Poznámka
Přístup k této stránce vyžaduje autorizaci. Můžete se zkusit přihlásit nebo změnit adresáře.
Přístup k této stránce vyžaduje autorizaci. Můžete zkusit změnit adresáře.
V tomto článku se dozvíte, jak automaticky škálovat úlohy GPU ve službě Azure Kubernetes Service (AKS) pomocí metrik GPU shromážděných vývozcem GPU Manageru (DCGM) NVIDIA Data Center. Tyto metriky jsou vystaveny prostřednictvím Azure Managed Prometheus a využívají je Kubernetes Event-Driven Autoscaling (KEDA) k automatickému škálování úloh na základě reálného využití GPU. Toto řešení pomáhá optimalizovat využití prostředků GPU a řídit provozní náklady tím, že dynamicky upravuje škálování aplikace v reakci na poptávku po úlohách.
Požadavky
-
Azure CLI verze 2.60.0 nebo novější Verzi zjistíte spuštěním příkazu
az --version. Pokud potřebujete instalovat nebo upgradovat, podívejte se na Install Azure CLI. - Nainstalovaný Helm verze 3.17.0 nebo novější.
- nainstalovaný kubectl verze 1.28.9 nebo novější.
- Kvóta GPU NVIDIA ve vašem předplatném Azure. Tento příklad používá skladovou
Standard_NC40ads_H100_v5položku, ale podporují se také jiné skladové položky virtuálních počítačů NVIDIA H100.
Než budete pokračovat, ujistěte se, že je cluster AKS nakonfigurovaný takto:
- Integrujte KEDA s vaším clusterem Azure Kubernetes Service
- Monitorujte metriky GPU z vývozce NVIDIA DCGM pomocí Azure Managed Prometheus a Azure Managed Grafana.
V tuto chvíli byste měli mít:
- Cluster AKS s fondy uzlů s podporou GRAFICKÉHO PROCESORu NVIDIA a gpu se potvrdil jako schedlitelný.
- Služba Azure Managed Prometheus a Grafana povolená v clusteru AKS KeDA je ve vašem clusteru povolená.
- Spravovaná identita přiřazená uživatelem používaná nástrojem KEDA přiřadila
Monitoring Data Readerroli vymezenou pracovnímu prostoru služby Azure Monitor přidruženému k vašemu clusteru AKS.
Vytvoření nového škálovače KEDA pomocí metrik exportéru NVIDIA DCGM
K vytvoření škálovače KEDA potřebujete dvě komponenty:
- Koncový bod dotazu Prometheus
- Spravovaná identita přiřazená uživatelem.
Načíst koncový bod dotazu pro Azure Managed Prometheus
Tuto hodnotu najdete v části Přehled pracovního prostoru služby Azure Monitor připojeného ke clusteru AKS na webu Azure Portal.
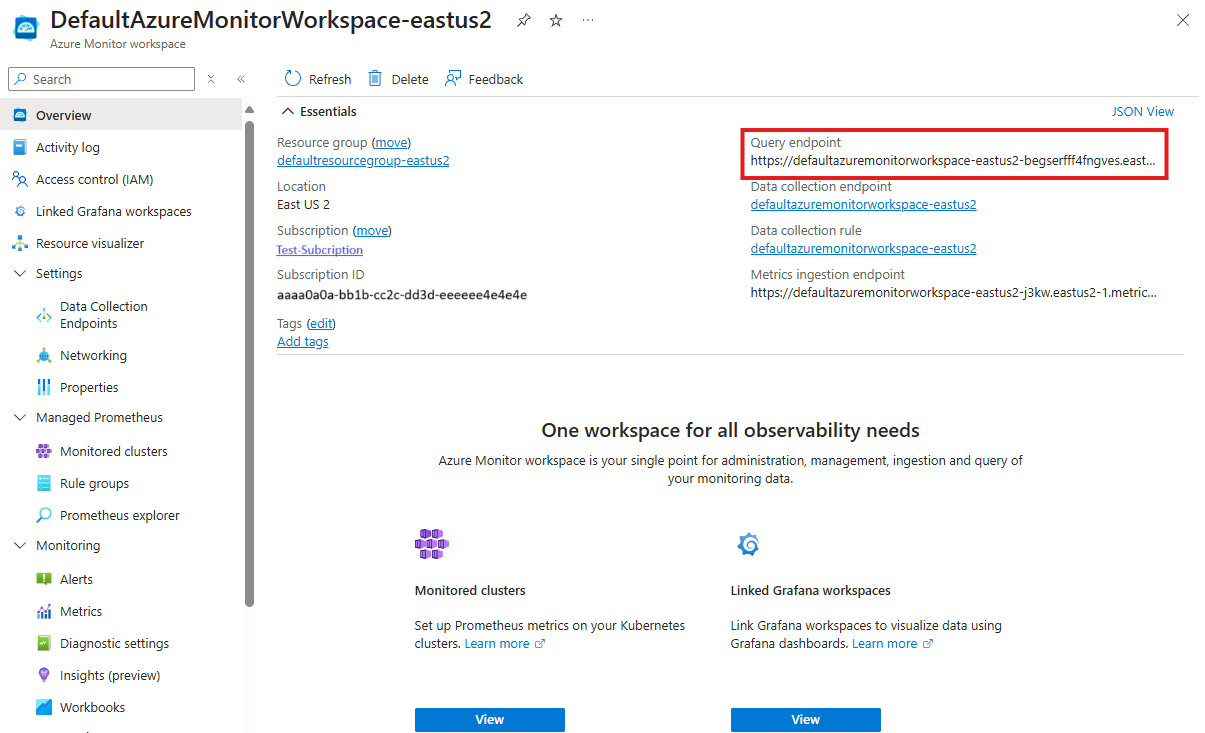
Exportujte koncový bod dotazu Azure Managed Prometheus do proměnné prostředí.
export PROMETHEUS_QUERY_ENDPOINT="https://example.prometheus.monitor.azure.com"
Načtení spravované identity přiřazené uživatelem
Spravovaná identita přiřazená uživatelem byla dříve vytvořena podle kroků integrace KEDA. V případě potřeby znovu načtěte tuto hodnotu pomocí az identity show příkazu:
export USER_ASSIGNED_CLIENT_ID="$(az identity show --resource-group $RESOURCE_GROUP --name $USER_ASSIGNED_IDENTITY_NAME --query 'clientId' -o tsv)"
Vytvoření manifestu škálování KEDA
Tento manifest vytvoří TriggerAuthentication a ScaledObject pro automatické škálování na základě využití GPU měřeného metrikou DCGM_FI_DEV_GPU_UTIL.
Poznámka:
V tomto příkladu DCGM_FI_DEV_GPU_UTIL se používá metrika, která měří využití GPU. Další metriky jsou také dostupné od vývozce DCGM v závislosti na vašich požadavcích na úlohy. Úplný seznam dostupných metrik najdete v dokumentaci k exportéru NVIDIA DCGM.
| Pole | Popis |
|---|---|
metricName |
Určuje metriku GPU, která se má monitorovat.
DCGM_FI_DEV_GPU_UTIL hlásí procento času, po který GPU aktivně zpracovává úlohy. Tato hodnota se obvykle pohybuje od 0 do 100. |
query |
Dotaz PromQL, který vypočítá průměrné využití GPU napříč všemi pody v nasazení my-gpu-workload. Tím se zajistí, že rozhodnutí o škálování jsou založená na celkovém využití GPU, nikoli na jednom podu. |
threshold |
Cílové průměrné procento využití GPU, které aktivuje škálování. Pokud průměr překročí 5%, škálovač zvýší počet replik podů. |
activationThreshold |
Minimální průměrné využití GPU potřebné k aktivaci škálování. Pokud je využití nižší než 2%, nedojde k akcím škálování, což zabrání zbytečnému škálování během období nízké aktivity. |
Vytvořte následující manifest KEDA:
cat <<EOF > keda-gpu-scaler-prometheus.yaml apiVersion: keda.sh/v1alpha1 kind: TriggerAuthentication metadata: name: azure-managed-prometheus-trigger-auth spec: podIdentity: provider: azure-workload identityId: ${USER_ASSIGNED_CLIENT_ID} --- apiVersion: keda.sh/v1alpha1 kind: ScaledObject metadata: name: my-gpu-workload spec: scaleTargetRef: name: my-gpu-workload minReplicaCount: 1 maxReplicaCount: 20 triggers: - type: prometheus metadata: serverAddress: ${PROMETHEUS_QUERY_ENDPOINT} metricName: DCGM_FI_DEV_GPU_UTIL query: avg(DCGM_FI_DEV_GPU_UTIL{deployment="my-gpu-workload"}) threshold: '5' activationThreshold: '2' authenticationRef: name: azure-managed-prometheus-trigger-auth EOFPoužijte tento manifest pomocí
kubectl applypříkazu:kubectl apply -f keda-gpu-scaler-prometheus.yaml
Testování nových možností škálování
Vytvořte ukázkovou úlohu, která využívá prostředky GPU v clusteru AKS. Můžete začít následujícím příkladem:
cat <<EOF > my-gpu-workload.yaml apiVersion: apps/v1 kind: Deployment metadata: name: my-gpu-workload namespace: default spec: replicas: 1 selector: matchLabels: app: my-gpu-workload template: metadata: labels: app: my-gpu-workload spec: tolerations: - key: "sku" operator: "Equal" value: "gpu" effect: "NoSchedule" containers: - name: my-gpu-workload image: mcr.microsoft.com/azuredocs/samples-tf-mnist-demo:gpu command: ["/bin/sh"] args: ["-c", "while true; do python /app/main.py --max_steps=500; done"] resources: limits: nvidia.com/gpu: 1 EOFPoužijte tento manifest nasazení pomocí
kubectl applypříkazu:kubectl apply -f my-gpu-workload.yamlPoznámka:
Pokud momentálně nejsou k dispozici žádné uzly GPU, pod zůstane ve stavu
Pendingaž do zajištění uzlu a zobrazí se následující zpráva:Events: Type Reason Age From Message ---- ------ ---- ---- ------- Warning FailedScheduling 3m19s default-scheduler 0/2 nodes are available: 2 Insufficient nvidia.com/gpu. preemption: 0/2 nodes are available: 2 No preemption victims found for incoming pod.Automatické škálování clusteru se nakonec spustí a zřídí nový uzel GPU:
Normal TriggeredScaleUp 2m43s cluster-autoscaler pod triggered scale-up: [{aks-gpunp-36854149-vmss 0->1 (max: 2)}]Poznámka:
V závislosti na velikosti zřízené skladové položky GPU může zřizování uzlů trvat několik minut.
Pokud chcete ověřit průběh, zkontrolujte události Horizontal Pod Autoscaler (HPA) pomocí příkazu
kubectl describe.kubectl describe hpa my-gpu-workloadVýstup by měl vypadat takto:
Conditions: Type Status Reason Message ---- ------ ------ ------- AbleToScale True ReadyForNewScale recommended size matches current size ScalingActive True ValidMetricFound the HPA successfully calculated a replica count from external metric s0-prometheus(&LabelSelector{MatchLabels:map[string]string{scaledobject.keda.sh/name: my-gpu-workload}}) ScalingLimited True TooFewReplicas the desired replica count is less than the minimum replica countOvěřte, že je přidaný uzel GPU a že pod běží pomocí
kubectl getpříkazu:kubectl get nodesVýstup by měl vypadat takto:
NAME STATUS ROLES AGE VERSION aks-gpunp-36854149-vmss000005 Ready <none> 4m36s v1.31.7 aks-nodepool1-34179260-vmss000002 Ready <none> 26h v1.31.7 aks-nodepool1-34179260-vmss000003 Ready <none> 26h v1.31.7
Snižte velikost fondu uzlů GPU
Pokud chcete vertikálně snížit kapacitu fondu uzlů GPU, odstraňte nasazení úloh pomocí kubectl delete příkazu:
kubectl delete deployment my-gpu-workload
Poznámka:
Fond uzlů můžete nakonfigurovat tak, aby se snížil na nulu, tím že povolíte automatické škálování clusteru a nastavíte min-count hodnotu 0 při vytváření fondu uzlů. Například:
az aks nodepool add \
--resource-group myResourceGroup \
--cluster-name myAKSCluster \
--name gpunp \
--node-count 1 \
--node-vm-size Standard_NC40ads_H100_v5 \
--node-taints sku=gpu:NoSchedule \
--enable-cluster-autoscaler \
--min-count 0 \
--max-count 3
Další kroky
- Nasazení úlohy s GPU (MIG) s více instancemi na AKS.
- Prozkoumejte KAITO v AKS pro odvozování a vyladění AI.
- Přečtěte si další informace o Ray clusterech v AKS.
Spolupracujte s námi na GitHubu
Zdroj tohoto obsahu najdete na GitHubu, kde můžete také vytvářet a kontrolovat problémy a žádosti o přijetí změn. Další informace najdete v našem průvodci pro přispěvatele.

Azure Kubernetes Service