在 Databricks 筆記本中開發程式碼
此頁面描述如何在 Databricks 筆記本中開發程式碼,包括自動完成、Python 和 SQL 的自動格式化、在筆記本中結合 Python 與 SQL,以及追蹤筆記本版本歷程記錄。
如需編輯器所提供之進階功能的詳細資訊,例如自動完成、變數選取、多資料指標支援和並排差異,請參閱使用 Databricks 筆記本和檔案編輯器。
當您使用筆記本或檔案編輯器時,可以使用 Databricks Assistant 來協助您產生、說明和偵錯程式碼。 如需詳細資訊,請參閱使用 Databricks Assistant。
Databricks 筆記本也包含適用於 Python 筆記本的內建互動式偵錯工具。 請參閱偵錯筆記本。
從 Databricks Assistant 取得程式碼撰寫說明
Databricks Assistant 是內容感知 AI 助理,您可以使用對話介面與之互動,提高在 Databricks 內的效率。 您可以使用英文描述任務,讓助理產生 Python 程式碼或 SQL 查詢、說明複雜的程式碼,並自動修正錯誤。 助理會使用 Unity Catalog 中繼資料來了解您公司的資料表、資料行、描述和熱門資料資產,以提供個人化的回覆。
Databricks Assistant 可協助執行下列任務:
- 產生程式碼。
- 偵錯程式碼,包括識別及建議錯誤修正。
- 轉換和最佳化程式碼。
- 解釋程式碼。
- 協助您在 Azure Databricks 文件中尋找相關資訊。
如需使用 Databricks Assistant 協助您更有效率地撰寫程式碼的相關資訊,請參閱使用 Databricks Assistant。 如需 Databricks Assistant 的一般資訊,請參閱支援 DatabricksIQ 的功能。
存取筆記本以進行編輯
若要開啟筆記本,請使用搜尋函式工作區或使用工作區瀏覽器瀏覽至筆記本,然後按下筆記本的名稱或圖示。
瀏覽資料
使用結構描述瀏覽器來探索筆記本可用的 Unity Catalog 物件。 按下筆記本左側的 ![]() 以開啟結構描述瀏覽器。
以開啟結構描述瀏覽器。
[適用於您] 按鈕只會顯示您在目前會話中使用的物件,或先前標示為 [我的最愛] 的物件。
當您在 [篩選器] 方塊中鍵入文字時,顯示會變更,只顯示包含您鍵入之文字的物件。 只有目前開啟或已在目前會話中開啟的物件才會顯示。 [篩選器] 方塊不會完整搜尋筆記本可用的目錄、結構描述、資料表和磁碟區。
若要開啟 ![]() kebab 功能表,請將游標停留在物件名稱的上方,如下所示:
kebab 功能表,請將游標停留在物件名稱的上方,如下所示:
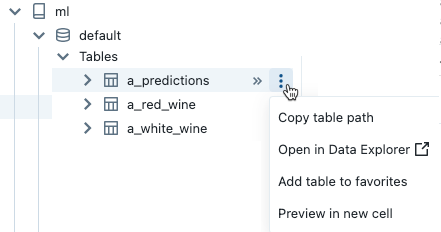
如果物件是資料表,您可以執行下列操作:
- 自動建立並執行儲存格,以顯示資料表中的資料預覽。 從資料表的 Kebab 功能表選取 [在新儲存格中預覽]。
- 在目錄總管中檢視目錄、結構描述或資料表。 從 Kebab 功能表選取 [在目錄總管中開啟]。 新的索引標籤隨即開啟,並顯示選取的物件。
- 取得目錄、結構描述或資料表的路徑。 從物件的 Kebab 功能表選取 [複製...路徑]。
- 將資料表新增至 [我的最愛]。 從資料表的 Kebab 功能表選取 [新增至我的最愛]。
如果物件是目錄、結構描述或磁碟區,您可以複製物件的路徑,或在目錄總管中開啟它。
若要將資料表或資料列名稱直接插入儲存格中:
- 在儲存格中要輸入名稱的位置按下游標。
- 將游標移至結構描述瀏覽器中的資料表名稱或資料行名稱上方。
- 按下物件名稱右邊的雙箭號
 。
。
鍵盤快速鍵
若要顯示鍵盤快速鍵,請選取 [輔助說明] > [鍵盤快速鍵]。 可用的鍵盤快速鍵取決於游標在程式碼儲存格中 (編輯模式),還是不在 (命令模式)。
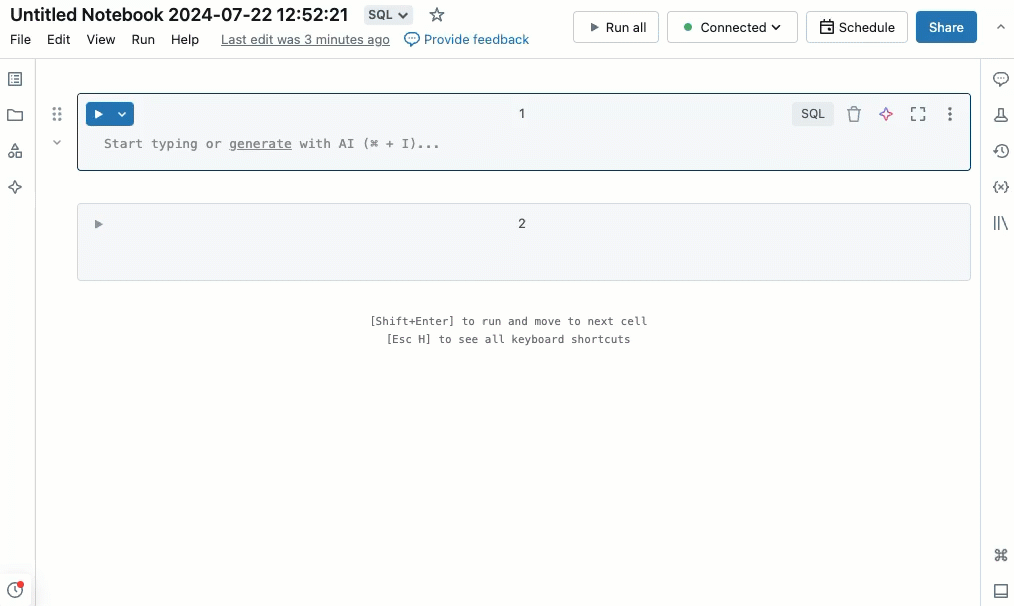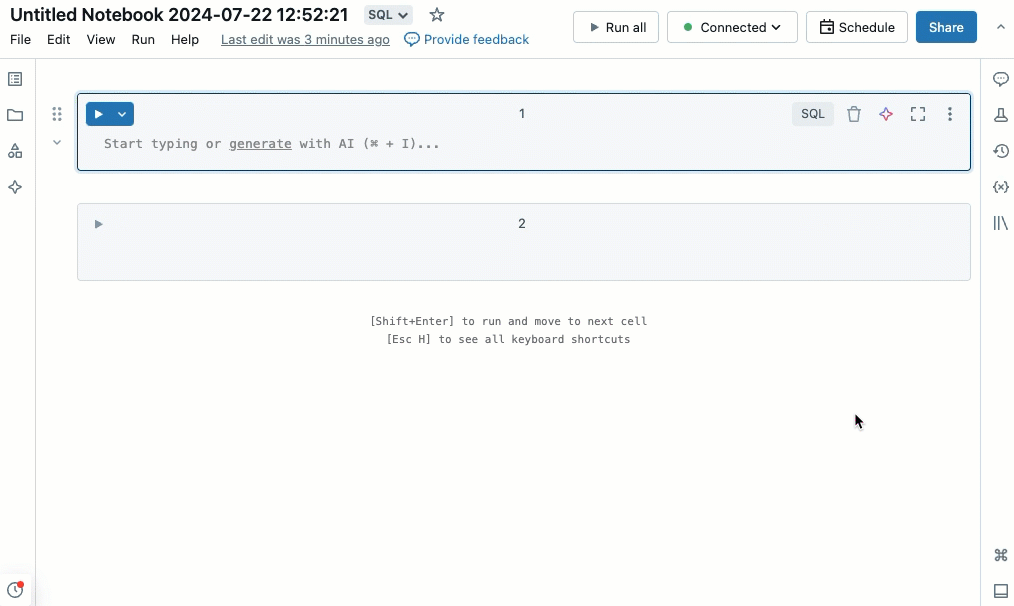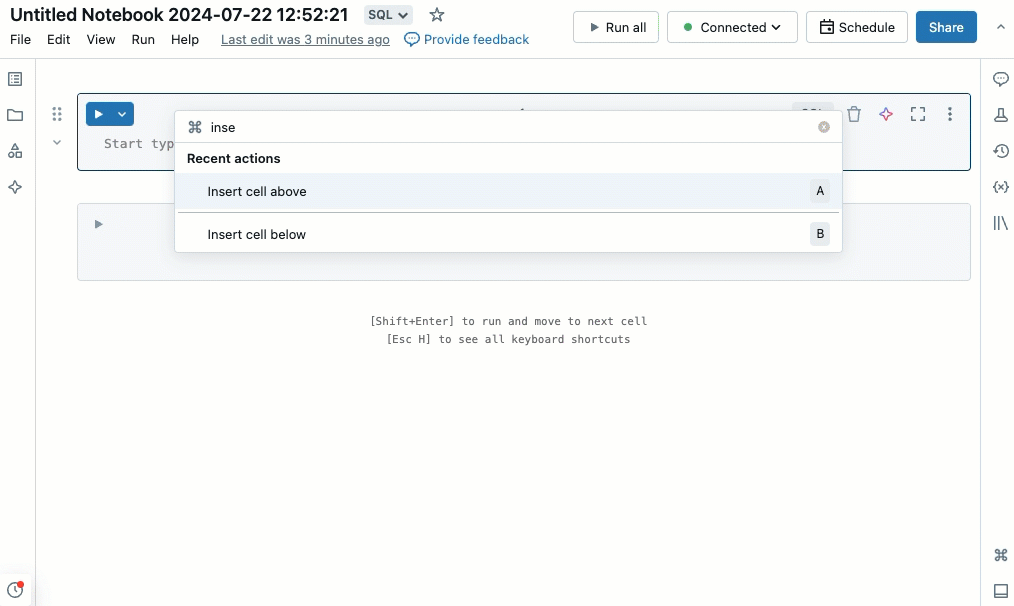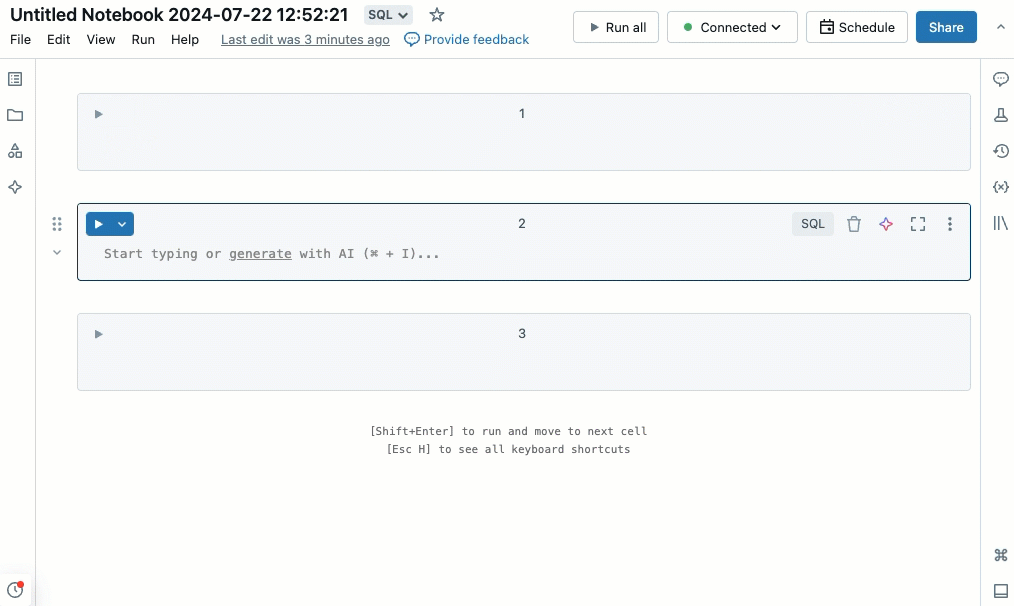
命令選擇區
您可以使用命令選擇區快速在筆記本中執行動作。 若要開啟筆記本動作面板,請按下工作區右下角的  、使用 MacOS 上的快速鍵 Cmd + Shift + P,或使用 Windows 上的 Ctrl + Shift + P。
、使用 MacOS 上的快速鍵 Cmd + Shift + P,或使用 Windows 上的 Ctrl + Shift + P。
尋找及取代文字
若要尋找並取代筆記本內的文字,請選取 [編輯] > [尋找及取代]。 目前的相符項以橙色反白顯示,所有其他相符項以黃色反白顯示。
若要取代目前的相符項,請按下 [取代]。 若要取代筆記本中的所有相符項,請按下 [全部取代]。
若要在相符項之間移動,請按下 [上一個] 和 [下一個] 按鈕。 您也可以按 shift+enter,然後按 enter 分別進入上一個和下一個相符項。
若要關閉尋找及取代工具,請按下 ![]() 或按 esc 鍵。
或按 esc 鍵。
執行所選儲存格
您可以執行單一儲存格或儲存格集合。 若要選取單一儲存格,請按下儲存格中的任意位置。 若要選取多個儲存格,請按住 MacOS 上的 Command 鍵或 Windows 上的 Ctrl 鍵,然後按下文字區域以外的儲存格,如螢幕擷取畫面中所示。
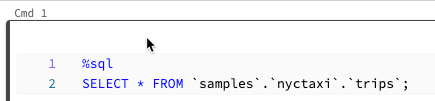
若要執行選取的儲存格,此命令的行為取決於筆記本連結的叢集。
- 在執行 Databricks Runtime 13.3 LTS 或以下版本的叢集上,會個別執行選取的儲存格。 如果儲存格中發生錯誤,則系統會繼續執行後續儲存格。
- 在執行 Databricks Runtime 14.0 或更新版本或 SQL 倉儲的叢集上,選取的儲存格會以批次方式執行。 任何錯誤都停止執行,而且您無法取消個別儲存格的執行。 您可以使用 [插斷] 按鈕停止執行所有儲存格。
模組化程式碼
重要
這項功能處於公開預覽狀態。
使用 Databricks Runtime 11.3 LTS 和更高版本,您可以在 Azure Databricks 工作區中建立和管理原始程式碼檔案,然後視需要將這些檔案匯入筆記本。
如需使用原始程式碼檔案的詳細資訊,請參閱在 Databricks 筆記本之間共用程式碼和使用 Python 和 R 模組。
執行選取的文字
您可以在筆記本儲存格中反白顯示程式碼或 SQL 陳述式,並只執行該選取範圍。 當您想要快速反覆執行程式碼和查詢時,這很有用。
反白顯示您要執行的行。
選取 [執行] > [執行選取的文字],或使用鍵盤快速鍵
Ctrl+Shift+Enter。 如果未反白顯示任何文字,執行選取的文字會執行目前的行。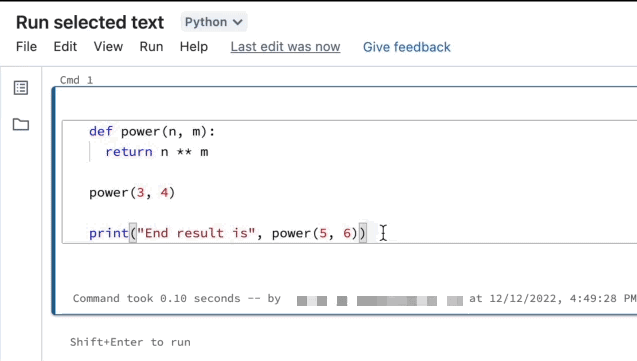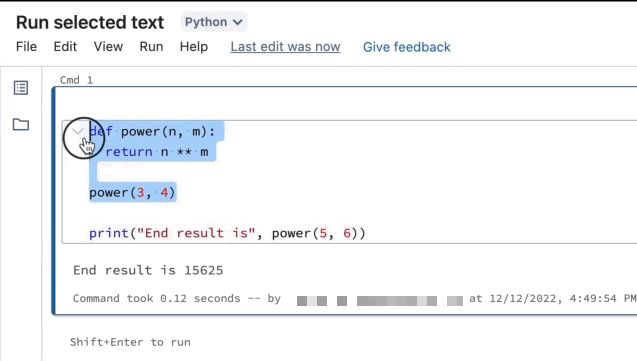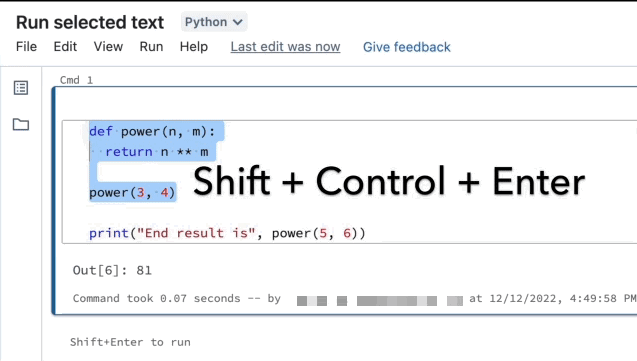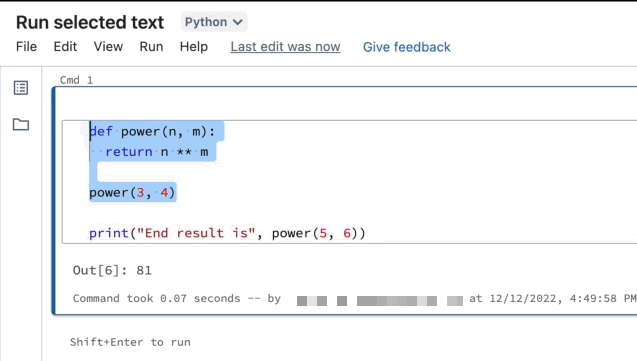
如果您在儲存格中使用混合語言,則必須在選取範圍中包含 %<language> 行。
執行選取的文字也會執行已收合的程式碼 (如果反白選取的文字中有任何程式碼)。
支援 %run、%pip 和 %sh 等特殊的儲存格命令。
您無法在具有多個輸出索引標籤的儲存格 (即已定義資料設定檔或視覺化的儲存格) 上使用執行選取文字。
格式化程式碼儲存格
Azure Databricks 提供工具,可讓您快速且輕鬆地在筆記本儲存格中格式化 Python 和 SQL 程式碼。 這些工具可減少將程式碼格式化的工作,並協助在您的筆記本中強制執行相同的編碼標準。
Python 黑色格式器程式庫
重要
這項功能處於公開預覽狀態。
Azure Databricks 支援在筆記本中使用黑色來格式化 Python 程式碼。 筆記本必須附加至已安裝 black 和 tokenize-rt Python 套件的叢集。
在 Databricks Runtime 11.3 LTS 和更新版本上,Azure Databricks 會預安裝 black 和 tokenize-rt: 您可以直接使用格式器,不需要安裝這些程式庫。
在 Databricks Runtime 10.4 LTS 和以下版本上,您必須從 PyPI 安裝 black==22.3.0 和 tokenize-rt==4.2.1 到筆記本或叢集上,才能使用 Python 格式器。 您可以在筆記本中執行下列命令:
%pip install black==22.3.0 tokenize-rt==4.2.1
或者在叢集上安裝程式庫。
如需安裝程式庫的詳細資訊,請參閱 Python 環境管理。
對於 Databricks Git 資料夾中的檔案和筆記本,您可以根據 pyproject.toml 檔案設定 Python 格式器。 若要使用此功能,請在 Git 資料夾根目錄中建立 pyproject.toml 檔案,並根據黑色組態格式進行設定。 編輯檔案中的 [tool.black] 區段。 當您格式化該 Git 資料夾中的任何檔案和筆記本時,設定即會套用。
如何格式化 Python 和 SQL 儲存格
您必須擁有筆記本的 [可以編輯] 權限,才能格式化程式碼。
Azure Databricks 會使用 Gethue/sql-formatter 程式庫來格式化 SQL 和適用於 Python 的黑色程式碼格式器。
可以透過下列方式觸發格式器:
格式化單一儲存格
格式化多個儲存格
選取多個儲存格,然後選取 [編輯] > [格式化儲存格]。 如果選取多個語言的儲存格,則只會格式化 SQL 和 Python 儲存格。 這包括使用
%sql與%python的儲存格。格式化筆記本中的所有 Python 和 SQL 儲存格
選取 [編輯] > [格式化筆記本]。 如果您的筆記本包含一種以上的語言,則只會格式化 SQL 和 Python 儲存格。 這包括使用
%sql與%python的儲存格。
程式碼格式化限制
- Black 會強制執行 4 個空間縮排的 PEP 8 標準。 無法設定縮排。
- 不支援格式化 SQL UDF 內的內嵌 Python 字串。 同樣,不支援在 Python UDF 內格式化 SQL 字串。
版本歷程記錄
Azure Databricks 筆記本會維護筆記本版本的歷程記錄,使您能夠檢視和還原筆記本先前的快照。 您可以在版本上執行下列動作:新增批注、還原和刪除版本,以及清除版本歷程記錄。
也可以在 Databricks 中與遠端 Git 存放庫同步工作。
若要存取筆記本版本,請按下右側側邊欄中的  。 筆記本版本歷程記錄隨即顯示。 您也可以選取 [檔案] > [版本歷程記錄]。
。 筆記本版本歷程記錄隨即顯示。 您也可以選取 [檔案] > [版本歷程記錄]。
新增註解
若要將批注新增至最新版本,請執行以下操作:
按下版本。
按下 [立即儲存]。
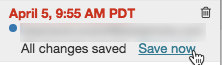
在 [儲存筆記本版本] 對話方塊中,輸入註解。
按一下 [檔案] 。 筆記本版本會與輸入的註解一起儲存。
還原版本
若要還原版本,請執行以下操作:
按下版本。
按下 [還原此版本]。
按一下確認。 選取的版本會變成筆記本的最新版本。
刪除版本
若要刪除版本項目,請執行以下操作:
按下版本。
按下垃圾桶圖示
 。
。
按下 [是,清除]。 選取的版本即會從歷程記錄中刪除。
清除版本歷程記錄
在清除版本歷程記錄之後,就無法復原版本歷程記錄。
若要清除筆記本的版本歷程記錄:
- 選取 [ 檔案] > [清除版本歷程記錄]。
- 按下 [是,清除]。 筆記本版本歷程記錄即已清除。
筆記本中的程式碼語言
設定預設語言
筆記本的預設語言顯示在筆記本名稱旁邊。

若要變更預設語言,請按下語言按鈕,然後從下拉式功能表中選取新語言。 為了確保現有的命令能夠繼續運作,先前預設語言的命令會自動加上語言魔術命令的前置詞。
混合語言
根據預設,儲存格會使用筆記本的預設語言。 您可以按下語言按鈕,然後從下拉式功能表中選取語言,以覆寫儲存格中的預設語言。
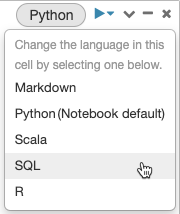
或者,您可以在儲存格開頭使用語言魔術命令 %<language>。 支援的魔術命令包括: %python、%r、%scala 和 %sql。
注意
當您叫用語言魔術命令時,命令會分派至筆記本執行內容中的 REPL。 以一種語言定義的變數 (因此在該語言的 REPL 中) 在另一種語言的 REPL 中不可用。 REPL 只能透過外部資源分享狀態,例如 DBFS 中的檔案或物件儲存體中的物件。
筆記本也支援一些輔助魔術命令:
%sh:可讓您在筆記本中執行 shell 程式碼。 如果 shell 命令具有非零離開狀態,則若要使儲存格失敗,請新增-e選項。 此命令只會在 Apache Spark 驅動程式上執行,而不是背景工作角色上。 若要在所有節點上執行 shell 命令,請使用 init 指令碼。%fs:可讓您使用dbutils檔案系統命令。 例如,若要執行dbutils.fs.ls命令來列出檔案,可以改為指定%fs ls。 如需詳細資訊,請參閱使用 Azure Databricks 上的檔案。%md:可讓您包括各種類型的文件,包括文字、影像,以及數學公式和方程式。 請參閱下一節。
Python 命令中的 SQL 語法反白顯示與自動完成
當您在 Python 命令 (例如 spark.sql 命令) 中使用 SQL 時,可以使用語法醒目提示和 SQL 自動完成。
使用 Python 探索 Python 筆記本中的 SQL 儲存格結果
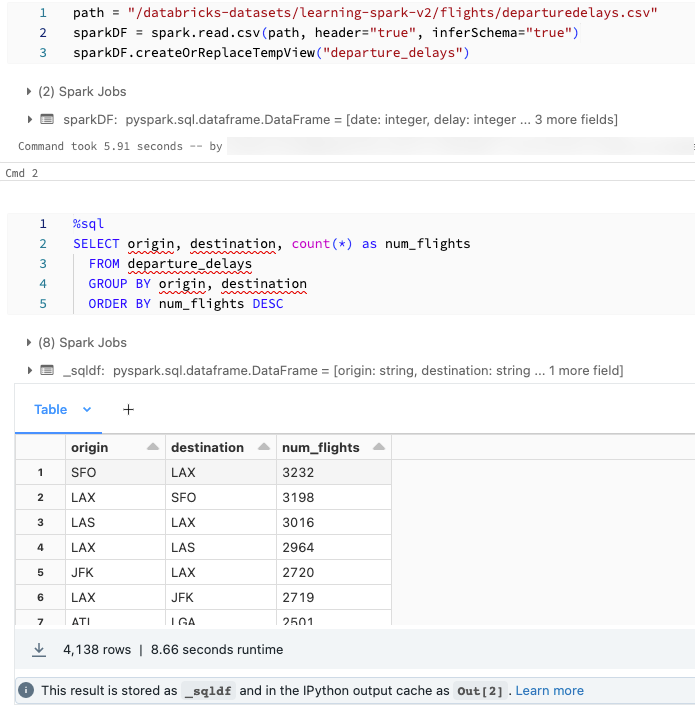
可以使用 SQL 載入資料,並使用 Python 加以探索。 在 Databricks Python 筆記本中,SQL 語言儲存格中的資料表結果會自動以 Python DataFrame 的形式分派給變數 _sqldf。
在 Databricks Runtime 13.3 LTS 和更新版本中,也可以使用 IPython 的輸出快取系統來存取 DataFrame 結果。 提示計數器會出現在儲存格結果底部顯示的輸出訊息中。 對於顯示的範例,可以將結果參考為 Out[2]。
注意
變數
_sqldf可能會在每次執行%sql儲存格時重新指派。 若要避免遺失 DataFrame 結果的參考,請在執行下一個%sql儲存格之前,將它指派給新的變數名稱:new_dataframe_name = _sqldf如果查詢使用小工具進行參數化,則結果無法以 Python DataFrame 格式提供。
如果查詢使用關鍵字
CACHE TABLE或UNCACHE TABLE,則結果無法以 Python DataFrame 格式提供。
以下螢幕擷取畫面顯示了一個範例:
平行執行 SQL 儲存格
當命令正在執行,且筆記本已連結至互動式叢集時,可以使用目前的命令同時執行 SQL 儲存格。 SQL 儲存格在新的平行工作階段中執行。
若要平行執行儲存格:
按下 [立即執行]。 儲存格會立即執行。
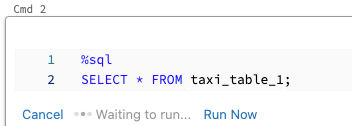
因為儲存格是在新的工作階段中執行,因此平行執行的儲存格不支援暫存檢視、UDF 和隱含 Python DataFrame (_sqldf)。 此外,平行執行期間會使用預設目錄和資料庫名稱。 如果您的程式碼參考不同目錄或資料庫中的資料表,必須使用三層命名空間 (catalog.schema.table) 指定資料表名稱。
在 SQL 倉儲上執行 SQL 儲存格
您可以在 Databricks 筆記本中的 SQL 倉儲上執行 SQL 命令,SQL 倉儲是一種針對 SQL 分析進行最佳化的計算類型。 請參閱將筆記本搭配 SQL 倉儲使用。
顯示影像
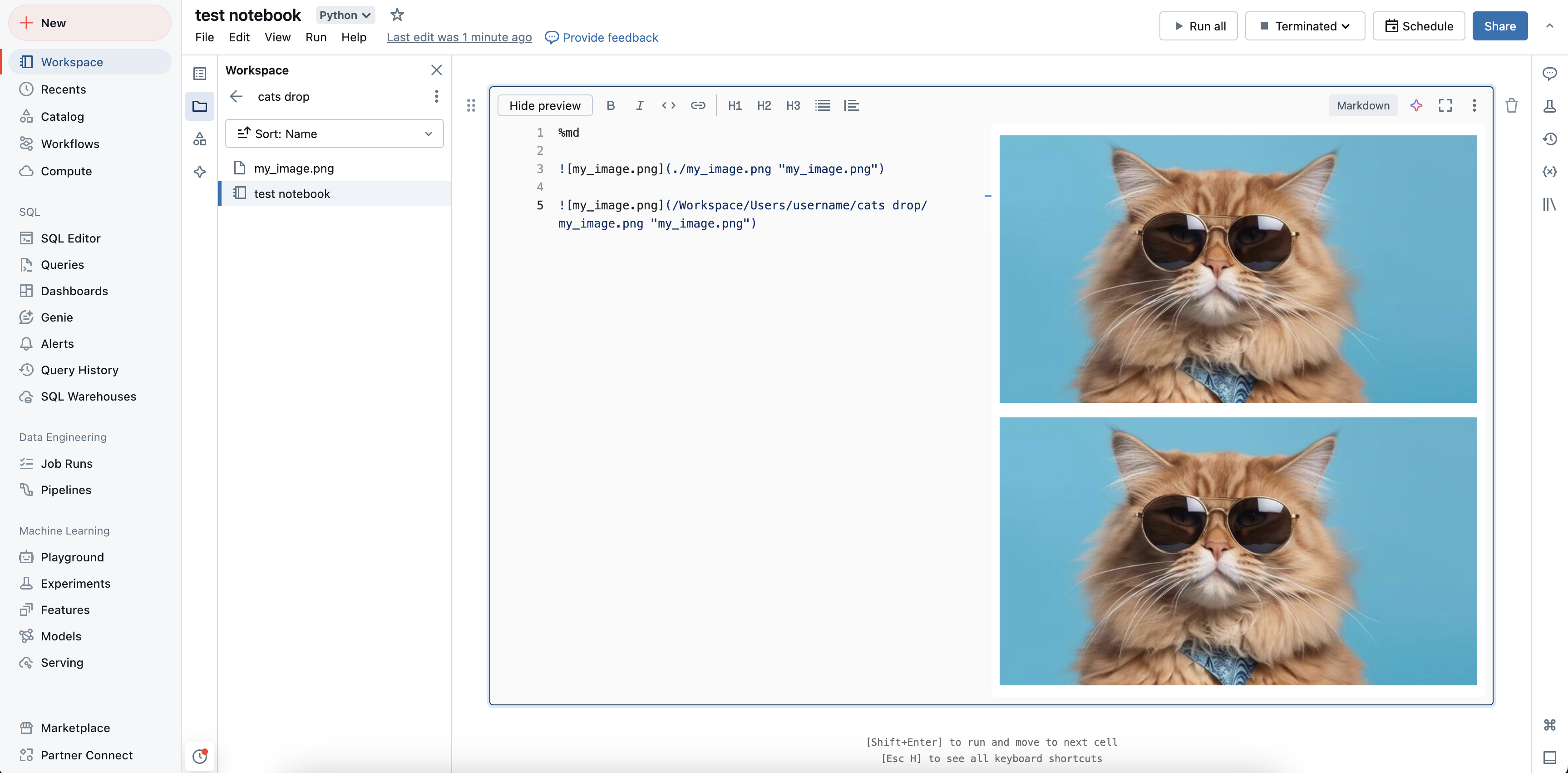
Azure Databricks 支援在 Markdown 儲存格中顯示影像。 您可以顯示儲存於工作區、磁碟區或 FileStore 中的影像。
顯示儲存於工作區中的影像
可以使用絕對路徑或相對路徑來顯示儲存在工作區中的影像。 若要顯示儲存在工作區中的影像,請使用下列語法:
%md


顯示儲存在磁碟區中的影像
可以使用絕對路徑來顯示儲存在磁碟區中的影像。 若要顯示儲存於磁碟區中的影像,請使用下列語法:
%md

顯示儲存於 FileStore 中的影像
若要顯示儲存於 FileStore 中的影像,請使用下列語法:
%md

例如,假設您在 FileStore 中有 Databricks 標誌影像文檔:
dbfs ls dbfs:/FileStore/
databricks-logo-mobile.png
當您在 Markdown 儲存格中包含下列程式碼時:

影像會在儲存格中轉譯:

拖放影像
可以將影像從本機檔案系統拖放到 Markdown 儲存格。 影像會上傳至目前的工作區目錄,並顯示在儲存格中。
顯示數學方程式
筆記本支援透過 KaTeX 顯示數學公式和方程式。 例如,
%md
\\(c = \\pm\\sqrt{a^2 + b^2} \\)
\\(A{_i}{_j}=B{_i}{_j}\\)
$$c = \\pm\\sqrt{a^2 + b^2}$$
\\[A{_i}{_j}=B{_i}{_j}\\]
轉譯為:
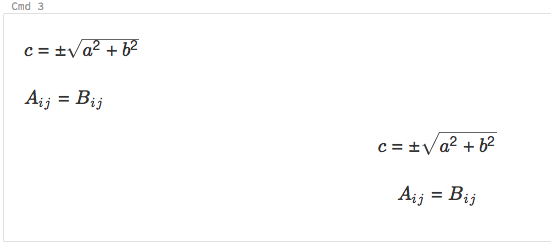
及
%md
\\( f(\beta)= -Y_t^T X_t \beta + \sum log( 1+{e}^{X_t\bullet\beta}) + \frac{1}{2}\delta^t S_t^{-1}\delta\\)
where \\(\delta=(\beta - \mu_{t-1})\\)
轉譯為:
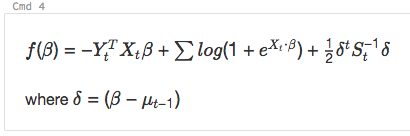
包含 HTML
您可以使用函式 displayHTML 在筆記本中包含 HTML。 如需如何執行這項操作的範例,請參閱筆記本 中的 HTML、D3 和 SVG。
注意
displayHTML iframe 會從網域 databricksusercontent.com 提供,而 iframe 沙盒會包含 allow-same-origin 屬性。 databricksusercontent.com 必須可從您的瀏覽器存取。 如果公司網路目前遭到封鎖,必須將其新增至允許清單。
連結至其他筆記本
可以使用相對路徑連結至 Markdown 儲存格中的其他筆記本或資料夾。 指定錨點標記的 href 屬性作為相對路徑,從 $ 開始,然後遵循與 Unix 檔案系統相同的模式:
%md
<a href="$./myNotebook">Link to notebook in same folder as current notebook</a>
<a href="$../myFolder">Link to folder in parent folder of current notebook</a>
<a href="$./myFolder2/myNotebook2">Link to nested notebook</a>