إشعار
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تسجيل الدخول أو تغيير الدلائل.
يتطلب الوصول إلى هذه الصفحة تخويلاً. يمكنك محاولة تغيير الدلائل.
يمكنك ترحيل البيانات من مخزن HDFS محلي لمجموعة Hadoop إلى Azure Storage (تخزين blob أو Data Lake Storage) باستخدام جهاز Data Box. يمكنك الاختيار من بين Data Box Disk أو Data Box بسعة 80 أو 120 أو 525 تيرابايت أو 770 تيرابايت Data Box Heavy.
تعمل هذه المقالة على مساعدتك في إكمال المهام التالية:
- الاستعداد لترحيل بياناتك
- نسخ بياناتك إلى Data Box Disk أو Data Box أو جهاز Data Box Heavy
- شحن الجهاز مرة أخرى إلى Microsoft
- تطبيق أذونات الوصول على الملفات والدلائل (Data Lake Storage فقط)
المتطلبات الأساسية
تتطلب هذه الأشياء إكمال الترحيل.
حساب Azure Storage.
تحتوي مجموعة Hadoop المحلية على بيانات المصدر الخاصة بك.
-
قم بتوصيل صندوق البيانات الخاص بك أو صندوق البيانات الثقيل بشبكة محلية.
إذا كنت مستعدا، فلنبدأ.
نسخ بياناتك إلى جهاز صندوق البيانات.
إذا كانت بياناتك تتناسب مع جهاز Data Box واحد، فإنك تنسخ البيانات إلى جهاز Data Box.
إذا تجاوز حجم البيانات سعة جهاز صندوق البيانات، فاستخدم الإجراء الاختياري لتقسيم البيانات عبر أجهزة صندوق البيانات المتعددة ثم قم بتنفيذ هذه الخطوة.
لنسخ البيانات من مخزن HDFS المحلي إلى جهاز Data Box، يمكنك إعداد بعض الأشياء، ثم استخدام أداة DistCp .
اتبع هذه الخطوات لنسخ البيانات عبر واجهات برمجة تطبيقات REST لتخزين الكائن الثنائي كبير الحجم/ العنصر إلى جهاز صندوق البيانات الخاص بك. تجعل واجهة REST API الجهاز يظهر كمخزن HDFS لنظام المجموعة.
قبل نسخ البيانات عبر REST، حدد بدائيات الأمان والاتصال للاتصال بواجهة REST على صندوق البيانات أو صندوق البيانات الثقيل. سجل الدخول إلى واجهة مستخدم الويب المحلية لصندوق البيانات وانتقل إلى صفحة الاتصال ونسخها. مقابل حسابات تخزين Azure لجهازك، ضمن إعدادات Access، حدد موقع REST وحدده.
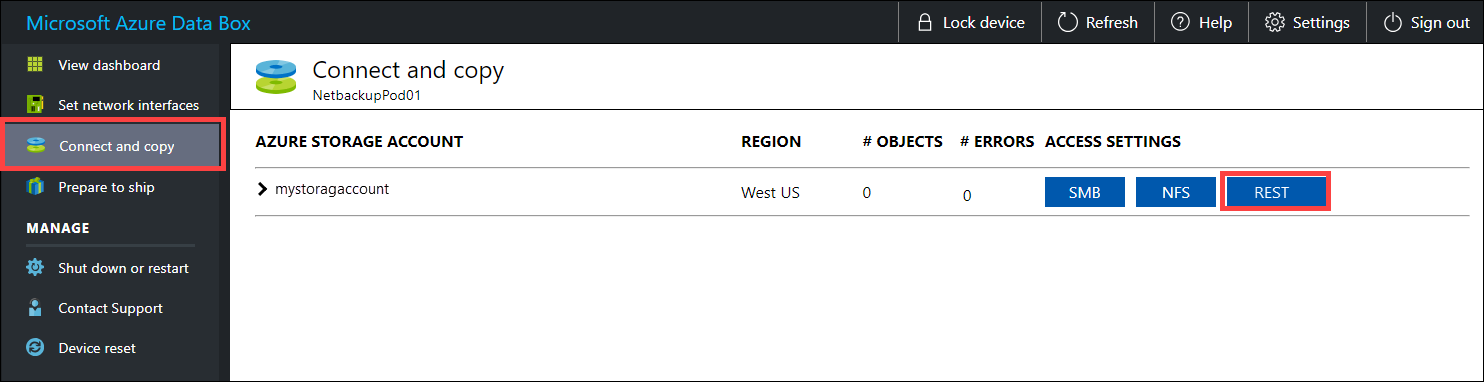
