Důležité informace o aplikační platformě pro klíčové úlohy
Klíčovou oblastí návrhu každé klíčové architektury je aplikační platforma. Platforma odkazuje na komponenty infrastruktury a služby Azure, které musí být zřízeny pro podporu aplikace. Tady je několik nadstřešujících doporučení.
Návrh ve vrstvách Zvolte správnou sadu služeb, jejich konfiguraci a závislosti specifické pro aplikaci. Tento vícevrstvý přístup pomáhá při vytváření logických a fyzických segmentací. Je užitečné definovat role a funkce a přiřazovat příslušná oprávnění a strategie nasazení. Tento přístup nakonec zvyšuje spolehlivost systému.
Nepostradatelná aplikace musí být vysoce spolehlivá a odolná vůči selhání datacentra a oblastem. Hlavní strategií je vytváření zónové a regionální redundance v konfiguraci aktivní-aktivní. Při výběru služeb Azure pro platformu vaší aplikace zvažte jejich Zóny dostupnosti podporu a nasazení a provozní vzory pro použití více oblastí Azure.
Ke zvládnutí zvýšeného zatížení použijte architekturu založenou na jednotkách škálování. Jednotky škálování umožňují logicky seskupit prostředky a jednotku je možné škálovat nezávisle na jiných jednotkách nebo službách v architektuře. Pomocí modelu kapacity a očekávaného výkonu můžete definovat hranice, počet a základní měřítko jednotlivých jednotek.
V této architektuře se aplikační platforma skládá z globálního razítka, razítka nasazení a regionálních prostředků. Místní prostředky se zřizují jako součást razítka nasazení. Každé razítko odpovídá jednotce škálování a v případě, že není v pořádku, může být zcela nahrazeno.
Prostředky v každé vrstvě mají odlišné charakteristiky. Další informace najdete v tématu Model architektury typické klíčové úlohy.
| Charakteristiky | Požadavky |
|---|---|
| Životnost | Jaká je očekávaná životnost prostředku vzhledem k jiným prostředkům v řešení? Měl by prostředek přežívat nebo sdílet životnost s celým systémem nebo oblastí, nebo by měl být dočasný? |
| State | Jaký dopad bude mít trvalý stav v této vrstvě na spolehlivost nebo možnosti správy? |
| Reach | Vyžaduje se globálně distribuovaný prostředek? Může prostředek komunikovat s jinými prostředky, globálně nebo v oblastech? |
| Závislosti | Jaká je závislost na jiných prostředcích, globálně nebo v jiných oblastech? |
| Omezení škálování | Jaká je očekávaná propustnost pro tento prostředek v této vrstvě? Kolik škálování poskytuje prostředek tak, aby odpovídal této poptávce? |
| Dostupnost / zotavení po havárii | Jaký je dopad na dostupnost nebo havárii v této vrstvě? Způsobila by systémový výpadek nebo pouze problém s lokalizovanou kapacitou nebo dostupností? |
Globální prostředky
Některé prostředky v této architektuře sdílí prostředky nasazené v oblastech. V této architektuře se používají k distribuci provozu napříč několika oblastmi, k uložení trvalého stavu pro celou aplikaci a k ukládání globálních statických dat do mezipaměti.
| Charakteristiky | Důležité informace o vrstvách |
|---|---|
| Životnost | U těchto prostředků se očekává, že budou dlouho žijící. Jejich životnost pokrývá životnost systému nebo déle. Prostředky se často spravují pomocí místních aktualizací dat a řídicí roviny za předpokladu, že podporují operace aktualizace nulového výpadku. |
| State | Vzhledem k tomu, že tyto prostředky existují alespoň po celou dobu životnosti systému, je tato vrstva často zodpovědná za ukládání globálního geograficky replikovaného stavu. |
| Reach | Prostředky by se měly distribuovat globálně. Doporučuje se, aby tyto prostředky komunikují s oblastmi nebo jinými prostředky s nízkou latencí a požadovanou konzistencí. |
| Závislosti | Prostředky by se měly vyhnout závislostem na regionálních prostředcích, protože jejich nedostupnost může být příčinou globálního selhání. Certifikáty nebo tajné kódy uložené v jednom trezoru můžou mít například globální dopad, pokud dojde k selhání oblasti, ve které se trezor nachází. |
| Omezení škálování | Tyto prostředky jsou často jediné instance v systému a jako takové by měly být schopny škálovat tak, aby mohly zpracovávat propustnost systému jako celek. |
| Dostupnost / zotavení po havárii | Vzhledem k tomu, že místní a kolkové prostředky můžou využívat globální prostředky nebo jsou před nimi, je důležité, aby globální prostředky byly nakonfigurovány s vysokou dostupností a zotavením po havárii pro stav celého systému. |
V této architektuře jsou prostředky globální vrstvy Azure Front Door, Azure Cosmos DB, Azure Container Registry a Azure Log Analytics pro ukládání protokolů a metrik z jiných prostředků globální vrstvy.
