使用功能相依性來清理資料。 當語意模型 (Power BI 資料集) 中的一個資料行相依於另一個資料行時,就會存在功能相依性。 例如,直 ZIP code 欄可以決定直欄中的 city 值。 功能相依關係會顯示為 中兩個或多個資料行 DataFrame中值之間的一對多關係。 本教學課程使用 Synthea 資料集來示範功能相依性如何協助偵測資料品質問題。
在本教學課程中,您將瞭解如何:
- 應用領域知識在語義模型中形成有關功能依賴關係的假設。
- 熟悉語意連結 Python 程式庫 (SemPy) 的元件,以自動化資料品質分析。 這些元件包括:
-
FabricDataFrame——一種類似熊貓的結構,具有額外的語義信息。 - 自動評估有關功能相依性的假設並識別語意模型中的違規的函數。
-
先決條件
取得 Microsoft Fabric 訂用帳戶。 或者,註冊免費 Microsoft Fabric 試用版。
登入 Microsoft Fabric。
使用首頁左下角的體驗切換器切換到 Fabric。

- 在導覽窗格中選取 [工作區] ,然後選取您的工作區以將其設定為目前的工作區。
在筆記本中跟隨
使用 data_cleaning_functional_dependencies_tutorial.ipynb 筆記本來遵循本教學課程。
若要開啟本教學課程隨附的筆記本,請依照 中的指示準備您的系統以進行數據科學教學課程,然後在 中將筆記本匯入您的工作區。
如果您要複製並貼上此頁面中的程式碼,您可以 建立新的筆記本。
請務必先 將 Lakehouse 附加至筆記本 ,再開始執行程式碼。
設定筆記本
在本節中,您會設定筆記本環境。
檢查您的 Spark 版本。 如果您在 Microsoft Fabric 中使用 Spark 3.4 或更新版本,預設會包含語意連結,因此您不需要安裝它。 如果您使用 Spark 3.3 或更早版本,或想要更新至最新的語意連結,請執行下列命令。
%pip install -U semantic-link匯入您在此筆記本中使用的模組。
import pandas as pd import sempy.fabric as fabric from sempy.fabric import FabricDataFrame from sempy.dependencies import plot_dependency_metadata下載範例資料。 在本教學課程中,使用合成醫療記錄的 Synthea 資料集 (為了簡單起見,小版本)。
download_synthea(which='small')
探索數據
使用
FabricDataFrame檔案的內容初始化 a。providers = FabricDataFrame(pd.read_csv("synthea/csv/providers.csv")) providers.head()通過繪製自動檢測到的功能依賴關係的圖表來檢查 Sempy 函數
find_dependencies的數據質量問題。deps = providers.find_dependencies() plot_dependency_metadata(deps)
該圖顯示決定
IdNAME和ORGANIZATION。 這個結果是預期的,因為Id是唯一的。確認這是
Id唯一的。providers.Id.is_unique程式代碼會傳回
True,以確認Id是唯一的。

深入分析功能相依性
功能相依性圖表也會顯示 ORGANIZATION 會如預期決定 ADDRESS 和 ZIP。 不過,您可能預期 ZIP 也會判斷 CITY,但虛線箭號表示相依性只是近似值,指向數據質量問題。
圖表中有其他特殊之處。 例如,NAME 不會判斷 GENDER、Id、SPECIALITY或 ORGANIZATION。 這些特點可能值得調查。
- 透過使用 SemPy 的
ZIP函數列出違規行為,更深入地了解 和CITY之間的list_dependency_violations近似關係:
providers.list_dependency_violations('ZIP', 'CITY')
- 使用 SemPy 的
plot_dependency_violations視覺效果函式繪製圖表。 如果違規數目很小,此圖表會很有説明:
providers.plot_dependency_violations('ZIP', 'CITY')
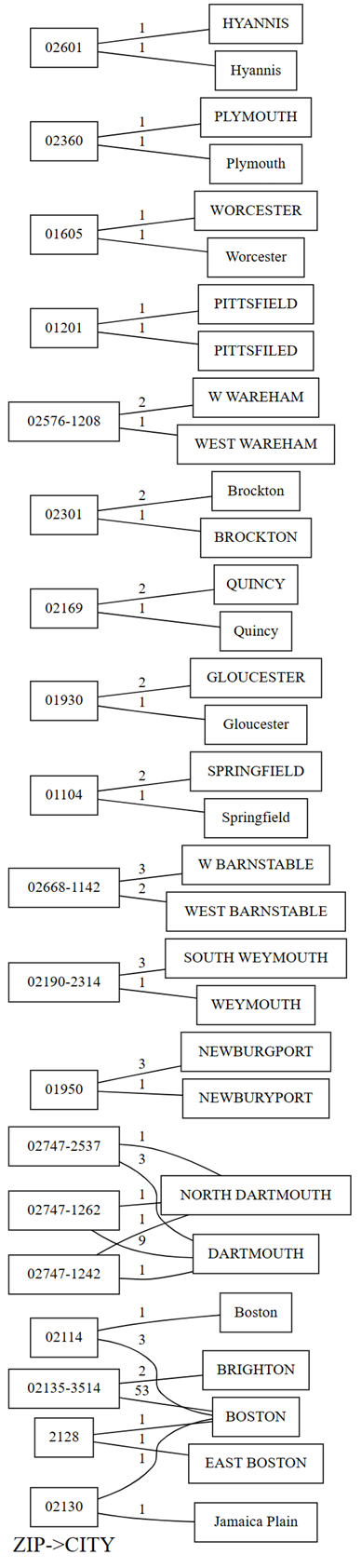
相依關係違規的圖形在左側顯示 的值,在右側顯示 的 ZIP 值 CITY 。 如果有包含這兩個值的數據列,邊緣會將繪圖左側的郵遞區編碼與右側的城市連接起來。 邊緣會以此類列的計數進行註釋。 例如,有兩個資料列的郵遞區號為02747-1242,一個資料列所屬城市為 "NORTH DARTHMOUTH",另一個資料列的城市為 "DARTHMOUTH",如前面的圖示及以下的程式碼所顯示。
- 通過運行以下代碼來確認圖中的觀察結果:
providers[providers.ZIP == '02747-1242'].CITY.value_counts()
該圖還顯示,在具有“DARTHMOUTH”的行
CITY中,有九行的 aZIP為 02747-1262。 一行的 aZIP是 02747-1242。 一行的 aZIP是 02747-2537。 使用以下程式碼確認這些觀察結果:providers[providers.CITY == 'DARTHMOUTH'].ZIP.value_counts()還有其他與「DARTMOUTH」相關的郵遞區號,但這些郵遞區號不會顯示在依賴違規圖表中,因為它們不會暗示資料品質問題。 例如,郵遞區號「02747-4302」與「DARTMOUTH」唯一相關聯,不會顯示在相依性違規圖表中。 執行下列程式代碼來確認:
providers[providers.ZIP == '02747-4302'].CITY.value_counts()
摘要說明使用 SemPy 偵測到的數據質量問題
相依性違規圖表顯示此語意模型中的數個資料品質問題:
- 有些城市名稱是大寫的。 使用字串方法來修正此問題。
- 某些城市名稱有限定符(或前置詞),例如 “North” 和 “East”。 例如,郵遞區號 “2128” 對應到 “EAST BOSTON” 一次,對應到 “BOSTON” 一次。 「北達特茅斯」和「達特茅斯」之間也出現了類似的問題。 刪除這些限定詞或將郵遞區號映射到最常見的城市。
- 一些城市名稱存在拼字錯誤,例如“PITTSFIELD”與“PITTSFILED”以及“NEWBURGPORT”與“NEWBURYPORT”。對於“NEWBURGPORT”,使用最常見的情況來修復此拼寫錯誤。 對於“PITTSFIELD”,每個只有一次出現,如果沒有外部知識或語言模型,自動消歧義要困難得多。
- 有時,像“West”這樣的前綴縮寫為單個字母“W”。如果所有出現的“W”都代表“West”,請將“W”替換為“West”。
- 郵政編碼 “02130” 對應一次 “BOSTON” 和 “Jamaica Plain” 一次。 這個問題並不容易解決。 使用更多資料,對應至最常見的事件。
清除數據
將值變更為標題大小寫,以修正大小寫。
providers['CITY'] = providers.CITY.str.title()再次執行違規偵測,以確認不明確的情況較少。
providers.list_dependency_violations('ZIP', 'CITY')
手動細化數據,或使用 SemPy 的 drop_dependency_violations 函數刪除違反列之間功能約束的行。
對於行列式變數的每一個值, drop_dependency_violations 挑選應變數的最常見值,並捨棄具有其他值的所有列。 只有在您確信此統計啟發式方法會導致資料的正確結果時,才套用此作業。 否則,請撰寫您自己的程式碼來處理偵測到的違規行為。
在 和
drop_dependency_violations資料行上ZIP執行CITY函式。providers_clean = providers.drop_dependency_violations('ZIP', 'CITY')列出 和
ZIP之間的CITY任何相依性違規。providers_clean.list_dependency_violations('ZIP', 'CITY')
程式碼會傳回一個空清單,以指出不再有違反功能約束 ZIP -> CITY的行為。
相關內容
請參閱語義連結或 Sempy 的其他教學課程: