語意連結是一項功能,讓你能在 Microsoft Fabric 中建立 語意模型 與 Synapse Data Science 之間的連結。 語意連結僅支援於 Microsoft Fabric 中。
對於 Fabric Runtime 1.2(Spark 3.4)及以上版本,語意連結已在預設執行環境中提供,且不需要安裝。
要更新到最新版本的語意連結,請執行以下指令:
%pip install -U semantic-link
語意連結的主要目標為:
- 促進資料連線。
- 啟用語意資訊的傳播。
- 無縫整合資料科學家使用的既有工具,例如 筆記本。
語意連結可協助您以標準化的方式保留資料語意的相關領域知識,以加速資料分析並減少錯誤。
語意連結資料流程
語意連結資料流程從包含資料和語意資訊的語意模型開始。 語意連結橋接了 Power BI 與 Synapse 資料科學體驗之間的橋樑。
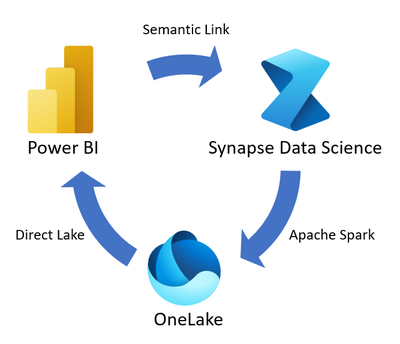
語意連結允許你在 Synapse 資料科學體驗中使用 Power BI 的語意模型,執行深入的統計分析與機器學習技術預測建模等任務。 你可以使用 Apache Spark 將資料科學成果儲存到
Power BI 連線
語意模型作為單一的表格物件模型提供可靠的語意定義來源,例如Power BI度量。 語意連結會連線到下列生態系統中的語意模型,讓資料科學家可以輕鬆地在最熟悉的系統中工作。
- Python pandas 生態系統,透過 SemPy Python 函式庫。
- Apache Spark 生態系統,透過 Apache Spark 原生連接器。 此實作支援各種語言,包括 PySpark、Spark SQL、R 及 Scala。
語意資訊的應用
資料中的語意資訊包括Power BI 資料類別,例如地址與郵遞區號、資料表間的關係,以及階層資訊。
這些資料類別包含透過語意連結傳遞到 Synapse 資料科學環境中的中繼資料,以促成新的使用體驗並維護資料血統。
語意連結的一些範例應用程式包括:
- 智慧建議的內建語意功能。
- 創新整合,透過使用 add-measures 增強 Power BI 度量值。
- 基於資料表間關係及資料表內功能依賴關係進行資料 品質驗證 的工具。
語意連結是功能強大的工具,可讓商務分析師在完整的資料科學環境中有效地使用資料。
語意連結促進資料科學家與業務分析師之間的無縫協作,免除了重新實作嵌入於Power BI度量中的商業邏輯。 這種方法可確保雙方都能高效且具有生產力地運作,以最大化其資料驅動深入解析的潛力。
FabricDataFrame 資料結構
FabricDataFrame 是語意連結用來將語意模型的語意資訊傳播到 Synapse 資料科學環境的主要資料結構。

FabricDataFrame 類別:
- 支援所有 pandas 操作。
- 將 pandas DataFrame 子類別,並加入元資料,如語意資訊與血統。
- 揭示語意函數及add-measure方法,讓你能在資料科學工作中使用 Power BI 度量。
相關內容
- 探索 Python 語意連結套件(SemPy)的參考文件
- 教學課程:使用功能相依性清理資料
Power BI 與語意連結以及 Microsoft Fabric 的連結性 - 藉由語意連結來探索和驗證資料
- 探索並驗證語意模型中的關聯性