V tomto návrhu existují další základní prostředky, jako je ID Microsoft Entra a Azure DNS. V tomto obrázku byly vynechány kvůli stručnosti.

Globální nástroj pro vyrovnávání zatížení
Azure Front Door se používá jako jediný vstupní bod pro uživatelský provoz. Azure zaručuje, že Služba Azure Front Door doručí požadovaný obsah bez chyby 99,99 % času. Další podrobnosti najdete v tématu Omezení služby Front Door. Pokud služba Front Door přestane být dostupná, koncový uživatel uvidí, že je systém mimo provoz.
Instance služby Front Door odesílá provoz do nakonfigurovaných back-endových služeb, jako je výpočetní cluster, který je hostitelem rozhraní API a front-endové spa. Chybné konfigurace back-endu ve službě Front Door můžou vést k výpadkům. Abyste se vyhnuli výpadkům způsobeným chybnou konfigurací, měli byste nastavení služby Front Door důkladně otestovat.
Další běžnou chybou může být chybná konfigurace nebo chybějící certifikáty TLS, což může uživatelům zabránit v používání front-endu nebo komunikace služby Front Door s back-endem. Zmírnění může vyžadovat ruční zásah. Pokud je to možné, můžete se například rozhodnout vrátit zpět k předchozí konfiguraci a certifikát znovu vydat. Bez ohledu na to, že se projeví změny, neočekávejte nedostupnost. Použití spravovaných certifikátů nabízených službou Front Door se doporučuje snížit provozní režii, jako je zpracování vypršení platnosti.
Služba Front Door nabízí mnoho dalších funkcí kromě globálního směrování provozu. Důležitou funkcí je firewall webových aplikací (WAF), protože Front Door dokáže kontrolovat provoz, který prochází. Když je nakonfigurovaný v režimu prevence , zablokuje podezřelý provoz ještě před tím, než se dostane do některého z back-endů.
Informace o možnostech služby Front Door najdete v tématu Nejčastější dotazy ke službě Azure Front Door.
Další důležité informace o globální distribuci provozu najdete v pokynech pro misson-critical v dobře architektuře architektury: globální směrování.
Container Registry
Azure Container Registry slouží k ukládání artefaktů Open Container Initiative (OCI), konkrétně chartů helmu a imagí kontejnerů. Neúčastní se toku žádosti a přistupuje se k němu jen pravidelně. Před nasazením prostředků razítka se vyžaduje registr kontejneru a neměl by mít závislost na prostředcích regionální vrstvy.
Povolte zónovou redundanci a geografickou replikaci registrů, aby byl přístup k imagím rychlý a odolný vůči selháním. V případě nedostupnosti může instance převzít služby při selhání do oblastí repliky a požadavky se automaticky znovu směrují do jiné oblasti. Počítejte s přechodnými chybami při načítání imagí, dokud nebude převzetí služeb při selhání dokončeno.
K selháním může dojít také v případě, že se image odstraní neúmyslně, nové výpočetní uzly nebudou moct vyžádat image, ale stávající uzly můžou i nadále používat image uložené v mezipaměti. Primární strategií zotavení po havárii je opětovné nasazení. Artefakty v registru kontejneru je možné vygenerovat z kanálů. Registr kontejneru musí být schopný odolat mnoha souběžnému připojení, aby podporoval všechna vaše nasazení.
K povolení geografické replikace se doporučuje použít skladovou položku Premium. Funkce redundance zón zajišťuje odolnost a vysokou dostupnost v rámci konkrétní oblasti. V případě regionálního výpadku jsou repliky v jiných oblastech stále dostupné pro operace roviny dat. Pomocí této skladové položky můžete omezit přístup k imagím prostřednictvím privátních koncových bodů.
Další podrobnosti najdete v tématu Osvědčené postupy pro Azure Container Registry.
Databáze
Doporučuje se, aby se všechny stavy ukládaly globálně do databáze oddělené od regionálních razítek. Sestavte redundanci nasazením databáze napříč oblastmi. V případě důležitých úloh by synchronizace dat napříč oblastmi měla být primárním zájmem. V případě selhání by také měly být požadavky na zápis do databáze funkční.
Replikace dat v konfiguraci aktivní-aktivní se důrazně doporučuje. Aplikace by se měla okamžitě připojit k jiné oblasti. Všechny instance by měly být schopné zpracovávat požadavky na čtení a zápis.
Další informace najdete v tématu Datová platforma pro klíčové úlohy.
Globální monitorování
Azure Log Analytics slouží k ukládání diagnostických protokolů ze všech globálních prostředků. Doporučuje se omezit denní kvótu úložiště, zejména v prostředích, která se používají pro zátěžové testování. Nastavte také zásady uchovávání informací. Tato omezení zabrání jakémukoli nadměrnému překročení, které vzniknou uložením dat, která nejsou potřebná nad rámec limitu.
Důležité informace o základních službách
Systém bude pravděpodobně používat další důležité služby platformy, které můžou způsobit riziko celého systému, jako je Azure DNS a Microsoft Entra ID. Azure DNS zaručuje 100% smlouvu SLA o dostupnosti pro platné požadavky DNS. Microsoft Entra zaručuje alespoň 99,99% dobu provozu. Přesto byste měli vědět o dopadu v případě selhání.
Závislost na základních službách je nevyhnutelné, protože mnoho služeb Azure na nich závisí. Pokud nejsou dostupné, počítejte s přerušením systému. Například:
- Azure Front Door používá Azure DNS k dosažení back-endu a dalších globálních služeb.
- Azure Container Registry využívá Azure DNS k převzetí služeb při selhání požadavků do jiné oblasti.
V obou případech budou obě služby Azure ovlivněny, pokud azure DNS není k dispozici. Překlad ip adres pro požadavky uživatelů ze služby Front Door selže; Image Dockeru se z registru nepřetáhnou. Použití externí služby DNS jako zálohování nezmírní riziko, protože mnoho služeb Azure nepovoluje takovou konfiguraci a spoléhá na interní DNS. Počítejte s úplným výpadkem.
Podobně se ID Microsoft Entra používá pro operace řídicí roviny, jako je vytváření nových uzlů AKS, načítání imagí ze služby Container Registry nebo přístup ke službě Key Vault při spuštění podu. Pokud není ID Microsoft Entra k dispozici, stávající komponenty by neměly být ovlivněné, ale celkový výkon může být snížený. Nové pody nebo uzly AKS nebudou funkční. V případě, že se během této doby vyžadují operace horizontálního navýšení kapacity, očekáváme snížení uživatelského prostředí.
Prostředky razítka místního nasazení
V této architektuře nasadí razítko nasazení úlohu a zřídí prostředky, které se účastní dokončení obchodních transakcí. Kolek obvykle odpovídá nasazení do oblasti Azure. I když oblast může mít více než jedno razítko.
| Charakteristiky | Požadavky |
|---|---|
| Životnost | Očekává se, že prostředky budou mít krátký časový rozsah (dočasný) se záměrem, že se můžou přidávat a odebírat dynamicky, zatímco regionální prostředky mimo razítko budou i nadále zachovány. Dočasný charakter je potřeba k zajištění větší odolnosti, škálování a blízkosti uživatelů. |
| State | Vzhledem k tomu, že kolky jsou dočasné a mohou být zničeny kdykoli, razítko by mělo být co nejvíce bezstavové. |
| Reach | Může komunikovat s regionálními a globálními prostředky. Je však třeba se vyhnout komunikaci s jinými oblastmi nebo jinými razítky. V této architektuře není potřeba tyto prostředky globálně distribuovat. |
| Závislosti | Prostředky razítka musí být nezávislé. To znamená, že by se neměli spoléhat na jiná razítka nebo komponenty v jiných oblastech. Očekává se, že budou mít regionální a globální závislosti. Hlavní sdílená komponenta je vrstva databáze a registr kontejneru. Tato komponenta vyžaduje synchronizaci za běhu. |
| Omezení škálování | Propustnost se naváže prostřednictvím testování. Propustnost celkového razítka je omezená na nejméně výkonný prostředek. Propustnost kolku musí vzít v úvahu odhadovanou vysokou úroveň poptávky a převzetí služeb při selhání v důsledku toho, že v oblasti se stane nedostupným jiným razítkem. |
| Dostupnost / zotavení po havárii | Vzhledem k dočasné povaze kolků se zotavení po havárii provádí opětovným nasazením razítka. Pokud jsou prostředky ve špatném stavu, je možné kolek jako celek zničit a znovu nasadit. |
V této architektuře jsou prostředky kolku azure Kubernetes Service, Azure Event Hubs, Azure Key Vault a Azure Blob Storage.
