Koordinuje sadu distribuovaných akcí jako jednu operaci. Pokud některá z akcí selže, pokusí se chyby zpracovat transparentně, nebo vrátí provedené změny, aby operace, ať už úspěšná nebo neúspěšná, proběhla jako celek. Tím se může zvýšit odolnost distribuovaného systému. Ten totiž bude moct provádět obnovení a opakovat akce, které selhaly kvůli přechodným výjimkám, dlouhodobým chybám i selháním procesu.
Kontext a problém
Aplikace provádí úlohy zahrnující několik kroků a některé z těchto kroků můžou volat vzdálené služby nebo přistupovat ke vzdáleným prostředkům. Jednotlivé kroky můžou být navzájem nezávislé, ale orchestruje je logika aplikace, která úlohu implementuje.
Kdykoli je to možné, aplikace by měla kontrolovat dokončení úloh a řešit všechny chyby, ke kterým může dojít během přístupu ke vzdáleným službám nebo prostředkům. K selhání může dojít z nejrůznějších důvodů. Například může dojít k výpadku sítě nebo přerušení komunikace, vzdálená služba může přestat odpovídat nebo může být v nestabilním stavu, anebo může být dočasně nedostupný vzdálený prostředek – pravděpodobně kvůli omezením prostředku. V mnoha případech bude selhání přechodné a půjde vyřešit pomocí modelu Opakování.
Pokud aplikace zjistí trvalejší chybu, u které je obnovení funkčnosti náročnější, musí být schopná obnovit systém v konzistentním stavu a zajistit integritu celé operace.
Řešení
Model plánovač-agent-správce definuje následující aktéry: Tyto aktéři řídí kroky, které se mají provést, jako dílčí části jedné úlohy.
Plánovač řídí kroky úloh, které se mají provést, a jejich operace. Tyto kroky je možné zkombinovat do kanálu nebo pracovního postupu. Plánovač zodpovídá za to, že jsou kroky v tomto pracovním postupu prováděny ve správném pořadí. Při provádění každého kroku plánovač zaznamená stav pracovního postupu, například krok, který ještě není spuštěný, krok spuštěný nebo dokončený. Informace o stavu by také měly obsahovat horní limit času, který je pro krok dokončen, označovaný jako dokončený čas. Pokud krok vyžaduje přístup ke vzdálené službě nebo prostředku, vyvolá plánovač odpovídajícího agenta a předá mu podrobnosti o činnosti, která má být provedena. Plánovač obvykle komunikuje s agentem pomocí asynchronního zasílání zpráv požadavků a odpovědí. Tento krok je možné implementovat pomocí front nebo jiných technologií pro distribuované zasílání zpráv.
Plánovač má podobnou funkci jako správce procesu v modelu správce procesu. Samotný pracovní postup je obvykle definován a implementován modulem pracovních postupů řízeným plánovačem. Tento přístup odděluje obchodní logiku v pracovním postupu od plánovače.
Agent obsahuje logiku zapouzdřující volání vzdálené služby nebo přístup ke vzdálenému prostředku, na který odkazuje daný krok úlohy. Každý agent obvykle zabalí volání jedné služby nebo prostředku a implementuje příslušnou logiku zpracování chyb a opakování pokusů (v závislosti na omezeních v podobě časových limitů popsaných níže). Při implementaci logiky opakování předejte stabilní identifikátor napříč všemi pokusy o opakování, aby ji vzdálená služba mohla použít pro jakoukoli logiku odstranění duplicitních dat, kterou může mít. Pokud různé kroky v pracovním postupu spouštěném plánovačem používají více služeb a prostředků, může každý krok odkazovat na jiného agenta (tato poznámka k implementaci se týká tohoto modelu).
Správce monitoruje stav kroků v úloze prováděné plánovačem. Spouští se pravidelně (frekvence bude specifická pro systém) a zkoumá stav kroků udržovaných plánovačem. Pokud zjistí, že některý krok selhal nebo vypršel jeho časový limit, zajistí, aby příslušný agent tento krok obnovil nebo provedl vhodnou nápravnou akci (to může zahrnovat změnu stavu kroku). Obnovení a nápravné akce jsou implementované plánovačem a agenty. Správce by měl pouze žádat o provedení těchto akcí.
Plánovač, agent a správce jsou logické komponenty a jejich fyzická implementace závisí na použité technologii. Například můžete implementovat několik logických agentů do jedné webové služby.
Plánovač uchovává informace o průběhu úlohy a stavu jednotlivých kroků v trvalém úložišti dat označovaném jako úložiště stavů. Správce může na základě těchto informací snadněji určit, zda nedošlo k selhání kroku. Na obrázku je znázorněný vztah mezi plánovačem, agenty, správcem a úložištěm stavů.
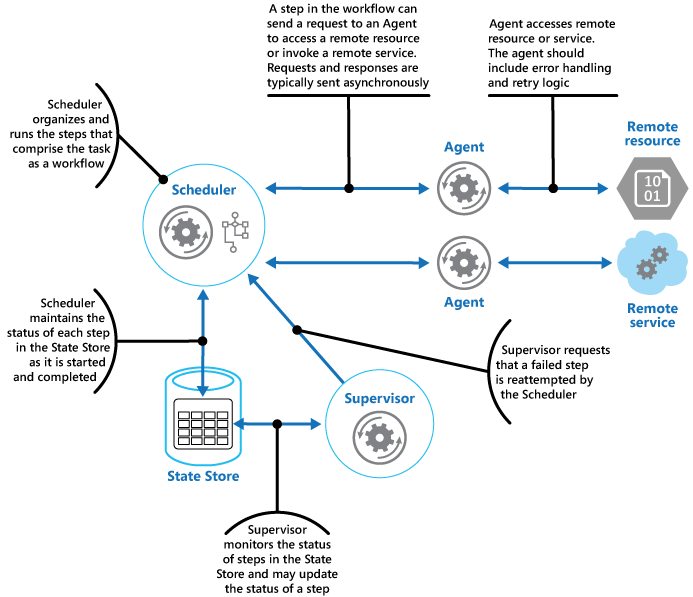
Poznámka:
Tento diagram znázorňuje zjednodušenou verzi modelu. Ve skutečné implementaci může být velký počet současně spuštěných instancí plánovače, kdy každá z nich je podmnožinou úloh. Podobně může systém spouštět více instancí jednotlivých agentů nebo dokonce více správců. V takovém případě musí vedoucí koordinovat svou práci s ostatními pečlivě, aby se ujistili, že nebudou soutěžit o obnovení stejných neúspěšných kroků a úkolů. Model volby vedoucího procesu poskytuje možné řešení tohoto problému.
Když je aplikace připravená spustit úlohu, odešle žádost plánovači. Plánovač zapíše počáteční informace o stavu úlohy a jejích kroků (například to, že krok ještě nebyl spuštěn) do úložiště stavů a potom začne provádět operace definované pracovním postupem. Pokaždé, když plánovač spustí nějaký krok, aktualizuje informace o jeho stavu v úložišti stavů (například zaznamená, že krok probíhá).
Pokud krok odkazuje na vzdálenou službu nebo prostředek, odešle plánovač zprávu příslušnému agentovi. Kromě časového limitu na dokončení operace obsahuje zpráva informace, které má agent předat službě, nebo informace potřebné pro přístup k prostředku. Pokud agent operaci dokončí úspěšně, odešle plánovači odpověď. Plánovač pak může aktualizovat informace o stavu v úložišti stavů (například zapsat, že krok je dokončený), a provést další krok. Tento proces pokračuje, dokud není dokončená celá úloha.
Pokud je potřeba, může agent implementovat jakoukoli logiku opakování pokusů. Pokud ale celou operaci nedokončí během časového limitu, bude plánovač předpokládat, že operace selhala. V takovém případě by měl agent zastavit svoji činnost, neměl by plánovači odesílat žádný výstup (ani chybovou zprávu) a ani by se neměl pokoušet o jakoukoli formu obnovení. Důvodem tohoto omezení je, že po vypršení platnosti nebo selhání daného kroku může být naplánována další instance agenta, která se má pokusit tento krok provést (tento proces je popsaný níže).
Pokud agent selže, neobdrží plánovač žádnou odpověď. Model nerozlišuje mezi krokem, u kterého vypršel časový limit, a krokem, který skutečně selhal.
Jak v případě vypršení časového limitu, tak selhání kroku bude v úložišti stavů záznam o tom, že krok probíhá, ale také, že časový limit na dokončení kroku vypršel. Správce hledá takovéto kroky a pokouší se je obnovit. Jednou zmožnýchchm řešením je, že správce aktualizuje hodnotu dokončení, aby prodloužil čas dostupný k dokončení kroku, a pak plánovači odešle zprávu s identifikací kroku, který vypršel. Plánovač se pak může pokusit tento krok zopakovat. Tento návrh ale vyžaduje, aby úkoly byly idempotentní. Systém by měl obsahovat infrastrukturu pro zachování konzistence. Další informace najdete v tématu Opakovatelná infrastruktura, architekt aplikace Azure pro zajištění odolnosti a dostupnosti a průvodce rozhodováním o konzistenci prostředků.
Správce může potřebovat zabránit opakovanému opakování stejného kroku, pokud se trvale nezdaří nebo vyprší časový limit. Za tímto účelem může správce udržovat počet opakování pro každý krok spolu s informacemi o stavu v úložišti stavů. Když tento počet překročí nastavený limit, může se správce rozhodnout počkat určitou dobu, než oznámí plánovači, že je potřeba krok zopakovat (protože předpokládá, že by během této doby mohlo dojít k vyřešení problému). Případně může správce plánovači odeslat zprávu s žádostí, aby celou úlohu zrušil implementováním modelu kompenzační transakce. Tento postup bude záviset na plánovači a agentech poskytujících informace potřebné k implementaci kompenzačních operací pro všechny kroky, které se dokončily úspěšně.
Úlohou správce není monitorovat plánovače a agenty a při jejich selhání je restartovat. Tyto akce by měla v systému zajišťovat infrastruktura, ve které tyto komponenty běží. Stejně tak by správce neměl mít informace o samotných obchodních operacích, které úlohy spouštěné plánovačem provádějí (včetně postupů kompenzace v případě jejich selhání). O tyto aspekty se stará logika pracovního postupu implementovaná plánovačem. Jediným účelem správce je sledovat úspěšné provádění kroků a v případě selhání buď zajistit jejich zopakování, nebo zrušit celou úlohu, která chybný krok obsahuje.
Pokud se plánovač z důvodu chyby restartuje, nebo neočekávaně skončí pracovní postup, který plánovač prováděl, měl by být plánovač schopný určit stav jakéhokoli příchozího úkolu, který zpracovával v okamžiku, kdy došlo k selhání, a pokračovat v jeho provádění od tohoto bodu. Podrobnosti implementace tohoto procesu budou pravděpodobně specifické pro systém. Pokud úlohu nelze obnovit, může být potřeba vrátit zpět akce, které už v rámci této úlohy proběhly. To může také vyžadovat implementaci kompenzační transakce.
Hlavní výhodou tohoto modelu je, že systém je odolný proti neočekávaným selháním, ať už dočasným, nebo neopravitelným. Systém lze vytvořit tak, aby byl samoopravený. Pokud například selže agent nebo plánovač, může být spuštěn nový a správce může zajistit obnovení úlohy. Pokud selže správce, může být spuštěna nová instance, která bude pokračovat od místa, kde došlo k chybě. Pokud je naplánované pravidelné spouštění správce, může se nová instance spustit automaticky po nastaveném intervalu. Pro ještě vyšší úroveň odolnosti je možné replikovat úložiště stavů.
Problémy a důležité informace
Když se budete rozhodovat, jak tento model implementovat, měli byste vzít v úvahu následující skutečnosti:
Tento model může být obtížné implementovat a vyžaduje důkladné testování všech možných režimů selhání systému.
Logika obnovení a opakování pokusů implementovaná plánovačem je velmi komplexní a závisí na informacích o stavu uložených v úložišti stavů. Může být také nezbytné zaznamenávat informace potřebné k implementaci kompenzační transakce v trvalém úložišti dat. Kompenzační transakce může také selhat.
Důležitým faktorem je frekvence spouštění správce. Správce by měl být spouštěn dostatečně často, aby zabránil tomu, že případné kroky, které selhaly, budou delší dobu blokovat aplikaci, ale ne tak často, aby se zvýšily režijní náklady.
Kroky prováděné agenty je možné spouštět vícekrát než jednou. Logika implementující tyto kroky by měla být idempotentní.
Kdy se má tento model použít
Tento model použijte, pokud procesy spouštěné v distribuovaném prostředí, například v cloudu, mají být odolné vůči selháním komunikace nebo provozním chybám.
Tento model nemusí být vhodný pro úlohy, které nevolají vzdálené služby ani nepřistupují ke vzdáleným prostředkům.
Návrh úloh
Architekt by měl vyhodnotit způsob použití vzoru Plánovač agenta agenta v návrhu úlohy k řešení cílů a principů popsaných v pilířích architektury Azure Well-Architected Framework. Příklad:
| Pilíř | Jak tento model podporuje cíle pilíře |
|---|---|
| Rozhodnutí o návrhu spolehlivosti pomáhají vaší úloze stát se odolnou proti selhání a zajistit, aby se po selhání obnovila do plně funkčního stavu. | Tento model používá metriky stavu ke zjišťování selhání a přesměrování úloh na agenta, který je v pořádku, aby se snížily účinky selhání. - RE:05 Redundance - RE:07 Samoopravení |
| Efektivita výkonu pomáhá vaší úloze efektivně splňovat požadavky prostřednictvím optimalizací škálování, dat a kódu. | Tento model používá metriky výkonu a kapacity ke zjištění aktuálního využití a směrování úloh do agenta, který má kapacitu. Můžete ji také použít k určení priority provádění práce s vyšší prioritou oproti práci s nižší prioritou. - PE:05 Škálování a dělení - PE:09 Kritické toky |
Stejně jako u jakéhokoli rozhodnutí o návrhu zvažte jakékoli kompromisy proti cílům ostatních pilířů, které by mohly být s tímto vzorem zavedeny.
Příklad
Příkladem může být webová aplikace, která implementuje systém elektronického obchodování, nasazená v Microsoft Azure. Uživatelé, kteří tuto aplikaci spouštějí, si můžou prohlížet dostupné produkty a zadávat objednávky. Uživatelské rozhraní je spuštěné jako webová role a prvky zpracování objednávek v aplikaci jsou implementované jako sada rolí pracovního procesu. Součástí logiky zpracování objednávek je přístup k vzdálené službě a tento aspekt systému může být příčinou přechodných i dlouhodobých chyb. Proto návrháři použili model plánovač-agent-správce, pomocí kterého do systému implementovali prvky zpracování objednávek.
Když zákazník zadá objednávku, aplikace vytvoří zprávu, která tuto objednávku popisuje, a odešle ji do fronty. Samostatný proces odeslání spuštěný v roli pracovního procesu tuto zprávu načte, vloží podrobnosti objednávky do databáze objednávek a vytvoří záznam pro proces zpracování objednávky v úložišti stavů. Vložení informací do databáze objednávek a úložiště stavů probíhá v rámci jedné operace. Proces odeslání je navržený tak, aby se oba kroky vložení dokončily současně.
Informace o stavu, které proces odeslání pro objednávku vytvoří, zahrnují tato pole:
OrderID (ID objednávky). ID objednávky v databázi objednávek.
LockedBy (Vyhrazeno pro instanci). ID instance role pracovního procesu, která objednávku zpracovává. Plánovač může spustit více instancí role pracovního procesu najednou, ale každou objednávku by měla zpracovávat vždy jen jedna instance.
CompleteBy (Dokončit do). Čas, do kdy má být objednávka zpracována.
ProcessState (Stav zpracování). Aktuální stav úlohy, která objednávku zpracovává. Možné stavy:
- Pending (Čeká na vyřízení). Objednávka byla vytvořena, ale ještě se nezačala zpracovávat.
- Processing (Zpracovává se). Objednávka se právě zpracovává.
- Processed (Zpracovaná). Objednávka byla úspěšně zpracovaná.
- Error. Zpracování objednávky se nezdařilo.
FailureCount (Počet chyb). Počet pokusů o zpracování objednávky, které proběhly.
Pole OrderID se v informacích o stavu zkopíruje z pole OrderID nové objednávky. Pole LockedBy a CompleteBy se nastaví na hodnotu null, pole ProcessState na hodnotu Pending a pole FailureCount na hodnotu 0.
Poznámka:
Logika zpracování objednávky v tomto příkladu je poměrně jednoduchá – obsahuje pouze jeden krok, který volá vzdálenou službu. V složitějším vícekrokovém scénáři by proces odeslání pravděpodobně zahrnoval několik kroků, takže v úložišti stavů by se vytvořilo několik záznamů – každý z nich popisuje stav jednotlivého kroku.
Také plánovač se spouští v rámci role pracovního procesu. Implementuje obchodní logiku, která objednávky zpracovává. Instance cyklického dotazování plánovače na nové objednávky hledá v úložišti stavů záznamy, ve kterých má pole LockedBy hodnotu null a pole ProcessState je ve stavu Pending. Když plánovač zjistí novou objednávku, okamžitě vloží do pole LockedBy ID své vlastní instance, do pole CompleteBy zadá příslušný čas a pole ProcessState změní na stav Processing. Kód je navržený jako výhradní a atomický, aby se předešlo tomu, že se dvě současně spuštěné instance plánovače pokusí zpracovat stejnou objednávku.
Plánovač pak spustí obchodní pracovní postup asynchronního zpracování objednávky, kdy tomuto pracovnímu postupu předá hodnotu pole OrderID z úložiště stavů. Pracovní postup, který objednávku zpracovává, načte podrobnosti objednávky z databáze objednávek a provede požadované operace. Když některý krok pracovního postupu zpracování objednávky potřebuje vyvolat vzdálenou službu, použije agenta. Tento krok pracovního postupu komunikuje s agentem pomocí dvojice front zpráv Azure Service Bus, které fungují jako kanál pro odesílání požadavků a přijímání odpovědí. Obrázek znázorňuje základní zobrazení řešení.
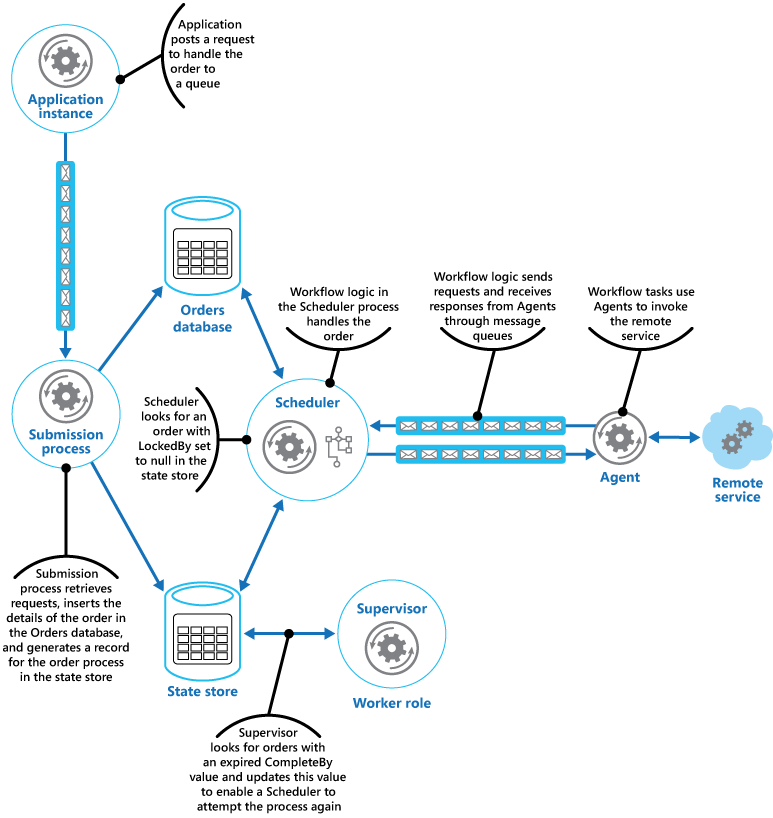
Zpráva odeslaná agentovi z kroku pracovního postupu popisuje objednávku a obsahuje časový limit na dokončení. Pokud agent obdrží odpověď ze vzdálené služby před vypršením časového limitu, odešle odpověď do fronty služby Service Bus, které pracovní postup naslouchá. Když krok pracovního postupu obdrží platnou zprávu odpovědi, dokončí zpracování a plánovač nastaví ProcessState pole stavu objednávky, které se zpracuje. V tomto okamžiku je zpracování objednávky úspěšně dokončeno.
Pokud časový limit vyprší dřív, než agent obdrží odpověď ze vzdálené služby, agent operaci jednoduše zastaví a ukončí zpracování objednávky. Stejně tak dojde k ukončení v případě překročení časového limitu pracovním postupem, který zpracovává objednávku. V obou případech zůstane stav objednávky v úložišti stavů nastavený na Processing, ale pole časového limitu bude označovat, že čas na dokončení objednávky vypršel, a proces se bude považovat za neúspěšný. Všimněte si, že pokud dojde k neočekávanému ukončení agenta, který přistupuje ke vzdálené službě, nebo pracovního postupu, který zpracovává objednávku, (nebo obou), zůstane i v tomto případě informace v úložišti stavů nastavená na Processing a hodnota pole časového limitu bude po uplynutí odpovídající doby označovat, že limit vypršel.
Pokud agent během pokusu o kontaktování vzdálené služby zjistí neopravitelnou chybu, která není přechodná, může o chybě informovat pracovní postup. Plánovač může u objednávky nastavit chybový stav a vyvolat událost, která odešle výstrahu operátorovi. Operátor pak může zkusit příčinu selhání vyřešit ručně a obnovit zpracování příslušného neúspěšného kroku.
Správce pravidelně kontroluje úložiště stavů a hledá objednávky, u kterých vypršel časový limit. Pokud správce nějaký takový záznam najde, inkrementuje pole FailureCount. Pokud je hodnota počtu selhání nižší než zadaná prahová hodnota, pak správce resetuje pole LockedBy na hodnotu null, aktualizuje pole CompleteBy na nový čas vypršení platnosti a v poli ProcessState nastaví hodnotu Pending. Instance plánovače může tuto objednávku převzít a zopakovat pokus o její zpracování. Jakmile hodnota počtu selhání překročí zadanou prahovou hodnotu, předpokládá se, že příčina selhání je trvalá. Správce nastaví u objednávky chybový stav a vyvolá událost, která odešle výstrahu operátorovi.
V tomto příkladu je správce implementovaný v samostatné roli pracovního procesu. Ke spuštění úlohy správce můžete přistoupit různými způsoby, například použít službu Azure Scheduler (neplést s komponentou plánovače v tomto modelu). Další informace o službě Azure Scheduler najdete na stránce Scheduler.
I když to tento příklad neukazuje, plánovač může chtít, aby byla aplikace, která objednávku odeslala, informována o průběhu a stavu této objednávky. Aplikace a plánovač jsou navzájem oddělené, aby se předešlo vzniku případných závislostí mezi nimi. Aplikace nemá žádné informace o tom, která instance plánovače objednávku zpracovává, a plánovač nemá žádné informace o tom, která instance aplikace objednávku odeslala.
K povolení reportování stavu objednávky může aplikace použít svoji vlastní privátní frontu odpovědí. Podrobnosti o této frontě odpovědí by byly zahrnuty do žádosti předané procesu odeslání, který by tyto informace uložil spolu s ostatními v úložišti stavů. Plánovač by pak do této fronty odesílal zprávy o stavu objednávky (například Žádost přijata, Objednávka dokončena, Zpracování objednávky selhalo apod.). V těchto zprávách je potřeba uvádět ID objednávek, aby mohly být přiřazeny k původním žádostem z aplikace.
Další kroky
Při implementaci tohoto modelu můžou být relevantní také následující pokyny:
Úvod k asynchronnímu zasílání zpráv: Komponenty modelu plánovač-agent-správce obvykle běží navzájem odděleně a komunikují asynchronně. Popisuje některé z přístupů, které lze použít k implementaci asynchronní komunikaci na základě front zpráv.
Referenční dokumentace 6: Sága o používání ság. Příklad znázorňující použití správce procesu modelem CQRS (součást dokumentace systému CQRS).
Související prostředky
Při implementaci tohoto modelu můžou být relevantní také následující vzory:
Model opakování. Agent může tento model použít k transparentnímu opakování neúspěšných operací, které přistupují k vzdálené službě nebo prostředku. Používejte ho, pokud očekáváte, že příčina selhání je přechodná a chyba bude opravena.
Model Jistič. Agent může pomocí tohoto modelu zpracovávat chyby připojení ke vzdálené službě nebo prostředku, jejichž oprava trvá různě dlouho.
Model kompenzační transakce: Pokud pracovní postup prováděný plánovačem nemůže být dokončen úspěšně, může být potřeba vrátit zpět veškeré dříve provedené akce. Model kompenzační transakce popisuje, jak to provést u operací, které se řídí modelem konzistence typu Případné. Tyto typy operací implementuje běžně plánovač, který provádí komplexní obchodní procesy a pracovní postupy.
Model volby vedoucího procesu. Může být potřeba koordinovat akce více instancí správce, a předejít tak tomu, aby se více instancí pokoušelo obnovit stejný neúspěšný proces. Jak to udělat, popisuje model volby vedoucího procesu.
Architektura cloudu: Model Scheduler-Agent-Supervisor na blogu Clemens Vasters