Úroveň bezserverových výpočetních prostředků pro službu Azure SQL Database
Platí pro: ![]() Azure SQL Database
Azure SQL Database
Bezserverová úroveň je výpočetní úroveň pro izolované databáze ve službě Azure SQL Database, která automaticky škáluje výpočetní prostředky na základě poptávky na zatížení a účtuje množství výpočetních prostředků využitých za sekundu. Bezserverová výpočetní úroveň také automaticky pozastavuje databáze v období neaktivity, kdy se účtuje pouze úložiště, a při vrácení aktivity databáze automaticky obnovuje. Úroveň výpočetních prostředků bez serveru je k dispozici na úrovni služby Pro obecné účely a na úrovni služby Hyperscale .
Poznámka:
Automatické pozastavení a automatické obnovení se v současné době podporuje jenom na úrovni služby Pro obecné účely.
Přehled
Rozsah automatického škálování výpočetních prostředků a zpoždění automatického pozastavení jsou důležité parametry pro bezserverovou výpočetní úroveň. Konfigurace těchto parametrů tvaruje výkon databáze a náklady na výpočetní prostředky.
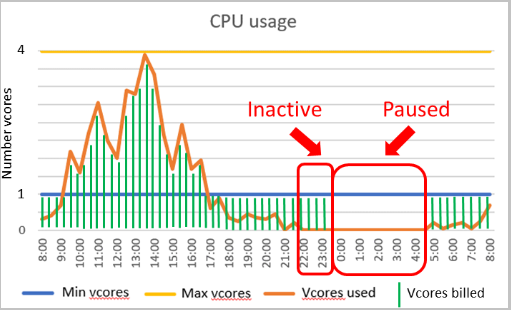
Konfigurace výkonu
- Minimální počet virtuálních jader a maximální počet virtuálních jader jsou konfigurovatelné parametry, které definují rozsah výpočetní kapacity dostupné pro databázi. Omezení paměti a vstupně-výstupních operací jsou úměrná zadanému rozsahu virtuálních jader.
- Zpoždění automatického pozastavení je konfigurovatelný parametr, který definuje dobu, po kterou musí být databáze neaktivní, než se automaticky pozastaví. Databáze se automaticky obnoví, když dojde k dalšímu přihlášení nebo jiné aktivitě. Případně je možné automatické pozastavení zakázat.
Náklady
- Náklady na bezserverovou databázi jsou součtem nákladů na výpočetní prostředky a nákladů na úložiště.
- Pokud je využití výpočetních prostředků mezi nakonfigurovaným minimálním a maximálním limitem, náklady na výpočetní prostředky jsou založené na využitých virtuálních jádrech a paměti.
- Pokud je využití výpočetních prostředků nižší než minimální nakonfigurovaná omezení, náklady na výpočetní prostředky jsou založené na minimálních virtuálních jádrech a nakonfigurované minimální paměti.
- Když je databáze pozastavená, náklady na výpočetní prostředky jsou nulové a účtují se pouze náklady na úložiště.
- Náklady na úložiště se určují stejným způsobem jako ve zřízené výpočetní vrstvě.
Další podrobnosti o nákladech najdete v tématu Fakturace.
Scénáře
Bezserverová architektura nabízí optimální poměr cena/výkon pro jednoúčelové databáze s přerušovanými a nepředvídatelnými vzory využití, které si můžou dovolit určité zpoždění při přípravě výpočetních prostředků po obdobích nečinnosti. Naproti tomu zřízená úroveň výpočetních prostředků je cenově optimalizovaná pro izolované databáze nebo více databází v elastických fondech s vyšším průměrným využitím, které si nemohou dovolit žádné zpoždění při zahřátí výpočetních prostředků.
Scénáře vhodné pro výpočetní prostředí bez serveru
- Samostatné databáze s přerušovaným nepředvídatelným využitím prokládaným obdobími nečinnosti a nižším průměrným využitím výpočetních prostředků v průběhu času
- Samostatné databáze na úrovni zřízených výpočetních prostředků, které se často škálují, a zákazníci, kteří upřednostňují delegování škálování výpočetních prostředků na tuto službu
- Nové izolované databáze bez historie využití, kdy je určení velikosti výpočetních prostředků obtížné nebo není možné odhadnout před nasazením ve službě Azure SQL Database.
Vhodné scénáře pro zřízené výpočetní prostředky
- Izolované databáze s pravidelnějšími, předvídatelnějšími vzory využití a vyšším průměrným využitím výpočetních prostředků v průběhu času.
- Databáze, které nemohou tolerovat kompromisy z výkonu způsobené častějším oříznutím paměti nebo zpožděním při obnovení z pozastaveného stavu.
- Více databází s přerušovanými a nepředvídatelnými vzory využití, které je možné konsolidovat do elastických fondů pro lepší optimalizaci výkonu cen.
