Rozděluje úložiště dat do sady horizontálních oddílů. Může to zlepšit škálovatelnost při ukládání a zobrazování velkých objemů dat.
Kontext a problém
Úložiště dat hostované jediným serverem může podléhat následujícím omezením:
Prostor úložiště: U úložiště dat pro rozsáhlé cloudové aplikace se očekává, že bude obsahovat velký objem dat, který se může postupně významně zvýšit. Server obvykle poskytuje jenom omezenou velikost místa na disku, ale stávající disky můžete nahradit většími. Můžete také s tím, jak se budou zvyšovat objemy dat, přidat do počítače další disky. Může ale dojít k tomu, že v systému bude dosaženo limitu, za hranicí kterého už není možné kapacitu úložiště na daném serveru jednoduše zvýšit.
Výpočetní prostředky: Pro podporu velkého počtu souběžných uživatelů, z nichž každý spouští dotazy, které načítají informace z úložiště dat, je nutná cloudová aplikace. Jeden server, který je hostitelem úložiště dat, nemusí být schopen poskytnout potřebný výpočetní výkon pro podporu tohoto zatížení, což vede k prodloužení doby odezvy pro uživatele a časté selhání při pokusu o uložení a načtení časového limitu dat. Může být možné přidat paměť nebo upgradovat procesory, ale systém dosáhne limitu, pokud už není možné výpočetní prostředky ještě zvýšit.
Šířka pásma sítě: Výkon úložiště dat, které běží na jediném serveru, se nakonec řídí rychlostí, jakou může server přijímat žádosti a posílat odpovědi. Je možné, že objem síťového provozu může překročit kapacitu sítě, která slouží pro připojení k serveru, což má za následek neúspěšné žádosti.
Geografie: Z hlediska práva, dodržování předpisů nebo kvůli výkonu či snižování latence u přístupu k datům může být nutné ukládat data generovaná konkrétními uživateli ve stejné oblasti, jako je oblast, ve které se nachází tito uživatelé. Pokud se uživatelé nacházejí v různých zemích nebo oblastech, nemusí být možné uložit veškerá data aplikace v jednom úložišti dat.
Vertikální škálování na základě zvýšení diskové kapacity, výkonu zpracování, paměti a síťového připojení může účinky některých těchto omezení odložit, ale toto řešení bude pravděpodobně jenom dočasné. Komerční cloudové aplikace, které dokážou zajistit podporu velkého počtu uživatelů a velkých objemů dat, musí být možné škálovat téměř bez omezení. Vertikální škálování tedy nemusí být nutně nejlepší řešení.
Řešení
Rozdělte úložiště dat do horizontálních oddílů. Každý horizontální oddíl má stejné schéma, ale obsahuje vlastní jedinečnou podmnožinu dat. Horizontální oddíl představuje ve své podstatě úložiště (může obsahovat data pro mnoho entit různých typů) spuštěné na serveru fungujícím jako uzel úložišť.
Tento model má tyto výhody:
Systém je možné škálovat tak, že přidáte další horizontální oddíly, které běží na dalších uzlech úložišť.
Systém může používat pro jednotlivé uzly úložišť namísto specializovaných a drahých počítačů standardní hardware.
Vyrovnávání zátěže napříč horizontálními oddíly může redukovat kolize a zdokonalit výkon.
V cloudu můžou být horizontální oddíly umístěné fyzicky v blízkosti uživatelů, kteří budou data zobrazovat.
Při dělení úložiště dat do horizontálních oddílů rozhodněte, která data se mají do jednotlivých oddílů umístit. Horizontální oddíl obvykle obsahuje položky, které spadají do zadaného rozsahu na základě jednoho nebo více atributů dat. Tyto atributy tvoří klíč horizontálního oddílu. Klíč horizontálního dělení by měl být statický. Neměl by být založený na datech, která se můžou změnit.
Při horizontálním dělení se data fyzicky uspořádají. Když aplikace ukládá a načítá data, přesměruje logika horizontálního dělení aplikaci do příslušného horizontálního oddílu. Tuto logiku horizontálního dělení je možné implementovat jako součást kódu pro přístup k datům v aplikaci nebo ji může implementovat systém úložiště dat, pokud transparentně podporuje horizontální dělení.
Abstrakce fyzického umístění dat v logice horizontálního dělení poskytuje vysokou úroveň kontroly nad tím, které horizontální oddíly obsahují která data. Umožňuje to také migraci dat mezi horizontálními umístěními bez nutnosti přepracovat podnikovou logiku aplikace v případě, že bude nutné později data v horizontálních umístěních znovu distribuovat (například, když dojde k tomu, že nebudou horizontální umístění vyrovnaná). Výměnou za to je nutný další přístup k datům při určování umístění jednotlivých datových položek při jejich načítání.
Pro zajištění optimálního výkonu a škálovatelnosti je důležité data rozdělit tak, aby to vyhovovalo typům dotazů, které provádí aplikace. V mnoha případech není pravděpodobné, že bude schéma horizontálního dělení přesně odpovídat požadavkům každého dotazu. Například v systému s více tenanty může aplikace potřebovat načíst data tenanta pomocí ID tenanta, ale může také potřebovat vyhledat tato data na základě některého jiného atributu, jako je název nebo umístění tenanta. Aby bylo možné tyto situace vyřešit, implementujte strategii horizontálního dělení, která podporuje nejběžněji prováděné dotazy.
Pokud dotazy pravidelně načítají data pomocí kombinace hodnot atributu, budete moci pravděpodobně definovat složený klíč horizontálního dělení na základě propojení atributů. Další možností je použít model, jako je například tabulka indexu, a získat možnost rychlého vyhledávání dat na základě atributů, které nepokrývá klíč horizontálního oddílu.
Strategie horizontálního dělení
Při výběru klíče horizontálního oddílu a rozhodování, jak distribuovat data v horizontálních oddílech, se používají tři strategie. Všimněte si, že mezi horizontálními oddíly a servery, které je hostují, nemusí existovat 1:1 – jeden server může hostovat více horizontálních oddílů. Strategie:
Strategie vyhledávání: V této strategii implementuje logika horizontálního dělení mapu, která směruje žádost o data do horizontálního oddílu, který obsahuje daná data, pomocí klíče horizontálního oddílu. Ve víceklientské aplikaci můžou být všechna data tenanta uložená společně v horizontálním oddílu pomocí ID tenanta jako klíče horizontálního oddílu. Několik tenantů může sdílet stejné ID horizontálního oddílu, ale data pro jednoho tenanta nebude možné rozdělit do několika těchto oddílů. Na obrázku vidíte horizontální dělení dat tenanta na základě ID tenantů.
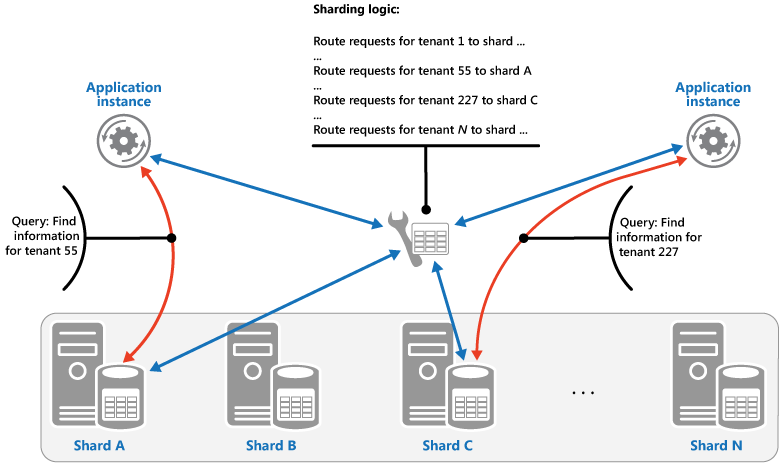
Mapování mezi hodnotou klíče horizontálního oddílu a fyzickým úložištěm, na kterém data existují, může být založeno na fyzických horizontálních oddílech, kde se každá hodnota klíče horizontálního oddílu mapuje na fyzický oddíl. Případně flexibilnější technika pro vyrovnávání horizontálních oddílů je virtuální dělení, kde se hodnoty klíčů horizontálních oddílů mapují na stejný počet virtuálních horizontálních oddílů, které se zase mapují na méně fyzických oddílů. V tomto přístupu aplikace vyhledá data pomocí hodnoty klíče horizontálního oddílu, která odkazuje na virtuální horizontální oddíl, a systém transparentně mapuje virtuální horizontální oddíly na fyzické oddíly. Mapování mezi virtuálním horizontálním oddílem a fyzickým oddílem se může změnit, aniž by bylo nutné upravit kód aplikace tak, aby používal jinou sadu hodnot klíče horizontálního oddílu.
Strategie rozsahu: Tato strategie seskupuje související položky ve stejném horizontálním oddílu a objednává je podle klíče horizontálního dělení – klíče horizontálních oddílů jsou sekvenční. Je to užitečné pro aplikace, které často načítají sady položek pomocí dotazů na rozsah (dotazy, které vracejí sadu datových položek pro klíč horizontálního oddílu, který spadá do daného rozsahu). Pokud například potřebuje aplikace pravidelně hledat všechny objednávky zadané v daném měsíci, můžou se tato data načíst rychleji, pokud jsou všechny objednávky za daný měsíc ve stejném horizontálním oddílu uložené v pořadí datum a čas. Kdyby byly jednotlivé objednávky uložené v rozdílných horizontálních oddílech, bylo by nutné je získat jednotlivě na základě provedení velkého počtu bodových dotazů (dotazů, které vrací jednotlivé datové položky). Na dalším obrázku vidíte ukládání postupných sad (rozsahů) dat v horizontálním oddílu.
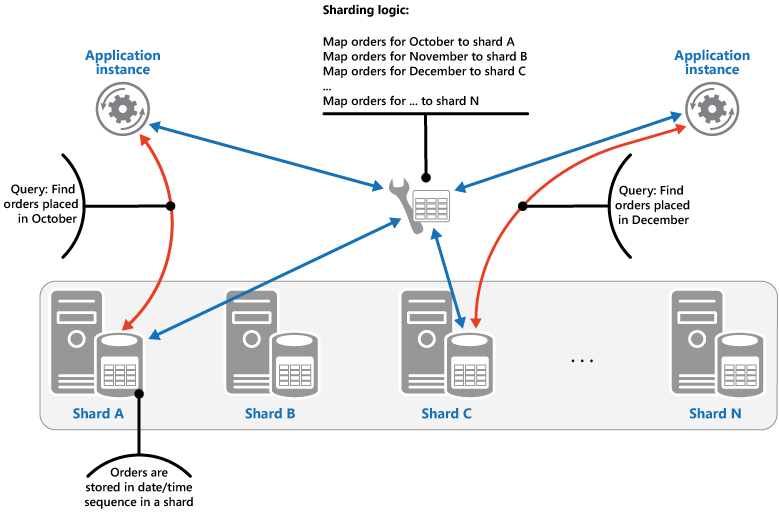
V tomto příkladu představuje klíč horizontálních dat složený klíč obsahující měsíc objednávky jako nejdůležitější element. Za ním následuje den a čas objednávky. Data objednávek se po přidání nových objednávek do horizontálního oddílu řadí přirozeným způsobem. Některá úložiště dat podporují klíče horizontálních oddílu, které se skládají ze dvou částí a obsahují element klíče oddílu, který identifikuje horizontální oddíl, a klíč řádku, který jednoznačně identifikuje položku v horizontálním oddílu. Data se obvykle uchovávají v pořadí podle klíče řádků v horizontálním oddílu. Položky, na které se dotazují dotazy na rozsah a které musí být seskupené pohromadě, můžou používat klíč horizontálního oddílu, který má stejnou hodnotu pro klíč oddílu, ale jedinečnou hodnotu pro klíč řádku.
Strategie Hash: Účelem této strategie je snížit pravděpodobnost vzniku hotspotů (horizontálních oddílů, které přijímají nevyrovnaný objem zátěže). Rozděluje data mezi horizontální oddíly takovým způsobem, aby bylo možné dosáhnout rovnováhy mezi velikostmi jednotlivých horizontálních oddílů a jejich průměrnou zátěží. Logika horizontálního dělení, která počítá horizontální oddíl pro uložení položky, je založená na hodnotě hash jednoho nebo více atributů dat. Zvolená funkce algoritmu hash by měla distribuovat data rovnoměrně mezi horizontální oddíly, eventuálně na základě zavedení nějakého náhodného elementu do výpočtu. Následující obrázek znázorňuje horizontální dělení dat tenanta podle hodnoty hash ID tenantů.
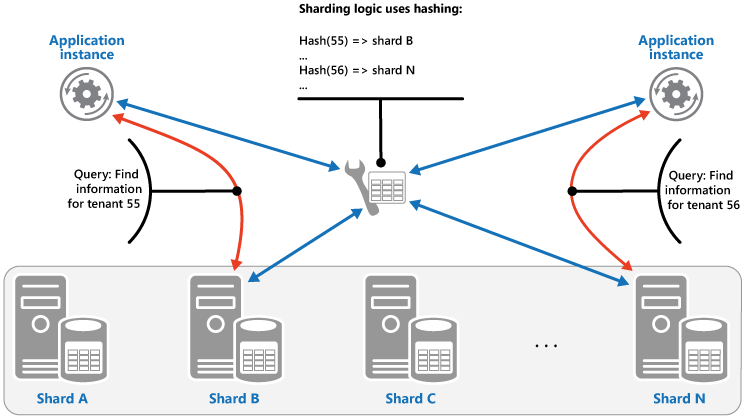
Abyste pochopili výhodu strategie hash oproti jiným strategiím horizontálního dělení, zvažte, jak může víceklientská aplikace, která registruje nové tenanty postupně, přiřazovat tenanty k horizontálním oddílům v úložišti dat. Při použití strategie Rozsah se všechna data pro tenanty 1 až n uloží v horizontálním oddílu A, všechna data pro tenanty n+1 až m se uloží do oddílu B a tak dále. Pokud jsou poslední registrované tenanty také nejaktivnější, bude většina aktivit souvisejících s daty probíhat na malém počtu horizontálních oddílů, což může vést ke vzniku hotspotů. Naproti tomu se při strategii Hash tenanty přidělují k horizontálním oddílům podle hodnoty hash ID tenantů. Znamená to, že tenanty s postupným řazením se budou s největší pravděpodobností přidělovat k různým horizontálním oddílům a zátěž se takto bude mezi ně distribuovat. Předchozí obrázek znázorňuje tento postup u tenantů 55 a 56.
U těchto tří strategií horizontálního dělení existují následující výhody a je potřeba zvážit následující skutečnosti:
Vyhledávání: Nabízí lepší kontrolu nad způsobem, jakým se konfigurují a používají horizontální oddíly. Použití virtuálních horizontálních oddílů snižuje dopad na vyrovnávání dat, protože je možné přidávat nové fyzické oddíly, které umožní vyrovnat zátěž. Mapování mezi virtuálním horizontálním oddílem a fyzickými oddíly, které implementují horizontální oddíly, je možné změnit, aniž by došlo k ovlivnění aplikačního kódu, který používá k ukládání a načítání dat klíč horizontálního oddílu. Vyhledávání umístění horizontálních oddílů může představovat režii navíc.
Rozsah: Toto řešení se snadno implementuje a dobře funguje s dotazy na rozsah, protože ty můžou často načíst z jediného horizontálního oddílu v rámci jedné operace více položek dat. Tato strategie nabízí jednodušší správu dat. Pokud jsou například uživatelé ve stejné oblasti ve stejném horizontálním oddílu, je možné naplánovat aktualizace v jednotlivých časových pásmech na základě modelu místní zátěže a poptávky. Tato strategie ale neumožňuje optimální vyrovnávání mezi horizontálními oddíly. Vyrovnávání v horizontálních oddílech je složité a nemusí vyřešit problém nerovnoměrné zátěže, pokud se většina aktivit vztahuje na klíče přilehlých horizontálních oddílů.
Hash: Tato strategie nabízí větší šance, že se podaří data a zátěž rovnoměrněji rozdělit. Směrování žádostí je možné provádět přímo pomocí funkce hash. Není nutné udržovat mapování. Chtěli bychom vás upozornit, že počítání hodnoty hash může představovat režii navíc. Složité je také opětovné vyrovnávání horizontálních oddílů.
Nejběžnější systémy horizontálního dělení implementují jeden z přístupů popsaných výše, ale měli byste zvážit také to, jaké máte ve firmě požadavky na aplikace a jaké se používají modely využití dat. Například ve víceklientských aplikacích:
Můžete horizontálně dělit data na základě zátěže. Data vysoce nestálých tenantů byste mohli izolovat v samostatných horizontálních oddílech. Výsledkem toho by mohlo být zlepšení rychlosti při přístupu k datům pro jiné tenanty.
Data můžete horizontálně dělit podle umístění tenantů. Data pro tenanty v určité geografické oblasti můžete v době, kdy v této oblasti není špička, převést offline pro účely zálohování a údržby, zatímco data pro tenanty v jiných oblastech zůstanou během pracovní doby v dané oblasti online a přístupná.
Tenantům s vysokou hodnotou je možné přiřadit vlastní privátní, vysoce výkonné, mírně načtené horizontální oddíly, zatímco u tenantů s nižší hodnotou se může očekávat, že budou sdílet hustěji zabalené a zaneprázdněné horizontální oddíly.
Data pro tenanty, které potřebují vysokou míru izolace dat a ochrany osobních údajů, se můžou ukládat na zcela samostatném serveru.
Operace škálování a přesunu dat
Každá ze strategií horizontálního dělení má různé možnosti a předpokládá různé úrovně složitosti správy horizontálního zvyšování a snižování kapacity, přesouvání dat a udržování stavu.
Strategie vyhledávání umožňuje provádět operace škálování a přesouvání dat na úrovni uživatele, online nebo offline. Jako postup se používá pozastavení některé nebo všech aktivit uživatelů (například v obdobích mimo špičku), přesunutí dat na nový virtuální oddíl nebo fyzický horizontální oddíl, změna mapování, zrušení platnosti nebo aktualizace všech mezipamětí, ve kterých jsou tato data, a následné povolení obnovení aktivity uživatelů. Tento typ operace se dá často centrálně spravovat. Strategie vyhledávání vyžaduje stav, kdy je možné dokonalé ukládání do mezipaměti a replikování.
Strategie rozsahu představuje určitá omezení pro operace škálování a přesouvání dat, které se musí obvykle provádět, když je část nebo celé úložiště dat offline, protože je nutné data rozdělit a sloučit napříč horizontálními oddíly. Přesun dat pro účely opětovného vyrovnání horizontálních oddílů nemusí vyřešit problém, kdy dochází k nerovnoměrné zátěži, když probíhá většina aktivity u klíčů přilehlých horizontálních oddílů nebo identifikátorů dat, které jsou ve stejném rozsahu. Strategie rozsahu by mohla také vyžadovat údržbu u některých stavů, aby bylo možné mapovat rozsahy na fyzické oddíly.
U strategie hash jsou operace škálování a přesouvání dat složitější, protože klíče oddílů jsou hodnoty hash klíčů horizontálních oddílů nebo identifikátorů dat. Aby bylo možné zajistit správné mapování, musí být nové umístění jednotlivých horizontálních oddílu určené podle funkce hash nebo upravené funkce. U strategie hash ale není nutná údržba stavu.
Problémy a důležité informace
Když se budete rozhodovat, jak tento model implementovat, měli byste vzít v úvahu následující skutečnosti:
Horizontální dělení představuje doplněk k dalším formám dělení do oddílů, jako je například vertikální dělení a funkční dělení. Například jeden horizontální oddíl může obsahovat entity rozdělené do vertikálních oddílů a funkční oddíl je možné implementovat jako více horizontálních oddílů. Další informace o dělení do oddílů najdete v tématu Pokyny k dělení dat.
Udržujte vyrovnaný stav horizontálních oddílů, aby všechny zpracovávaly podobné objemy vstupních a výstupních operací. Při vkládání a odstraňování dat je potřeba pravidelně znovu vyvažovat horizontální oddíly, aby byla zaručená rovnoměrná distribuce a snížila se pravděpodobnost vzniku hotspotů. Vyrovnávání může být nákladná operace. Aby se snížila potřeba vyrovnávat zátěž, naplánujte si možnost růstu tak, aby bylo zajištěno, že každý horizontální oddíl bude obsahovat dostatek volného místa pro zpracování očekávaného objemu změn. Měli byste také vytvořit strategie a skripty, které můžete v případě potřeby použít k rychlému opětovnému vyvážení horizontálních oddílů.
Pro klíč horizontálního oddílu použijte stabilní data. Je možné, že pokud se změní klíč horizontálního oddílu, bude nutné přesunout odpovídající položku dat mezi horizontálními oddíly, což zvýší množství práce prováděné operacemi aktualizací. Vyhněte se proto tomu, aby byl klíč horizontálního oddílu založený na potenciálně nestabilních informacích. Místo toho hledejte atributy, které se nebudou měnit nebo které budou přirozeně tvořit klíč.
Klíče horizontálního oddílu musí být jedinečné. Jako klíč horizontálního oddílu například nepoužívejte pole s automatickými přírůstky. V některých systémech nelze automaticky navyšovaná pole koordinovat napříč horizontálními oddíly, což může mít za následek, že položky v různých horizontálních oddílech mají stejný klíč horizontálního oddílu.
Potíže můžou způsobit i hodnoty s automatickými přírůstky v jiných polích, která nepředstavují klíče horizontálních oddílů. Pokud například použijete pole s automatickými přírůstky ke generování jedinečných ID, pak dvě různé položky umístěné v různých horizontálních oddílech může mít přiřazené stejné ID.
Nemusí být možné navrhnout klíč horizontálního oddílu, který vyhoví požadavkům jakéhokoliv možného dotazu na data. Data rozdělte do horizontálních oddílů tak, aby podporovala nejčastěji prováděné dotazy, a v případě potřeby vytvořte tabulky sekundárních indexů pro podporu dotazů, které načítají data s použitím kritérií založených na atributech, které nejsou součástí klíče horizontálního oddílu. Další informace najdete v tématu Model tabulky indexů.
Dotazy, které získávají přístup jenom do jednoho horizontálního oddílu, jsou účinnější než ty, které načítají data z více horizontálních oddílů. Neimplementujte tedy systém horizontálního dělení, jehož výsledkem by bylo, že aplikace budou provádět velké množství dotazů, které se připojují k datům uloženým v různých horizontálních oddílech. Nezapomeňte, že jediný horizontální oddíl může obsahovat data pro různé typy entit. Zvažte možnost denormalizovat data, aby se daly zachovat související entity, na které se běžně dotazuje společně (jako jsou například podrobnosti o zákaznících a objednávky, které mohli zadat), ve stejném horizontálním oddílu a snížil se tak počet samostatných čtení, která provádí aplikace.
Pokud entita v jednom horizontálním oddílu odkazuje na entitu uloženou v jiném horizontálním oddílu, zahrňte klíč horizontálního oddílu pro druhou entitu jako součást schématu pro první entitu. Může vám to pomoct zlepšit výkon dotazů, které odkazují na související data napříč horizontálními oddíly.
Pokud musí aplikace provádět dotazy, které načítají data z více horizontálních oddílů, je možné, že se tato data budou dát načíst pomocí paralelních úloh. Jako příklad je možné uvést větvené dotazy, kde se data z více horizontálních oddílů načítají paralelně a pak agregují do jediného výsledku. Tento postup ale nevyhnutelně zvyšuje u řešení složitost logiky přístupu k datům.
Pro mnoho aplikací může být vytvoření většího počtu malých horizontálních oddílů mnohem účinnější než malý počet velkých horizontálních oddílů, protože můžou nabídnout lepší možnosti vyrovnávání zátěže. Může to být užitečné také, když očekáváte, že bude potřeba migrovat horizontální oddíly z jednoho fyzického umístění do jiného. Přesunutí malého horizontálního oddílu je rychlejší než přesouvání velkého.
Ujistěte se, že prostředky dostupné pro jednotlivé uzly horizontálního oddílu jsou dostatečné pro zpracování požadavků na škálovatelnost z hlediska velikosti a propustnosti dat. Další informace najdete v části Návrh oddílů pro zajištění škálovatelnosti v pokynech k dělení dat.
Zvažte možnost replikovat referenční data na všechny horizontální oddíly. Pokud operace, která načte data z horizontálního oddílu, odkazuje v rámci stejného dotazu také na statická data nebo data s pomalým pohybem, přidejte tato data do horizontálního oddílu. Aplikace může potom snadno načíst veškerá data pro dotaz, bez nutnosti přecházet dál do samostatného úložiště dat.
Pokud se referenční data uložená ve více horizontálních oddílech změní, musí systém tyto změny synchronizovat napříč všemi horizontálními oddíly. Během této synchronizace můžou v systému nastat jisté nekonzistence. V takovém případě byste měli navrhnout aplikace tak, aby si s takovou situací dokázaly poradit.
Může být složité udržet referenční integritu a konzistenci mezi horizontálními oddíly, měli byste tedy minimalizovat operace, které mají vliv na data ve více horizontálních oddílech. Pokud musí aplikace upravit data napříč horizontálními oddíly, vyhodnoťte, jestli je úplná konzistence dat skutečně nutná. Běžným přístupem v cloudu je místo toho implementovat konečnou konzistenci. Data v jednotlivých oddílech se aktualizují samostatně a logika aplikace musí nést odpovědnost za zajištění toho, že všechny aktualizace proběhnou úspěšně, stejně jako zpracování nekonzistencí, které můžou nastat v důsledku dotazování na data, i když poběží operace, která je nakonec konzistentní. Další informace o implementaci konzistence typu Případné najdete v úvodu ke konzistenci dat.
Konfigurace a správa velkého počtu horizontálních oddílů může být složitý úkol. Úlohy, jako je monitorování, zálohování, kontrola konzistence a protokolování nebo auditování, je nutné provádět na více horizontálních oddílech a serverech, které se můžou nacházet ve více umístěních. Tyto úkoly se budou pravděpodobně implementovat pomocí skriptů nebo jiných automatických řešení, ale ani tak se nemusí úplně eliminovat další požadavky na správu.
Horizontální oddíly je možné geograficky umístit tak, aby data, která obsahují, byla v blízkosti instancí aplikace, které je používají. Tento přístup může výrazně zlepšit výkon, ale je nutné ho pečlivě zvážit u úloh, které potřebují přístup k více horizontálním oddílům v různých umístěních.
Kdy se má tento model použít
Tento model použijte v případě, že bude úložiště dat pravděpodobně nutné škálovat nad rámec prostředků, které jsou dostupné v jediném uzlu úložiště, nebo když bude potřeba zvýšit výkon redukcí počtu kolizí v úložišti dat.
Poznámka:
Horizontální dělení se primárně zaměřuje na zlepšení výkonu a škálovatelnost systému, ale vedlejším produktem může být také zlepšení dostupnosti díky rozdělení dat do samostatných oddílů. Pokud dojde k selhání v jednom oddílu, neznamená to nutně, že aplikace nebude mít přístup k datům v jiných oddílech, a operátor může provádět údržbu nebo obnovení jednoho nebo více oddílů, aniž by zakázal přístup ke všem datům aplikace. Další informace najdete v tématu Pokyny k dělení dat.
Návrh úloh
Architekt by měl vyhodnotit způsob použití modelu horizontálního dělení v návrhu úloh k řešení cílů a principů popsaných v pilířích architektury Azure Well-Architected Framework. Příklad:
| Pilíř | Jak tento model podporuje cíle pilíře |
|---|---|
| Rozhodnutí o návrhu spolehlivosti pomáhají vaší úloze stát se odolnou proti selhání a zajistit, aby se po selhání obnovila do plně funkčního stavu. | Vzhledem k tomu, že data nebo zpracování jsou izolovaná s horizontálním oddílem, zůstává v jednom horizontálním oddílu chyba izolovaná. - RE:06 Dělení dat - RE:07 Sebezáchování |
| Optimalizace nákladů se zaměřuje na udržení a zlepšení návratnosti vašich úloh. | Systém, který implementuje horizontální oddíly, často přináší výhody použití několika instancí levnějších výpočetních prostředků nebo prostředků úložiště místo jednoho nákladnějšího prostředku. V mnoha případech vám tato konfigurace může ušetřit peníze. - CO:07 Náklady na komponenty |
| Efektivita výkonu pomáhá vaší úloze efektivně splňovat požadavky prostřednictvím optimalizací škálování, dat a kódu. | Při použití horizontálního dělení ve vaší strategii škálování se data nebo zpracování izolují s horizontálním oddílem, takže soupeří o prostředky pouze s jinými požadavky směrovanými na tento horizontální oddíl. Horizontální dělení můžete použít také k optimalizaci na základě zeměpisné polohy. - PE:05 Škálování a dělení - Výkon dat PE:08 |
Stejně jako u jakéhokoli rozhodnutí o návrhu zvažte jakékoli kompromisy proti cílům ostatních pilířů, které by mohly být s tímto vzorem zavedeny.
Příklad
Představte si web, který poskytuje rozsáhlé kolekce informací o publikovaných knihách po celém světě. Počet možných knih katalogovaných v této úloze a typické vzory dotazování/použití kontraa-indikují použití jedné relační databáze k uložení informací o knize. Architekt úloh se rozhodne horizontálně dělit data napříč několika instancemi databáze pomocí statického standardního čísla knihy (ISBN) pro klíč horizontálního dělení. Konkrétně používají kontrolní číslici (0 –10) ISBN, protože poskytuje 11 možných logických horizontálních oddílů a data budou v každém horizontálním oddílu poměrně vyvážená. Začněme tím, že se rozhodnou umístit 11 logických horizontálních oddílů do tří fyzických databází horizontálních oddílů. Používají přístup k horizontálnímu dělení vyhledávání a ukládají informace o mapování klíčů na server do databáze mapování horizontálních oddílů.
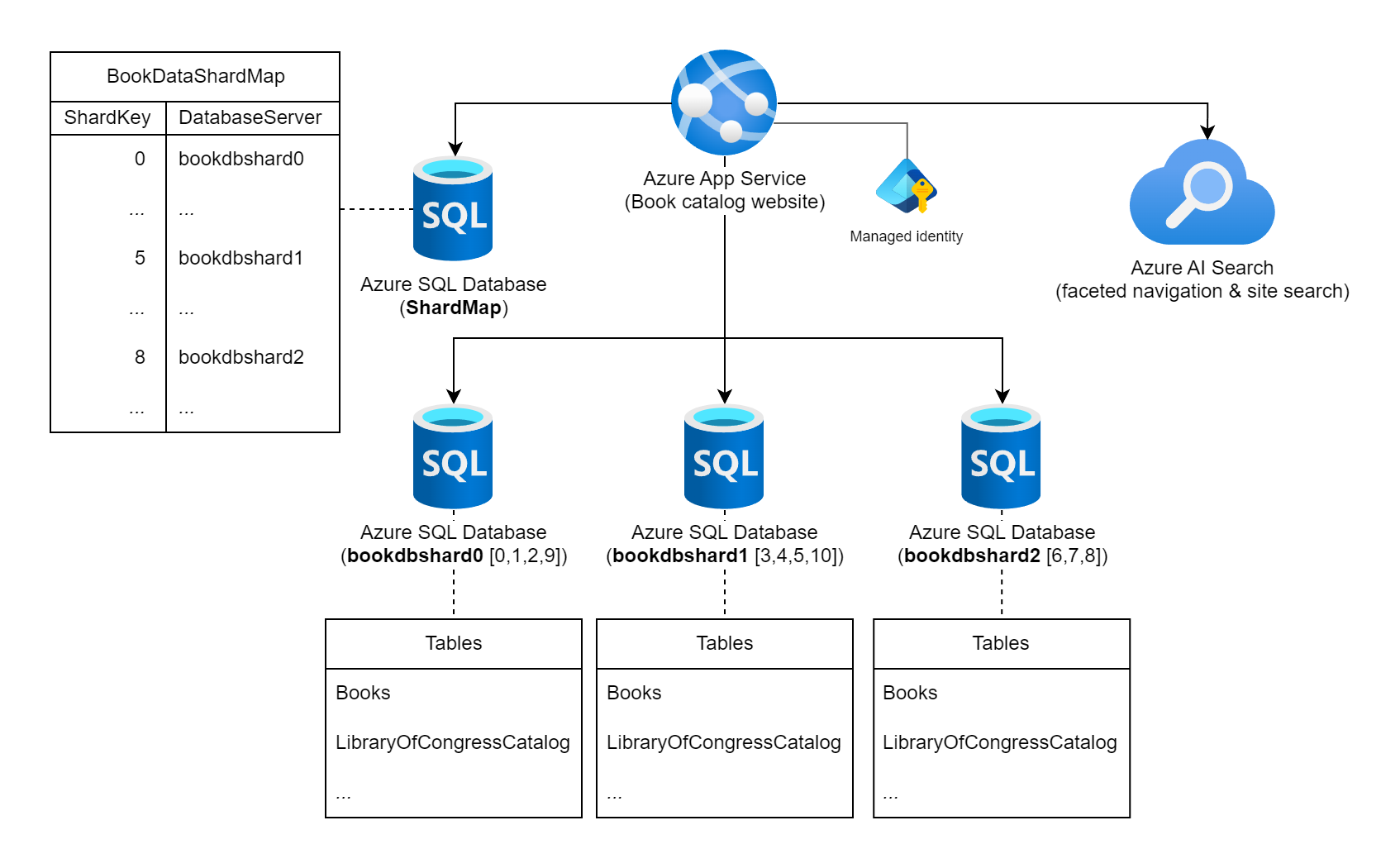
Diagram znázorňující službu Aplikace Azure označenou jako "Web katalogu knih", který je připojený k několika instancím služby Azure SQL Database a instanci služby Azure AI Search Jedna z databází je označená jako databáze ShardMap a má ukázkovou tabulku, která zrcadlí část mapovací tabulky, která je dále uvedena v tomto dokumentu. Existují také tři instance databází horizontálních oddílů: bookdbshard0, bookdbshard1 a bookdbshard2. Každá databáze obsahuje příklad výpisu tabulek. Všechny tři příklady jsou identické, uvádějící tabulky "Books" a "LibraryOfCongressCatalog" a indikátor dalších tabulek. Ikona Azure AI Search označuje, že se používá pro fasetovou navigaci a vyhledávání na webu. Spravovaná identita se zobrazuje přidružená ke službě Aplikace Azure Service.
Mapa horizontálních oddílů vyhledávání
Databáze mapování horizontálních oddílů obsahuje následující tabulku a data mapování horizontálních oddílů.
SELECT ShardKey, DatabaseServer
FROM BookDataShardMap
| ShardKey | DatabaseServer |
|----------|----------------|
| 0 | bookdbshard0 |
| 1 | bookdbshard0 |
| 2 | bookdbshard0 |
| 3 | bookdbshard1 |
| 4 | bookdbshard1 |
| 5 | bookdbshard1 |
| 6 | bookdbshard2 |
| 7 | bookdbshard2 |
| 8 | bookdbshard2 |
| 9 | bookdbshard0 |
| 10 | bookdbshard1 |
Ukázkový kód webu – přístup k jednomu horizontálnímu oddílu
Web nezná počet fyzických databází horizontálních oddílů (v tomto případě tři) ani logiku, která mapuje klíč horizontálního oddílu na instanci databáze, ale web ví, že kontrolní číslice isBN knihy by se měla považovat za klíč horizontálního dělení. Web má přístup jen pro čtení k databázi mapování horizontálních oddílů a přístup pro čtení i zápis ke všem databázím horizontálních oddílů. V tomto příkladu web používá systémovou spravovanou identitu služby Aplikace Azure, která je hostitelem webu pro autorizaci, aby se tajné kódy uchovály mimo připojovací řetězec.
Web se konfiguruje s následujícími připojovací řetězec buď v appsettings.json souboru, například v tomto příkladu, nebo prostřednictvím nastavení aplikace služby App Service.
{
...
"ConnectionStrings": {
"ShardMapDb": "Data Source=tcp:<database-server-name>.database.windows.net,1433;Initial Catalog=ShardMap;Authentication=Active Directory Default;App=Book Site v1.5a",
"BookDbFragment": "Data Source=tcp:SHARD.database.windows.net,1433;Initial Catalog=Books;Authentication=Active Directory Default;App=Book Site v1.5a"
},
...
}
Při dostupných informacích o připojení k mapové databázi horizontálních oddílů by příklad aktualizačního dotazu spouštěného webem do fondu horizontálních oddílů úlohy vypadal podobně jako následující kód.
...
// All data for this book is stored in a shard based on the book's ISBN check digit,
// which is converted to an integer 0 - 10 (special value 'X' becomes 10).
int isbnCheckDigit = book.Isbn.CheckDigitAsInt;
// Establish a pooled connection to the database shard for this specific book.
using (SqlConnection sqlConn = await shardedDatabaseConnections.OpenShardConnectionForKeyAsync(key: isbnCheckDigit, cancellationToken))
{
// Update the book's Library of Congress catalog information
SqlCommand cmd = sqlConn.CreateCommand();
cmd.CommandText = @"UPDATE LibraryOfCongressCatalog
SET ControlNumber = @lccn,
...
Classification = @lcc
WHERE BookID = @bookId";
cmd.Parameters.AddWithValue("@lccn", book.LibraryOfCongress.Lccn);
...
cmd.Parameters.AddWithValue("@lcc", book.LibraryOfCongress.Lcc);
cmd.Parameters.AddWithValue("@bookId", book.Id);
await cmd.ExecuteNonQueryAsync(cancellationToken);
}
...
V předchozím příkladu kódu, pokud book.Isbn byl 978-8-1130-1024-6, pak isbnCheckDigit by měl být 6. Volání OpenShardConnectionForKeyAsync(6) by se obvykle implementovalo s přístupem doplňování do mezipaměti. Dotazuje se na databázi mapování horizontálních oddílů identifikovanou s připojovací řetězecShardMapDb, pokud nemá informace o horizontálním oddílu uložené v mezipaměti pro klíč horizontálního oddílu 6. Z mezipaměti aplikace nebo z databáze horizontálních oddílů se hodnota bookdbshard2 umístí SHARD do BookDbFragment připojovací řetězec. Připojení ve fondu je (znovu) navázané na bookdbshard2.database.windows.net, otevřené a vrácené do volajícího kódu. Kód pak aktualizuje existující záznam pro danou instanci databáze.
Ukázkový kód webu – přístup k více horizontálním oddílům
Ve výjimečných případech vyžaduje web přímý dotaz napříč horizontálními oddíly, aplikace provede paralelní dotaz ventilátoru napříč všemi horizontálními oddíly.
...
// Retrieve all shard keys
var shardKeys = shardedDatabaseConnections.GetAllShardKeys();
// Execute the query, in a fan-out style, against each shard in the shard list.
Parallel.ForEachAsync(shardKeys, async (shardKey, cancellationToken) =>
{
using (SqlConnection sqlConn = await shardedDatabaseConnections.OpenShardConnectionForKeyAsync(key: shardKey, cancellationToken))
{
SqlCommand cmd = sqlConn.CreateCommand();
cmd.CommandText = @"SELECT ...
FROM ...
WHERE ...";
SqlDataReader reader = await cmd.ExecuteReaderAsync(cancellationToken);
while (await reader.ReadAsync(cancellationToken))
{
// Read the results in to a thread-safe data structure.
}
reader.Close();
}
});
...
Alternativou k dotazům napříč horizontálními oddíly v této úloze může být použití externě udržovaného indexu ve službě Azure AI Search, jako je vyhledávání na webu nebo fasetová navigace.
Přidání instancí horizontálních oddílů
Tým úloh si je vědom toho, že pokud se katalog dat nebo jeho souběžné využití výrazně zvyšuje, může být vyžadováno více než tři databázové instance. Tým úloh neočekává, že dynamicky přidá databázové servery a v případě, že se nový horizontální oddíl musí připojit do online režimu, vydrží výpadky úloh. Online přenesení nové instance horizontálních oddílů vyžaduje přesun dat z existujících horizontálních oddílů do nového horizontálního oddílu spolu s aktualizací tabulky mapování horizontálních oddílů. Tento poměrně statický přístup umožňuje úloze bezpečně ukládat do mezipaměti mapování databáze klíčů horizontálních oddílů v kódu webu.
Logika klíče horizontálního dělení v tomto příkladu má pevný horní limit 11 maximálních fyzických horizontálních oddílů. Pokud tým úloh provede testy odhadu zatížení a vyhodnotí, že se nakonec vyžaduje více než 11 instancí databází, bude potřeba provést invazní změnu logiky klíče horizontálního dělení. Tato změna zahrnuje pečlivé plánování úprav kódu a migrace dat do nové klíčové logiky.
Funkce sady SDK
Místo psaní vlastního kódu pro správu horizontálních oddílů a směrování dotazů do instancí služby Azure SQL Database vyhodnoťte klientskou knihovnu elastické databáze. Tato knihovna podporuje správu mapování horizontálních oddílů, směrování dotazů závislých na datech a dotazy napříč horizontálními oddíly v C# i Javě.
Další kroky
Při implementaci tohoto modelu můžou být relevantní také následující pokyny:
- Úvod do konzistence dat. U dat distribuovaných napříč různými horizontálními oddíly může být nutné udržovat konzistenci. Shrnuje problémy kolem udržování konzistentnosti distribuovaných dat a popisuje výhody a nevýhody různých modelů konzistence.
- Pokyny k dělení dat: Při horizontálním dělení úložiště dat může nastat řada dalších problémů. Popisuje tyto problémy ve vztahu k vytváření oddílů datových úložišť v cloudu, aby se zlepšila škálovatelnost, snížil počet kolizí a optimalizoval výkon.
Související prostředky
Při implementaci tohoto modelu můžou být relevantní také následující vzory:
- Model tabulky indexů: Někdy není možná úplná podpora dotazů jenom na základě návrhu klíče horizontálního dělení. Umožňuje aplikaci rychle načíst data z rozsáhlého úložiště dat po zadání klíče jiného, než je klíč horizontálního oddílu.
- Model Materializované zobrazení. Pokud chcete zachovat výkon nějakých operací dotazů, je užitečné vytvořit materializovaná zobrazení, která agregují a shrnují data, zejména pokud jsou tato souhrnná data založená na informacích distribuovaných napříč horizontálními oddíly. Popisuje, jak tato zobrazení generovat a naplnit.