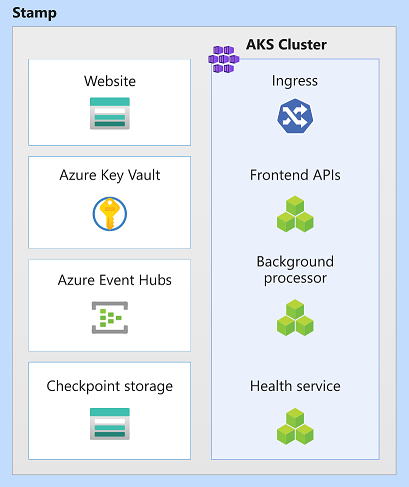
Jednotka škálování
Kolek lze také považovat za jednotku škálování (SU). Všechny komponenty a služby v daném razítku se konfigurují a testují tak, aby obsluhovaly požadavky v daném rozsahu. Tady je příklad jednotky škálování použité v implementaci.
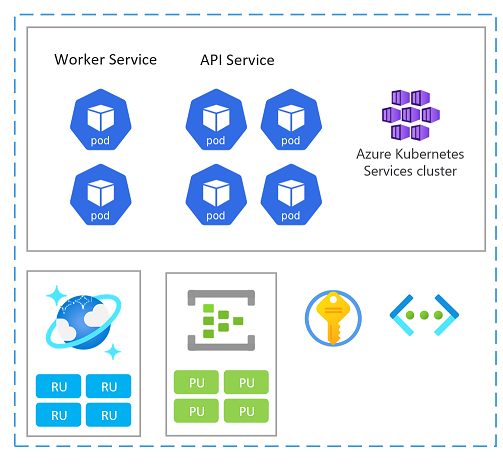
Každá jednotka škálování se nasadí do oblasti Azure a proto primárně zpracovává provoz z dané oblasti (i když může v případě potřeby převzít provoz z jiných oblastí). Toto geografické rozpětí bude pravděpodobně mít za následek vzorce zatížení a pracovní dobu, které se můžou lišit od oblasti po oblast, a proto je každá SU navržená tak, aby se při nečinnosti škálovat nebo snížit.
Můžete nasadit nové razítko pro škálování. Uvnitř razítka můžou být jednotlivé prostředky také jednotky škálování.
Tady je několik aspektů škálování a dostupnosti při výběru služeb Azure v lekci:
Vyhodnoťte vztahy kapacity mezi všemi prostředky v jednotce škálování. Například pro zpracování 100 příchozích požadavků bude potřeba 5 podů kontroleru příchozího přenosu dat a 3 pody služby katalogu a 1000 RU ve službě Azure Cosmos DB. Proto při automatickém škálování podů příchozího přenosu dat počítejte s škálováním služby katalogu a jednotek RU služby Azure Cosmos DB vzhledem k těmto rozsahům.
Zátěžový test služeb k určení rozsahu, ve kterém se budou požadavky obsluhovat. Na základě výsledků konfigurují minimální a maximální instance a cílové metriky. Po dosažení cíle se můžete rozhodnout automatizovat škálování celé jednotky.
Projděte si limity a kvóty škálování předplatného Azure, které podporují kapacitu a nákladový model nastavený obchodními požadavky. Zkontrolujte také limity jednotlivých služeb, které je potřeba vzít v úvahu. Vzhledem k tomu, že jednotky se obvykle nasazují společně, zapojte do limitů prostředků předplatného, které jsou potřeba pro kanárské nasazení. Další informace najdete v tématu Omezení služby Azure.
Zvolte služby, které podporují zóny dostupnosti pro sestavení redundance. To může omezit vaše technologické volby. Podrobnosti najdete v Zóny dostupnosti.
Další důležité informace o velikosti jednotky a kombinaci prostředků najdete v tématu Misson-critical guidance in Well-architected Framework: Scale-unit architecture.
Výpočtový cluster
Ke kontejnerizaci úlohy musí každý kolek spustit výpočetní cluster. V této architektuře je zvolena služba Azure Kubernetes Service (AKS), protože Kubernetes je nejoblíbenější výpočetní platformou pro moderní kontejnerizované aplikace.
Životnost clusteru AKS je svázaná s dočasným charakterem razítka. Cluster je bezstavový a nemá trvalé svazky. Místo spravovaných disků používá dočasné disky s operačním systémem, protože se neočekává, že budou přijímat údržbu na úrovni aplikace nebo systému.
Pro zvýšení spolehlivosti je cluster nakonfigurovaný tak, aby používal všechny tři zóny dostupnosti v dané oblasti. Díky tomu může cluster používat smlouvu SLA o provozu AKS, která zaručuje 99,95% dostupnost smlouvy SLA řídicí roviny AKS.
Další faktory, jako jsou limity škálování, výpočetní kapacita nebo kvóta předplatného, můžou mít také vliv na spolehlivost. Pokud není dosaženo dostatečné kapacity nebo limitů, operace horizontálního navýšení kapacity a vertikálního navýšení kapacity selžou, ale očekává se, že budou fungovat stávající výpočetní prostředky.
Cluster má povolené automatické škálování, aby fondy uzlů v případě potřeby automaticky navyšily kapacitu, což zvyšuje spolehlivost. Při použití více fondů uzlů by měly být všechny fondy uzlů automaticky škálovány.
Na úrovni podu horizontální automatické škálování podů (HPA) škáluje pody na základě nakonfigurovaných metrik procesoru, paměti nebo vlastních metrik. Zátěžový test součástí úlohy, aby vytvořil směrný plán pro hodnoty automatického škálování a HPA.
Cluster je také nakonfigurovaný pro automatické upgrady imagí uzlů a pro správné škálování během těchto upgradů. Toto škálování umožňuje nulový výpadek během provedení upgradů. Pokud cluster v jednom razítku během upgradu selže, nemělo by to mít vliv na ostatní clustery v jiných razítkech, ale upgrady napříč kolky by měly probíhat v různých časech, aby se zachovala dostupnost. Upgrady clusteru se také automaticky zahrnou mezi uzly, aby byly nedostupné současně.
Některé komponenty, jako je cert-manager a ingress-nginx, vyžadují image kontejnerů z externích registrů kontejnerů. Pokud tato úložiště nebo image nejsou dostupná, nemusí se nové instance na nových uzlech (kde image není uložená v mezipaměti) spustit. Toto riziko je možné zmírnit importem těchto imagí do služby Azure Container Registry prostředí.
Pozorovatelnost je v této architektuře důležitá , protože kolky jsou dočasné. Nastavení diagnostiky jsou nakonfigurovaná tak, aby ukládaly všechna data protokolů a metrik do místního pracovního prostoru služby Log Analytics. Kontejner AKS Přehledy je také povolený prostřednictvím agenta OMS v clusteru. Tento agent umožňuje clusteru odesílat data monitorování do pracovního prostoru služby Log Analytics.
Další důležité informace o výpočetním clusteru najdete v důležitých pokynech pro Misson v dobře architektuované architektuře: Orchestrace kontejnerů a Kubernetes.
Key Vault
Azure Key Vault slouží k ukládání globálních tajných kódů, jako jsou připojovací řetězec do databáze a tajných kódů razítka, jako je připojovací řetězec event Hubs.
Tato architektura používá ovladač CSI úložiště tajných kódů ve výpočetním clusteru k získání tajných kódů ze služby Key Vault. Tajné kódy jsou potřeba při vytváření nových podů. Pokud není služba Key Vault dostupná, nemusí se začít používat nové pody. V důsledku toho může dojít k přerušení; Operace horizontálního navýšení kapacity můžou mít vliv, aktualizace můžou selhat, nová nasazení se nedají spustit.
Key Vault má limit počtu operací. Kvůli automatické aktualizaci tajných kódů je možné dosáhnout limitu, pokud existuje mnoho podů. Můžete se rozhodnout snížit frekvenci aktualizací , abyste se této situaci vyhnuli.
Další důležité informace o správě tajných kódů najdete v důležitých doprovodných materiálech v dobře architektuře architektury: Ochrana integrity dat.
Event Hubs
Jedinou stavovou službou v razítku je zprostředkovatel zpráv, Azure Event Hubs, který ukládá žádosti po krátkou dobu. Zprostředkovatel obsluhuje potřebu ukládání do vyrovnávací paměti a spolehlivého zasílání zpráv. Zpracovávané požadavky se uchovávají v globální databázi.
V této architektuře se používá skladová položka Standard a pro zajištění vysoké dostupnosti je povolená redundance zón.
Stav služby Event Hubs ověřuje komponenta HealthService spuštěná ve výpočetním clusteru. Provádí pravidelné kontroly různých zdrojů. To je užitečné při zjišťování podmínek, které nejsou v pořádku. Pokud například nelze odesílat zprávy do centra událostí, razítko by bylo nepoužitelné pro všechny operace zápisu. Služba HealthService by měla tuto podmínku automaticky rozpoznat a nahlásit stav není v pořádku službě Front Door, což vytáčí razítko mimo rotaci.
Pro zajištění škálovatelnosti se doporučuje povolení automatického nafouknutí.
Další informace najdete v tématu Služby zasílání zpráv pro klíčové úlohy.
Další důležité informace o zasílání zpráv najdete v tématu s důležitými pokyny pro Misson v architektuře: Asynchronní zasílání zpráv.
Účty úložiště
V této architektuře jsou zřízeny dva účty úložiště. Oba účty se nasazují v zónově redundantním režimu (ZRS).
Jeden účet se používá pro vytváření kontrolních bodů služby Event Hubs. Pokud tento účet nereaguje, razítko nebude moct zpracovávat zprávy ze služby Event Hubs a může to mít i vliv na jiné služby v kolku. Tato podmínka se pravidelně kontroluje službou HealthService, což je jedna z komponent aplikací spuštěných ve výpočetním clusteru.
Druhý se používá k hostování jednostrákové aplikace uživatelského rozhraní. Pokud má obsluha statického webu nějaké problémy, služba Front Door tento problém zjistí a neodesílá provoz do tohoto účtu úložiště. Během této doby může služba Front Door používat obsah uložený v mezipaměti.
Další informace o obnovení najdete v tématu Zotavení po havárii a převzetí služeb při selhání účtu úložiště.
Regionální zdroje
Systém může mít prostředky nasazené v oblasti, ale prožít prostředky razítka. V této architektuře se data pozorovatelnosti pro prostředky kolku ukládají v místních úložištích dat.
| Charakteristiky | Situace |
|---|---|
| Životnost | Prostředky sdílejí dobu životnosti oblasti a zažívají prostředky razítka. |
| State | Stav uložený v oblasti nemůže žít po dobu životnosti oblasti. Pokud je potřeba sdílet stav napříč oblastmi, zvažte použití globálního úložiště dat. |
| Reach | Prostředky nemusí být globálně distribuované. Přímá komunikace s jinými oblastmi by se měla vyhnout všem nákladům. |
| Závislosti | Prostředky můžou mít závislosti na globálních prostředcích, ale ne na prostředcích razítka, protože kolky mají být krátkodobé. |
| Omezení škálování | Určete limit škálování regionálních prostředků kombinací všech razítek v rámci oblasti. |
Monitorování dat pro prostředky kolku
Nasazení monitorovacích prostředků je typickým příkladem regionálních prostředků. V této architektuře má každá oblast samostatný pracovní prostor služby Log Analytics nakonfigurovaný tak, aby ukládaly všechna data protokolů a metrik vygenerovaná z prostředků kolku. Vzhledem k tomu, že zdroje místního prostředí mají razítko, jsou data k dispozici i po odstranění razítka.
Azure Log Analytics a Aplikace Azure Přehledy se používají k ukládání protokolů a metrik z platformy. Doporučuje se omezit denní kvótu úložiště, zejména v prostředích, která se používají pro zátěžové testování. Nastavte také zásady uchovávání informací pro ukládání všech dat. Tato omezení zabrání jakémukoli nadměrnému překročení, které vzniknou uložením dat, která nejsou potřebná nad rámec limitu.
Podobně se aplikační Přehledy nasadí také jako regionální prostředek, aby se shromáždila všechna data monitorování aplikací.
Doporučení k návrhu týkající se monitorování najdete v tématu Misson-critical guidance in Well-architected Framework: Health modeling.
Další kroky
Nasaďte referenční implementaci, abyste získali úplný přehled o prostředcích a jejich konfiguraci používaných v této architektuře.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro