Osvědčené postupy služby Azure Machine Učení pro podnikové zabezpečení
Tento článek vysvětluje osvědčené postupy zabezpečení pro plánování nebo správu zabezpečeného nasazení služby Azure Machine Učení. Osvědčené postupy pocházejí z Microsoftu a zkušeností zákazníků se službou Azure Machine Učení. Každý návod vysvětluje postup a jeho odůvodnění. Článek obsahuje také odkazy na návody a referenční dokumentaci.
Doporučená architektura zabezpečení sítě (spravovaná síť)
Doporučená architektura zabezpečení sítě strojového učení je spravovaná virtuální síť. Počítač Azure Učení spravovaná virtuální síť zabezpečuje pracovní prostor, přidružené prostředky Azure a všechny spravované výpočetní prostředky. Zjednodušuje konfiguraci a správu zabezpečení sítě tím, že předem nakonfiguruje požadované výstupy a automaticky vytváří spravované prostředky v síti. Privátní koncové body můžete použít k tomu, aby služby Azure mohly přistupovat k síti, a volitelně můžete definovat pravidla odchozích přenosů, která síti umožní přístup k internetu.
Spravovaná virtuální síť má dva režimy, pro které je možné nakonfigurovat:
Povolit odchozí provoz internetu – tento režim umožňuje odchozí komunikaci s prostředky umístěnými na internetu, jako jsou veřejná úložiště balíčků PyPi nebo Anaconda.

Povolit pouze schválenou odchozí komunikaci – tento režim umožňuje fungování pouze minimální odchozí komunikace vyžadovaná pro fungování pracovního prostoru. Tento režim se doporučuje pro pracovní prostory, které musí být izolované od internetu. Nebo pokud je odchozí přístup povolený jenom ke konkrétním prostředkům prostřednictvím koncových bodů služby, značek služeb nebo plně kvalifikovaných názvů domén.

Další informace najdete v tématu Izolace spravované virtuální sítě.
Doporučená architektura zabezpečení sítě (Azure Virtual Network)
Pokud nemůžete použít spravovanou virtuální síť z důvodu vašich obchodních požadavků, můžete použít virtuální síť Azure s následujícími podsítěmi:
- Trénování obsahuje výpočetní prostředky používané k trénování, jako jsou výpočetní instance strojového učení nebo výpočetní clustery.
- Bodování obsahuje výpočetní prostředky používané k bodování, jako je Azure Kubernetes Service (AKS).
- Brána firewall obsahuje bránu firewall, která umožňuje provoz do a z veřejného internetu, jako je azure Firewall.
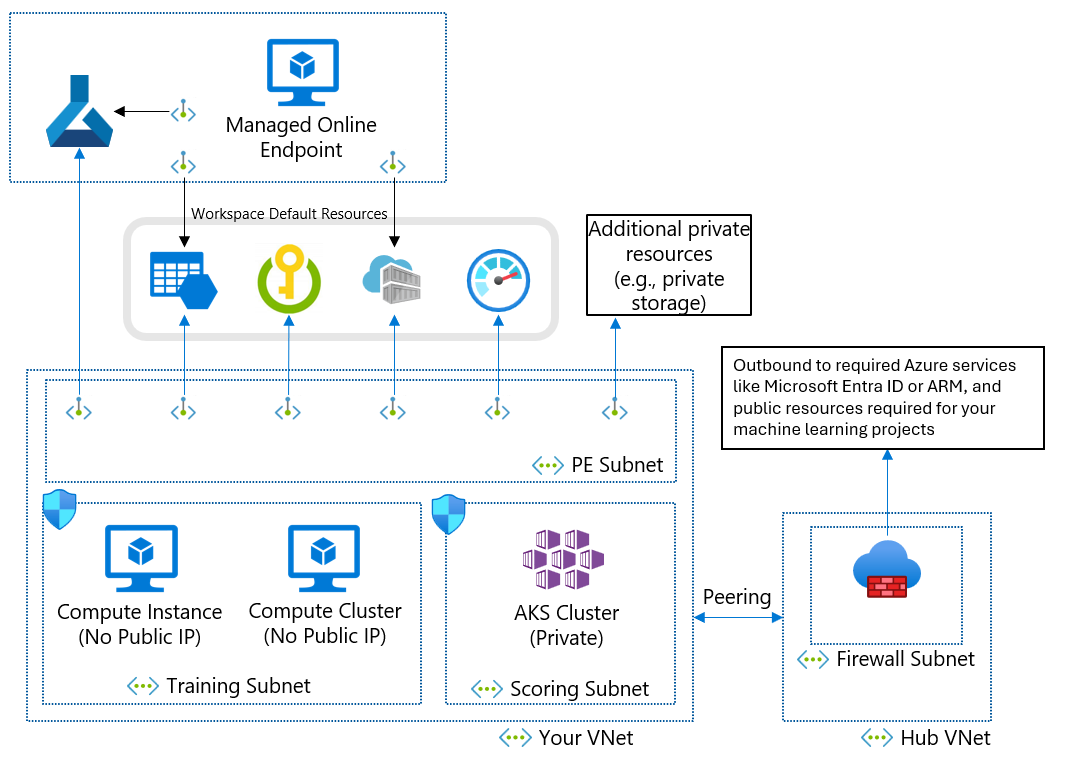
Virtuální síť obsahuje také privátní koncový bod pro váš pracovní prostor strojového učení a následující závislé služby:
- Účet služby Azure Storage
- Azure Key Vault
- Azure Container Registry
Odchozí komunikace z virtuální sítě musí být schopná kontaktovat následující služby Microsoft:
- Strojové učení
- Microsoft Entra ID
- Azure Container Registry a konkrétní registry, které microsoft udržuje
- Azure Front Door
- Azure Resource Manager
- Azure Storage
Vzdálení klienti se připojují k virtuální síti pomocí Azure ExpressRoute nebo připojení k virtuální privátní síti (VPN).
Návrh virtuální sítě a privátního koncového bodu
Při navrhování virtuální sítě, podsítí a privátních koncových bodů Azure zvažte následující požadavky:
Obecně vytvořte samostatné podsítě pro trénování a bodování a pro všechny privátní koncové body použijte trénovací podsíť.
Pro přidělování IP adres potřebují výpočetní instance jednu privátní IP adresu. Výpočetní clustery potřebují jednu privátní IP adresu na uzel. Clustery AKS potřebují mnoho privátních IP adres, jak je popsáno v tématu Plánování přidělování IP adres clusteru AKS. Samostatná podsíť alespoň pro AKS pomáhá zabránit vyčerpání IP adres.
Výpočetní prostředky v podsítích trénování a bodování musí přistupovat k účtu úložiště, trezoru klíčů a registru kontejneru. Vytvořte privátní koncové body pro účet úložiště, trezor klíčů a registr kontejneru.
Výchozí úložiště pracovního prostoru Machine Learning potřebuje dva privátní koncové body, jeden pro Azure Blob Storage a druhý pro Azure File Storage.
Pokud používáte studio Azure Machine Learning, měly by být privátní koncové body pracovního prostoru a úložiště ve stejné virtuální síti.
Pokud máte více pracovních prostorů, vytvořte explicitní hranici sítě mezi pracovními prostory pomocí virtuální sítě pro každý pracovní prostor.
Použití privátních IP adres
Privátní IP adresy minimalizují vystavení prostředků Azure internetu. Machine Learning používá mnoho prostředků Azure a privátní koncový bod pracovního prostoru strojového učení nestačí pro koncovou privátní IP adresu. Následující tabulka ukazuje hlavní prostředky, které strojové učení používá a jak povolit privátní IP adresu pro prostředky. Výpočetní instance a výpočetní clustery jsou jediné prostředky, které nemají funkci privátní IP adresy.
| Zdroje informací | Řešení privátníCH IP adres | Dokumentace |
|---|---|---|
| Pracovní prostor | Privátní koncový bod | Konfigurace privátního koncového bodu pro pracovní prostor služby Azure Machine Learning |
| Registr | Privátní koncový bod | Izolace sítě s využitím registrů služby Azure Machine Učení |
| Přidružené prostředky | ||
| Úložiště | Privátní koncový bod | Zabezpečení účtů Azure Storage pomocí koncových bodů služby |
| Key Vault | Privátní koncový bod | Zabezpečení služby Azure Key Vault |
| Container Registry | Privátní koncový bod | Povolení služby Azure Container Registry |
| Školící materiály | ||
| Výpočetní instance | Privátní IP adresa (bez veřejné IP adresy) | Zabezpečená trénovací prostředí |
| Výpočtový cluster | Privátní IP adresa (bez veřejné IP adresy) | Zabezpečená trénovací prostředí |
| Hostování prostředků | ||
| Spravovaný online koncový bod | Privátní koncový bod | Izolace sítě se spravovanými online koncovými body |
| Online koncový bod (Kubernetes) | Privátní koncový bod | Zabezpečení online koncových bodů služby Azure Kubernetes Service |
| Koncové body služby Batch | Privátní IP adresa (zděděná z výpočetního clusteru) | Izolace sítě v dávkových koncových bodech |
Řízení příchozího a odchozího provozu virtuální sítě
K řízení příchozího a odchozího provozu virtuální sítě použijte bránu firewall nebo skupinu zabezpečení sítě Azure (NSG). Další informace o požadavcích na příchozí a odchozí provoz najdete v tématu Konfigurace příchozího a odchozího síťového provozu. Další informace o tocích provozu mezi komponentami najdete v tématu Tok síťového provozu v zabezpečeném pracovním prostoru.
