將 Spark 作業定義從 Azure Synapse 遷移至 Fabric
若要將 Spark 作業定義 (SJD) 從 Azure Synapse 移至 Fabric,您有兩個不同的選項:
- 選項 1:在 Fabric 中手動建立 Spark 作業定義。
- 選項 2:您可以使用腳本從 Azure Synapse 匯出 Spark 作業定義,並使用 API 在 Fabric 中匯入它們。
如需Spark作業定義考慮,請參閱 Azure Synapse Spark 與 Fabric 之間的差異。
必要條件
如果您還沒有網狀架構工作區,請在租使用者中建立 Fabric 工作區 。
選項 1:手動建立 Spark 作業定義
若要從 Azure Synapse 匯出 Spark 作業定義:
- 開啟 Synapse Studio:登入 Azure。 流覽至您的 Azure Synapse 工作區,然後開啟 Synapse Studio。
- 找出 Python/Scala/R Spark 作業:尋找並識別您想要移轉的 Python/Scala/R Spark 作業定義。
- 匯出工作定義群組態:
- 在 Synapse Studio 中,開啟 Spark 作業定義。
- 匯出或記下組態設定,包括腳本檔案位置、相依性、參數,以及任何其他相關詳細數據。
若要根據 Fabric 中導出的 SJD 資訊建立新的 Spark 作業定義 :.
- 存取網狀架構工作區:登入 Fabric 並存取您的工作區。
- 在 Fabric 中建立新的 Spark 作業定義:
- 在 [網狀架構] 中,移至 資料工程師 首頁。
- 選取 [Spark 作業定義]。
- 使用您從 Synapse 匯出的資訊來設定作業,包括腳本位置、相依性、參數和叢集設定。
- 調整和測試:對腳本或組態進行任何必要的調整,以符合 Fabric 環境。 在 Fabric 中測試作業,以確保作業正確執行。
建立 Spark 作業定義之後,請驗證相依性:
- 請確定使用相同的 Spark 版本。
- 驗證主要定義檔是否存在。
- 驗證參考檔案、相依性和資源是否存在。
- 鏈接的服務、數據源連線和裝入點。
深入瞭解如何在 Fabric 中建立 Apache Spark 作業定義 。
選項 2:使用網狀架構 API
請遵循下列重要步驟進行移轉:
- 必要條件。
- 步驟 1:將 Spark 作業定義從 Azure Synapse 導出至 OneLake (.json)。
- 步驟 2:使用網狀架構 API 自動將 Spark 作業定義匯入 Fabric。
必要條件
必要條件包括開始將 Spark 作業定義移轉至 Fabric 之前,您需要考慮的動作。
- 光纖工作區。
- 如果您還沒有,請在工作區中建立 Fabric Lakehouse 。
步驟 1:從 Azure Synapse 工作區匯出 Spark 作業定義
步驟 1 的重點在於以 json 格式將 Spark 作業定義從 Azure Synapse 工作區導出至 OneLake。 此程式如下所示:
- 1.1) 將 SJD 移轉筆記本匯入 Fabric 工作區。 此筆記本 會將所有Spark作業定義從指定的 Azure Synapse 工作區匯出至 OneLake 中的中繼目錄。 Synapse API 可用來匯出 SJD。
- 1.2) 在第一個命令中設定參數 ,將Spark作業定義匯出至中繼記憶體 (OneLake)。 這隻會匯出 json 元數據檔案。 下列代碼段是用來設定來源和目的地參數。 請務必以您自己的值取代它們。
# Azure config
azure_client_id = "<client_id>"
azure_tenant_id = "<tenant_id>"
azure_client_secret = "<client_secret>"
# Azure Synapse workspace config
synapse_workspace_name = "<synapse_workspace_name>"
# Fabric config
workspace_id = "<workspace_id>"
lakehouse_id = "<lakehouse_id>"
export_folder_name = f"export/{synapse_workspace_name}"
prefix = "" # this prefix is used during import {prefix}{sjd_name}
output_folder = f"abfss://{workspace_id}@onelake.dfs.fabric.microsoft.com/{lakehouse_id}/Files/{export_folder_name}"
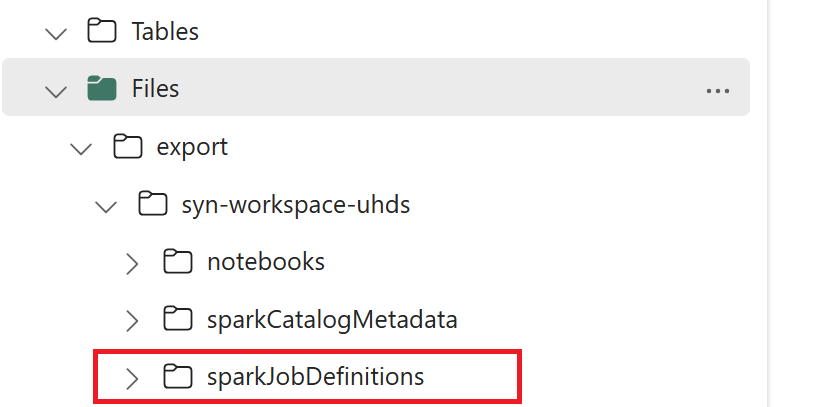
- 1.3) 執行匯出/匯入筆記本的前兩個數據格 ,將Spark作業定義元數據匯出至 OneLake。 一旦儲存格完成,就會建立中繼輸出目錄下的這個資料夾結構。
步驟 2:將 Spark 作業定義匯入 Fabric
步驟 2 是從中繼記憶體匯入 Spark 作業定義到 Fabric 工作區時。 此程式如下所示:
- 2.1) 驗證 1.2 中的組態 ,以確保會指出正確的工作區和前置詞以匯入 Spark 作業定義。
- 2.2) 執行匯出/匯入筆記本的第三個數據格 ,以從中繼位置匯入所有Spark作業定義。
注意
匯出選項會輸出 json 元數據檔案。 確定可從 Fabric 存取 Spark 作業定義可執行文件、參考檔案和自變數。