 命令中才支援 "\r\n"。 針對對應資料流,用來分隔檔案中資料列的單一或兩個字元。 預設值是下列任一值 讀取時:["\r\n", "\r", "\n"];寫入時:"\n"。 當資料列分隔符號設定為沒有分隔符號 (空字串) 時,資料行分隔符號也必須設定為沒有分隔符號 (空字串),表示將整個內容視為單一值。 目前只有對應資料流支援資料列分隔符號做為空字串,複製活動不支援。 |
No |
| quoteChar | 如果包含資料行分隔符號,用於括住資料行值的單一字元。 預設值為雙引號 "。 當 quoteChar 定義為空字串時,表示沒有引號字元,資料行值未加上引號,而且 escapeChar 用於逸出資料行分隔符號和本身。 |
No |
| escapeChar | 在已加上引號的值內逸出引號的單一字元。 預設值為反斜線 \。 當 escapeChar 定義為空字串時,必須也將 quoteChar 設為空字串,在此情況下,請確定所有資料行值不包含分隔符號。 |
No |
| firstRowAsHeader | 指定是否要將第一個資料列視為具有資料行名稱的標頭行。 允許的值為 true 和 false (預設值)。 當第一個資料列做為標頭為 false 時,請注意,UI 資料預覽和查詢活動輸出會自動產生名稱為 Prop_{n} (從 0 開始) 的資料行,複製活動需要從來源明確對應至接收,並依序 (從 1 開始) 找出資料行,而對應資料流會列出並找出名稱為 Column_{n} (從 1 開始) 的資料行。 |
No |
| nullValue | 指定 Null 值的字串表示法。 預設值是空字串。 |
No |
| encodingName | 用來讀取/寫入測試檔案的編碼類型。 允許的值如下:"UTF-8"、"UTF-8 不使用 BOM"、"UTF-16"、"UTF-16BE"、"UTF-32"、"UTF-32BE"、"US-ASCII"、"UTF-7"、"BIG5"、"EUC-JP"、"EUC-KR"、"GB2312"、"GB18030"、"JOHAB"、"SHIFT-JIS"、"CP875"、"CP866"、"IBM00858"、"IBM037"、"IBM273"、"IBM437"、"IBM500"、"IBM737"、"IBM775"、"IBM850"、"IBM852"、"IBM855"、"IBM857"、"IBM860"、"IBM861"、"IBM863"、"IBM864"、"IBM865"、"IBM869"、"IBM870"、"IBM01140"、"IBM01141"、"IBM01142"、"IBM01143"、"IBM01144"、"IBM01145"、"IBM01146"、"IBM01147"、"IBM01148"、"IBM01149"、"ISO-2022-JP"、"ISO-2022-KR"、"ISO-8859-1"、"ISO-8859-2"、"ISO-8859-3"、"ISO-8859-4"、"ISO-8859-5"、"ISO-8859-6"、"ISO-8859-7"、"ISO-8859-8"、"ISO-8859-9"、"ISO-8859-13"、"ISO-8859-15"、"WINDOWS-874"、"WINDOWS-1250"、"WINDOWS-1251"、"WINDOWS-1252"、"WINDOWS-1253"、"WINDOWS-1254"、"WINDOWS-1255"、"WINDOWS-1256"、"WINDOWS-1257"、"WINDOWS-1258"。 請注意,對應資料流不支援 UTF-7 編碼。 請注意,對應資料流不支援使用位元組順序標記 (BOM) 的 UTF-8 編碼。 |
No |
| compressionCodec | 用來讀取/寫入文字檔的壓縮轉碼器。 允許的值為 bzip2、gzip、deflate、ZipDflate、TarGzip、Tar、snappy 或 lz4。 預設為不壓縮。 請注意,複製活動目前不支援 "snappy" 與 "lz4",而對應資料流不支援 "ZipDeflate"、"TarGzip" 和 "Tar"。 請注意,使用複製活動將 ZipDeflate/TarGzip/Tar 檔案解壓縮並寫入檔案型接收資料存放區時,預設會將檔案擷取至資料夾: <path specified in dataset>/<folder named as source compressed file>/,在複製活動來源上使用 preserveZipFileNameAsFolder/preserveCompressionFileNameAsFolder 來控制是否要保留壓縮檔的名稱做為資料夾結構。 |
No |
| compressionLevel | 壓縮比。 允許的值為 Optimal 或 Fastest。 - Fastest:即使產生的檔案不以最佳方式壓縮,也應盡快完成壓縮作業。 - Optimal:即使作業需要較長時間完成,壓縮作業也應以最佳方式壓縮。 如需詳細資訊,請參閱 壓縮層級 主題。 |
No |
以下是 Azure Blob 儲存體上的分隔符號文字資料集範例:
{
"name": "DelimitedTextDataset",
"properties": {
"type": "DelimitedText",
"linkedServiceName": {
"referenceName": "<Azure Blob Storage linked service name>",
"type": "LinkedServiceReference"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"typeProperties": {
"location": {
"type": "AzureBlobStorageLocation",
"container": "containername",
"folderPath": "folder/subfolder",
},
"columnDelimiter": ",",
"quoteChar": "\"",
"escapeChar": "\"",
"firstRowAsHeader": true,
"compressionCodec": "gzip"
}
}
}
複製活動屬性
如需可用來定義活動的區段和屬性完整清單,請參閱管線一文。 本節提供分隔符號文字來源和接收所支援的屬性清單。
做為來源的分隔符號文字
複製活動的 [來源] 區段支援下列屬性。
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 複製活動來源的 type 屬性必須設為 DelimitedTextSource。 | Yes |
| formatSettings | 屬性群組。 請參閱下方分隔符號文字讀取設定資料表。 | No |
| storeSettings | 屬性群組,可決定從資料存放區讀取資料的方式。 在 storeSettings 下,每個檔案型連接器都包含專屬的支援讀取設定。 |
No |
formatSettings 下支援的分隔符號文字讀取設定:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | formatSettings 的型別必須設定為 DelimitedTextReadSettings。 | Yes |
| skipLineCount | 指出從輸入檔讀取資料時,要略過的非空白資料列數。 如果同時指定 skipLineCount 和 firstRowAsHeader,則會先略過行,然後從輸入檔讀取標頭資訊。 |
No |
| compressionProperties | 關於如何針對指定的壓縮轉碼器解壓縮資料的一組屬性。 | No |
| preserveZipFileNameAsFolder ( compressionProperties->type 下為 ZipDeflateReadSettings) |
將輸入資料集設定為使用 ZipDeflate 壓縮時適用。 指出是否要在複製期間保留來源 ZIP 檔案名稱做為資料夾結構。 - 設定為 true (預設) 時,服務會將解壓縮的檔案寫入 <path specified in dataset>/<folder named as source zip file>/。- 設定為 false 時,服務會將解壓縮的檔案直接寫入 <path specified in dataset>。 請確定不同的來源 ZIP 檔案中沒有重複的檔案名稱,以避免發生競爭或非預期的行為。 |
No |
| preserveCompressionFileNameAsFolder ( compressionProperties-type> 下為 TarGZipReadSettings 或 TarReadSettings) |
將輸入資料集設定為使用 TarGzip/Tar 壓縮時適用。 指出是否要在複製期間保留來源壓縮檔案名稱做為資料夾結構。 - 設定為 true (預設) 時,服務會將解壓縮的檔案寫入 <path specified in dataset>/<folder named as source compressed file>/。 - 設定為 false 時,服務會將解壓縮的檔案直接寫入 <path specified in dataset>。 請確定不同的來源檔案中沒有重複的檔案名稱,以避免發生競爭或非預期的行為。 |
No |
"activities": [
{
"name": "CopyFromDelimitedText",
"type": "Copy",
"typeProperties": {
"source": {
"type": "DelimitedTextSource",
"storeSettings": {
"type": "AzureBlobStorageReadSettings",
"recursive": true
},
"formatSettings": {
"type": "DelimitedTextReadSettings",
"skipLineCount": 3,
"compressionProperties": {
"type": "ZipDeflateReadSettings",
"preserveZipFileNameAsFolder": false
}
}
},
...
}
...
}
]
做為接收的分隔符號文字
複製活動的 [接收] 區段支援下列屬性。
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | 複製活動來源的 type 屬性必須設為 DelimitedTextSink。 | Yes |
| formatSettings | 屬性群組。 請參閱下方分隔符號文字寫入設定資料表。 | No |
| storeSettings | 屬性群組,可決定將資料寫入資料存放區的方式。 每個以檔案為基礎的連接器在 storeSettings 底下皆具有自身的支援寫入設定。 |
No |
formatSettings 下支援的分隔符號文字寫入設定:
| 屬性 | 描述 | 必要 |
|---|---|---|
| type | formatSettings 的型別必須設定為 DelimitedTextWriteSettings。 | Yes |
| fileExtension | 用來命名輸出檔案的副檔名,例如 .csv.txt。 在輸出 DelimitedText 資料集中未指定 fileName 時,必須加以指定。 在輸出資料集中設定檔案名稱時,會做為接收檔案名稱使用,並忽略副檔名設定。 |
當輸出資料集未指定檔案名稱時,請選取 [是] |
| maxRowsPerFile | 當您將資料寫入資料夾時,可以選擇寫入多個檔案,並指定每個檔案的資料列上限。 | No |
| fileNamePrefix | 當 maxRowsPerFile 完成設定時適用。當您將資料寫入多個檔案時,請指定檔案名稱前置詞,使系統進行此模式: <fileNamePrefix>_00000.<fileExtension>。 如果未指定,系統會自動產生檔案名稱前置詞。 當來源是以檔案為基礎的存放區,或啟用資料分割選項的資料存放區時,系統不會套用此屬性。 |
No |
對應資料流程屬性
在對應資料流中,您可以在下列資料存放區讀取和寫入分隔符號文字格式:Azure Blob 儲存體、Azure Data Lake Storage Gen1、Azure Data Lake Storage Gen2 和 SFTP,且您可以在 Amazon S3 中讀取分隔符號文字格式。
內嵌資料集
對應資料流支援將「內嵌資料集」作為定義來源和接收的選項。 內嵌分隔資料集會直接在您的來源和接收轉換內定義,且不會在定義的資料流程外部共用。 這有助於直接在資料流程內針對資料集屬性進行參數化,並可受益於共用 ADF 資料集帶來的效能提升。
當您要讀取大量的來源資料夾和檔案時,可以在 [投影] | [結構描述選項] 對話方塊內設定 [使用者投影的結構描述] 選項來改善資料流程檔案探索效能。 此選項會關閉 ADF 的預設結構描述自動探索,並將大幅改善檔案探索的效能。 設定此選項之前,請務必匯入投影,讓 ADF 具有現有投影的結構描述。 此選項不適用於結構描述漂移。
來源屬性
下表列出分隔符號文字來源支援的屬性。 您可以在 [來源選項] 索引標籤中編輯這些屬性。
| 名稱 | 描述 | 必要 | 允許的值 | 資料流程指令碼屬性 |
|---|---|---|---|---|
| 萬用字元路徑 | 系統會處理符合萬用字元路徑的所有檔案。 覆寫資料集的資料夾和檔案路徑集合。 | 否 | String[] | wildcardPaths |
| 分割區根路徑 | 如果是分割的檔案資料,您可以輸入分割區根路徑,讀取作為資料行的分割資料夾 | 否 | String | partitionRootPath |
| 檔案清單 | 您的來源是否指向列出待處理檔案的文字檔 | 否 | true 或 false |
