ملاحظة
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
ينطبق على: Azure Data Factory Azure Synapse Analytics
Azure Data Factory Azure Synapse Analytics
تلميح
جرب Data Factory في Microsoft Fabric، وهو حل تحليلي متكامل للمؤسسات. يغطي Microsoft Fabric كل شيء بدءا من حركة البيانات إلى علم البيانات والتحليلات في الوقت الحقيقي والمعلومات المهنية وإعداد التقارير. تعرف على كيفية بدء إصدار تجريبي جديد مجانا!
توضح هذه المقالة كيفية استخدام نشاط النسخ في مصنع بيانات Azure وAzure Synapse لنسخ البيانات من وإلى Azure Databricks Delta Lake. تعتمد هذه المقالة على مقالة نشاط النسخ التي تقدم نظرة عامة على نشاط النسخ.
القدرات المدعومة
يُدعم موصّل Azure Databricks Delta Lake هذا لغرض الأنشطة التالية:
| القدرات المدعومة | IR |
|---|---|
| Copy activity (المصدر/المتلق) | (1) (2) |
| تعيين تدفق البيانات (المصدر/ المتلقي) | (1) |
| نشاط البحث | (1) (2) |
① وقت تشغيل تكامل Azure ② وقت تشغيل التكامل المستضاف ذاتيًا
بشكل عام، تُدعم الخدمة Delta Lake بالقدرات التالية لتلبية احتياجاتك المختلفة.
- يَدعم نشاط النسخ موصل Azure Databricks Delta Lake لنسخ البيانات من أي مخزن بيانات مصدر مدعوم إلى جدول Azure Databricks delta lake ومنه إلى أي مخزن بيانات مصدر مدعوم. وهو يستفيد من كتلة Databricks الخاص لتنفيذ حركة البيانات، انظر التفاصيل في قسم المتطلبات الأساسية.
- تعيين تدفق البيانات يدعم تنسيق Delta العام على Azure Storage كمصدر ومتلقٍ لقراءة وكتابة ملفات Delta لـETL الخالية من التعليمات البرمجية، ويعمل على وقت تشغيل تكامل Azure المدار.
- تدعم أنشطة Databricks تنسيق ETL الذي يركز على التعليمات البرمجية أو حمل عمل التعلم الآلي على قمة delta lake.
المتطلبات الأساسية
لاستخدام Azure Databricks Delta Lake هذا، تحتاج إلى إعداد مقطع تخزين في Azure Databricks.
- لنسخ البيانات إلى delta lake، استدعِ نشاط النسخ لمجموعة تخزين Azure Databricks لقراءة البيانات من Azure Storage، وهو إما المصدر الأصلي أو منطقة التقسيم المرحلي حيث تكتب الخدمة أولاً البيانات المصدر عبر نسخة مرحلية مضمنة. تعرف على المزيد من Delta lake كمتلقٍ.
- وبالمثل، لنسخ البيانات من delta lake، استدعِ نشاط النسخ لمجموعة تخزين Azure Databricks لكتابة البيانات إلى Azure Storage، وهو إما متلقٍ أصلي أو منطقة التقسيم المرحلي حيث تستمر الخدمة في كتابة البيانات إلى المتلقي النهائي عبر النسخة المرحلية المضمنة. تعرف على المزيد من Delta lake كمصدر.
تحتاج مجموعة تخزين Databricks الوصول إلى حساب Azure Blob or Azure Data Lake Storage Gen2، وكلٍّ من حاوية التخزين / نظام الملفات المستخدمة للمصدر / للمتلقي / للتقسيم المرحلي، ونظام الحاوية / الملف حيث تريد كتابة جداول Delta Lake.
لاستخدام Azure Data Lake Storage Gen2، يمكنك تكوين أساس خدمة على مجموعة تخزين Databricks كجزء من تكوين Apache Spark. اتبع الخطوات الموجودة في الوصول مباشرة مع كيان الخدمة.
