Hive 中繼存放區 (HMS) 移轉的初始步驟牽涉到決定您要傳輸的資料庫、資料表和資料分割。 不需要移轉所有項目;您可以選取特定資料庫。 識別要移轉的資料庫時,請務必確認是否有受控或外部Spark資料表。
如需 HMS 考慮,請參閱 Azure Synapse Spark 與 Fabric 之間的差異。
注意
或者,如果您的 ADLS Gen2 包含 Delta 資料表,您可以在 ADLS Gen2 中建立 Delta 資料表的 OneLake 捷徑。
必要條件
- 如果您還沒有 Fabric 工作區,請在您的租戶中建立一個 Fabric 工作區。
- 如果您還沒有,請在工作區中建立 Fabric Lakehouse。
選項 1:將 HMS 匯出和匯入至 lakehouse metastore
請遵循下列重要步驟進行移轉:
- 步驟 1:從來源 HMS 匯出中繼資料
- 步驟 2:將中繼資料匯入 Fabric Lakehouse
- 移轉後步驟:驗證內容
注意
腳本只會將 Spark 目錄物件複製到 Fabric Lakehouse。 假設資料已經複製(例如,從倉儲位置複製到 ADLS Gen2),或可用於 Managed 和外部資料表(例如,透過捷徑—偏好)複製到 Fabric Lakehouse。
步驟 1:從來源 HMS 匯出中繼資料
步驟 1 的重點在於將中繼資料從來源 HMS 匯出至 Fabric Lakehouse 的檔案 區段。 此程序如下:
1.1) 將 HMS 中繼資料匯出筆記本 匯入 Azure Synapse 工作區。 此筆記本 會查詢和匯出資料庫、資料表和資料分割的 HMS 中繼資料至 OneLake 中的中繼目錄(尚未包含的函式)。 此文稿會使用 Spark 內部目錄 API 來讀取目錄物件。
1.2) 在第一個命令中設定參數,以將中繼資料資訊匯出至中繼儲存體 (OneLake)。 下列代碼段是用來設定來源和目的地參數。 請務必用您自己的值取代這些值。
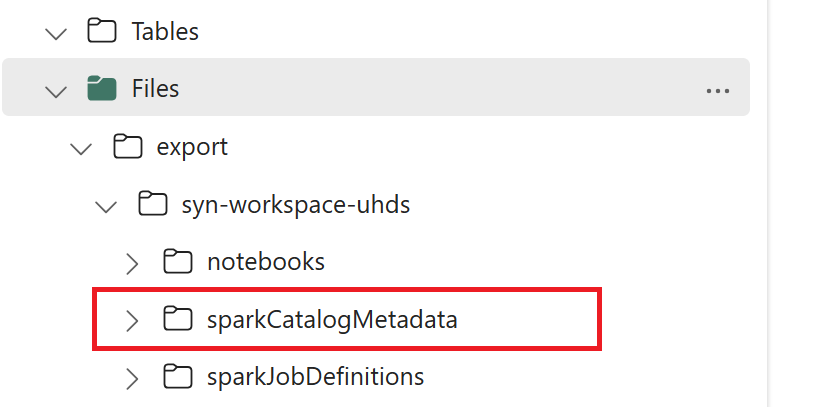
// Azure Synapse workspace config var SynapseWorkspaceName = "<synapse_workspace_name>" var DatabaseNames = "<db1_name>;<db2_name>" var SkipExportTablesWithUnrecognizedType:Boolean = false // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/"1.3) 執行所有筆記本命令 ,將目錄對象匯出至 OneLake。 一旦儲存格完成,就會建立中繼輸出目錄下的這個資料夾結構。

步驟 2:將中繼資料匯入 Fabric lakehouse
步驟 2 是將中繼儲存體中的中繼資料匯入到 Fabric Lakehouse。 此步驟的結果是將所有 HMS 中繼數據(資料庫、資料表和資料分割)移轉。 此程序如下:
2.1) 在 Lakehouse 的「檔案」區段 內建立捷徑。 此捷徑必須指向來源 Spark 倉儲目錄,稍後會用來取代 Spark 受控資料表。 請參閱指向 Spark 倉儲目錄的捷徑範例:
- Azure Synapse Spark 倉儲目錄的捷徑路徑:
abfss://<container>@<storage_name>.dfs.core.windows.net/synapse/workspaces/<workspace_name>/warehouse - Azure Databricks 倉儲目錄的捷徑路徑:
dbfs:/mnt/<warehouse_dir> - HDInsight Spark 倉儲目錄的捷徑路徑:
abfss://<container>@<storage_name>.dfs.core.windows.net/apps/spark/warehouse
- Azure Synapse Spark 倉儲目錄的捷徑路徑:
2.2)將 HMS 中繼資料匯入筆記本匯入至您的 Fabric 工作區。 匯 入此筆記本 ,以從中繼儲存體匯入資料庫、資料表和資料分割物件。 此腳本會使用 Spark 內部目錄 API,在 Fabric 中建立目錄物件。
2.3) 在第一個命令中設定參數。 在 Apache Spark 中,當您建立受控資料表時,該資料表的資料會儲存在 Spark 本身所管理的位置,通常是在 Spark 的倉儲目錄中。 確切的位置是由Spark決定。 這與外部資料表形成對比,您可以在其中指定位置和管理基礎資料。 當您移轉受管資料表的中繼資料時(不移動實際資料),中繼資料仍會包含指向舊 Spark 倉儲目錄的原始位置資訊。 因此,針對 Managed 資料表,
WarehouseMappings會使用步驟 2.1 中建立的捷徑來執行取代作業。 所有來源受控資料表都會使用此腳本轉換成外部資料表。LakehouseId是指在步驟 2.1 中建立的包含捷徑的 Lakehouse。// Azure Synapse workspace config var ContainerName = "<container_name>" var StorageName = "<storage_name>" var SynapseWorkspaceName = "<synapse_workspace_name>" // Fabric config var WorkspaceId = "<workspace_id>" var LakehouseId = "<lakehouse_id>" var ExportFolderName = f"export/${SynapseWorkspaceName}/sparkCatalogMetadata" var ShortcutName = "<warehouse_dir_shortcut_name>" var WarehouseMappings:Map[String, String] = Map( f"abfss://${ContainerName}@${StorageName}.dfs.core.windows.net/synapse/workspaces/${SynapseWorkspaceName}/warehouse"-> f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ShortcutName}" ) var OutputFolder = f"abfss://${WorkspaceId}@onelake.dfs.fabric.microsoft.com/${LakehouseId}/Files/${ExportFolderName}/" var DatabasePrefix = "" var TablePrefix = "" var IgnoreIfExists = true2.4) 執行所有 Notebook 命令 ,以從中繼路徑匯入目錄物件。
注意
匯入多個資料庫時,您可以為每個資料庫建立一個 Lakehouse(此處所使用的方法),或 (ii) 將所有資料表從不同的資料庫移至單一 Lakehouse。 對於後者,所有遷移的資料表可能是 <lakehouse>.<db_name>_<table_name>,因此你需要相應地修改匯入筆記本腳本。
步驟 3:驗證內容
步驟 3 是在驗證中繼資料是否已成功移轉的階段。 請參閱不同的範例。
您可以執行下列命令來檢視匯入的資料庫:
%%sql
SHOW DATABASES
您可以執行下列命令來檢查 Lakehouse (database) 中的所有資料表:
%%sql
SHOW TABLES IN <lakehouse_name>
您可以執行下列命令來檢視特定資料表的詳細資料:
%%sql
DESCRIBE EXTENDED <lakehouse_name>.<table_name>
或者,所有匯入的資料表都會顯示在每個 Lakehouse 的 Lakehouse 總管 UI 資料表區段中。

其他考量
- 延展性:此處的解決方案是使用內部 Spark 類別目錄 API 進行匯入/匯出,但不會直接連線到 HMS 以取得目錄物件,因此如果目錄很大,解決方案就無法正常調整。 您必須使用 HMS DB 來變更匯出邏輯。
- 資料精確度:沒有隔離保證,這表示如果Spark計算引擎在執行移轉筆記本時對中繼存放區進行並行修改,可以在 Fabric Lakehouse 中匯入不一致的資料。
相關內容
- 網狀架構與 Azure Synapse Spark
- 深入瞭解 Spark 集區、配置、函式庫、筆記本 及 Spark 作業定義 的移轉選項。