Porovnání úrovní výpočetních prostředků
Následující tabulka shrnuje rozdíly mezi bezserverovou výpočetní úrovní a zřízenou výpočetní úrovní:
| Bezserverové výpočetní prostředí | Zřízené výpočetní prostředky | |
|---|---|---|
| Model využití databáze | Přerušované a nepředvídatelné využití s nižším průměrným využitím výpočetních prostředků v průběhu času. | Častější vzory využití s vyšším průměrným využitím výpočetních prostředků v průběhu času nebo více databází využívajících elastické fondy. |
| Úsilí o správu výkonu | Lower | Vyšší |
| Škálování výpočetních prostředků | Automatic (Automaticky) | Ruční |
| Rychlost odezvy výpočetních prostředků | Nižší po neaktivních obdobích | Okamžité |
| Členitost fakturace | Sekundu | Za hodinu |
Nákupní model a úroveň služeb
Následující tabulka popisuje bezserverovou podporu na základě nákupního modelu, úrovní služeb a hardwaru:
| Kategorie | Podporuje se | Nepodporováno |
|---|---|---|
| Nákupní model | Virtuální jádro | DTU |
| Úroveň služby | Obecné použití Hyperškálování |
Pro důležité obchodní informace |
| Hardware | Řada Standard (Gen5) | Veškerý ostatní hardware |
Automatické škálování
Rychlost odezvy škálování
Bezserverové databáze se spouštějí na počítači s dostatečnou kapacitou pro uspokojení poptávky po prostředcích bez přerušení jakéhokoli množství výpočetních prostředků požadovaných v mezích nastavených maximální hodnotou virtuálních jader. Vyrovnávání zatížení se někdy stává automaticky, pokud počítač během několika minut nedokáže vyhovět poptávce po prostředcích. Pokud je například poptávka po prostředcích 4 virtuálních jader, ale jsou k dispozici pouze 2 virtuální jádra, může vyrovnávání zatížení trvat až několik minut, než se poskytne 4 virtuální jádra. Databáze zůstane online během vyrovnávání zatížení s výjimkou krátkého období na konci operace, když dojde k vyřazení připojení.
Správa paměti
V úrovních služby Pro obecné účely i Hyperscale se paměť pro bezserverové databáze uvolní častěji než u zřízených výpočetních databází. Toto chování je důležité k řízení nákladů v bezserverové aplikaci a může mít vliv na výkon.
Relamace mezipaměti
Na rozdíl od zřízených výpočetních databází se paměť z mezipaměti SQL uvolní z bezserverové databáze v případě nízkého využití procesoru nebo aktivní mezipaměti.
- Využití aktivní mezipaměti se považuje za nízké, když celková velikost naposledy použitých položek mezipaměti klesne pod prahovou hodnotu po určitou dobu.
- Při aktivaci reclamace mezipaměti se cílová velikost mezipaměti zmenší přírůstkově na zlomek předchozí velikosti a uvolnění paměti bude pokračovat pouze v případě, že využití zůstává nízké.
- Když dojde k reclamaci mezipaměti, zásady pro výběr položek mezipaměti, které se mají vyřadit, jsou stejné zásady výběru jako pro zřízené výpočetní databáze, pokud je zatížení paměti vysoké.
- Velikost mezipaměti se nikdy nezmenší pod minimální limit paměti, jak je definováno minimálními virtuálními jádry.
V bezserverových i zřízených výpočetních databázích je možné položky mezipaměti vyřadit, pokud se použije všechna dostupná paměť.
Pokud je využití procesoru nízké, může aktivní využití mezipaměti zůstat vysoké v závislosti na vzoru využití a zabránit reclamaci paměti. Může také dojít k dalším zpožděním po zastavení aktivity uživatele před obnovením paměti kvůli pravidelným procesům na pozadí, které reagují na předchozí aktivitu uživatele. Například operace odstranění a úlohy čištění úložiště dotazů generují záznamy duchů, které jsou označené k odstranění, ale nejsou fyzicky odstraněny, dokud proces čištění duchů neběží. Čištění duchů může zahrnovat čtení datových stránek do mezipaměti.
Hydrace mezipaměti
Mezipaměť paměti SQL roste, protože data se načítají z disku stejným způsobem a se stejnou rychlostí jako u zřízených databází. Pokud je databáze zaneprázdněná, může se mezipaměť zvětšit bez omezení, pokud je k dispozici paměť.
Správa mezipaměti disku
V úrovni služby Hyperscale pro bezserverovou i zřízenou výpočetní vrstvu používá každá výpočetní replika mezipaměť odolného fondu vyrovnávacích pamětí (RBPEX), která ukládá datové stránky na místním disku SSD, aby se zlepšil výkon vstupně-výstupních operací. V bezserverové výpočetní vrstvě hyperškálování se však mezipaměť RBPEX pro každou výpočetní repliku automaticky zvětší a zmenší v reakci na zvýšení a snížení poptávky po úlohách. Maximální velikost, na které může mezipaměť RBPEX narůstat, je třikrát vyšší než maximální paměť nakonfigurovaná pro databázi. Podrobnosti o maximální paměti a omezení automatického škálování RBPEX v bezserverové verzi najdete v tématu Omezení prostředků hyperškálování bez serveru.
Automatické pozastavení a automatické obnovení
V současné době se automatické pozastavení a automatické obnovení bez serveru podporuje jenom na úrovni Pro obecné účely.
Automatické pozastavení
Automatické pozastavení se aktivuje, pokud jsou během zpoždění automatického pozastavení splněny všechny následující podmínky:
- Počet relací = 0
- Počet procesorů = 0 pro uživatelské úlohy spuštěné v uživatelském fondu
V případě potřeby je k dispozici možnost automatického pozastavení.
Následující funkce nepodporují automatické pozastavení, ale podporují automatické škálování. Pokud použijete některou z následujících funkcí, je potřeba automatické pozastavení zakázat a databáze zůstane online bez ohledu na dobu nečinnosti databáze:
- Geografická replikace (aktivní geografická replikace a skupiny převzetí služeb při selhání)
- Dlouhodobé uchovávání záloh (LTR).
- Synchronizační databáze použitá v Synchronizace dat SQL. Na rozdíl od synchronizačních databází podporují automatické pozastavení databáze centra a členů.
- Alias DNS vytvořený pro logický server obsahující bezserverovou databázi.
- Elastické úlohy, bezserverová databáze s povoleným automatickým pozastavením není podporována jako databáze úloh. Bezserverové databáze cílené elastickými úlohami podporují automatické pozastavení. Připojení úloh obnoví databázi.
Automatické pozastavení je dočasně zabráněno během nasazování některých aktualizací služby, které vyžadují, aby byla databáze online. V takových případech se automatické pozastavení znovu povolí, jakmile se aktualizace služby dokončí.
Řešení potíží s automatickým pozastavením
Pokud je povolené automatické pozastavení a funkce, které blokují automatické pozastavení, se nepoužívají, ale databáze se po uplynutí doby zpoždění automaticky pozastaví, může bránit automatickému pozastavení relací aplikace nebo uživatelů.
Pokud chcete zjistit, jestli jsou k databázi aktuálně připojené nějaké relace aplikací nebo uživatelů, připojte se k databázi pomocí jakéhokoli klientského nástroje a spusťte následující dotaz:
SELECT session_id,
host_name,
program_name,
client_interface_name,
login_name,
status,
login_time,
last_request_start_time,
last_request_end_time
FROM sys.dm_exec_sessions AS s
INNER JOIN sys.dm_resource_governor_workload_groups AS wg
ON s.group_id = wg.group_id
WHERE s.session_id <> @@SPID
AND
(
(
wg.name like 'UserPrimaryGroup.DB%'
AND
TRY_CAST(RIGHT(wg.name, LEN(wg.name) - LEN('UserPrimaryGroup.DB') - 2) AS int) = DB_ID()
)
OR
wg.name = 'DACGroup'
);
Tip
Po spuštění dotazu se nezapomeňte odpojit od databáze. Jinak otevřená relace používaná dotazem zabrání automatickému pozastavení.
- Pokud je sada výsledků neprázdná, znamená to, že aktuálně brání automatickému pozastavení relací.
- Pokud je sada výsledků dotazu prázdná, stále je možné, že někdy dříve během doby zpoždění automatického pozastavení byly otevřené nějaké relace, pravděpodobně po krátkou dobu. Pokud chcete zkontrolovat aktivitu během období zpoždění, můžete použít auditování Azure SQL a prozkoumat data auditu pro příslušné období.
Důležité
Otevřené relace, ať už se souběžným využitím procesoru ve fondu prostředků uživatelů, nebo bez, jsou nejčastější příčinou, proč nedojde k očekávanému automatickému pozastavení bezserverové databáze.
Automatické obnovení
Automatické obnovení se aktivuje, pokud jsou splněné některé z následujících podmínek:
| Funkce | Trigger automatického obnovení |
|---|---|
| Ověřování a autorizace | Přihlásit |
| Detekce hrozeb | Povolení nebo zákaz nastavení detekce hrozeb na úrovni databáze nebo serveru Úprava nastavení detekce hrozeb na úrovni databáze nebo serveru |
| Zjišťování a klasifikace dat | Přidání, úprava, odstranění nebo zobrazení popisků citlivosti |
| Auditování | Zobrazení záznamů auditování Aktualizace nebo zobrazení zásad auditování |
| Maskování dat | Přidání, úprava, odstranění nebo zobrazení pravidel maskování dat |
| Transparentní šifrování dat | Zobrazení stavu nebo stavu transparentního šifrování dat |
| Posouzení ohrožení zabezpečení | Ad hoc kontroly a pravidelné kontroly, pokud jsou povolené |
| Dotazování úložiště dat (výkon) | Úprava nebo zobrazení nastavení úložiště dotazů |
| Doporučení k výkonu | Zobrazení nebo použití doporučení k výkonu |
| Automatické ladění | Aplikace a ověření doporučení automatického ladění, jako je automatické indexování |
| Kopírování databáze | Vytvoření kopie databáze Export do souboru BACPAC. |
| Synchronizace dat SQL | Synchronizace mezi centrálními a členskými databázemi, které běží v konfigurovatelném plánu nebo se provádějí ručně |
| Úprava určitých metadat databáze | Přidání nových databázových značek Změna maximálního počtu virtuálních jader, minimálních virtuálních jader nebo zpoždění automatického pozastavení |
| SQL Server Management Studio (SSMS) | Při použití verzí SSMS starších než 18.1 a otevření nového okna dotazu pro libovolnou databázi na serveru se obnoví všechny automaticky pozastavené databáze na stejném serveru. K tomuto chování nedojde, pokud používáte SSMS verze 18.1 nebo novější. |
Monitorování, správa nebo jiná řešení provádějící některou z výše uvedených operací aktivuje automatické obnovení. Automatické obnovení se aktivuje také během nasazování některých aktualizací služeb, které vyžadují online databázi.
Připojení
Pokud je bezserverová databáze pozastavená, první pokus o připojení obnoví databázi a vrátí chybu s informací, že databáze není k dispozici s kódem chyby 40613. Po obnovení databáze je možné přihlášení opakovat a navázat připojení. Databázové klienty, kteří sledují doporučení logiky opakování připojení, by se nemělo upravovat. Možnosti logiky opakování připojení a doporučení najdete v tématech:
- Logika opakování připojení v SqlClient
- Logika opakování připojení ve službě SQL Database s využitím Entity Framework Core
- Logika opakování připojení ve službě SQL Database s využitím Entity Frameworku 6
- Logika opakování připojení ve službě SQL Database s využitím ADO.NET
Latence
Latence automatického obnovení a automatického pozastavení bezserverové databáze je obvykle 1 minuta automatického obnovení a 1 až 10 minut po uplynutí doby zpoždění automatického pozastavení.
Transparentní šifrování dat spravované zákazníkem (BYOK)
Odstranění nebo odvolání klíče
Pokud používáte transparentní šifrování dat spravované zákazníkem (BYOK) a bezserverová databáze se při odstranění nebo odvolání klíče automaticky pozastaví, databáze zůstane v automaticky pozastaveném stavu. V takovém případě bude databáze po dalším obnovení nedostupná během přibližně 10 minut. Jakmile bude databáze nepřístupná, proces obnovení je stejný jako u zřízených výpočetních databází. Pokud dojde k odstranění nebo odvolání klíče online bezserverové databáze, stane se databáze také nepřístupná přibližně během 10 minut stejně jako u zřízených výpočetních databází.
Obměna klíčů
Pokud používáte transparentní šifrování dat spravované zákazníkem (BYOK) a je povolené automatické pozastavení bez serveru, databáze se automaticky obnoví při každé obměně klíčů a následném automatickém pozastavení, když jsou splněny podmínky automatického pozastavení.
Vytvoření nové bezserverové databáze
Vytvoření nové databáze nebo přesunutí existující databáze do bezserverové výpočetní úrovně se řídí stejným vzorem jako vytvoření nové databáze ve zřízené výpočetní vrstvě a zahrnuje následující dva kroky:
Zadejte cíl služby. Cíl služby předepisuje úroveň služby, konfiguraci hardwaru a maximální počet virtuálních jader. Možnosti cíle služby najdete v tématu Omezení bezserverových prostředků.
Volitelně můžete zadat minimální zpoždění virtuálních jader a zpoždění automatického pozastavení, aby se změnily jejich výchozí hodnoty. V následující tabulce jsou uvedeny dostupné hodnoty těchto parametrů.
Parametr Volby hodnot Default value Minimální počet virtuálních jader Závisí na maximálních nakonfigurovaných virtuálních jádrech – viz limity prostředků. 0,5 virtuálních jader Zpoždění automatického pozastavení Minimum: 15 minut
Maximum: 10 080 minut (7 dní)
Přírůstky: 1 minuta
Zakázat automatické pozastavení: -160 min
Následující příklady vytvoří novou databázi na úrovni výpočetních prostředků bez serveru.
Použití webu Azure Portal
Viz Rychlý start: Vytvoření izolované databáze ve službě Azure SQL Database pomocí webu Azure Portal.
Použití PowerShellu
Vytvořte novou bezserverovou databázi pro obecné účely s následujícím příkladem PowerShellu:
New-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 0.5 -MaxVcore 2 -AutoPauseDelayInMinutes 720
Použití Azure CLI
Vytvořte novou bezserverovou databázi pro obecné účely s následujícím příkladem Azure CLI:
az sql db create -g $resourceGroupName -s $serverName -n $databaseName `
-e GeneralPurpose --compute-model Serverless -f Gen5 `
--min-capacity 0.5 -c 2 --auto-pause-delay 720
Použití jazyka Transact-SQL (T-SQL)
Při použití T-SQL k vytvoření nové bezserverové databáze se použijí výchozí hodnoty pro minimální počet virtuálních jader a zpoždění automatického pozastavení. Jejich hodnoty je možné následně změnit z webu Azure Portal nebo prostřednictvím rozhraní API, včetně PowerShellu, Azure CLI a REST.
Podrobnosti najdete v tématu CREATE DATABASE.
Vytvořte novou bezserverovou databázi pro obecné účely s následujícím příkladem T-SQL:
CREATE DATABASE testdb
( EDITION = 'GeneralPurpose', SERVICE_OBJECTIVE = 'GP_S_Gen5_1' ) ;
Přesun databáze mezi úrovněmi výpočetních prostředků nebo úrovněmi služby
Databázi je možné přesouvat mezi zřízenou výpočetní vrstvou a bezserverovou výpočetní úrovní.
Bezserverovou databázi lze také přesunout z úrovně služby Pro obecné účely do úrovně služby Hyperscale. Další informace najdete v tématu Správa databází Hyperscale.
Při přesouvání databáze mezi úrovněmi výpočetních prostředků zadejte parametr výpočetního modelu buď Serverless nebo Provisioned při použití PowerShellu nebo Azure CLI, nebo SERVICE_OBJECTIVE při použití T-SQL. Zkontrolujte limity prostředků a identifikujte odpovídající cíl služby.
Následující příklady přesunou existující databázi ze zřízeného výpočetního prostředí do bezserverové databáze.
Použití PowerShellu
Přesuňte zřízenou výpočetní databázi pro obecné účely do bezserverové výpočetní úrovně pomocí následujícího příkladu PowerShellu:
Set-AzSqlDatabase -ResourceGroupName $resourceGroupName -ServerName $serverName -DatabaseName $databaseName `
-Edition GeneralPurpose -ComputeModel Serverless -ComputeGeneration Gen5 `
-MinVcore 1 -MaxVcore 4 -AutoPauseDelayInMinutes 1440
Použití Azure CLI
Přesuňte zřízenou výpočetní databázi pro obecné účely do bezserverové výpočetní úrovně pomocí následujícího příkladu Azure CLI:
az sql db update -g $resourceGroupName -s $serverName -n $databaseName `
--edition GeneralPurpose --compute-model Serverless --family Gen5 `
--min-capacity 1 --capacity 4 --auto-pause-delay 1440
Použití jazyka Transact-SQL (T-SQL)
Při použití T-SQL k přesunu databáze mezi úrovněmi výpočetních prostředků se použijí výchozí hodnoty pro minimální počet virtuálních jader a zpoždění automatického pozastavení. Jejich hodnoty je možné následně změnit z webu Azure Portal nebo prostřednictvím rozhraní API, včetně PowerShellu, Azure CLI a REST. Další informace naleznete v tématu ALTER DATABASE.
Přesuňte zřízenou výpočetní databázi pro obecné účely do bezserverové výpočetní úrovně s následujícím příkladem T-SQL:
ALTER DATABASE testdb
MODIFY ( SERVICE_OBJECTIVE = 'GP_S_Gen5_1') ;
Úprava bezserverové konfigurace
Použití PowerShellu
Pomocí Set-AzSqlDatabase můžete upravit maximální nebo minimální počet virtuálních jader a zpoždění automatického pozastavení. Použijte argumenty MaxVcore, MinVcorea AutoPauseDelayInMinutes argumenty. Bezserverové automatické pozastavení se v současné době nepodporuje na úrovni Hyperscale, takže argument zpoždění automatického pozastavení se vztahuje pouze na úroveň Pro obecné účely.
Použití Azure CLI
Pomocí příkazu az sql db update upravte maximální nebo minimální počet virtuálních jader a zpoždění automatického pozastavení. Použijte argumenty capacity, min-capacitya auto-pause-delay argumenty. Bezserverové automatické pozastavení se v současné době nepodporuje na úrovni Hyperscale, takže argument zpoždění automatického pozastavení se vztahuje pouze na úroveň Pro obecné účely.
Monitor
Využité a fakturované prostředky
Mezi prostředky bezserverové databáze patří balíček aplikace, instance SQL a entity fondu prostředků uživatele.
Balíček aplikace
Balíček aplikace je vnější hranicí správy prostředků pro databázi bez ohledu na to, jestli je databáze v bezserverové nebo zřízené výpočetní vrstvě. Balíček aplikace obsahuje instanci SQL a externí služby, jako je fulltextové vyhledávání, které všechny dohromady rozdělují všechny uživatelské a systémové prostředky používané databází ve službě SQL Database. Instance SQL obecně dominuje celkovému využití prostředků v balíčku aplikace.
Fond zdrojů uživatelů
Fond prostředků uživatele je vnitřní hranicí správy prostředků pro databázi bez ohledu na to, jestli je databáze v bezserverové nebo zřízené úrovni výpočetních prostředků. Fond prostředků uživatele definuje procesor a vstupně-výstupní operace pro uživatelské úlohy generované dotazy DDL (CREATE a ALTER) a DML (INSERT, UPDATE, DELETE a MERGE a SELECT). Tyto dotazy obecně představují největší podíl využití v balíčku aplikace.
Metriky
Následující tabulka obsahuje metriky pro monitorování využití prostředků balíčku aplikace a fondu prostředků uživatelů bezserverové databáze, včetně všech geografických replik:
| Entity | Metrický | Popis | Jednotky |
|---|---|---|---|
| Balíček aplikace | app_cpu_percent | Procento virtuálních jader používaných aplikací vzhledem k maximálnímu počtu virtuálních jader povolených pro aplikaci U bezserverového Hyperscale se tato metrika zobrazí pro všechny primární repliky, pojmenované repliky a geografické repliky. | Procento |
| Balíček aplikace | app_cpu_billed | Množství výpočetních prostředků fakturovaných za aplikaci během sledovaného období. Částka zaplacená během tohoto období je produktem této metriky a jednotkové ceny virtuálních jader. Hodnoty této metriky se určují agregací maximálního využitého procesoru a paměti každou sekundu. Pokud je využitá částka menší než minimální zřízená částka nastavená minimálními virtuálními jádry a minimální pamětí, bude se účtovat minimální zřízená částka. Pro účely porovnání využití procesoru a paměti kvůli fakturaci se využití paměti normalizuje do jednotek virtuálních jader, a to změnou škálování množství paměti v GB o 3 GB na virtuální jádro. U bezserverové technologie Hyperscale se tato metrika zobrazí pro primární repliku a všechny pojmenované repliky. |
Sekundy virtuálních jader |
| Balíček aplikace | app_cpu_billed_HA_replicas | Vztahuje se pouze na bezserverové hyperškálování. Součet výpočetních prostředků účtovaných napříč všemi aplikacemi pro repliky vysoké dostupnosti během sledovaného období Tento součet je vymezen buď na repliky vysoké dostupnosti patřící do primární repliky, nebo repliky vysoké dostupnosti patřící do dané pojmenované repliky. Před výpočtem tohoto součtu mezi replikami vysoké dostupnosti se množství výpočetních prostředků fakturovaných za jednotlivé repliky vysoké dostupnosti určuje stejným způsobem jako u primární repliky nebo pojmenované repliky. U bezserverového Hyperscale se tato metrika zobrazí pro všechny primární repliky, pojmenované repliky a geografické repliky. Částka zaplacená během sledovaného období je součinem této metriky a jednotkové ceny virtuálních jader. | Sekundy virtuálních jader |
| Balíček aplikace | app_memory_percent | Procento paměti používané aplikací vzhledem k maximální povolené paměti pro aplikaci U bezserverového Hyperscale se tato metrika zobrazí pro všechny primární repliky, pojmenované repliky a geografické repliky. | Procento |
| Fond zdrojů uživatelů | cpu_percent | Procento virtuálních jader používaných uživatelskými úlohami vzhledem k maximálnímu počtu virtuálních jader povolených pro uživatelské úlohy | Procento |
| Fond zdrojů uživatelů | data_IO_percent | Procento IOPS dat používaných uživatelskými úlohami vzhledem k maximálnímu počtu vstupně-výstupních operací za sekundu dat povolených pro uživatelské úlohy | Procento |
| Fond zdrojů uživatelů | log_IO_percent | Procento MB/s protokolů používaných uživatelskými úlohami vzhledem k maximálnímu povolenému počtu MB/s protokolu pro uživatelské úlohy | Procento |
| Fond zdrojů uživatelů | workers_percent | Procento pracovních procesů používaných uživatelskými úlohami vzhledem k maximálnímu počtu pracovních procesů povolených pro uživatelské úlohy | Procento |
| Fond zdrojů uživatelů | sessions_percent | Procento relací používaných uživatelskými úlohami vzhledem k maximálnímu povolenému počtu relací pro uživatelské úlohy | Procento |
Pozastavení a obnovení stavu
V případě bezserverové databáze s povoleným automatickým pozastavením obsahuje stav, který hlásí, následující hodnoty:
| Status | Popis |
|---|---|
| Online | Databáze je online. |
| Pozastaveno | Databáze přechází z online na pozastavený. |
| Pozastaveno | Databáze je pozastavená. |
| Pokračování | Databáze přechází z pozastavení na online. |
Použití webu Azure Portal
Na webu Azure Portal se stav databáze zobrazí na stránce přehledu databáze a na stránce přehledu serveru. Na webu Azure Portal je také možné zobrazit historii pozastavení a obnovení událostí bezserverové databáze v protokolu aktivit.
Použití PowerShellu
Pomocí následujícího příkladu PowerShellu zobrazte aktuální stav databáze:
Get-AzSqlDatabase -ResourceGroupName $resourcegroupname -ServerName $servername -DatabaseName $databasename `
| Select -ExpandProperty "Status"
Použití Azure CLI
Pomocí následujícího příkladu Azure CLI zobrazte aktuální stav databáze:
az sql db show --name $databasename --resource-group $resourcegroupname --server $servername --query 'status' -o json
Omezení prostředků
Omezení prostředků najdete v tématu Bezserverová úroveň výpočetních prostředků.
Fakturace
Množství výpočetních prostředků účtovaných za bezserverovou databázi je maximální využitý procesor a využitá paměť každou sekundu. Pokud je množství využitého procesoru a paměti menší než minimální množství zřízené pro každý prostředek, bude se účtovat zřízená částka. Aby bylo možné porovnat procesor s pamětí pro účely fakturace, je paměť normalizována do jednotek virtuálních jader změnou velikosti počtu GB o 3 GB na virtuální jádro.
- Fakturované prostředky: PROCESOR a paměť
- Fakturovaná částka: jednotková cena virtuálního jádra * maximum (minimální počet virtuálních jader, využitá virtuální jádra, minimální paměť GB * 1/3, využitá paměť × 1/3)
- Četnost fakturace: za sekundu
Jednotková cena za virtuální jádro je cena za virtuální jádro za sekundu.
Konkrétní informace o jednotkových cenách v dané oblasti najdete na stránce s cenami služby Azure SQL Database.
Množství výpočetních prostředků fakturovaných v bezserverové databázi pro obecné účely nebo primární nebo pojmenovaná replika Hyperscale se zobrazí pomocí následující metriky:
- Metrika: app_cpu_billed (sekundy virtuálních jader)
- Definice: maximum (minimální počet virtuálních jader, využitá virtuální jádra, minimální paměť GB × 1/3, využitá paměť GB * 1/3)
- Četnost generování sestav: Za minutu založenou na měřeních za sekundu agregované přes 1 minutu.
Množství výpočetních prostředků účtovaných v bezserverové úrovni pro repliky hyperškálování, které patří do primární repliky nebo jakékoli pojmenované repliky, se vystavuje následující metrikou:
- Metrika: app_cpu_billed_HA_replicas (sekundy virtuálních jader)
- Definice: Součet maxima (minimální počet virtuálních jader, využitá virtuální jádra, minimální paměť GB × 1/3, využitá paměť × 1/3) pro všechny repliky vysoké dostupnosti patřící do nadřazeného prostředku.
- Nadřazený prostředek a koncový bod metriky: Primární replika a každá pojmenovaná replika zpřístupňují tuto metriku, která měří výpočetní prostředky účtované za všechny přidružené repliky vysoké dostupnosti.
- Četnost generování sestav: Za minutu založenou na měřeních za sekundu agregované přes 1 minutu.
Minimální vyúčtování výpočetních prostředků
Pokud je bezserverová databáze pozastavená, je faktura za výpočetní prostředky nulová. Pokud není bezserverová databáze pozastavená, minimální vyúčtování výpočetních prostředků není menší než množství virtuálních jader na základě maxima (minimální počet virtuálních jader, minimální paměť GB × 1/3).
Příklady:
- Předpokládejme, že bezserverová databáze na úrovni Pro obecné účely není pozastavená a nakonfigurovaná s 8 maximálními virtuálními jádry a 1 minimálním virtuálním jádrem odpovídajícím minimální paměti 3,0 GB. Minimální vyúčtování výpočetních prostředků je pak založeno na maximu (1 virtuální jádro, 3,0 GB × 1 virtuální jádro / 3 GB) = 1 virtuální jádro.
- Předpokládejme, že bezserverová databáze na úrovni Pro obecné účely není pozastavená a nakonfigurovaná se 4 maximálními virtuálními jádry a 0,5 minimálními virtuálními jádry odpovídajícími minimální paměti 2,1 GB. Minimální vyúčtování výpočetních prostředků je pak založeno na maximálním počtu (0,5 virtuálních jader, 2,1 GB × 1 virtuální jádro / 3 GB) = 0,7 virtuálních jader.
- Předpokládejme, že bezserverová databáze na úrovni Hyperscale má primární repliku s jednou replikou vysoké dostupnosti a jednou pojmenovanou replikou bez replik vysoké dostupnosti. Předpokládejme, že každá replika má nakonfigurované 8 maximálních virtuálních jader a minimálně 1 virtuální jádro odpovídající 3 GB minimální paměti. Minimální vyúčtování výpočetních prostředků pro primární repliku, repliku vysoké dostupnosti a pojmenovanou repliku jsou každou z nich založená na maximálním počtu (1 virtuální jádro, 3 GB × 1 virtuální jádro / 3 GB) = 1 virtuální jádro.
Cenovou kalkulačku služby Azure SQL Database pro bezserverovou architekturu je možné použít k určení minimální konfigurovatelné paměti na základě počtu nakonfigurovaných maximálních a minimálních virtuálních jader. Pokud je nakonfigurovaná minimální počet virtuálních jader větší než 0,5 virtuálních jader, je minimální účet výpočetních prostředků nezávislý na minimální nakonfigurované paměti a vychází pouze z počtu nakonfigurovaných minimálních virtuálních jader.
Příklady scénářů
Zvažte bezserverovou databázi na úrovni Pro obecné účely nakonfigurovanou s minimálním virtuálním jádrem a 4 maximálními virtuálními jádry. Tato konfigurace odpovídá přibližně 3 GB minimální paměti a maximální paměti o velikosti 12 GB. Předpokládejme, že zpoždění automatického pozastavení je nastavené na 6 hodin a úloha databáze je aktivní během prvních 2 hodin 24hodinového období a jinak neaktivní.
V tomto případě se databáze účtuje za výpočetní prostředky a úložiště během prvních 8 hodin. I když je databáze neaktivní počínaje druhou hodinou, účtuje se za výpočetní prostředky v následujících 6 hodinách na základě minimálního zřízeného výpočetního výkonu v době, kdy je databáze online. Během 24hodinového období se účtuje pouze úložiště.
Přesněji řečeno, vyúčtování výpočetních prostředků v tomto příkladu se vypočítá takto:
| Časový interval | Virtuální jádra se použily každou sekundu. | GB využito každou sekundu | Účtované dimenze výpočetních prostředků | Sekundy virtuálních jader fakturované v průběhu časového intervalu |
|---|---|---|---|---|
| 0:00-1:00 | 4 | 9 | Použité virtuální jádra | 4 virtuální jádra * 3600 sekund = 14400 sekund virtuálních jader |
| 1:00-2:00 | 0 | 12 | Využití paměti | 12 GB * 1/3 * 3600 sekund = 14400 sekund virtuálních jader |
| 2:00-8:00 | 0 | 0 | Minimální zřízená paměť | 3 GB * 1/3 * 21600 sekund = 21600 sekund virtuálních jader |
| 8:00-24:00 | 0 | 0 | Během pozastavení se neúčtují žádné výpočetní prostředky | 0 sekund virtuálních jader |
| Celkové sekundy virtuálních jader účtované za 24 hodin | 50 400 sekund virtuálních jader |
Předpokládejme, že cena výpočetní jednotky je 0,000145 USD za sekundu. Výpočetní prostředky účtované za tuto 24hodinovou dobu jsou produktem ceny výpočetní jednotky a sekundy virtuálních jader fakturované: 0,000145 USD za sekundu * 5 0400 sekund virtuálních jader ~ 7,31 USD.
Zvýhodněné hybridní využití Azure a rezervovaná kapacita
Zvýhodněné hybridní využití Azure (AHB) a slevy na rezervovanou kapacitu se nevztahují na bezserverovou výpočetní úroveň.
Dostupné oblasti
Bezserverová úroveň pro obecné účely a hyperškálování s podporou až 40 maximálních virtuálních jader je dostupná po celém světě s výjimkou následujících oblastí:
- Čína – východ
- Čína – sever
- Německo – střed
- Německo – severovýchod
- US Gov – střed (Iowa)
Oblasti podporující maximálně 80 virtuálních jader bez zón dostupnosti pro obecné účely a Hyperscale
V současné době se v následujících oblastech aktuálně podporuje 80 maximálních virtuálních jader v bezserverové úrovni pro obecné účely a hyperškálování:
- Austrálie – střed 1
- Austrálie – střed 2
- Austrálie – východ
- Austrálie – jihovýchod
- Brazílie – jih
- Brazílie – jihovýchod
- Střední Kanada
- Kanada – východ
- USA – střed
- Čína – východ 2
- Čína – východ 3
- Čína – sever 2
- Čína – sever 3
- Východní Asie
- East US
- USA – východ 2
- Francie – střed
- Francie – jih
- Německo – sever
- Německo – středozápad
- Střední Indie
- Jižní Indie
- Izrael - střed
- Itálie - sever
- Japonsko – východ
- Japonsko – západ
- Jio Indie – střed
- Jio – západní Indie
- Jižní Korea – střed
- Korea Jih
- Maylaysia – jih
- Mexiko – střed
- USA – středosever
- Severní Evropa
- Norsko – východ
- Norsko – západ
- Střední Polsko
- Střední Katar
- Jižní Afrika – sever
- Jižní Afrika – západ
- Středojižní USA
- Southeast Asia
- Španělsko – střed
- Švédsko – střed
- Švédsko – jih
- Švýcarsko – sever
- Švýcarsko – západ
- Tchaj-wan – sever
- Tchaj-wan – severozápad
- Spojené arabské emiráty – střed
- Spojené arabské emiráty – sever
- Spojené království – jih
- Spojené království – západ
- US Gov – východ
- US Gov Southcentral
- US Gov – jihozápad
- Západní Evropa
- Středozápad USA
- USA – západ
- Západní USA 2
- USA – západ 3
Oblasti podporující maximálně 80 virtuálních jader se zónami dostupnosti pro obecné účely a Hyperškálování
V současné době je k dispozici 80 maximálních virtuálních jader s podporou zóny dostupnosti v bezserverové úrovni pro obecné účely a hyperškálování v následujících oblastech s dalšími plánovanými oblastmi:
- Austrálie – východ
- Brazílie – jih
- Střední Kanada
- USA – střed
- Východní Asie
- East US
- USA – východ 2
- Francie – střed
- Německo – středozápad
- Střední Indie
- Japonsko – východ
- Jižní Korea – střed
- Severní Evropa
- Jižní Afrika – sever
- Středojižní USA
- Southeast Asia
- Švédsko – střed
- Spojené arabské emiráty – sever
- Spojené království – jih
- US Gov – východ
- Západní Evropa
- Západní USA 2
- USA – západ 3
Související obsah
- Pokud chcete začít, přečtěte si článek Rychlý start: Vytvoření izolované databáze – Azure SQL Database.
- Možnosti bezserverové úrovně služby najdete v tématu Obecné účely a Hyperscale.