Tento článek popisuje alternativní přístup k projektům datového skladu, kterým se říká průzkumná analýza dat (EDA). Tento přístup může snížit problémy operací extrakce, transformace, načítání (ETL). Nejprve se zaměřuje na generování obchodních přehledů a pak se obrátí na řešení úloh modelování a ETL.
Architektura

Stáhněte si soubor aplikace Visio s touto architekturou.
U EDA se zabýváte pouze pravou stranou diagramu. Bezserverový modul Azure Synapse SQL se používá jako výpočetní modul pro soubory Data Lake.
K dosažení EDA:
- Dotazy T-SQL běží přímo v Bezserverové službě Azure Synapse SQL nebo Azure Synapse Spark.
- Dotazy se spouštějí z grafického nástroje pro dotazy, jako je Power BI nebo Azure Data Studio.
Doporučujeme zachovat všechna data lakehouse pomocí Parquet nebo Delta.
Levou stranu diagramu (příjem dat) můžete implementovat pomocí libovolného nástroje pro extrakci, načtení, transformaci (ELT). Nemá žádný vliv na EDA.
Komponenty
Azure Synapse Analytics kombinuje integraci dat, skladování podnikových dat a analýzu velkých objemů dat přes data lakehouse. V tomto řešení:
- Pracovní prostor Azure Synapse podporuje spolupráci mezi datovými inženýry, datovými vědci, datovými analytiky a odborníky na business intelligence (BI) pro úlohy EDA.
- Bezserverové fondy SQL Azure Synapse analyzují nestrukturovaná a částečně strukturovaná data ve službě Azure Data Lake Storage pomocí standardního T-SQL.
- Bezserverové fondy Apache Sparku Ve službě Azure Synapse se ve službě Data Lake Storage poprvé zkoumá kód pomocí jazyků Spark, jako je Spark SQL, PySpark a Scala.
Azure Data Lake Storage poskytuje úložiště pro data, která se pak analyzují bezserverovými fondy SQL Azure Synapse.
Azure Machine Učení poskytuje data do Azure Synapse Sparku.
Power BI se v tomto řešení používá k dotazování dat k dosažení EDA.
Alternativy
Bezserverové fondy Synapse SQL můžete nahradit nebo doplnit pomocí Azure Databricks.
Místo použití modelu lakehouse s bezserverovými fondy Synapse SQL můžete k ukládání podnikových dat použít vyhrazené fondy SQL Služby Synapse. Projděte si případy použití a důležité informace v tomto článku a související zdroje informací a rozhodněte se, kterou technologii použít.
Podrobnosti scénáře
Toto řešení ukazuje implementaci přístupu EDA k projektům datového skladu. Tento přístup může snížit problémy operací ETL. Nejprve se zaměřuje na generování obchodních přehledů a pak se obrátí na řešení úloh modelování a ETL.
Potenciální případy použití
Další scénáře, které můžou těžit z tohoto analytického modelu:
Preskriptivní analýza. Položte otázky k vašim datům, jako je další nejlepší akce, nebo co uděláme dál? Používejte data k tomu, aby byla více řízená daty a byla méně řízena gutem. Data můžou být nestrukturovaná a z mnoha externích zdrojů různé kvality. Data můžete použít co nejrychleji k vyhodnocení obchodní strategie bez skutečného načtení dat do datového skladu. Po zodpovězení otázek můžete data odstranit.
Samoobslužné ETL. Proveďte ETL/ELT při aktivitách sandboxu dat (EDA). Transformujte data a udělejte je cennou. To může zlepšit škálování vývojářů ETL.
Informace o průzkumné analýze dat
Než se podrobněji podíváme na to, jak EDA funguje, stojí za to shrnout tradiční přístup k projektům datového skladu. Tradiční přístup vypadá takto:
Shromažďování požadavků Zdokumentujte, co s daty dělat.
Modelování dat Určete, jak modelovat číselná data a data atributů do tabulek faktů a dimenzí. Tradičně tento krok provedete před získáním nových dat.
ETL. Získejte data a masírujte je do datového modelu datového skladu.