في حساب تخزين الوصول وحوار تحميل البيانات، انسخ نقطة نهاية خدمة الكائن الثنائي كبير الحجمومفتاح حساب التخزين. من نقطة نهاية خدمة الكائن الثنائي كبير الحجم، احذف الشرطة المائلة
https://والزائدة.في هذه الحالة، تكون نقطة النهاية هي:
https://mystorageaccount.blob.mydataboxno.microsoftdatabox.com/. جزء المضيف من URI الذي تستخدمه هو:mystorageaccount.blob.mydataboxno.microsoftdatabox.com. على سبيل المثال، راجع كيفية الاتصال إلى REST باستخدام http.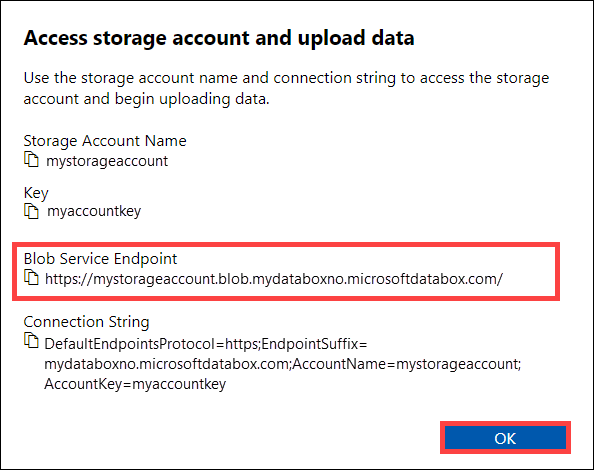
أضف نقطة النهاية وعنوان IP لعقدة صندوق البيانات أو عقدة صندوق البيانات الثقيل إلى
/etc/hostsكل عقدة.10.128.5.42 mystorageaccount.blob.mydataboxno.microsoftdatabox.comإذا كنت تستخدم آلية أخرى ل DNS، فيجب عليك التأكد من إمكانية حل نقطة نهاية Data Box.
اضبط متغير
azjarsshell الخاص بموقعhadoop-azureملفات Jarazure-storage. يمكنك العثور على هذه الملفات ضمن دليل التثبيت الخاص بـ Hadoop.لتحديد ما إذا كانت هذه الملفات موجودة، يُنصح باستخدم الأمر التالي:
ls -l $<hadoop_install_dir>/share/hadoop/tools/lib/ | grep azure. استبدل<hadoop_install_dir>العنصر النائب بالمسار الخاص بالدليل حيث قمت بتثبيت Hadoop. التأكد من استخدام مسارات مؤهلة بالكامل.أمثلة:
azjars=$hadoop_install_dir/share/hadoop/tools/lib/hadoop-azure-2.6.0-cdh5.14.0.jarazjars=$azjars,$hadoop_install_dir/share/hadoop/tools/lib/microsoft-windowsazure-storage-sdk-0.6.0.jarيتعين بإنشاء حاوية التخزين التي تريد استخدامها لنسخ البيانات. يجب عليك أيضا القيام بتحديد دليل وجهة كجزء من هذا الأمر. قد يمثل هذا دليل وجهة وهمية في هذه المرحلة.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -mkdir -p wasb://<container_name>@<blob_service_endpoint>/<destination_directory>استبدل العنصر النائب
<blob_service_endpoint>باسم نقطة نهاية خدمة الكائن الثنائي كبير الحجم.استبدل العنصر النائب
<account_key>بمفتاح الوصول الخاص بالحاسب الخاص بك.استبدل العنصر النائب
<container-name>باسم الحاوية الخاصة بك.استبدل
<destination_directory>العنصر النائب باسم الدليل الذي تريد نسخ البيانات الخاصة بك إليه.
قم بتشغيل أمر قائمة للتأكد من عملية إنشاء الحاوية والدليل.
hadoop fs -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint>=<account_key> \ -ls -R wasb://<container_name>@<blob_service_endpoint>/استبدل العنصر النائب
<blob_service_endpoint>باسم نقطة نهاية خدمة الكائن الثنائي كبير الحجم.استبدل العنصر النائب
<account_key>بمفتاح الوصول الخاص بالحاسب الخاص بك.استبدل العنصر النائب
<container-name>باسم الحاوية الخاصة بك.
انسخ البيانات من Hadoop HDFS إلى وحدة تخزين الكائن الثنائي كبير الحجم الخاص بصندوق البيانات في الحاوية التي قمت بإنشائها مسبقا. إذا لم يتم العثور على الدليل الذي تقوم بالنسخ إليه، يقوم الأمر تلقائيا بإنشائه.
hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -filters <exclusion_filelist_file> \ [-f filelist_file | /<source_directory> \ wasb://<container_name>@<blob_service_endpoint>/<destination_directory>استبدل العنصر النائب
<blob_service_endpoint>باسم نقطة نهاية خدمة الكائن الثنائي كبير الحجم.استبدل العنصر النائب
<account_key>بمفتاح الوصول الخاص بالحاسب الخاص بك.استبدل العنصر النائب
<container-name>باسم الحاوية الخاصة بك.استبدل
<exclusion_filelist_file>العنصر النائب باسم الملف الذي يحتوي على قائمة استثناءات الملفات الخاصة بك.استبدل
<source_directory>العنصر النائب باسم الدليل الذي تريد نسخ البيانات الخاصة بك إليه.استبدل
<destination_directory>العنصر النائب باسم الدليل الذي تريد نسخ البيانات الخاصة بك إليه.
يتم استخدام الخيار
-libjarsلجعلhadoop-azure*.jarوالملفات التابعةazure-storage*.jarمتوفرة لـdistcp. قد يحدث هذا بالفعل لبعض أنظمة المجموعات.يوضح المثال التالي كيفية
distcpيمكن استخدام الأمر لنسخ البيانات.hadoop distcp \ -libjars $azjars \ -D fs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -D fs.azure.account.key.mystorageaccount.blob.mydataboxno.microsoftdatabox.com=myaccountkey \ -filter ./exclusions.lst -f /tmp/copylist1 -m 4 \ /data/testfiles \ wasb://hdfscontainer@mystorageaccount.blob.mydataboxno.microsoftdatabox.com/dataالعمل على تحسين سرعة النسخ:
محاولة تغيير عدد مخططي الخرائط. (العدد الافتراضي لمخططي الخرائط هو 20. يستخدم
mالمثال أعلاه = 4 مخططين.)جرّب
-D fs.azure.concurrentRequestCount.out=<thread_number>. استبدل<thread_number>بعدد مؤشرات الترابط لكل مخطط. يجب ألا يتجاوز ناتج عدد المعينين وعدد مؤشرات الترابط لكل mapper،m*<thread_number>32.حاول بدء التشغيل عدة مرات
distcpبالتوازي.يُرجى العلم بأن الملفات الكبيرة تعمل بشكل أفضل من الملفات الصغيرة.
إذا كان لديك ملفات أكبر من 200 غيغابايت، نوصي بتغيير حجم الكتلة إلى 100 ميغابايت باستخدام المعلمات التالية:
hadoop distcp \ -libjars $azjars \ -Dfs.azure.write.request.size= 104857600 \ -Dfs.AbstractFileSystem.wasb.Impl=org.apache.hadoop.fs.azure.Wasb \ -Dfs.azure.account.key.<blob_service_endpoint<>=<account_key> \ -strategy dynamic \ -Dmapreduce.map.memory.mb=16384 \ -Dfs.azure.concurrentRequestCount.out=8 \ -Dmapreduce.map.java.opts=-Xmx8196m \ -m 4 \ -update \ /data/bigfile wasb://hadoop@mystorageaccount.blob.core.windows.net/bigfile
شحن صندوق البيانات البيانات إلى Microsoft
اتبع هذه الخطوات لإعداد جهاز صندوق البيانات وشحنه إلى Microsoft.
أولا، استعد للشحن باستخدام صندوق البيانات الخاص بك أو صندوق البيانات الثقيل.