Zajištění přístupu k pracovnímu prostoru
Pokud chcete zajistit, aby váš privátní koncový bod mohl přistupovat k pracovnímu prostoru strojového učení, postupujte následovně:
Ujistěte se, že máte přístup k virtuální síti pomocí připojení VPN, ExpressRoute nebo přeskakování virtuálního počítače s přístupem ke službě Azure Bastion. Veřejný uživatel nemá přístup k pracovnímu prostoru strojového učení pomocí privátního koncového bodu, protože k němu bude možné přistupovat pouze z vaší virtuální sítě. Další informace najdete v tématu Zabezpečení pracovního prostoru s virtuálními sítěmi.
Ujistěte se, že můžete přeložit plně kvalifikované názvy domén pracovního prostoru s vaší privátní IP adresou. Pokud používáte vlastní server DNS (Domain Name System) nebo centralizovanou infrastrukturu DNS, musíte nakonfigurovat službu předávání DNS. Další informace najdete v tématu Používání pracovního prostoru s vlastním serverem DNS.
Správa přístupu k pracovnímu prostoru
Při definování řízení identit a přístupu ve službě Machine Learning můžete oddělit ovládací prvky, které definují přístup k prostředkům Azure, od ovládacích prvků, které spravují přístup k datovým prostředkům. V závislosti na vašem případu použití zvažte, jestli použít samoobslužnou správu, správu identit a přístupu zaměřenou na data nebo správu přístupu zaměřenou na projekt.
Model samoobslužných služeb
V modelu samoobslužných služeb můžou datoví vědci vytvářet a spravovat pracovní prostory. Tento model je nejvhodnější pro situace testování konceptu, které vyžadují flexibilitu při vyzkoušení různých konfigurací. Nevýhodou je, že datoví vědci potřebují odborné znalosti ke zřízení prostředků Azure. Tento přístup je méně vhodný v případě, že se vyžaduje striktní kontrola, použití prostředků, trasování auditu a přístup k datům.
Definujte zásady Azure pro nastavení zabezpečení pro zřizování a používání prostředků, jako jsou povolené velikosti clusterů a typy virtuálních počítačů.
Vytvořte skupinu prostředků pro uchovávání pracovních prostorů a udělte datovým vědcům roli Přispěvatel ve skupině prostředků.
Datoví vědci teď můžou vytvářet pracovní prostory a přidružit prostředky ve skupině prostředků samoobslužným způsobem.
Pokud chcete získat přístup k úložišti dat, vytvořte spravované identity přiřazené uživatelem a udělte identitám role přístupu pro čtení v úložišti.
Když datoví vědci vytvářejí výpočetní prostředky, můžou spravované identity přiřadit výpočetním instancím, aby získali přístup k datům.
Osvědčené postupy najdete v tématu Ověřování pro analýzy v cloudovém měřítku.
Model orientovaný na data
V modelu zaměřeném na data patří pracovní prostor jednomu datovému vědci, který může pracovat na více projektech. Výhodou tohoto přístupu je, že datový vědec může opakovaně používat kanály kódu nebo trénování napříč projekty. Pokud je pracovní prostor omezen na jednoho uživatele, je možné při auditování protokolů úložiště trasovat přístup k datům zpět ho.
Nevýhodou je, že přístup k datům není rozdělený nebo omezený na jednotlivé projekty a každý uživatel přidaný do pracovního prostoru má přístup ke stejným prostředkům.
Vytvořte pracovní prostor.
Vytváření výpočetních prostředků s povolenými spravovanými identitami přiřazenými systémem
Když datový vědec potřebuje přístup k datům pro daný projekt, udělte výpočetní spravované identitě přístup ke čtení dat.
Udělte výpočetní spravované identitě přístup k dalším požadovaným prostředkům, jako je registr kontejneru s vlastními imagemi Dockeru pro trénování.
Také udělte spravované identitě pracovního prostoru roli pro čtení a přístup k datům, aby bylo možné povolit náhled dat.
Udělte datovému vědci přístup k pracovnímu prostoru.
Datový vědec teď může vytvářet úložiště dat pro přístup k datům potřebným pro projekty a odesílat trénovací běhy, které data používají.
Volitelně můžete vytvořit skupinu zabezpečení Microsoft Entra a udělit jí přístup pro čtení k datům a pak do skupiny zabezpečení přidat spravované identity. Tento přístup snižuje počet přímých přiřazení rolí u prostředků, aby nedošlo k dosažení limitu předplatného u přiřazení rolí.
Model orientovaný na projekt
Vzor zaměřený na projekt vytvoří pracovní prostor strojového učení pro konkrétní projekt a mnoho datových vědců spolupracuje ve stejném pracovním prostoru. Přístup k datům je omezený na konkrétní projekt a je vhodný pro práci s citlivými daty. Je také jednoduché přidat nebo odebrat datové vědce z projektu.
Nevýhodou tohoto přístupu je, že sdílení prostředků napříč projekty může být obtížné. Během auditů je také obtížné trasovat přístup k datům konkrétním uživatelům.
Vytvořte pracovní prostor.
Identifikujte instance úložiště dat vyžadované pro projekt, vytvořte spravovanou identitu přiřazenou uživatelem a udělte identitě přístup ke čtení úložiště.
Volitelně udělte spravované identitě pracovního prostoru přístup k úložišti dat, aby bylo možné povolit náhled dat. Tento přístup můžete vynechat pro citlivá data, která nejsou vhodná pro verzi Preview.
Vytvořte úložiště dat bez přihlašovacích údajů pro prostředky úložiště.
Vytvořte výpočetní prostředky v rámci pracovního prostoru a přiřaďte spravovanou identitu k výpočetním prostředkům.
Udělte výpočetní spravované identitě přístup k dalším požadovaným prostředkům, jako je registr kontejneru s vlastními imagemi Dockeru pro trénování.
Udělte datovým vědcům, kteří pracují na projektu, roli v pracovním prostoru.
Pomocí řízení přístupu na základě role v Azure (RBAC) můžete datovým vědcům omezit vytváření nových úložišť dat nebo nových výpočetních prostředků s různými spravovanými identitami. Tento postup brání přístupu k datům, která nejsou specifická pro daný projekt.
Pokud chcete zjednodušit správu členství v projektu, můžete vytvořit skupinu zabezpečení Microsoft Entra pro členy projektu a udělit skupině přístup k pracovnímu prostoru.
Azure Data Lake Storage s předáváním přihlašovacích údajů
Identitu uživatele Microsoft Entra můžete použít k interaktivnímu přístupu k úložišti z nástroje Machine Learning Studio. Data Lake Storage s povoleným hierarchickým oborem názvů umožňuje vylepšenou organizaci datových prostředků pro ukládání a spolupráci. Díky hierarchickému oboru názvů Data Lake Storage můžete přístup k datům uspořádat tak, že různým uživatelům udělíte přístup na seznam řízení přístupu (ACL) na základě různých složek a souborů. Můžete například udělit jenom podmnožinu uživatelů přístup k důvěrným datům.
RBAC a vlastní role
Azure RBAC pomáhá spravovat, kdo má přístup k prostředkům strojového učení, a nakonfigurovat, kdo může provádět operace. Můžete například chtít udělit jenom konkrétním uživatelům roli správce pracovního prostoru pro správu výpočetních prostředků.
Obor přístupu se může mezi prostředími lišit. V produkčním prostředí můžete chtít omezit možnost uživatelů aktualizovat koncové body odvozování. Místo toho můžete toto oprávnění udělit autorizovanému instančnímu objektu.
Strojové učení má několik výchozích rolí: vlastníka, přispěvatele, čtenáře a datového vědce. Můžete také vytvořit vlastní role, například vytvořit oprávnění, která odpovídají organizační struktuře. Další informace najdete v tématu Správa přístupu k pracovnímu prostoru Azure Machine Učení.
Složení týmu se v průběhu času může změnit. Pokud vytvoříte skupinu Microsoft Entra pro každou roli a pracovní prostor týmu, můžete přiřadit roli Azure RBAC skupině Microsoft Entra a spravovat přístup k prostředkům a skupiny uživatelů samostatně.
Instanční objekty a instanční objekty mohou být součástí stejné skupiny Microsoft Entra. Když například vytvoříte spravovanou identitu přiřazenou uživatelem, kterou azure Data Factory používá k aktivaci kanálu strojového učení, můžete zahrnout spravovanou identitu do skupiny exekutoru kanálů ML Microsoft Entra.
Centrální správa imagí Dockeru
Azure Machine Učení poskytuje kurátorované image Dockeru, které můžete použít k trénování a nasazení. Vaše podnikové požadavky na dodržování předpisů ale můžou vyžadovat používání imagí z privátního úložiště, které spravuje vaše společnost. Strojové učení má dva způsoby použití centrálního úložiště:
Jako základní image použijte image z centrálního úložiště. Správa prostředí strojového učení nainstaluje balíčky a vytvoří prostředí Pythonu, ve kterém běží trénování nebo odvozování kódu. Díky tomuto přístupu můžete snadno aktualizovat závislosti balíčků beze změny základní image.
Používejte image tak, jak je, bez použití správy prostředí strojového učení. Tento přístup poskytuje vyšší stupeň kontroly, ale také vyžaduje, abyste prostředí Pythonu pečlivě vytvořili jako součást image. Ke spuštění kódu je potřeba splnit všechny potřebné závislosti a všechny nové závislosti vyžadují opětovné sestavení image.
Další informace najdete v tématu Správa prostředí.
Šifrování dat
Neaktivní uložená data strojového učení mají dva zdroje dat:
Úložiště obsahuje všechna vaše data, včetně trénovacích a trénovaných dat modelu s výjimkou metadat. Zodpovídáte za šifrování úložiště.
Azure Cosmos DB obsahuje vaše metadata, včetně informací historie spuštění, jako je název experimentu a datum a čas odeslání experimentu. Ve většině pracovních prostorů je služba Azure Cosmos DB v předplatném Microsoftu a šifrována klíčem spravovaným Microsoftem.
Pokud chcete metadata šifrovat pomocí vlastního klíče, můžete použít pracovní prostor klíčů spravovaný zákazníkem. Nevýhodou je, že ve svém předplatném potřebujete mít Službu Azure Cosmos DB a platit její náklady. Další informace najdete v tématu Šifrování dat pomocí služby Azure Machine Učení.
Informace o tom, jak Azure Machine Učení šifruje přenášená data, najdete v tématu Šifrování během přenosu.
Sledování
Při nasazování prostředků strojového učení nastavte řízení protokolování a auditování pro pozorovatelnost. Motivace pro pozorování dat se může lišit v závislosti na tom, kdo data sleduje. Mezi scénáře patří:
Odborníci na strojové učení nebo provozní týmy chtějí monitorovat stav kanálu strojového učení. Tito pozorovatelé potřebují porozumět problémům s plánovaným spuštěním nebo problémy s kvalitou dat nebo očekávaným výkonem trénování. Můžete vytvářet řídicí panely Azure, které monitorují data služby Azure Machine Učení, nebo vytvářet pracovní postupy řízené událostmi.
Správci kapacity, odborníci na strojové učení nebo provozní týmy můžou chtít vytvořit řídicí panel pro sledování využití výpočetních prostředků a kvót. Pokud chcete spravovat nasazení s více pracovními prostory Azure Machine Učení, zvažte vytvoření centrálního řídicího panelu, abyste porozuměli využití kvót. Kvóty se spravují na úrovni předplatného, takže zobrazení na úrovni celého prostředí je důležité k optimalizaci.
IT a provozní týmy můžou nastavit protokolování diagnostiky pro audit přístupu k prostředkům a změnu událostí v pracovním prostoru.
Zvažte vytvoření řídicích panelů, které monitorují celkový stav infrastruktury pro strojové učení a závislé prostředky, jako je úložiště. Například kombinování metrik Azure Storage s daty spouštění kanálu vám může pomoct optimalizovat infrastrukturu pro lepší výkon nebo zjistit původní příčiny problému.
Azure shromažďuje a ukládá metriky platformy a protokoly aktivit automaticky. Data můžete směrovat do jiných umístění pomocí nastavení diagnostiky. Nastavte protokolování diagnostiky do centralizovaného pracovního prostoru služby Log Analytics pro pozorovatelnost napříč několika instancemi pracovního prostoru. Pomocí služby Azure Policy můžete automaticky nastavit protokolování pro nové pracovní prostory strojového učení do tohoto centrálního pracovního prostoru služby Log Analytics.
Azure Policy
Používání funkcí zabezpečení v pracovních prostorech můžete vynutit a auditovat prostřednictvím služby Azure Policy. Mezi další doporučení patří:
- Vynucujte šifrování klíčů spravovaných vlastními daty.
- Vynucujte Privátní propojení Azure a privátní koncové body.
- Vynucujte privátní zóny DNS.
- Zakažte ověřování mimo Azure AD, jako je Secure Shell (SSH).
Další informace najdete v tématu Předdefinované definice zásad pro službu Azure Machine Učení.
K flexibilnímu řízení zabezpečení pracovního prostoru můžete také použít vlastní definice zásad.
Výpočetní clustery a instance
Následující aspekty a doporučení platí pro výpočetní clustery a instance strojového učení.
Šifrování disku
Disk operačního systému pro výpočetní instanci nebo uzel výpočetního clusteru je uložený ve službě Azure Storage a šifrovaný pomocí klíčů spravovaných Microsoftem. Každý uzel má také místní dočasný disk. Dočasný disk je také šifrovaný pomocí klíčů spravovaných Microsoftem, pokud byl pracovní prostor vytvořen pomocí parametru hbi_workspace = True . Další informace najdete v tématu Šifrování dat pomocí služby Azure Machine Učení.
Spravovaná identita
Výpočetní clustery podporují ověřování prostředků Azure pomocí spravovaných identit. Použití spravované identity pro cluster umožňuje ověřování prostředků bez vystavení přihlašovacích údajů v kódu. Další informace najdete v tématu Vytvoření výpočetního clusteru Azure Machine Učení.
Instalační skript
Pomocí instalačního skriptu můžete automatizovat přizpůsobení a konfiguraci výpočetních instancí při vytváření. Jako správce můžete napsat skript pro přizpůsobení, který se použije při vytváření všech výpočetních instancí v pracovním prostoru. Azure Policy můžete použít k vynucení použití instalačního skriptu k vytvoření každé výpočetní instance. Další informace najdete v tématu Vytvoření a správa výpočetní instance služby Azure Machine Učení.
Vytvořit jménem uživatele
Pokud nechcete, aby datoví vědci zřídili výpočetní prostředky, můžete za ně vytvářet výpočetní instance a přiřazovat je datovým vědcům. Další informace najdete v tématu Vytvoření a správa výpočetní instance služby Azure Machine Učení.
Pracovní prostor s podporou privátního koncového bodu
Použijte výpočetní instance s pracovním prostorem s povoleným privátním koncovým bodem. Výpočetní instance odmítne veškerý veřejný přístup mimo virtuální síť. Tato konfigurace také zabraňuje filtrování paketů.
Podpora služby Azure Policy
Pokud používáte virtuální síť Azure, můžete pomocí služby Azure Policy zajistit, aby se ve virtuální síti vytvořil každý výpočetní cluster nebo instance a zadali výchozí virtuální síť a podsíť. Zásady nejsou potřeba při použití spravované virtuální sítě, protože výpočetní prostředky se automaticky vytvářejí ve spravované virtuální síti.
Zásady můžete použít také k zakázání ověřování mimo Azure AD, jako je SSH.
Další kroky
Další informace o konfiguracích zabezpečení strojového učení:
- Podnikové zabezpečení a zásady správného řízení
- Zabezpečení prostředků pracovního prostoru pomocí virtuálních sítí
Začínáme s nasazením založeným na šablonách strojového učení:
Přečtěte si další články o aspektech architektury při nasazování strojového učení:
Přečtěte si, jak týmová struktura, prostředí nebo regionální omezení ovlivňují nastavení pracovního prostoru.
Zjistěte, jak spravovat náklady na výpočetní prostředky a rozpočet napříč týmy a uživateli.
Seznamte se s DevOps (MLOps) strojového učení, který využívá kombinaci lidí, procesů a technologií k poskytování robustních, spolehlivých a automatizovaných řešení strojového učení.
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro