適用於:✅ Fabric 資料工程與資料科學
Fabric Livy API 允許你直接從遠端客戶端提交 Spark 批次和會話工作到 Fabric Spark 運算,無需使用 Fabric 入口網站。 在本文中,你會建立一個 Lakehouse,使用 Microsoft Entra 憑證驗證,發現 Livy API 端點,並提交並監控 Spark 會話工作。
必要條件
Fabric Premium 或試用容量搭配 Lakehouse
啟用 Livy API 的租戶管理員設定
遠端用戶端如 Visual Studio Code,支援 Jupyter 筆記型電腦、PySpark 及 Microsoft Authentication Library (MSAL) 支援 Python
也可以是 Microsoft Entra 應用程式的令牌。 在 Microsoft identity 平台上註冊應用程式
或者使用 Microsoft Entra SPN(Service Principal)令牌。
在 Microsoft Entra ID
選擇一個 REST API 用戶端
你可以從任何支援 HTTP 請求的客戶端與 Livy API 互動,包括像 curl 或任何帶有 HTTP 函式庫的語言。 本文範例使用
如何為 Livy API 請求授權存取權限
要使用 Livy API,你需要使用 Microsoft Entra ID 來驗證你的請求。 有兩種授權方法可供選擇:
Entra SPN 憑證(服務主體):應用程式以憑證(如用戶端秘密或憑證)作為自身身份驗證。 此方法適用於自動化流程與背景服務,無需使用者互動。
Entra 應用程式令牌(委派):該應用程式以登入使用者的身份執行操作。 此方法適合您希望應用程式能以已認證使用者的權限存取資源。
選擇最適合您情況的授權方式,並依照下方相應的章節操作。
如何以 Microsoft Entra SPN 令牌授權 Livy API 請求
要使用 Fabric API,包括 Livy API,首先需要建立一個 Microsoft Entra 應用程式,並建立一個秘密,並將這個秘密用於程式碼中。 你的應用程式需要被註冊並設定,才能對 Fabric 執行 API 呼叫。 欲了解更多資訊,請參閱
建立應用程式註冊之後,請建立客戶端密碼。
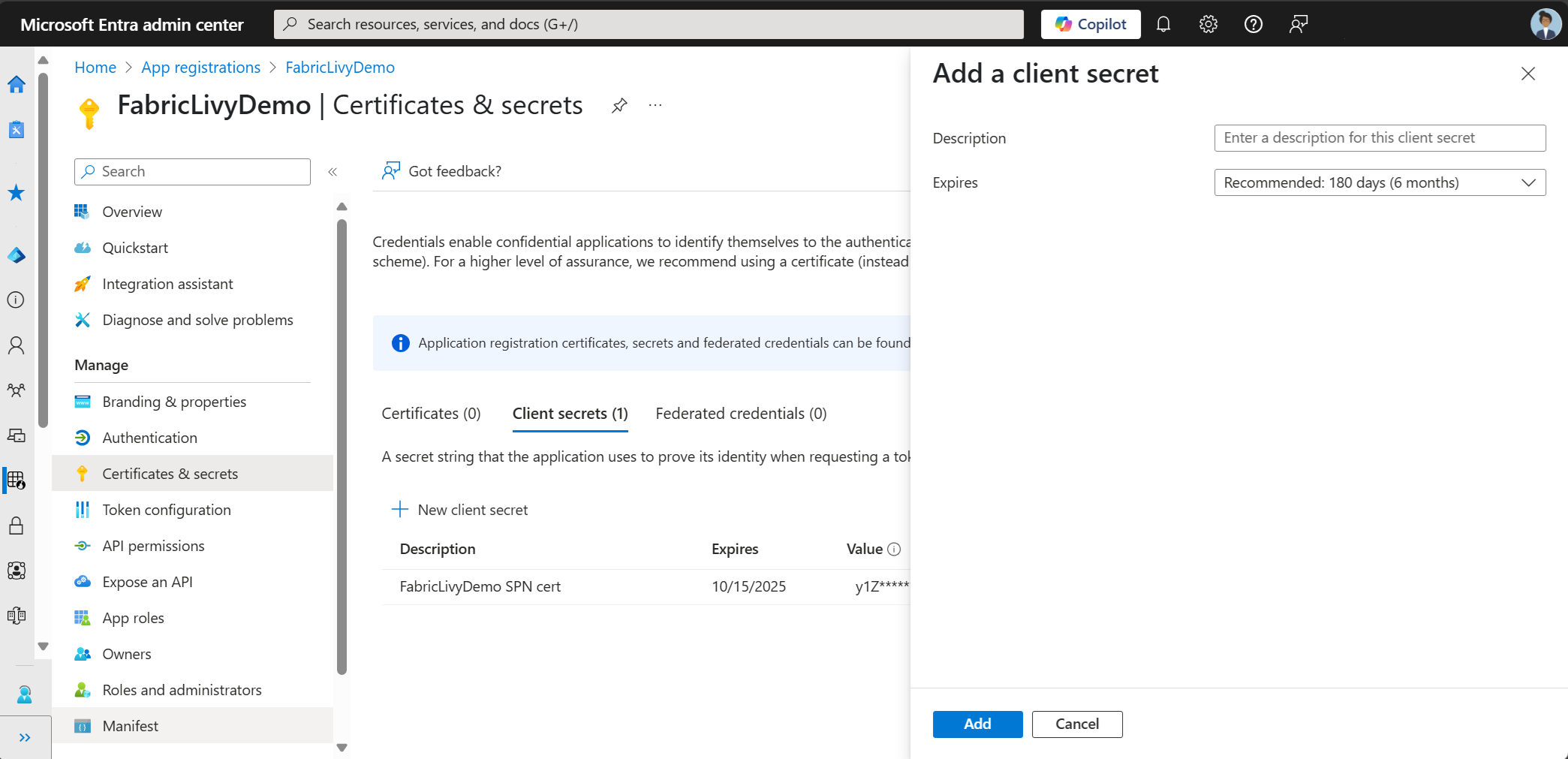
當您建立客戶端密碼時,請務必複製值。 您稍後在程式碼中會用到這個,並且無法再次查看這個秘密。 你還需要應用程式(客戶端)ID 和目錄(租戶 ID),以及程式碼中的機密。
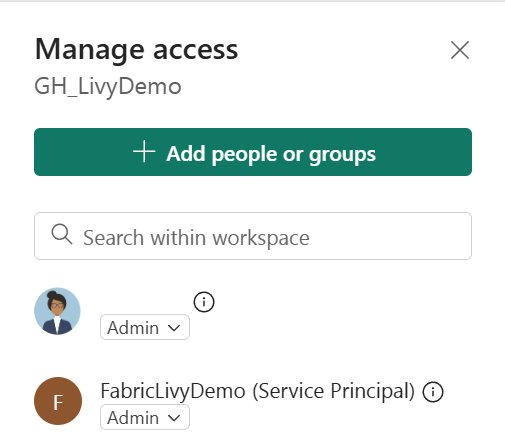
接著,將服務主體新增到你的工作空間。
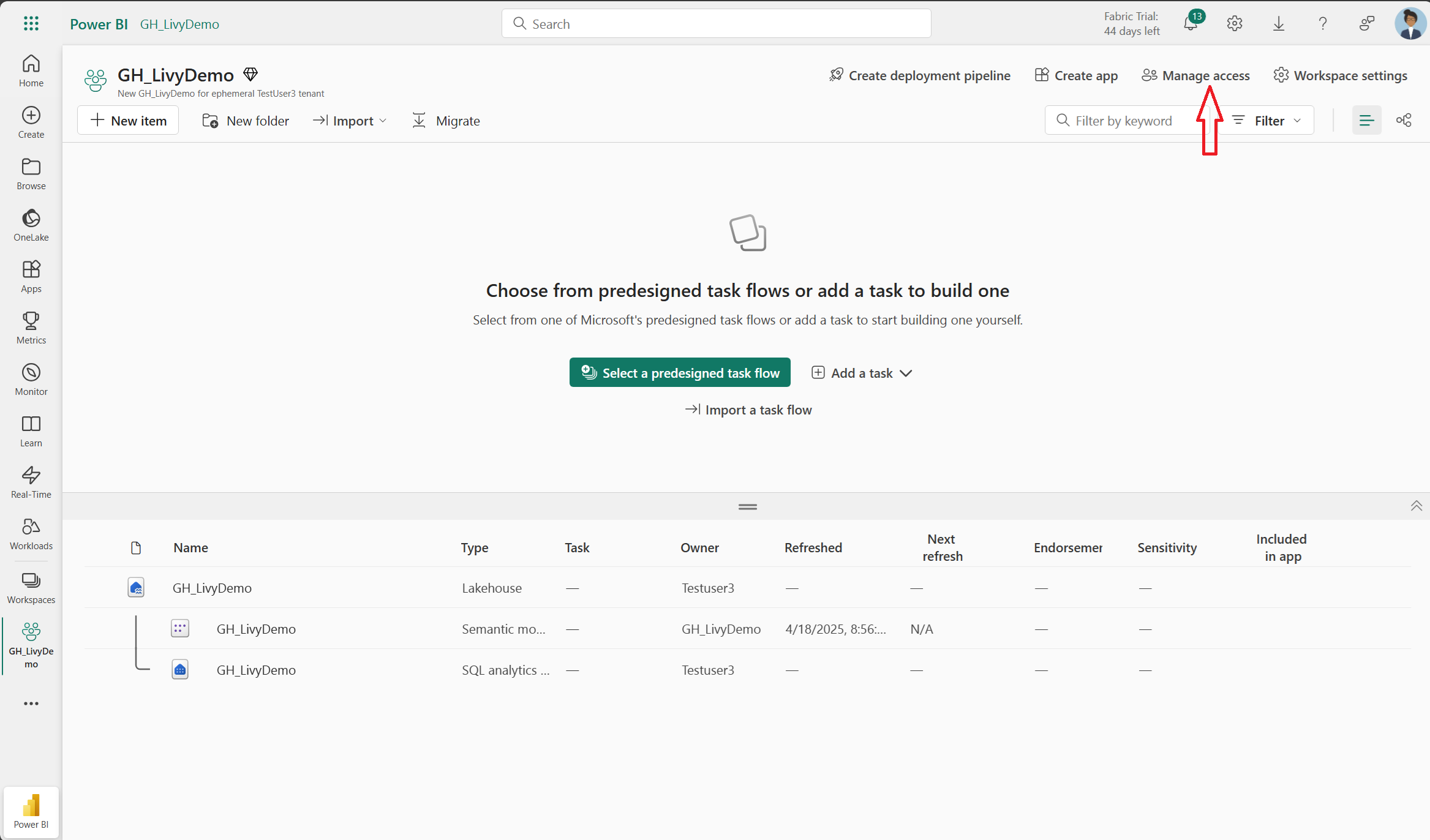
使用應用程式(用戶端)ID 或名稱搜尋 Microsoft Entra 應用程式,將其加入工作區,並確保服務主體擁有貢獻者權限。



如何使用 Entra 應用程式令牌授權 Livy API 請求
要使用 Fabric API,包括 Livy API,首先需要建立一個 Microsoft Entra 應用程式並取得一個憑證。 你的應用程式需要被註冊並設定,才能對 Fabric 執行 API 呼叫。 欲了解更多資訊,請參閱以Microsoft identity platform註冊申請。
執行 Livy API 工作需要以下 Microsoft Entra 範圍權限:
所需的範圍
| Scope | 說明 |
|---|---|
Lakehouse.Execute.All |
在 Fabric 湖屋中執行作業。 |
Lakehouse.Read.All |
閱讀 Lakehouse 的元資料。 |
Code.AccessFabric.All |
允許取得 Microsoft Fabric 的存取權杖。 所有 Livy API 操作皆需。 |
Code.AccessStorage.All |
允許取得 OneLake 和 Azure 儲存的存取權杖。 用於在湖倉中讀寫數據所需的。 |
可選代碼*範圍
只有當你的 Spark 工作需要在執行時存取對應的 Azure 服務時,才加入這些範圍。
| Scope | 說明 | 使用時機 |
|---|---|---|
Code.AccessAzureKeyvault.All |
允許取得 Azure Key Vault 的存取權杖。 | 您的 Spark 程式碼會從 Azure Key Vault 取得秘密、金鑰或憑證。 |
Code.AccessAzureDataLake.All |
允許取得 Azure Data Lake Storage Gen1 的存取權杖。 | 你的 Spark 程式碼會從 Azure Data Lake Storage Gen1 帳號讀取或寫入。 |
Code.AccessAzureDataExplorer.All |
允許取得 Azure Data Explorer(Kusto)的存取令牌。 | 你的 Spark 程式碼查詢或從 Azure Data Explorer 叢集匯入資料。 |
Code.AccessSQL.All |
允許獲取 Azure SQL 的存取權杖。 | 你的 Spark 程式碼需要連接到 Azure SQL 資料庫。 |
註冊應用程式時,你需要同時提供應用程式(客戶端)ID 和目錄(租戶)ID。
呼叫 Livy API 的已驗證用戶必須是具有參與者角色的 API 和數據源專案所在的工作區成員。 如需詳細資訊,請參閱讓使用者存取工作區。
理解 Livy API 的程式碼*範圍