Tyto kroky můžou trvat týdny nebo dokonce měsíce. Teprve pak můžete začít dotazovat data a vyřešit obchodní problém. Uživatel uvidí hodnotu až po vytvoření sestav. Architektura řešení obvykle vypadá přibližně takto:
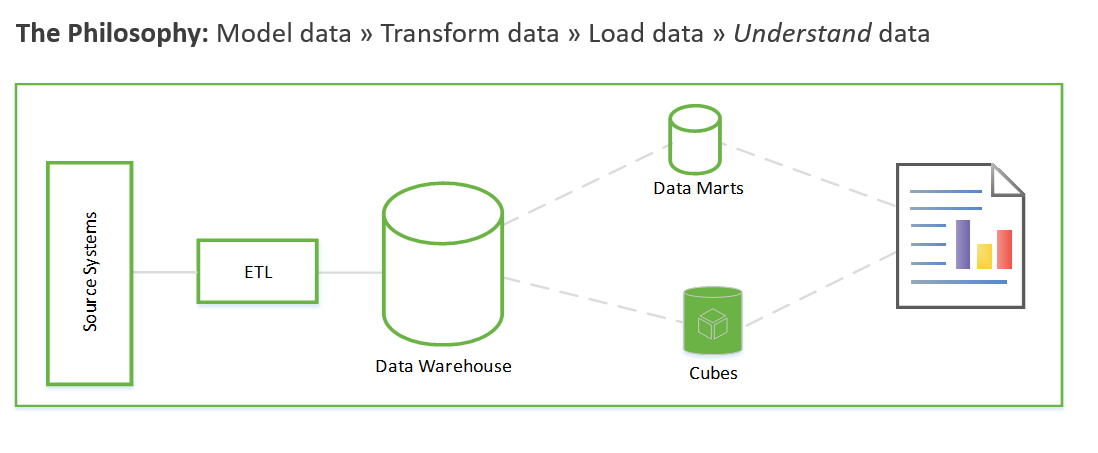
Můžete to udělat jiným způsobem, který se nejprve zaměřuje na generování obchodních přehledů a pak se obrátí na řešení úloh modelování a ETL. Proces je podobný procesům datových věd. Vypadá nějak takto:
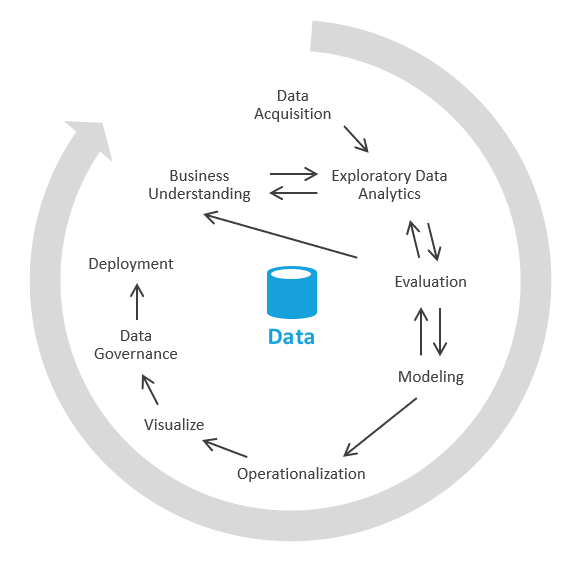
V odvětví se tento proces nazývá EDA nebo průzkumná analýza dat.
Postup je následující:
Získávání dat. Nejprve musíte určit, jaké zdroje dat potřebujete ingestovat do datového jezera nebo sandboxu. Pak je potřeba tato data přenést do cílové oblasti jezera. Azure poskytuje nástroje, jako je Azure Data Factory a Azure Logic Apps, které dokážou rychle ingestovat data.
Sandboxování dat Obchodní analytik a technik, který má zkušenosti s průzkumnou analýzou dat prostřednictvím bezserverové služby Azure Synapse Analytics nebo základního SQL, zpočátku spolupracují. Během této fáze se snaží odhalit obchodní přehled pomocí nových dat. EDA je iterativní proces. Možná budete muset ingestovat další data, mluvit s msp, klást další otázky nebo generovat vizualizace.
Vyhodnocení: Po nalezení obchodního přehledu je potřeba vyhodnotit, co s daty dělat. Možná budete chtít zachovat data do datového skladu (takže přejdete do fáze modelování). V jiných případech se můžete rozhodnout ponechat data v datovém jezeře nebo jezeře a použít je k prediktivní analýze (algoritmy strojového učení). V ostatních případech se můžete rozhodnout znovu doplnit systémy záznamů o nových přehledech. Na základě těchto rozhodnutí můžete lépe porozumět tomu, co potřebujete udělat dále. Možná nebudete muset provádět ETL.
Tyto metody jsou jádrem skutečné samoobslužné analýzy. Pomocí datového jezera a dotazovacího nástroje, jako je bezserverová platforma Azure Synapse, která rozumí vzorům dotazů data lake, můžete datové prostředky vložit do rukou obchodních lidí, kteří chápou modicum SQL. Pomocí této metody můžete výrazně zkrátit dobu na hodnotu a odebrat některá rizika spojená s iniciativami podnikových dat.
Důležité informace
Tyto aspekty implementují pilíře dobře architektuře Azure, což je sada hlavních principů, které je možné použít ke zlepšení kvality úlohy. Další informace naleznete v tématu Microsoft Azure Well-Architected Framework.
Dostupnost
Bezserverové fondy Azure Synapse SQL je funkce PaaS (Platforma jako služba), která může splňovat požadavky na vysokou dostupnost (HA) a zotavení po havárii (DR).
Bezserverové fondy jsou k dispozici na vyžádání. Nevyžadují vertikální navýšení, snížení nebo snížení kapacity ani správu jakéhokoli druhu. Používají model plateb za dotaz, takže není k dispozici žádná nevyužitá kapacita. Bezserverové fondy jsou ideální pro:
- Ad hoc zkoumání datových věd v T-SQL
- Počáteční vytváření prototypů entit datového skladu
- Definování zobrazení, která můžou uživatelé používat, například v Power BI, pro scénáře, které můžou tolerovat prodlevu výkonu.
- Průzkumná analýza dat
Operace
Bezserverová aplikace Synapse SQL používá standardní T-SQL k dotazování a operacím. Jako nástroj T-SQL můžete použít uživatelské rozhraní pracovního prostoru Synapse, Azure Data Studio nebo SQL Server Management Studio.
Optimalizace nákladů
Optimalizace nákladů se zabývá způsoby, jak snížit zbytečné výdaje a zlepšit efektivitu provozu. Další informace najdete v tématu Přehled pilíře optimalizace nákladů.
Ceny služby Data Lake Storage závisí na množství uložených dat a na tom, jak často data používáte. Ukázkové ceny zahrnují jednu TB uložených dat s dalšími transakčními předpoklady. Jedna TB odkazuje na velikost datového jezera, nikoli na velikost původní starší databáze.
Fond Azure Synapse Spark je založen na cenách velikosti uzlu, počtu instancí a doby provozu. Příklad předpokládá jeden malý výpočetní uzel s využitím mezi pěti hodinami za týden a 40 hodin za měsíc.
Bezserverový fond SQL Azure Synapse vychází z cen na databázích zpracovaných dat. Ukázka předpokládá, že 50 TB zpracovaných za měsíc. Tento obrázek odkazuje na velikost datového jezera, nikoli na velikost původní starší databáze.
Přispěvatelé
Tento článek aktualizuje a udržuje Microsoft. Původně byla napsána následujícími přispěvateli.
Hlavní autoři:
- Dave Wentzel | Hlavní technický architekt MTC
Další kroky
- studijní programy pro Datoví technici
- Kurz: Začínáme s Azure Synapse Analytics
- Vytvoření izolované databáze – Azure SQL Database
- Architektura Azure Synapse SQL
- Vytvoření účtu úložiště pro Azure Data Lake Storage
- Rychlý start služby Azure Event Hubs – Vytvoření centra událostí pomocí webu Azure Portal
- Rychlý start – Vytvoření úlohy Stream Analytics pomocí webu Azure Portal
- Rychlý start: Začínáme se službou Azure Machine Učení