بعد اكتمال إعداد الجهاز، قم بتنزيل ملفات علامة ترتيب وحدات البايت. يمكنك استخدام قائمة مكونات الصنف هذه أو ملفات البيان لاحقا للتحقق من البيانات التي تم تحميلها إلى Azure.
إجراء عملية إيقاف تشغيل الجهاز وإزالة الكابلات.
جدولة موعد للاستلام باستخدام UPS.
فيما يتعلق أجهزة صندوق البيانات، راجع شحن صندوق البيانات.
بالنسبة إلى الأجهزة الثقيلة لصندوق البيانات، راجع شحن صندوق البيانات الثقيل.
بعد أن تتلقى Microsoft جهازك، يتم توصيله بشبكة مركز البيانات، ويتم تحميل البيانات إلى حساب التخزين الذي حددته عند تقديم طلب الجهاز. تحقق من تحميل جميع البيانات الخاصة بك إلى Azure مقابل ملفات علامة ترتيب وحدات البايت.
تطبيق أذونات الوصول على الملفات والدلائل (Data Lake Storage فقط)
لديك بالفعل البيانات في حساب تخزين Azure الخاص بك. الآن يمكنك تطبيق أذونات الوصول على الملفات والدلائل.
إشعار
هذه الخطوة مطلوبة فقط إذا كنت تستخدم Azure Data Lake Storage كمخزن بيانات. إذا كنت تستخدم حساب تخزين الكائن الثنائي كبير الحجم فقط بدون مساحة اسم هرمية كمخزن بيانات، يمكنك تخطي هذا القسم.
إنشاء كيان خدمة لحساب Azure Data Lake Storage الممكن
لإنشاء كيان خدمة، راجع كيفية: استخدام المدخل لإنشاء تطبيق Microsoft Entra ومدير الخدمة الذي يمكنه الوصول إلى الموارد.
:heavy_check_mark: عند تنفيذ الخطوات الواردة في قسم تعيين التطبيق إلى دور من المقالة، يُرجى التحقق من تعيين دور مساهم بيانات كائن الثنائي كبير الحجم للتخزين إلى كيان الخدمة.
:heavy_check_mark: عند تنفيذ الخطوات الواردة في قسم الحصول على قيم لتسجيل الدخول من المقالة، يُرجى حفظ معرف التطبيق والقيم السرية للعميل في ملف نصي. أنت بحاجة إليها قريبا.
إنشاء قائمة بالملفات المنسوخة باستخدام الأذونات الخاصة بها.
من نظام مجموعة Hadoop المحلي، يُنصح بتشغيل هذا الأمر:
sudo -u hdfs ./copy-acls.sh -s /{hdfs_path} > ./filelist.json
يقوم هذا الأمر بإنشاء قائمة بالملفات المنسوخة باستخدام الأذونات الخاصة بها..
إشعار
أستناداً إلى عدد الملفات في HDFS ، قد يستغرق تشغيل هذا الأمر وقتا طويلا.
إنشاء قائمة الهويات وتعيينها إلى هويات Microsoft Entra
يُنصح بتنزيل البرنامج النصي
copy-acls.py. راجع قسم تنزيل البرامج النصية المساعدة وإعداد عقدة الحافة لتشغيلها في هذه المقالة.يتعين بتشغيل هذا الأمر لإنشاء قائمة بالهويات الفريدة.
./copy-acls.py -s ./filelist.json -i ./id_map.json -gيقوم هذا البرنامج النصي بإنشاء اسم ملف
id_map.jsonيحتوي على الهويات التي تحتاج إلى تعيينها إلى هويات تستند إلى ADD.افتح الملف
id_map.jsonباستخدام محرر نص كما يلي:لكل كائن JSON يظهر في الملف، قم بتحديث
targetالسمة إما اسم مستخدم Microsoft Entra الأساسي (UPN) أو ObjectId (OID)، بالهوية المعينة المناسبة. بعد الانتهاء من ذلك، احفظ الملف. سوف تكون بحاجة إلى هذا الملف في الخطوة التالية.
تطبيق الأذونات على الملفات المنسوخة وتطبيق التعيينات الخاصة بالهوية
قم بتشغيل هذا الأمر لتطبيق الأذونات على البيانات التي نسختها في حساب Data Lake Storage الممكن:
./copy-acls.py -s ./filelist.json -i ./id_map.json -A <storage-account-name> -C <container-name> --dest-spn-id <application-id> --dest-spn-secret <client-secret>
استبدال
<storage-account-name>العنصر النائب باسم حساب التخزين.استبدل العنصر النائب
<container-name>باسم الحاوية الخاصة بك.استبدل العناصر النائبة والعناصر
<application-id>النائبة<client-secret>بمعرف التطبيق وسر العميل اللذين قمت بجمعهما عند إنشاء أصل الخدمة.
ملحق: تقسيم البيانات باستخدام أجهزة صندوق بيانات متعددة
قبل نقل بياناتك إلى جهاز Data Box، تحتاج إلى تنزيل بعض البرامج النصية المساعدة، والتأكد من تنظيم بياناتك لتناسب جهاز Data Box، واستبعاد أي ملفات غير ضرورية.
تنزيل البرامج النصية المساعدة وإعداد عقدة الحافة لإجراء عملية تشغيلها.
باستخدام الحافة أو عقدة الرأس الخاصة بمجموعة Hadoop المحلية، قم بتشغيل هذا الأمر:
git clone https://github.com/jamesbak/databox-adls-loader.git cd databox-adls-loaderيقوم هذا الأمر إجراء عملية استنساخ لمستودع GitHub الذي يحتوي على البرامج النصية المساعدة.
تأكد من تثبيت حزمة jq على الكمبيوتر المحلي.
sudo apt-get install jqتثبيت حُزمة Python المتعلقة بالطلبات
pip install requestsيجب بتعيين أذونات التنفيذ على البرامج النصية المطلوبة.
chmod +x *.py *.sh
تأكد من تنظيم البيانات الخاصة بك لتناسب جهاز صندوق البيانات.
إذا تجاوز حجم البيانات حجم جهاز Data Box واحد، يمكنك تقسيم الملفات إلى مجموعات يمكنك تخزينها على أجهزة Data Box متعددة.
إذا لم تتجاوز بياناتك حجم جهاز Data Box واحد، يمكنك المتابعة إلى القسم التالي.
باستخدام الأذونات العالية
generate-file-list، يُنصح بتشغيل البرنامج النصي الذي قمت بتنزيله باتباع الإرشادات الواردة في القسم السابق.أدناه وصف لمعلمات الأوامر:
sudo -u hdfs ./generate-file-list.py [-h] [-s DATABOX_SIZE] [-b FILELIST_BASENAME] [-f LOG_CONFIG] [-l LOG_FILE] [-v {DEBUG,INFO,WARNING,ERROR}] path where: positional arguments: path The base HDFS path to process. optional arguments: -h, --help show this help message and exit -s DATABOX_SIZE, --databox-size DATABOX_SIZE The size of each Data Box in bytes. -b FILELIST_BASENAME, --filelist-basename FILELIST_BASENAME The base name for the output filelists. Lists will be named basename1, basename2, ... . -f LOG_CONFIG, --log-config LOG_CONFIG The name of a configuration file for logging. -l LOG_FILE, --log-file LOG_FILE Name of file to have log output written to (default is stdout/stderr) -v {DEBUG,INFO,WARNING,ERROR}, --log-level {DEBUG,INFO,WARNING,ERROR} Level of log information to output. Default is 'INFO'.انسخ قوائم الملفات التي تم إنشاؤها إلى HDFS بحيث يمكن الوصول إليها من مهمة DistCp .
hadoop fs -copyFromLocal {filelist_pattern} /[hdfs directory]
يجب استبعاد الملفات غير الضرورية
تحتاج إلى استبعاد بعض الدلائل من مهمة DisCp. على سبيل المثال، استبعاد الدلائل التي تحتوي على معلومات الحالة التي من شأنها أن تحافظ على تشغيل نظام المجموعة.
في نظام مجموعة Hadoop المحلية حيث تخطط لبدء مهمة DistCp، قم بإنشاء ملف يقوم بتحديد قائمة الدلائل التي تريد استبعادها.
إليك مثال:
.*ranger/audit.*
.*/hbase/data/WALs.*
الخطوات التالية
تعرف على كيفية عمل Data Lake Storage مع مجموعات HDInsight. لمزيد من المعلومات، راجع استخدام Azure Data Lake Storage مع مجموعات Azure HDInsight.