當你的 Spark 工作透過 Livy API 執行時,Code.* 範圍控制已認證使用者代表 Spark 執行環境能存取哪些外部服務。 需要兩個,其餘根據你的工作量自行選擇。
必要代碼。* 範圍
| Scope | 說明 |
|---|---|
Code.AccessFabric.All |
允許取得 Microsoft Fabric 的存取權杖。 所有 Livy API 操作皆需。 |
Code.AccessStorage.All |
允許取得 OneLake 和 Azure 儲存的存取權杖。 用於在湖倉中讀寫數據所需的。 |
可選代碼*範圍
只有當你的 Spark 工作需要在執行時存取對應的 Azure 服務時,才加入這些範圍。
| Scope | 說明 | 使用時機 |
|---|---|---|
Code.AccessAzureKeyvault.All |
允許取得 Azure Key Vault 的存取權杖。 | 您的 Spark 程式碼會從 Azure Key Vault 取得秘密、金鑰或憑證。 |
Code.AccessAzureDataLake.All |
允許取得 Azure Data Lake Storage Gen1 的存取權杖。 | 你的 Spark 程式碼會從 Azure Data Lake Storage Gen1 帳號讀取或寫入。 |
Code.AccessAzureDataExplorer.All |
允許取得 Azure Data Explorer(Kusto)的存取令牌。 | 你的 Spark 程式碼查詢或從 Azure Data Explorer 叢集匯入資料。 |
Code.AccessSQL.All |
允許獲取 Azure SQL 的存取權杖。 | 你的 Spark 程式碼需要連接到 Azure SQL 資料庫。 |
注意
Lakehouse.Execute.All和Lakehouse.Read.All範疇也是必需的,但不屬於Code.*家族。 它們分別授權在 Fabric 數據湖屋中執行操作與讀取元資料。
如何發現 Fabric Livy API 端點
需要 Lakehouse 工件才能存取 Livy 端點。 建立 Lakehouse 之後,Livy API 端點就可以位於設定面板中。

Livy API 的端點會遵循下列模式:
https://api.fabric.microsoft.com/v1/workspaces/><ws_id>/lakehouses/<lakehouse_id>/livyapi/versions/2023-12-01/
根據您的選擇,URL 會附加<會話>或<批次>。
下載 Livy API Swagger 檔案
您可以在這裡取得 Livy API 的完整 Swagger 檔案。
高並行會話
高並行(HC)支援允許用戶端取得多個獨立執行上下文,稱為 高並行會話,從而實現Spark的同時執行。
每個 HC 會話代表一個邏輯執行上下文,該上下文對應至 Spark REPL(讀取-評估-輸出循環)。 不同 HC session 提交的 Spark 語句可同時執行。
這讓:
- 跨 HC 會話的平行執行
- 可預測的資源使用方式
- 並行請求之間的隔離
- 與每個請求建立新的工作階段相比,這種方法的開銷較低
使用單一會話處理所有請求會使語句依序執行。 為每個請求建立新工作階段會帶來不必要的開銷和資源利用率不足。
注意
HC 會話的獲取並非冪等性。 多個相同擷取請求會 sessionTag 回傳不同的 HC 會話 ID,即使它們是由同一底層 Livy 會話支持。
如需逐步示範範例程式碼,請參見 開始使用適用於 Fabric 高併發會話的 Livy API。 欲了解概念性概述,請參見Fabric Livy API中的高並發支援。
提交 Livy API 任務
現在 Livy API 的設定已完成,您可以選擇提交批次或會話作業。
與 Fabric 環境的整合
根據預設,此 Livy API 會話會針對工作區的預設起始集區執行。 另外,您可以使用 Fabric Environments Create、Configure,並在 Microsoft Fabric 中使用環境,以自訂 Livy API 會話所使用的 Spark 工作的 Spark 池配置。
若要在 Livy Spark 會話中使用 Fabric 環境,請更新 json 以包含此有效載荷。
create_livy_session = requests.post(livy_base_url, headers = headers, json={
"conf" : {
"spark.fabric.environmentDetails" : "{\"id\" : \""EnvironmentID""}"}
}
)
若要在 Livy Spark 批次會話中使用 Fabric 環境,請如此處更新 json 有效載荷:
payload_data = {
"name":"livybatchdemo_with"+ newlakehouseName,
"file":"abfss://YourABFSPathToYourPayload.py",
"conf": {
"spark.targetLakehouse": "Fabric_LakehouseID",
"spark.fabric.environmentDetails" : "{\"id\" : \""EnvironmentID"\"}" # Replace "EnvironmentID" with your environment ID, or remove this line to use starter pools instead of an environment
}
}
如何監視要求歷程記錄
您可以使用監視中樞來查看先前的 Livy API 提交,並偵錯任何提交錯誤。