لاستخدام Azure Blob storage، يمكك تكوين مفتاح وصول لحساب التخزين أو رمز SAS المميز على مجموعة تخزين Databricks كجزء من تكوين Apache Spark. اتبع الخطوات في Access Azure Blob storage باستخدام RDD API.
أثناء تنفيذ نشاط النسخ، إذا انتهت مجموعة التخزين الكتلة التي كوّنتها، فإن الخدمة تبدأ تلقائياً. إذا ألّفت مساراً باستخدام واجهة المستخدم التأليف، لعمليات مثل معاينة البيانات، ستحتاج إلى أن يكون لديك مجموعة تخزين نشطة، وإلا فلن تبدأ خدمة مجموعة التخزين نيابة عنك.
تحديد تكوين نظام المجموعة
في القائمة المنسدلة Cluster Mode حدد Standard.
في القائمة المنسدلة Databricks Runtime Version حدد "Databricks runtime version".
شغّل Auto Optimize بإضافة الخصائص التالية إلى تكوين Spark:
spark.databricks.delta.optimizeWrite.enabled true spark.databricks.delta.autoCompact.enabled trueكون مجموعتك التخزينية بناء على احتياجاتك للتكامل والتحجيم.
للحصول على تفاصيل تكوين مجموعة التخزين، راجع تكوين مجموعة التخزين.
الشروع في العمل
لتنفيذ نشاط النسخ باستخدام أحد المسارات، يمكنك استخدام إحدى الأدوات أو عدد تطوير البرامج التالية:
- أداة نسخ البيانات
- مدخل Azure
- The .NET SDK
- عدة تطوير برامج Python
- Azure PowerShell
- واجهة برمجة تطبيقات REST
- قالب Azure Resource Manager
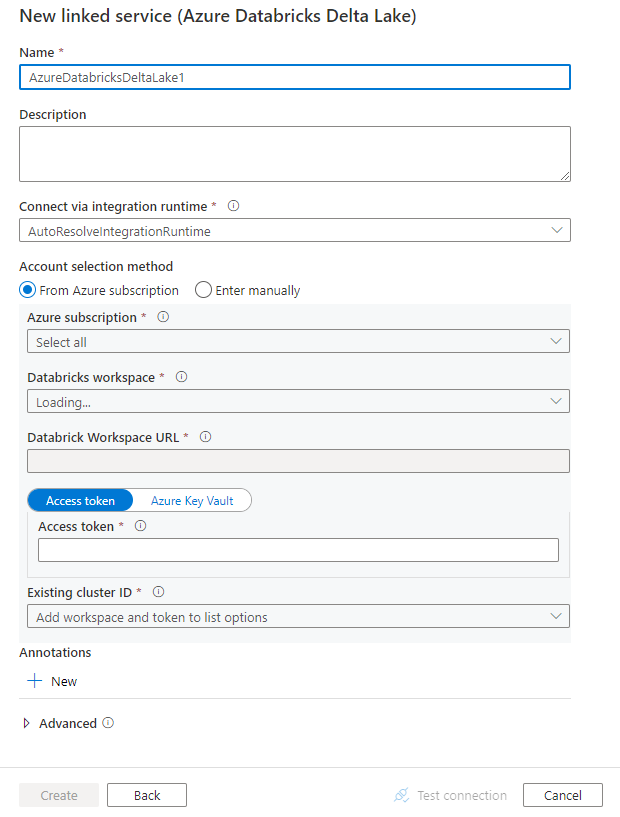
أنشئ خدمة مرتبطة بـ Azure Databricks Delta Lake باستخدام واجهة المستخدم
استخدم الخطوات التالية لإنشاء خدمة مرتبطة إلى Azure DatabricksAzure Databricks Delta Lake في واجهة مستخدم مدخل Azure.
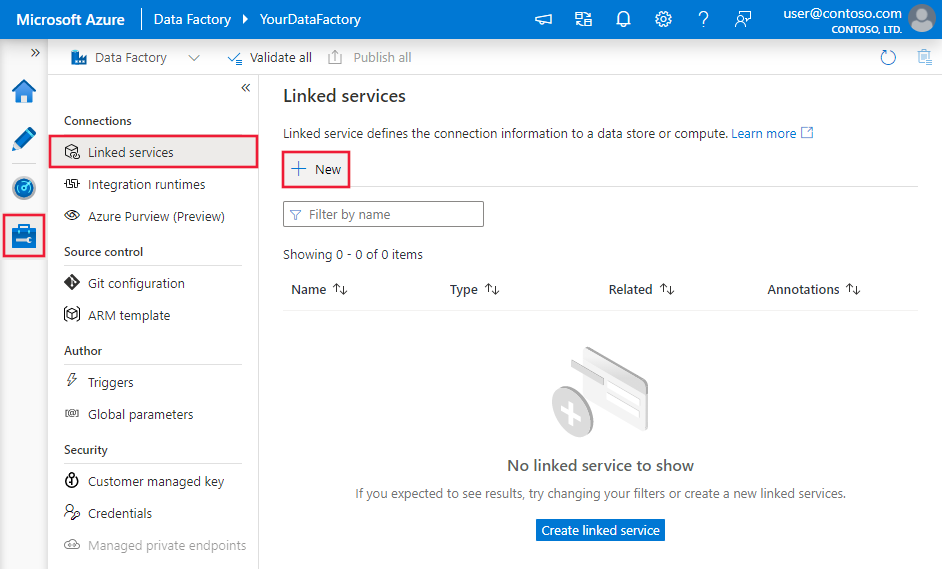
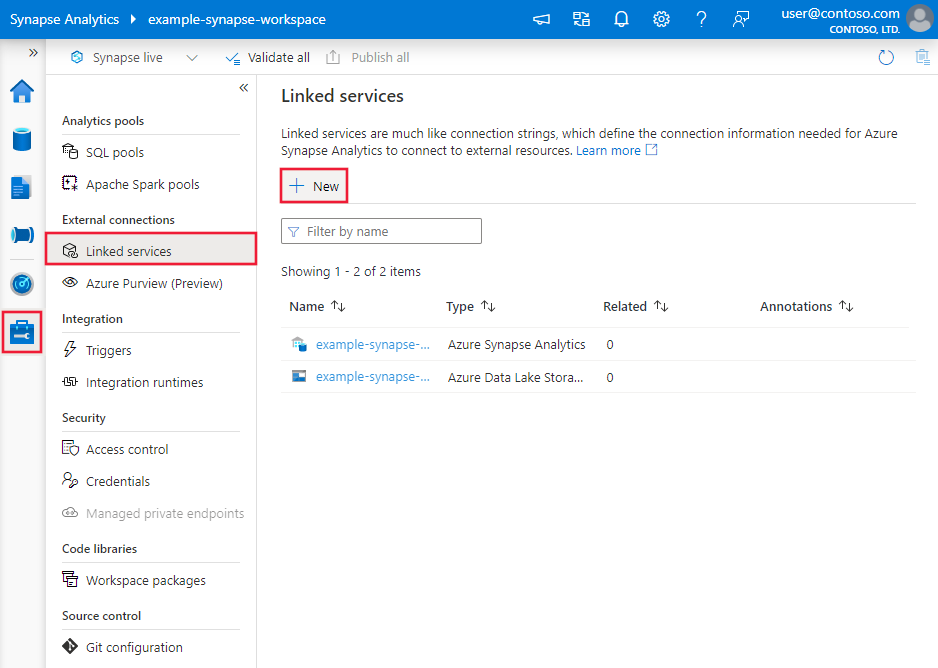
استعرض للوصول إلى علامة التبويب "Manage" في مصنع بيانات Azure أو مساحة عمل Synapse، وحدد "Linked Services"، ثم انقر فوق "New":
ابحث عن delta وحدد موصل Azure Databricks Delta Lake.

قم بتكوين تفاصيل الخدمة، واختبر الاتصال، وأنشئ الخدمة المرتبطة الجديدة.
تفاصيل تكوين الموصل
توفر المقاطع التالية تفاصيل حول الخصائص المستخدمة لتعريف كيانات خاصة بموصل Azure Databricks Delta Lake.
خصائص الخدمة المرتبطة
يدعم موصّل Azure Databricks Delta Lake أنواع المصادقة التالية. راجع الأقسام المقابلة للاطلاع على التفاصيل.
- الرمز المميز للوصول
- مصادقة الهوية المدارة المعينة من قبل النظام
- مصادقة الهوية المدارة المعينة من قبل المستخدم
الرمز المميز للوصول
تُدعم الخصائص التالية لغرض خدمة Azure Databricks Delta Lake ذات الصلة.
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية النوع إلى: AzureDatabricksDeltaLake. | نعم |
| المجال | حدد عنوان URL لمساحة عمل Azure Databricks، على سبيل المثال https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
|
| clusterId | حدد معرف نظام مجموعة التخزين من مجموعة التخزين الحالية. يجب أن تكون مجموعة التخزين المنشأة مسبقاً مجموعة تفاعلية. يمكنك العثور على مُعرّف نظام المجموعة لمجموعة تفاعلية على مساحة عمل Databricks -> Clusters -> Interactive Cluster Name -> Configuration -> Tags. اعرف المزيد. |
|
| accessToken | الرمز المميز للوصول مطلوب للخدمة للمصادقة على Azure Databricks. يجب إنشاء الرمز المميز للوصول من مساحة عمل databricks. يمكن العثور على مزيد من الخطوات التفصيلية للعثور على الرمز المميز للوصول هنا. | |
| connectVia | يُستخدم وقت تشغيل التكامل للاتصال بمخزن البيانات. يمكنك استخدام Azure Integration Runtime أو وقت تشغيل التكامل المستضاف ذاتياً (إذا كان مخزن بياناتك في شبكة اتصال خاصة). إذا لم يكن محدداً، فإنه يستخدم وقت تشغيل تكامل Azure الافتراضي. | لا |
مثال:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"accessToken": {
"type": "SecureString",
"value": "<access token>"
}
}
}
}
مصادقة الهوية المدارة المعينة من قبل النظام
لمعرفة المزيد حول الهويات المُدارة المعينة من قبل النظام لموارد Azure، راجع الهوية المُدارة المعينة من النظام لموارد Azure.
لاستخدام مصادقة الهوية المدارة المعينة من قبل النظام، اتبع الخطوات التالية لمنح الأذونات:
استردّ معلومات الهوية المُدارة من خلال نسخ قيمة معرّف عنصر الهوية المدارة الذي تم إنشاؤه جنبًا إلى جنب مع بيانات المصنع الخاصة بك أو مساحة عمل Synapse.
امنح الهوية المُدارة الأذونات الصحيحة في Azure Data Explorer. بشكل عام، يجب منح دور المساهم على الأقل للهوية المُدارة المعينة من النظام في Access control (IAM) لـ Azure Databricks.
تُدعم الخصائص التالية لغرض خدمة Azure Databricks Delta Lake ذات الصلة.
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية النوع إلى: AzureDatabricksDeltaLake. | نعم |
| المجال | حدد عنوان URL لمساحة عمل Azure Databricks، على سبيل المثال https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
نعم |
| clusterId | حدد معرف نظام مجموعة التخزين من مجموعة التخزين الحالية. يجب أن تكون مجموعة التخزين المنشأة مسبقاً مجموعة تفاعلية. يمكنك العثور على مُعرّف نظام المجموعة لمجموعة تفاعلية على مساحة عمل Databricks -> Clusters -> Interactive Cluster Name -> Configuration -> Tags. اعرف المزيد. |
نعم |
| workspaceResourceId | حدد معرّف مورد مساحة العمل لـ Azure Databricks. | نعم |
| connectVia | يُستخدم وقت تشغيل التكامل للاتصال بمخزن البيانات. يمكنك استخدام Azure Integration Runtime أو وقت تشغيل التكامل المستضاف ذاتياً (إذا كان مخزن بياناتك في شبكة اتصال خاصة). إذا لم يكن محدداً، فإنه يستخدم وقت تشغيل تكامل Azure الافتراضي. | لا |
مثال:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
مصادقة الهوية المدارة المعينة من قبل المستخدم
لمزيد من المعلومات حول الهويات المُدارة المعينة من المستخدم لموارد Azure، راجع user-assigned managed identities
لاستخدام مصادقة الهوية المدارة المعينة من قبل المستخدم اتبع الخطوات التالية:
إنشاء هوية مدارة واحدة أو متعددة من المستخدمين ومنح الإذن في Azure Databricks. بشكل عام، يجب منح دور المساهم على الأقل للهوية المُدارة المعينة من المستخدم في Access control (IAM) لـ Azure Databricks.
تعيين هوية مدارة معينة من قبل مستخدم واحد أو متعدد إلى مصنع البيانات أو مساحة عمل Synapse وإنشاء بيانات اعتماد لكل هوية مدارة معينة من قبل المستخدم.
تُدعم الخصائص التالية لغرض خدمة Azure Databricks Delta Lake ذات الصلة.
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية النوع إلى: AzureDatabricksDeltaLake. | نعم |
| المجال | حدد عنوان URL لمساحة عمل Azure Databricks، على سبيل المثال https://adb-xxxxxxxxx.xx.azuredatabricks.net. |
نعم |
| clusterId | حدد معرف نظام مجموعة التخزين من مجموعة التخزين الحالية. يجب أن تكون مجموعة التخزين المنشأة مسبقاً مجموعة تفاعلية. يمكنك العثور على مُعرّف نظام المجموعة لمجموعة تفاعلية على مساحة عمل Databricks -> Clusters -> Interactive Cluster Name -> Configuration -> Tags. اعرف المزيد. |
نعم |
| بيانات الاعتماد | حدد الهوية المدارة المعينة من قبل المستخدم ككائن بيانات الاعتماد. | نعم |
| workspaceResourceId | حدد معرّف مورد مساحة العمل لـ Azure Databricks. | نعم |
| connectVia | يُستخدم وقت تشغيل التكامل للاتصال بمخزن البيانات. يمكنك استخدام Azure Integration Runtime أو وقت تشغيل التكامل المستضاف ذاتياً (إذا كان مخزن بياناتك في شبكة اتصال خاصة). إذا لم يكن محدداً، فإنه يستخدم وقت تشغيل تكامل Azure الافتراضي. | لا |
مثال:
{
"name": "AzureDatabricksDeltaLakeLinkedService",
"properties": {
"type": "AzureDatabricksDeltaLake",
"typeProperties": {
"domain": "https://adb-xxxxxxxxx.xx.azuredatabricks.net",
"clusterId": "<cluster id>",
"credential": {
"referenceName": "credential1",
"type": "CredentialReference"
},
"workspaceResourceId": "<workspace resource id>"
},
"connectVia": {
"referenceName": "<name of Integration Runtime>",
"type": "IntegrationRuntimeReference"
}
}
}
خصائص مجموعة البيانات
للحصول على قائمة كاملة بالأقسام والخصائص المتوفرة لتعريف مجموعات البيانات، راجع مقالة مجموعات البيانات.
تُدعم الخصائص التالية لمجموعة بيانات Azure Databricks Delta Lake.
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية نوع مجموعة البيانات إلى AzureDatabricksDeltaLakeDataset. | نعم |
| قاعدة بيانات | اسم قاعدة البيانات. | لا للمصدر، نعم للمتلقي |
| طاولتنا | اسم جدول delta. | لا للمصدر، نعم للمتلقي |
مثال:
{
"name": "AzureDatabricksDeltaLakeDataset",
"properties": {
"type": "AzureDatabricksDeltaLakeDataset",
"typeProperties": {
"database": "<database name>",
"table": "<delta table name>"
},
"schema": [ < physical schema, optional, retrievable during authoring > ],
"linkedServiceName": {
"referenceName": "<name of linked service>",
"type": "LinkedServiceReference"
}
}
}
انسخ خصائص النشاط
للحصول على قائمة كاملة بالأقسام والخصائص المتوفرة لتعريف الأنشطة، راجع مقالة التدفقات. يوفر هذا المقطع قائمة من الخصائص المدعومة من قِبَل المصدر والمتلقي في Azure Databricks Delta Lake.
Delta lake كمصدر
لنسخ البيانات من Azure Databricks Delta Lake، تُدعم الخصائص التالية في قسم مصدر نشاط النسخ.
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | يجب تعيين خاصية نوع مصدر نشاط النسخ إلى AzureDatabricksDeltaLakeSource. | نعم |
| استعلام | حدد استعلام SQL لقراءة البيانات. للتحكم في السفر عبر الزمن، اتبع النمط أدناه: - SELECT * FROM events TIMESTAMP AS OF timestamp_expression- SELECT * FROM events VERSION AS OF version |
لا |
| exportSettings | إعدادات متقدمة تستخدم لاسترداد البيانات من جدول delta. | لا |
تحت exportSettings: |
||
| النوع | نوع أمر التصدير، عيّنه إلىAzureDatabricksDeltaLakeExportCommand. | نعم |
| dateFormat | نسّق نوع التاريخ إلى سلسلة بتنسيق تاريخ. تتبع تنسيقات التاريخ المخصص التنسيقات في datetime pattern. إذا لم يكن محدداً، فإنه يستخدم القيمة الافتراضية yyyy-MM-dd. |
لا |
| timestampFormat | نسّق نوع الطابع الزمني إلى سلسلة بتنسيق الطابع الزمني. تتبع تنسيقات التاريخ المخصص التنسيقات في datetime pattern. إذا لم يكن محدداً، فإنه يستخدم القيمة الافتراضية yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]. |
لا |
النسخ المباشر من delta lake
إذا كان مخزن البيانات المتلقي والتنسيق يفيان بالمعايير الموضحة في هذا القسم، يمكنك استخدام نشاط النسخ للنسخ المباشر من جدول Azure Databricks Delta إلى المتلقي. تتحقق الخدمة من الإعدادات وتفشل في تشغيل نشاط النسخ إذا لم تُستوف المعايير التالية:
خدمة المتلقي المرتبطة هيAzure Blob storage أو Azure Data Lake Storage Gen2. يجب أن تكون بيانات اعتماد الحساب مكونة مسبقاً في تكوين مجموعة تخزين Azure Databricks، تعرف على المزيد من الشروط الأساسية.
تنسيق بيانات المتلقي يكون من Parquet، delimited text، أو Avro مع التكوينات التالية، ويشير إلى مجلد بدلاً من الملف.
- لتنسيق Parquet يكون ترميز الضغط none، snappy، أو gzip.
- لتنسيق النص المحدد:
-
rowDelimiterأي حرف واحد. -
compressionيمكن أن يكون none، bzip2، gzip. -
encodingNameUTF-7 غير مدعوم.
-
- لتنسيق Avro يكون ترميز الضغط none، deflate، أوsnappy.
في مصدر نشاط النسخ،
additionalColumnsهو غير محدد.إذا كان نسخ البيانات إلى نص محدد، في متلقي نشاط النسخ،
fileExtensionيجب أن يكون ".csv".في تعيين نشاط النسخ، لا يُمكن تحويل النوع.
مثال:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
}
}
}
]
نسخة مرحلية من delta lake
عندما لا يتطابق مخزن البيانات المصدر أو تنسيقه مع معايير النسخ المباشر، كما هو مذكور في القسم الأخير، مكّن النسخة المرحلية المضمنة باستخدام مثيل تخزين Azure مؤقت. توفر لك ميزة النسخ المرحلي أيضاً إنتاجية أفضل. تصدر الخدمة البيانات من Azure Databricks Delta Lake إلى التخزين المرحلي، ثم تنسخ البيانات للمتلقي، ثم تمسح أخيراً البيانات المؤقتة من التخزين المرحلي. راجع نسخة مرحلية للحصول على تفاصيل حول نسخ البيانات باستخدام التقسيم المرحلي.
لاستخدام هذه الميزة، أنشئ خدمة تخزين Azure Blob المرتبطة أو خدمة Azure Data Lake Storage Gen2 المرتبطة التي تشير إلى حساب التخزين كتقسيم مرحلي مؤقت. ثم حدد enableStaging وstagingSettings الخصائص في نشاط النسخ.
إشعار
يجب أن تكون بيانات اعتماد حساب تخزين التقسيم المرحلي مكونة مسبقاً في تكوين مجموعة تخزين Azure Databricks، تعرف على المزيد من الشروط الأساسية.
مثال:
"activities":[
{
"name": "CopyFromDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<Delta lake input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "AzureDatabricksDeltaLakeSource",
"sqlReaderQuery": "SELECT * FROM events TIMESTAMP AS OF timestamp_expression"
},
"sink": {
"type": "<sink type>"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingStorage",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
Delta lake كمتلقٍ
لنسخ البيانات إلى Azure Databricks Delta Lake، تُدعم الخصائص التالية في قسم مصدر نشاط النسخ.
| الخاصية | الوصف | مطلوب |
|---|---|---|
| النوع | خاصية نوع مصدر نشاط النسخ، عّين إلى AzureDatabricksDeltaLakeSink. | نعم |
| preCopyScript | حدد استعلام SQL لنشاط النسخ لتنفيذه قبل كتابة البيانات في Databricks delta table في كل تشغيل. مثال: VACUUM eventsTable DRY RUN يمكنك استخدام هذه الخاصية لتنظيف البيانات المحملة مسبقاً، أو إضافة جدول اقتطاع أو عبارة فراغ. |
لا |
| importSettings | إعدادات متقدمة تستخدم لكتابة البيانات في جدول delta. | لا |
تحت importSettings: |
||
| النوع | نوع أمر الاستيراد، عيّنه إلىAzureDatabricksDeltaLakeExportCommand. | نعم |
| dateFormat | نسّق السلسلة إلى نوع التاريخ بتنسيق تاريخ. تتبع تنسيقات التاريخ المخصص التنسيقات في datetime pattern. إذا لم يكن محدداً، فإنه يستخدم القيمة الافتراضية yyyy-MM-dd. |
لا |
| timestampFormat | نسّق السلسلة إلى نوع الطابع الزمني بتنسيق الطابع الزمني. تتبع تنسيقات التاريخ المخصص التنسيقات في datetime pattern. إذا لم يكن محدداً، فإنه يستخدم القيمة الافتراضية yyyy-MM-dd'T'HH:mm:ss[.SSS][XXX]. |
لا |
النسخ المباشر إلى delta lake
إذا كان مخزن البيانات المتلقي والتنسيق يفيان بالمعايير الموضحة في هذا القسم، يمكنك استخدام نشاط النسخ للنسخ المباشر من المصدر إلىAzure Databricks Delta. تتحقق الخدمة من الإعدادات وتفشل في تشغيل نشاط النسخ إذا لم تُستوف المعايير التالية:
خدمة المصدر المرتبطة هيAzure Blob storage أو Azure Data Lake Storage Gen2. يجب أن تكون بيانات اعتماد الحساب مكونة مسبقاً في تكوين مجموعة تخزين Azure Databricks، تعرف على المزيد من الشروط الأساسية.
تنسيق بيانات المصدر يكون من Parquet، delimited text، أو Avro مع التكوينات التالية، ويشير إلى مجلد بدلاً من الملف.
- لتنسيق Parquet يكون ترميز الضغط none، snappy، أو gzip.
- لتنسيق النص المحدد:
-
rowDelimiterهو افتراضي، أو أي حرف واحد. -
compressionيمكن أن يكون none، bzip2، gzip. -
encodingNameUTF-7 غير مدعوم.
-
- لتنسيق Avro يكون ترميز الضغط none، deflate، أوsnappy.
في مصدر نشاط النسخ:
-
wildcardFileNameيحتوي فقط على حرف بدل*ولكن ليس?، وwildcardFolderNameغير محدد. -
prefix،modifiedDateTimeStart،modifiedDateTimeEnd، وenablePartitionDiscoveryغير محددين. -
additionalColumnsغير محدد.
-
في تعيين نشاط النسخ، لا يُمكن تحويل النوع.
مثال:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink",
"sqlReaderQuery": "VACUUM eventsTable DRY RUN"
}
}
}
]
نسخة مرحلية إلى delta lake
عندما لا يتطابق مخزن البيانات المتلقي أو تنسيقه مع معايير النسخ المباشر، كما هو مذكور في القسم الأخير، مكّن النسخة المرحلية المضمنة باستخدام مثيل تخزين Azure مؤقت. توفر لك ميزة النسخ المرحلي أيضاً إنتاجية أفضل. تحول الخدمة تلقائياً البيانات لتلبية متطلبات تنسيق البيانات إلى تخزين مرحلي، ثم تحمل البيانات في delta lake من هناك. أخيراً، يقوم بتنظيف بياناتك المؤقتة من التخزين. راجع النسخ المرحلي للحصول على تفاصيل حول نسخ البيانات باستخدام التقسيم المرحلي.
لاستخدام هذه الميزة، أنشئ خدمة تخزين Azure Blob المرتبطة أو خدمة Azure Data Lake Storage Gen2 المرتبطة التي تشير إلى حساب التخزين كتقسيم مرحلي مؤقت. ثم حدد enableStaging وstagingSettings الخصائص في نشاط النسخ.
إشعار
يجب أن تكون بيانات اعتماد حساب تخزين التقسيم المرحلي مكونة مسبقاً في تكوين مجموعة تخزين Azure Databricks، تعرف على المزيد من الشروط الأساسية.
مثال:
"activities":[
{
"name": "CopyToDeltaLake",
"type": "Copy",
"inputs": [
{
"referenceName": "<input dataset name>",
"type": "DatasetReference"
}
],
"outputs": [
{
"referenceName": "<Delta lake output dataset name>",
"type": "DatasetReference"
}
],
"typeProperties": {
"source": {
"type": "<source type>"
},
"sink": {
"type": "AzureDatabricksDeltaLakeSink"
},
"enableStaging": true,
"stagingSettings": {
"linkedServiceName": {
"referenceName": "MyStagingBlob",
"type": "LinkedServiceReference"
},
"path": "mystagingpath"
}
}
}
]
مراقبة
تتوفر نفس تجربة مراقبة نشاط النسخ كما هو الحال بالنسبة للموصلات الأخرى. بالإضافة إلى ذلك، ولأن تحميل البيانات من/إلى delta lake ينفذ على مجموعتك التخزينيةAzure Databricks، يمكنك عرض سجلات المجموعة مفصلةومراقبة الأداء.
بحث عن خصائص النشاط
لمزيد من المعلومات حول الخصائص، راجع نشاط البحث.
يمكن أن يرجع نشاط البحث ما يصل إلى 1000 صف؛ إذا كانت مجموعة النتائج تحتوي على المزيد من السجلات، إرجاع أول 1000 صف.
المحتوى ذو الصلة
للحصول على قائمة مخازن البيانات المعتمدة كمصادر ومواضع تلقٍّ، راجع مخازن البيانات المعتمدة والتنسيقات.