fileList |
| 多行資料列 | 來源檔案是否包含跨越多行的資料列。 多行值必須以引號括住。 | 不可使用 true 或 false |
multiLineRow | |
| 要儲存檔案名稱的資料行 | 使用來源檔案名稱和路徑,建立新的資料行 | 否 | String | rowUrlColumn |
| 完成後 | 處理後刪除或移動檔案。 從容器根開始的檔案路徑 | 否 | 刪除:true 或 false 移動: ['<from>', '<to>'] |
purgeFiles moveFiles |
| 依上次修改日期來篩選 | 根據上次變更檔案的時間,選擇篩選的檔案 | 否 | 時間戳記 | modifiedAfter modifiedBefore |
| 允許找不到檔案 | 如果為 true,找不到檔案時不會擲回錯誤 | 否 | true 或 false |
ignoreNoFilesFound |
| 最大資料行數 | 預設值為 20480。 當資料行編號超過 20480 時請自訂此值 | 否 | 整數 | maxColumns |
注意
檔案清單的資料流程來源支援限制為檔案中的 1024 個項目。 若要包含更多檔案,請在檔案清單中使用萬用字元。
來源範例
下圖是在對應資料流中分隔符號文字來源設定的範例。
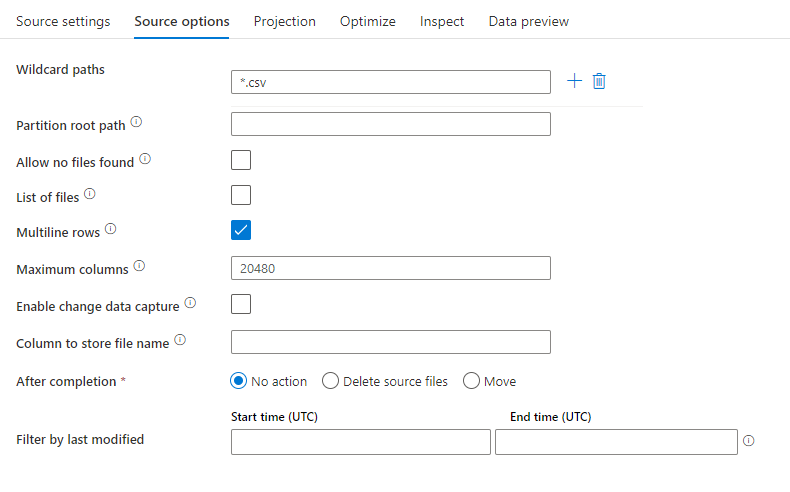
相關的資料流程指令碼:
source(
allowSchemaDrift: true,
validateSchema: false,
ignoreNoFilesFound: false,
multiLineRow: true,
wildcardPaths:['*.csv']) ~> CSVSource
注意
資料流程來源支援 Hadoop 檔案系統支援之 Linux 萬用字元的有限集合
接收屬性
下表列出分隔符號文字接收支援的屬性。 您可以在 [設定] 索引標籤中編輯這些屬性。
| 名稱 | 描述 | 必要 | 允許的值 | 資料流程指令碼屬性 |
|---|---|---|---|---|
| 清除資料夾 | 如果在進行寫入之前清除目的地資料夾 | 否 | true 或 false |
truncate |
| 檔案名稱選項 | 已寫入資料的命名格式。 依預設,每個分割區的一個檔案會是 part-#####-tid-<guid> 格式 |
否 | 模式:String 每個分割區:String[] 將檔案命名為資料行資料:String 輸出至單一檔案: ['<fileName>'] 將資料夾命名為資料行資料:String |
filePattern partitionFileNames rowUrlColumn partitionFileNames rowFolderUrlColumn |
| 全部以引號括住 | 以引號括住所有值 | 否 | true 或 false |
quoteAll |
| 頁首 | 將客戶標頭新增至輸出檔案 | 否 | [<string array>] |
標頭 |
接收範例
下圖是在對應資料流中分隔符號文字接收設定的範例。
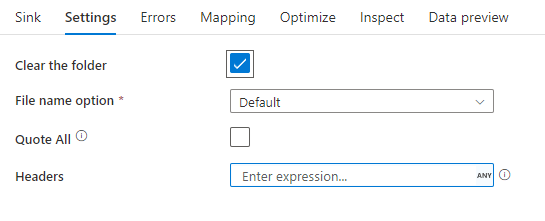
相關的資料流程指令碼:
CSVSource sink(allowSchemaDrift: true,
validateSchema: false,
truncate: true,
skipDuplicateMapInputs: true,
skipDuplicateMapOutputs: true) ~> CSVSink
相關的連接器和格式
以下是一些與分隔符號文字格式相關的常見連接器和格式: