Poznámka:
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
Azure Blob Storage je řešení úložiště objektů pro cloud od Microsoftu. Je navržený tak, aby ukládal obrovské objemy nestrukturovaných dat, jako jsou textová, binární data, dokumenty, mediální soubory a zálohy aplikací. Jako základní služba úložiště Azure poskytuje Blob Storage několik funkcí spolehlivosti, které zajišťují, že vaše data zůstanou dostupná a odolná během plánovaných i neplánovaných událostí.
Při používání Azure je spolehlivost sdílenou odpovědností. Microsoft nabízí celou řadu možností, které podporují odolnost a obnovení. Zodpovídáte za pochopení toho, jak tyto možnosti fungují ve všech službách, které používáte, a výběrem možností, které potřebujete ke splnění vašich obchodních cílů a cílů dostupnosti.
Tento článek popisuje, jak zajistit odolnost služby Blob Storage vůči nejrůznějším potenciálním výpadkům a problémům, včetně přechodných chyb, výpadků zón dostupnosti a výpadků oblastí. Popisuje také, jak můžete použít zálohy k zotavení z jiných typů problémů a zvýrazní některé klíčové informace o smlouvě o úrovni služeb Blob Storage (SLA).
Poznámka:
Blob Storage je součástí platformy Azure Storage. Některé možnosti služby Blob Storage jsou společné v mnoha službách Azure Storage. V tomto článku používáme Azure Storage k odkaz na tyto funkce.
Doporučení pro nasazení do produkčního prostředí
Informace o nasazení služby Blob Storage pro podporu požadavků na spolehlivost vašeho řešení a o tom, jak spolehlivost ovlivňuje další aspekty architektury, najdete v tématu Osvědčené postupy architektury pro službu Blob Storage v architektuře Azure Well-Architected Framework.
Přehled architektury spolehlivosti
Azure Storage nabízí několik možností redundance, které vám pomůžou chránit data před různými typy selhání. Každá možnost poskytuje konkrétní úroveň redundance dat, takže můžete zvolit úroveň, která nejlépe odpovídá požadavkům vaší aplikace.
Místně redundantní úložiště (LRS) replikuje data v účtech úložiště do jedné nebo více zón dostupnosti Azure umístěných v primární oblasti podle vašeho výběru. I když není možné zvolit upřednostňovanou zónu dostupnosti, Azure může přesunout nebo rozšířit účty LRS napříč zónami, aby se zlepšilo vyrovnávání zatížení. Není zaručeno, že se vaše data budou šířit mezi zóny. Další informace o zónách dostupnosti najdete v tématu Co jsou zóny dostupnosti?.

Zónově redundantní úložiště (ZRS), geograficky redundantní úložiště (GRS) a geograficky zónově redundantní úložiště (GZRS) poskytují dodatečnou ochranu. Tento článek podrobně popisuje tyto možnosti.
Odolnost proti přechodným chybám
Přechodné chyby jsou krátká, přerušovaná selhání ve složkách. V distribuovaném prostředí, jako je cloud, se vyskytují často a jsou normální součástí provozu. Přechodné chyby se opravují po krátké době. Je důležité, aby vaše aplikace mohly zpracovávat přechodné chyby, obvykle opakováním ovlivněných požadavků.
Všechny aplikace hostované v cloudu by měly při komunikaci se všemi cloudovými rozhraními API, databázemi a dalšími komponentami postupovat podle pokynů pro zpracování přechodných chyb Azure. Další informace najdete v tématu Doporučení pro zpracování přechodných chyb.
Pokud chcete efektivně spravovat přechodné chyby při použití služby Blob Storage, implementujte následující doporučení:
Použijte klientské knihovny Azure Storage, které zahrnují integrované zásady opakování s exponenciálním zpožováním a zpožděním. Sady .NET, Java, Python a JavaScript SDK automaticky zpracovávají opakování přechodných selhání. Další informace o možnostech konfigurace opakování najdete v tématu Implementace zásad opakování v .NET.
Nakonfigurujte odpovídající hodnoty časového limitu pro operace objektů blob na základě velikosti objektu blob a podmínek sítě. Větší objekty blob vyžadují delší časové limity, ale menší operace můžou k rychlému zjišťování selhání použít kratší hodnoty.
Odolnost proti chybám zóny dostupnosti
Zóny dostupnosti jsou fyzicky oddělené skupiny datacenter v rámci oblasti Azure. Když jedna zóna selže, mohou služby přejít na jednu ze zbývajících zón.
Blob Storage poskytuje robustní podporu zón dostupnosti prostřednictvím konfigurací ZRS, které automaticky distribuují vaše data napříč několika zónami dostupnosti v rámci oblasti. Na rozdíl od místně redundantního úložiště (LRS) zaručuje ZRS synchronní replikaci dat objektů blob napříč několika zónami dostupnosti. ZRS zajišťuje, aby vaše data zůstala přístupná i v případě výpadku jedné zóny.
Redundance zón je povolená na úrovni účtu úložiště a vztahuje se na všechny kontejnery objektů blob v rámci daného účtu. Pro jednotlivé kontejnery nemůžete nastavit různé úrovně redundance. Konfigurace redundance se použije pro celý účet úložiště. Když dojde k výpadku zóny dostupnosti, Azure Storage automaticky směruje požadavky do zón, které jsou v pořádku, aniž by vyžadovala zásah od vás nebo vaší aplikace.

Požadavky
- Podpora oblastí: Zónově redundantní účty Azure Storage můžete nasadit v libovolné oblasti, která podporuje zóny dostupnosti.
- Typy účtů úložiště: Redundance zón je dostupná pro oba typy účtů úložiště: Standardní obecný účel V2 a Prémiový úložiště blokových objektů Blob. Objekty blob bloku, doplňovací objekty blob a objekty blob stránky podporují zónově redundantní konfigurace, ale typ účtu úložiště, který používáte, určuje, které možnosti jsou k dispozici. Další informace najdete v tématu Podporované typy účtů úložiště.
Náklady
Když povolíte zónově redundantní úložiště (ZRS), bude se vám účtovat jiná sazba než místně redundantní úložiště (LRS) z důvodu dodatečné replikace a režie úložiště.
Další informace najdete v tématu Ceny služby Blob Storage.
Konfigurujte podporu zón dostupnosti
- Vytvořte účet úložiště objektů blob s redundancí zón. Pokud chcete vytvořit nový účet úložiště pomocí ZRS, přečtěte si téma Vytvoření účtu úložiště a výběr ZRS, geograficky zónově redundantního úložiště (GZRS) nebo geograficky redundantního úložiště jen pro čtení (RA-GZRS) jako možnosti redundance při vytváření účtu.
Změnit typ replikace. Informace o tom, jak změnit existující účet úložiště na zónově redundantní úložiště (ZRS) a informace o možnostech konfigurace a požadavcích, najdete v tématu Změna způsobu replikace účtu úložiště.
Zakažte zónovou redundanci. Převeďte účty ZRS zpět na nezonální konfiguraci, jako je místně redundantní úložiště (LRS), pomocí stejného procesu změny konfigurace redundance.
Chování, když jsou všechny zóny v pořádku
Tato část popisuje, co očekávat, když je účet úložiště objektů blob nakonfigurovaný pro redundanci zón a všechny zóny dostupnosti jsou funkční.
Směrování provozu mezi zónami: Azure Storage s zónově redundantním úložištěm (ZRS) automaticky distribuuje požadavky mezi clustery úložiště ve více zónách dostupnosti. Distribuce provozu je pro aplikace transparentní a nevyžaduje žádnou konfiguraci na straně klienta.
Replikace dat mezi zónami: Všechny operace zápisu do ZRS se replikují synchronně napříč všemi zónami dostupnosti v rámci oblasti. Po nahrání nebo úpravě dat se operace nepovažuje za dokončenou, dokud se data úspěšně nereplikují napříč všemi zónami dostupnosti. Tato synchronní replikace zajišťuje silnou konzistenci a nulovou ztrátu dat během selhání zóny.
Chování při selhání zóny
Tato část popisuje, co očekávat, když je účet úložiště objektů blob nakonfigurovaný pro ZRS a dojde k výpadku zóny dostupnosti.
Detekce a odpověď: Microsoft automaticky rozpozná selhání zóny a zahájí procesy obnovení. Pro účty zónově redundantního úložiště (ZRS) se nevyžaduje žádná akce zákazníka.
Pokud se zóna stane nedostupnou, Azure provádí aktualizace sítí, jako je repointování DNS (Domain Name System).
- Oznámení: Microsoft vás automaticky neoznámí, když je zóna mimo provoz. Azure Resource Health ale můžete použít k monitorování stavu jednotlivých prostředků a můžete nastavit upozornění služby Resource Health , která vás upozorní na problémy. Pomocí služby Azure Service Health můžete také porozumět celkovému stavu služby, včetně jakýchkoli selhání zón, a můžete nastavit upozornění služby Service Health , která vás upozorní na problémy.
Aktivní požadavky: Během procesu obnovení může dojít k vyřazení požadavků během letu a mělo by se to opakovat. Aplikace by měly implementovat logiku opakování pro zpracování těchto dočasných přerušení.
Očekávaná ztráta dat: Během selhání zóny nedojde ke ztrátě dat, protože data se před dokončením operací zápisu synchronně replikují napříč několika zónami.
Očekávaný výpadek: Během automatického obnovení může během automatického obnovení dojít k malému výpadku, obvykle během několika sekund, protože se provoz přesměruje do zón, které jsou v pořádku. Při návrhu aplikací pro ZRS dodržujte postupy pro zpracování přechodných chyb, včetně implementace zásad opakování s exponenciálním zpětným vypnutím.
- Přesměrování provozu: Pokud zóna dostupnosti přejde do offline režimu, Azure zahájí změny sítí, jako je repointování DNS (Domain Name System). Tyto aktualizace zajišťují přesměrování provozu do zbývajících zón dostupnosti, které jsou v pořádku. Služba udržuje plnou funkčnost pomocí přeživších zón a nevyžaduje zásah zákazníka.
Obnovení zóny
Když se zóna dostupnosti zotaví z chyby, Azure Storage automaticky obnoví normální operace napříč všemi zónami dostupnosti. Služba automaticky zajišťuje konzistenci dat tím, že synchronizuje všechny operace, ke kterým došlo během období výpadku.
Testování poruch zón
Když používáte zónově redundantní úložiště (ZRS), Azure Storage automaticky spravuje replikaci, směrování provozu a odezvy na zónově dolů. Vzhledem k tomu, že je tato funkce plně spravována, nemusíte zahajovat ani ověřovat procesy selhání zóny dostupnosti.
Odolnost proti selháním v celé oblasti
Azure Storage, včetně Azure Blob Storage, Azure Files, Azure Table Storage a Azure Queue Storage, poskytuje celou řadu možností geografické redundance a převzetí služeb při selhání, které vyhovují různým požadavkům.
Důležité
Geograficky redundantní úložiště (GRS) funguje jenom v rámci spárovaných oblastí Azure. Pokud oblast vašeho účtu úložiště není spárovaná, zvažte použití vlastních řešení pro více oblastí pro zajištění odolnosti.
Geograficky redundantní úložiště pro spárované oblasti
Azure Storage poskytuje několik typů GRS ve spárovaných oblastech. Podle toho, jaký typ GRS používáte, se data v sekundární oblasti vždy replikují pomocí místně redundantního úložiště (LRS). Tento přístup poskytuje ochranu před selháním hardwaru v sekundární oblasti.
GRS poskytuje podporu pro plánované a neplánované převzetí služeb při selhání do spárované oblasti Azure v případě výpadku v primární oblasti. GRS asynchronně replikuje data z primární oblasti do spárované oblasti.
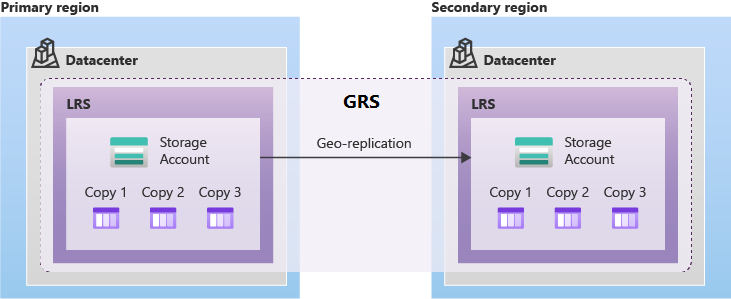
Geograficky zónově redundantní úložiště (GZRS) replikuje data v několika zónách dostupnosti v primární oblasti a do spárované oblasti.
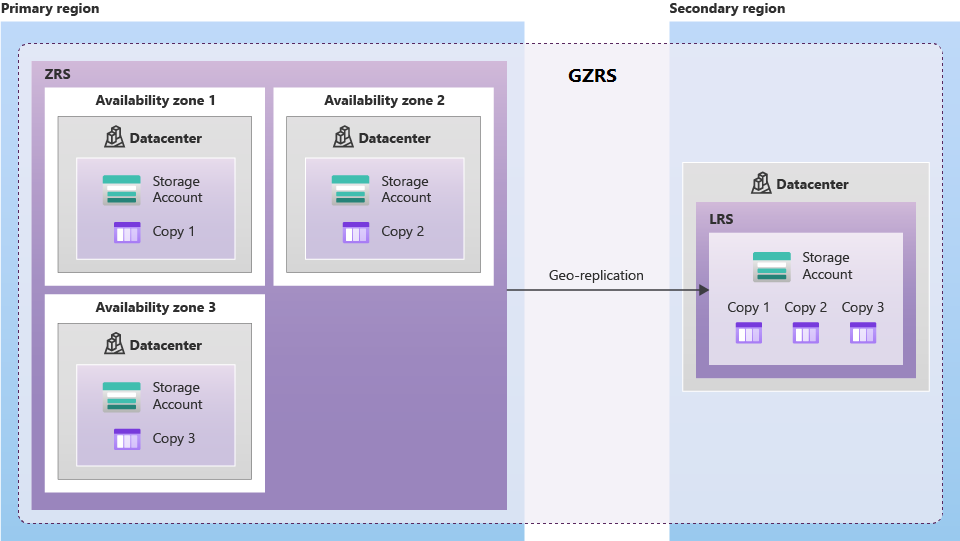


Geograficky redundantní úložiště
- Geograficky redundantní úložiště s přístupem pro čtení (RA-GRS) a geograficky zónově redundantní úložiště jen pro čtení (RA-GZRS) rozšiřuje geograficky redundantní úložiště (GRS) a geograficky zónově redundantní úložiště (GZRS) s přidanou výhodou přístupu pro čtení k sekundárnímu koncovému bodu. Tyto možnosti jsou ideální pro aplikace navržené pro obchodní aplikace s vysokou dostupností, které jsou kritické pro podnikání. V nepravděpodobném případě, že primární koncový bod dojde k výpadku, můžou aplikace nakonfigurované pro přístup pro čtení do sekundární oblasti dál fungovat.
Typy převzetí služeb při selhání
Azure Storage podporuje tři typy převzetí služeb při selhání pro různé scénáře.
Neplánované převzetí služeb při selhání spravované zákazníkem: Pokud v primární oblasti dojde k selhání úložiště v celé oblasti, zodpovídáte za inicializování obnovení.
Plánované převzetí služeb při selhání spravované zákazníkem: Zodpovídáte za zahájení obnovy, pokud jiná část vašeho řešení selže v primárním regionu, a potřebujete přepnout celé řešení do sekundárního regionu. Pokud úložiště zůstane funkční v primární oblasti, použijte plánované převzetí služeb do sekundární oblasti, například pro simulace obnovy po havárii, které jsou navrženy k zajištění shody s regulačními požadavky a auditem.
Převzetí služeb při selhání spravované Microsoftem: Za výjimečných okolností může Microsoft zahájit převzetí služeb při selhání pro všechny účty geograficky redundantního úložiště (GRS) v oblasti. Převzetí služeb při selhání spravované Microsoftem je ale poslední možností a očekává se, že se provede pouze po delší době výpadku. Neměli byste spoléhat na převzetí při selhání spravované společností Microsoft.
Účty GRS můžou používat kterýkoli z těchto typů převzetí služeb při selhání. Není třeba předem nakonfigurovat účet úložiště pro použití jakéhokoli typu převzetí služeb při selhání.
Požadavky
Podpora oblastí: Geograficky redundantní konfigurace Azure Storage používají spárované oblasti Azure pro replikaci sekundární oblasti. Sekundární oblast se automaticky určí na základě výběru primární oblasti a nedá se přizpůsobit. Úplný seznam spárovaných oblastí Azure najdete v seznamu oblastí Azure.
Pokud oblast vašeho účtu úložiště není spárovaná, zvažte použití vlastních řešení pro více oblastí pro zajištění odolnosti.
- Typy účtů úložiště: Geo-redundantní úložiště (GRS) a převzetí a obnovení iniciované zákazníkem jsou k dispozici ve všech spárovaných oblastech Azure, které podporují účty Azure Storage verze pro obecné účely v2.
Úvahy
Při implementaci služby Blob Storage s více oblastmi zvažte následující klíčové faktory:
Latence asynchronní replikace: Replikace dat do sekundární oblasti je asynchronní, což znamená, že mezi zápisem dat do primární oblasti a dostupností dat v sekundární oblasti dochází k prodlevě. Tato prodleva může způsobit potenciální ztrátu dat, pokud dojde k selhání primární oblasti před replikací nedávných dat. Ztrátu dat měří cíl bodu obnovení (RPO). Můžete očekávat, že prodleva replikace bude kratší než 15 minut, ale tentokrát je odhad a není zaručen.
Pokud má váš účet úložiště neplánované převzetí služeb při selhání, můžete zkontrolovat vlastnost Čas poslední synchronizace a zjistit, kolik dat může dojít ke ztrátě dat.
Přístup k sekundární oblasti: S konfigurací geograficky redundantního úložiště (GRS) a geograficky zónově redundantního úložiště (GZRS) není sekundární oblast přístupná pro čtení, dokud nedojde k převzetí služeb při selhání.
Konfigurace geograficky redundantního úložiště s přístupem pro čtení (RA-GRS) a geograficky zónově redundantní úložiště s přístupem pro čtení (RA-GZRS) poskytují přístup ke čtení sekundární oblasti během normálních operací, ale kvůli latenci asynchronní replikace můžou vracet mírně zastaralá data.
- Omezení funkcí: Některé funkce služby Azure Storage nejsou podporované nebo mají omezení, pokud používáte geograficky redundantní úložiště (GRS) nebo převzetí služeb při selhání spravované zákazníkem. Před implementací geografické redundance zkontrolujte kompatibilitu funkcí .
Náklady
Konfigurace účtu Azure Storage ve více oblastech účtují dodatečné náklady na replikaci mezi oblastmi a úložiště v sekundární oblasti. Přenos dat mezi oblastmi Azure se účtuje na základě standardních sazeb šířky pásma mezi oblastmi.
Další informace najdete v tématu Ceny služby Blob Storage.
Konfigurace podpory více oblastí
- Vytvořte nový účet geograficky redundantního úložiště (GRS). Pokud chcete vytvořit účet GRS, přečtěte si téma Vytvoření účtu úložiště a výběr geograficky redundantního úložiště jen pro čtení (RA-GRS), geograficky zónově redundantního úložiště (GZRS) nebo geograficky zónově redundantního úložiště jen pro čtení (RA-GZRS) během vytváření účtu.
Povolte geografickou redundanci u existujícího účtu úložiště. Pokud chcete převést existující účet úložiště na geograficky redundantní úložiště (GRS), přečtěte si téma Změna způsobu replikace účtu úložiště.
Výstraha
Po změně konfigurace vašeho účtu pro geografickou redundanci může trvat značné množství času, než se stávající data v nové primární oblasti plně zkopírují do nové sekundární oblasti.
Pokud se chcete vyhnout závažné ztrátě dat, před zahájením neplánovaného převzetí služeb při selhání zkontrolujte hodnotu vlastnosti Čas poslední synchronizace . Pokud chcete vyhodnotit potenciální ztrátu dat, porovnejte čas poslední synchronizace s časem posledního zápisu dat do nové primární oblasti.
Zakažte geografickou redundanci. Pomocí stejného procesu změny konfigurace redundance převeďte účty GRS zpět na konfigurace s jednou oblastí, jako je místně redundantní úložiště (LRS) nebo zónově redundantní úložiště (ZRS).
Chování, když jsou všechny oblasti v pořádku
Tato část popisuje, co očekávat, když je účet úložiště nakonfigurovaný pro geografickou redundanci a všechny oblasti jsou funkční.
Směrování provozu mezi oblastmi: Azure Storage používá přístup typu aktivní-pasivní, kdy se všechny operace zápisu a většina operací čtení směrují do primární oblasti.
Pro geograficky redundantní úložiště s přístupem pro čtení (RA-GRS) a konfigurace geograficky zónově redundantního úložiště s přístupem pro čtení (RA-GZRS) můžou aplikace volitelně číst ze sekundární oblasti tak, že přistupují k sekundárnímu koncovému bodu. Tento přístup vyžaduje explicitní konfiguraci aplikace a není automatický. Kvůli prodlevě asynchronní replikace mohou být data v sekundární oblasti mírně zastaralá.
Replikace dat mezi oblastmi: Operace zápisu se nejprve potvrdí do primární oblasti pomocí následujících nakonfigurovaných typů redundance:
- Místně redundantní úložiště (LRS) pro geograficky redundantní úložiště (GRS) a RA-GRS
- Zónově redundantní úložiště (ZRS) pro geograficky zónově redundantní úložiště (GZRS) a RA-GZRS
Po úspěšném dokončení v primární oblasti se data asynchronně replikují do sekundární oblasti, kde jsou uložená pomocí LRS.
Asynchronní povaha replikace mezi oblastmi znamená, že mezi zápisem dat do primární oblasti a dostupností v sekundární oblasti je obvykle prodleva. Čas replikace můžete monitorovat pomocí vlastnosti Čas poslední synchronizace.
Chování při selhání oblasti
Tato část popisuje, co očekávat, když je účet úložiště nakonfigurovaný pro geografickou redundanci a v primární oblasti došlo k výpadku.
Převzetí služeb při selhání spravované zákazníkem (neplánované): Pokud úložiště v primární oblasti není k dispozici, použijte neplánované převzetí služeb při selhání.
Detekce a reakce: V nepravděpodobném případě, že váš účet úložiště není v primární oblasti dostupný, můžete zvážit zahájení zákaznicky řízeného neplánovaného převzetí služeb při selhání. Při rozhodování zvažte následující faktory:
Jestli azure Resource Health zobrazuje problémy s přístupem k účtu úložiště ve vaší primární oblasti
Jestli vám Microsoft doporučuje provést převzetí služeb při selhání do jiné oblasti
Výstraha
Neplánované převzetí služeb při selhání může vést ke ztrátě dat. Než zahájíte převzetí služeb při selhání spravované zákazníkem, rozhodněte se, jestli obnovení služby odůvodňuje riziko ztráty dat.
Oznámení: Microsoft vás automaticky neoznámí, když je oblast mimo provoz. Nicméně:
Azure Resource Health můžete použít k monitorování stavu jednotlivých prostředků a můžete nastavit upozornění služby Resource Health , která vás upozorní na problémy.
Pomocí služby Azure Service Health můžete porozumět celkovému stavu služby, včetně všech selhání oblastí, a můžete nastavit upozornění služby Service Health , která vás upozorní na problémy.
Aktivní požadavky: Během procesu převzetí služeb při selhání jsou koncové body primárního i sekundárního účtu úložiště dočasně nedostupné pro čtení i zápis. Jakékoli aktivní požadavky mohou být zrušeny a klientské aplikace musí opakovat pokus po dokončení převzetí služeb při selhání.
Očekávaná ztráta dat: Ztráta dat je běžná během neplánovaného převzetí služeb při selhání kvůli prodlevě asynchronní replikace, což znamená, že nedávné zápisy nemusí být replikovány. Můžete zkontrolovat vlastnost Čas poslední synchronizace a zjistit, kolik dat může být ztraceno během neplánovaného převzetí služeb při selhání. Očekávaná ztráta dat se často označuje jako cíl bodu obnovení (RPO). Obvykle můžete očekávat, že RPO bude méně než 15 minut, ale tento čas není zaručen.
Očekávaný výpadek: Očekávané výpadky se často označují jako plánovaná doba obnovení (RTO). Zotavení po selhání spravovaného zákazníkem se obvykle dokončí během 60 minut, v závislosti na velikosti a složitosti účtu.
Přesměrování provozu: Jakmile se převzetí služeb při selhání dokončí, Azure automaticky aktualizuje koncové body účtu úložiště, aby aplikace nemusely být znovu nakonfigurované. Pokud vaše aplikace uchovává záznamy DNS (Domain Name System) v mezipaměti, může být nutné vymazat mezipaměť, aby aplikace odesílala provoz do nové primární oblasti.
Konfigurace po převzetí služeb při selhání: Po dokončení neplánovaného převzetí služeb při selhání použije váš účet úložiště v cílové oblasti místně redundantní úroveň úložiště (LRS). Pokud ho potřebujete geograficky replikovat znovu, musíte znovu povolit geograficky redundantní úložiště (GRS) a počkat na replikaci dat do nové sekundární oblasti.
Další informace o tom, jak iniciovat převzetí služeb při selhání spravované zákazníkem, najdete v tématu Fungování převzetí služeb při selhání spravovaného zákazníkem (neplánované) a zahájení převzetí služeb při selhání účtu úložiště.
Převzetí služeb při selhání spravované zákazníkem (plánované): Pokud úložiště zůstane funkční v primární oblasti, použijte plánované převzetí služeb při selhání, ale z jiného důvodu musíte převzít služby při selhání celého řešení do sekundární oblasti. Například u jiné služby Azure může docházet k problému a potřebujete přejít na použití sekundární oblasti pro celé řešení. Nebo můžete použít plánované převzetí služeb při selhání k provedení cvičení obnovy po havárii (DR) pro účely dodržování předpisů a auditu.
Detekce a odpověď: Zodpovídáte za rozhodnutí o převzetí provozu. Toto rozhodnutí obvykle provedete v případě, že potřebujete provést přepnutí mezi regiony, i když je váš účet úložiště v pořádku. Můžete například aktivovat převzetí služeb při selhání, pokud dojde k závažnému výpadku jiné součásti aplikace, ze které se v primární oblasti nemůžete zotavit.
Oznámení: Microsoft vás automaticky neoznámí, když je oblast mimo provoz. Nicméně:
Azure Resource Health můžete použít k monitorování stavu jednotlivých prostředků a můžete nastavit upozornění služby Resource Health , která vás upozorní na problémy.
Pomocí služby Azure Service Health můžete porozumět celkovému stavu služby, včetně všech selhání oblastí, a můžete nastavit upozornění služby Service Health , která vás upozorní na problémy.
Aktivní požadavky: Během procesu převzetí služeb při selhání jsou koncové body primárního i sekundárního účtu úložiště dočasně nedostupné pro čtení i zápis. Jakékoli aktivní požadavky mohou být zrušeny a klientské aplikace musí opakovat pokus po dokončení převzetí služeb při selhání.
Očekávaná ztráta dat: Neočekává se žádná ztráta dat, protože proces převzetí služeb při selhání proběhne až po synchronizaci všech dat, což vede k RPO rovný nule.
Očekávaný výpadek: Převzetí služeb při selhání se obvykle dokončí do 60 minut, což znamená, že očekávaná doba obnovy (RTO) je přibližně 60 minut, v závislosti na velikosti účtu a složitosti. Během procesu přepnutí jsou koncové body primárního i sekundárního účtu úložiště dočasně nedostupné pro čtení i zápis.
Přesměrování provozu: Jakmile se převzetí služeb při selhání dokončí, Azure automaticky aktualizuje koncové body účtu úložiště, aby aplikace nemusely být znovu nakonfigurované. Pokud vaše aplikace uchovává záznamy DNS v mezipaměti, může být nutné vymazat mezipaměť, aby se zajistilo, že aplikace odesílá provoz do nové primární oblasti.
Konfigurace po převzetí služeb: Po dokončení plánovaného převzetí služeb se váš účet úložiště v cílovém regionu bude dál geograficky replikovat a zůstane na úrovni GRS.
Další informace o tom, jak iniciovat převzetí služeb při selhání spravované zákazníkem, najdete v tématu Fungování převzetí služeb při selhání spravovaného zákazníkem (plánované) a zahájení převzetí služeb při selhání účtu úložiště.
Převzetí služeb při selhání řízené Microsoftem: V ojedinělých případech závažné havárie, kdy Microsoft zjistí, že primární oblast je nenávratně poškozená, může být zahájeno automatické převzetí služeb sekundární oblasti při selhání. Microsoft zpracovává celý proces a nevyžaduje žádnou akci zákazníka. Doba, která uplyne před převzetím služeb při selhání, závisí na závažnosti havárie a času potřebném k vyhodnocení situace.
Oznámení: Microsoft vás automaticky neoznámí, když je oblast mimo provoz. Nicméně:
Azure Resource Health můžete použít k monitorování stavu jednotlivých prostředků a můžete nastavit upozornění služby Resource Health , která vás upozorní na problémy.
Pomocí služby Azure Service Health můžete porozumět celkovému stavu služby, včetně všech selhání oblastí, a můžete nastavit upozornění služby Service Health , která vás upozorní na problémy.
Důležité
Využijte možnosti převzetí služeb při poruše spravované zákazníkem k vývoji, testování a implementaci vašich plánů zotavení po havárii. Nespoléhejte na převzetí služeb při selhání spravovaném Microsoftem, které se může používat jenom za extrémních okolností. Převzetí služeb při selhání spravované Microsoftem je pravděpodobně zahájeno pro celou oblast. Nelze jej zahájit pro jednotlivé účty úložiště, předplatná nebo zákazníky. Převzetí služeb při selhání může probíhat v různých časech pro různé služby Azure. Doporučujeme použít převzetí služeb při selhání spravované zákazníkem.
Obnovení oblasti
Proces navrácení služeb po obnovení se výrazně liší ve scénářích převzetí služeb při selhání spravovaných Microsoftem a spravovanými zákazníky.
Převzetí služeb při selhání spravované zákazníkem (neplánované): Po neplánovaném převzetí služeb při selhání se účet úložiště nakonfiguruje s místně redundantním úložištěm (LRS). Pokud chcete provést navrácení služeb po obnovení, musíte znovu vytvořit vztah geograficky redundantního úložiště (GRS) a počkat na replikaci dat.
Převzetí služeb při selhání spravované zákazníkem (plánované): Po plánovaném převzetí služeb při selhání zůstane účet úložiště geograficky replikovaný. Můžete zahájit další převzetí služeb při selhání spravované zákazníkem a navrátit služby po obnovení do původní primární oblasti. Platí stejné úvahy o převzetí služeb při selhání.
Převzetí služeb při selhání spravované Microsoftem: Pokud Microsoft zahájí převzetí služeb při selhání, pravděpodobně dojde k významné havárii v primární oblasti a primární oblast nemusí být obnovitelná. Všechny časové osy nebo plány obnovení závisí na rozsahu regionálního úsilí o havárii a zotavení po havárii. Monitorujte komunikaci služby Azure Service Health pro podrobnosti.
Testování selhání regionů
Můžete simulovat regionální selhání a otestovat postupy zotavení po havárii.
Plánované testování převzetí služeb při selhání: U účtů geograficky redundantního úložiště (GRS) můžete během období údržby provádět plánované operace převzetí služeb při selhání a otestovat celý proces převzetí služeb při selhání a navrácení služeb po obnovení. Plánované převzetí služeb při selhání nevyžaduje ztrátu dat, ale zahrnuje výpadky během převzetí služeb při selhání i navrácení služeb po obnovení.
Testování sekundárního koncového bodu: V případě geograficky redundantního úložiště s přístupem pro čtení (RA-GRS) a konfigurací geograficky zónově redundantního úložiště s přístupem pro čtení (RA-GZRS) pravidelně testujte operace čtení na sekundárním koncovém bodu, abyste zajistili, že vaše aplikace dokáže úspěšně číst data ze sekundární oblasti.
Vlastní řešení pro více regionů pro odolnost systémů
Možnosti převzetí služeb při selhání mezi oblastmi služby Azure Storage můžou být nevhodné z následujících důvodů:
Váš účet úložiště je v nepárovaném regionu.
Vaše obchodní cíle dostupnosti nejsou splněny dobou obnovy ani ztrátou dat, které nabízejí integrované možnosti při selhání systému.
Musíte převzít služby při selhání do oblasti, která není párem primární oblasti.
Potřebujete aktivní/aktivní konfiguraci napříč oblastmi.
Tato část obsahuje základní přehled některých přístupů, které je potřeba zvážit. Komplexní přehled topologií nasazení ve více oblastech pro Azure Storage je mimo rozsah tohoto článku.
Azure Storage můžete nasadit napříč několika oblastmi pomocí samostatných účtů úložiště v každé oblasti. Tento přístup poskytuje flexibilitu při výběru oblastí, možnost používat neprůplné oblasti a podrobnější kontrolu nad načasováním replikace a konzistencí dat. Při implementaci více účtů úložiště napříč oblastmi je potřeba nakonfigurovat replikaci dat mezi oblastmi, implementovat vyrovnávání zatížení a zásady převzetí služeb při selhání a zajistit konzistenci dat napříč oblastmi.
Replikace objektů poskytuje další možnost pro replikaci dat mezi oblastmi, která poskytuje asynchronní kopírování objektů blob bloku mezi účty úložiště. Na rozdíl od předdefinovaných geograficky redundantních možností úložiště, které používají pevné spárované oblasti, umožňuje replikace objektů replikovat data mezi účty úložiště v libovolné oblasti Azure, včetně nepapírovaných oblastí. Tento přístup poskytuje úplnou kontrolu nad zdrojovými a cílovými oblastmi, zásadami replikace a konkrétními kontejnery a předponami objektů blob, které se mají replikovat.
Replikaci objektů můžete nakonfigurovat tak, aby replikovali všechny objekty blob v rámci kontejneru nebo konkrétní podmnožinu na základě předpon objektů blob a značek. Replikace je asynchronní a probíhá na pozadí. Můžete nakonfigurovat více zásad replikace a dokonce zřetězovat replikaci napříč několika účty úložiště a vytvářet sofistikované topologie s více oblastmi.
Replikace objektů není kompatibilní se všemi účty úložiště. Například nefunguje s účty úložiště, které používají hierarchické obory názvů (označované také jako účty Azure Data Lake Storage Gen2).
Další informace najdete v tématu Replikace objektů blob bloku a Konfigurace replikace objektů.
Zálohování a obnovování
Blob Storage poskytuje několik mechanismů ochrany dat, které doplňují redundanci pro komplexní strategie zálohování. Integrovaná redundance služby chrání před selháními infrastruktury a další funkce zálohování chrání před náhodným odstraněním, poškozením a škodlivými aktivitami.
Obnovení k určitému bodu v čase (PITR) umožňuje obnovit data objektů blob bloku do předchozího stavu během nakonfigurované doby uchovávání až do 365 dnů. Microsoft tuto funkci plně spravuje. Poskytuje také podrobné možnosti obnovení na úrovni kontejneru nebo objektu blob. Data pitR se ukládají ve stejné oblasti jako zdrojový účet a jsou přístupná i během oblastních výpadků, pokud používáte geograficky redundantní konfigurace.
Správa verzí objektů blob automaticky udržuje předchozí verze objektů blob při jejich úpravě nebo odstranění. Každá verze je uložená jako samostatný objekt a dá se k němu přistupovat nezávisle. Verze se ukládají ve stejné oblasti jako aktuální objekt blob a dodržují stejnou konfiguraci redundance jako účet úložiště.
Obnovitelné odstranění poskytuje bezpečnostní síť pro náhodně odstraněné objekty blob a kontejnery tím, že uchovává odstraněná data po konfigurovatelnou dobu. Obnovitelně odstraněná data zůstanou ve stejném účtu úložiště a oblasti, takže jsou okamžitě k dispozici pro obnovení. U geograficky redundantních účtů se obnovitelně odstraněná data replikují také do sekundární oblasti.
Snímky objektů blob vytvářejí kopie objektů blob jen pro čtení a kopie objektů blob k určitému bodu v čase, které můžete použít pro scénáře zálohování a obnovení. Snímky se ukládají ve stejném účtu úložiště a dodržují stejná nastavení redundance a geografické replikace jako základní objekt blob.
V případě požadavků na zálohování mezi oblastmi zvažte použití služby Azure Backup pro objekty blob, které poskytuje centralizovanou správu zálohování a může ukládat zálohovaná data v oblastech, které se liší od zdrojových dat. Tato služba poskytuje možnosti provozního a trezoru zálohování, které mají konfigurovatelné zásady uchovávání informací a možnosti obnovení. Další informace najdete v tématu Zálohování objektů blob s přehledem.
U většiny řešení byste se neměli spoléhat výhradně na zálohy. Místo toho využijte další funkce popsané v tomto průvodci k podpoře vašich požadavků na odolnost. Zálohy ale chrání před některými riziky, která jiné přístupy nechrání. Další informace najdete v tématu Co jsou redundance, replikace a zálohování?.
Smlouva o úrovni služeb
Smlouva o úrovni služeb (SLA) pro Azure Storage popisuje očekávanou dostupnost služby a podmínky, které musí být splněny, aby bylo možné očekávat dostupnost. Smlouva SLA dostupnosti, pro kterou máte nárok, závisí na úrovni úložiště a na typu replikace, který používáte. Další informace najdete v tématu Smlouvy SLA pro online služby.