適用於: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
提示
Data Factory in Microsoft Fabric 是下一代的 Azure Data Factory,擁有更簡單的架構、內建 AI 及新功能。 如果你是資料整合新手,建議先從 Fabric Data Factory 開始。 現有的 ADF 工作負載可升級至 Fabric,以存取資料科學、即時分析與報告等新能力。
在資料處理站與 Synapse 管線中的 Spark 活動會在您自有的或按需的 HDInsight 叢集中執行 Spark 程式。 本文延續於資料轉換活動 一文,呈現了資料轉換和支援的轉換活動的一般概覽。 當您使用隨選 Spark 連結的服務時,服務會自動為您建立 Spark 叢集 Just-In-Time 以處理資料,一旦處理完成之後就會刪除叢集。
使用 UI 將 Spark 活動新增至管道
若要對管道使用 Spark 活動,請完成下列步驟:
在管線 [活動] 窗格中搜尋 Spark,然後將 Spark 活動拖曳至管線畫布中。
若尚未選取 Spark 活動,請在畫布上選取新的 Spark 活動。
選取 [HDI 叢集] 索引標籤,即可選取或建立 HDInsight 叢集的新連結服務,該叢集會用來執行 Spark 活動。
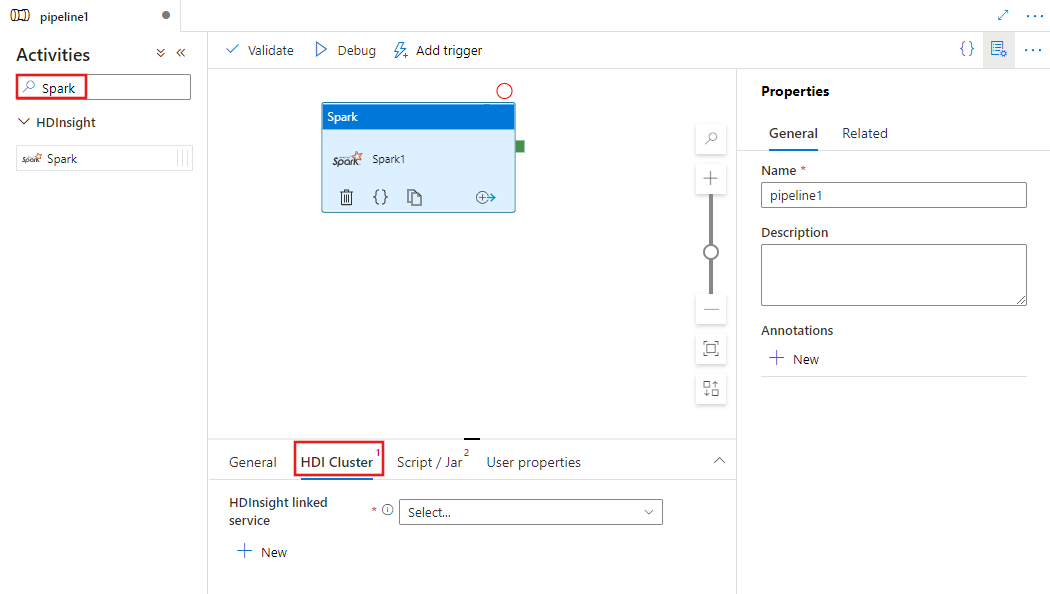
選擇 Script / Jar 標籤,選擇或建立一個新的工作連結服務,連接到一個Azure Storage帳號,該帳號將承載你的腳本。 指定要在該處執行的檔案路徑。 您也可以設定進階的詳細資料,包括 Proxy 使用者、偵錯設定,以及要傳遞至指令碼的引數和 Spark 設定參數。
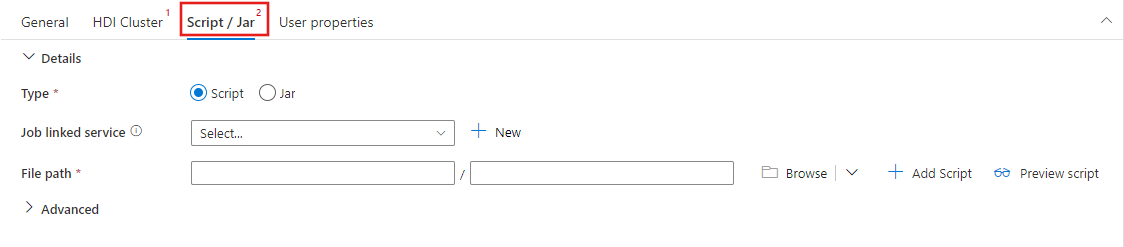
Spark 活動屬性
以下是 Spark 活動的 JSON 定義範例:
{
"name": "Spark Activity",
"description": "Description",
"type": "HDInsightSpark",
"linkedServiceName": {
"referenceName": "MyHDInsightLinkedService",
"type": "LinkedServiceReference"
},
"typeProperties": {
"sparkJobLinkedService": {
"referenceName": "MyAzureStorageLinkedService",
"type": "LinkedServiceReference"
},
"rootPath": "adfspark",
"entryFilePath": "test.py",
"sparkConfig": {
"ConfigItem1": "Value"
},
"getDebugInfo": "Failure",
"arguments": [
"SampleHadoopJobArgument1"
]
}
}
下表說明 JSON 定義中使用的 JSON 屬性:
| 屬性 | 描述 | 必要 |
|---|---|---|
| 名稱 | 管線中的活動名稱。 | Yes |
| 說明 | 說明活動用途的文字。 | 不 |
| 型別 | 對於 Spark 活動,活動類型為 HDInsightSpark。 | Yes |
| 連結服務名稱 | Spark 程式執行所在的 HDInsight Spark 連結服務名稱。 若要深入了解此已連結的服務,請參閱計算已連結的服務一文。 | Yes |
| SparkJobLinkedService | Azure Storage 連結服務,存放 Spark 工作檔案、相依關係和日誌。 此處僅支援 Azure Blob Storage 及 ADLS Gen2 連接的服務。 如果您未指定此屬性的值,則會使用與 HDInsight 叢集相關聯的儲存體。 這個屬性的價值只能是 Azure Storage 連結服務。 | 不 |
| rootPath | Azure Blob 容器和資料夾,裡面有 Spark 檔案。 檔案名稱有區分大小寫。 如需了解此資料夾結構的詳細資料,請參閱資料夾結構一節 (下一節)。 | Yes |
| entryFilePath | Spark 程式碼/套件之根資料夾的相對路徑。 入口檔案必須是 Python 檔案或 .jar 檔案。 | Yes |
| className | 應用程式的 Java/Spark 主類別 | 不 |
| 引數 | Spark 程式的命令列引數清單。 | 不 |
| proxyUser | 模擬來執行 Spark 程式的使用者帳戶 | 不 |
| sparkConfig | 指定下列主題中所列的 Spark 組態屬性值:Spark 組態 - 應用程式屬性 (英文)。 | 不 |
| getDebugInfo | 指定何時將 Spark 日誌檔案複製到 HDInsight 叢集使用的 Azure 儲存裝置(或由 sparkJobLinkedService 指定)。 允許的值︰「None」、「Always」或「Failure」。 預設值:無。 | 不 |
資料夾結構
Spark 作業比 Pig/Hive 作業更具擴充性。 對於 Spark 工作,你可以提供多個相依,例如 jar 套件(放在 Java CLASSPATH 中)、Python 檔案(放在 PYTHONPATH 中)以及任何其他檔案。
在 HDInsight 連結服務參考的 Azure Blob 儲存中建立以下資料夾結構。 然後,將相依檔案上傳至根資料夾中以 entryFilePath 表示的適當子資料夾。 例如,將 Python 檔案上傳到 pyFiles 子資料夾,將 jar 檔案上傳到 root 資料夾的 jars 子資料夾。 執行時,服務預期 Azure Blob 儲存中的資料夾結構如下:
| 路徑 | 描述 | 必要 | 類型 |
|---|---|---|---|
. (根目錄) |
Spark 工作在儲存體連結服務中的根路徑 | Yes | 資料夾 |
| <使用者定義> | 指向 Spark 作業輸入檔案的路徑 | Yes | 檔案 |
| ./jars | 此資料夾下的所有檔案都會上傳並放置在叢集的 Java 類別路徑上 | 不 | 資料夾 |
| ./pyFiles | 此資料夾下的所有檔案會上傳至並置於計算叢集的 PYTHONPATH 中。 | 不 | 資料夾 |
| ./files | 此資料夾下的所有檔案會上傳並放在執行程式工作目錄 | 不 | 資料夾 |
| ./archives | 此資料夾下的所有檔案未壓縮 | 不 | 資料夾 |
| ./logs | 此資料夾包含來自 Spark 叢集的記錄。 | 不 | 資料夾 |
這裡有一個包含兩個 Spark 工作檔案的儲存裝置範例,該檔案在 Azure Blob Storage 中由 HDInsight 連結服務引用。
SparkJob1
main.jar
files
input1.txt
input2.txt
jars
package1.jar
package2.jar
logs
archives
pyFiles
SparkJob2
main.py
pyFiles
scrip1.py
script2.py
logs
archives
jars
files
相關內容
請參閱下列文章,其說明如何以其他方式轉換資料: