Operace strojového učení
Operace strojového učení (označované také jako MLOps) jsou použití principů DevOps pro aplikace s využitím AI. Aby bylo možné implementovat operace strojového učení v organizaci, musí být zavedeny konkrétní dovednosti, procesy a technologie. Cílem je poskytovat řešení strojového učení, která jsou robustní, škálovatelná, spolehlivá a automatizovaná.
V tomto článku se dozvíte, jak naplánovat prostředky na podporu operací strojového učení na úrovni organizace. Projděte si osvědčené postupy a doporučení založená na používání služby Azure Machine Learning k přijetí operací strojového učení v podniku.
Co jsou operace strojového učení?
Moderní algoritmy a architektury strojového učení usnadňují vývoj modelů, které umožňují přesné předpovědi. Operace strojového učení jsou strukturovaným způsobem, jak začlenit strojové učení do vývoje aplikací v podniku.
V ukázkovém scénáři jste vytvořili model strojového učení, který překračuje všechna vaše očekávání přesnosti a zapůsobí na vaše firemní sponzory. Teď je čas model nasadit do produkčního prostředí, ale to nemusí být tak snadné, jak jste očekávali. Organizace bude pravděpodobně muset mít lidi, procesy a technologie, než bude moct používat model strojového učení v produkčním prostředí.
V průběhu času můžete vy nebo kolega vyvíjet nový model, který funguje lépe než původní model. Nahrazení modelu strojového učení, který se používá v produkčním prostředí, představuje určité obavy, které jsou pro organizaci důležité:
- Nový model budete chtít implementovat bez narušení obchodních operací, které spoléhají na nasazený model.
- Pro zákonné účely může být nutné vysvětlit předpovědi modelu nebo model znovu vytvořit, pokud jsou neobvyklé nebo zkreslené předpovědi výsledkem dat v novém modelu.
- Data, která používáte v trénování a modelu strojového učení, se můžou v průběhu času měnit. Při změnách dat možná budete muset model pravidelně přetrénovat, aby se zachovala přesnost predikce. Osoba nebo role bude muset mít přiřazenou odpovědnost za podávání dat, monitorovat výkon modelu, přetrénovat model a opravit ho, pokud selže.
Předpokládejme, že máte aplikaci, která obsluhuje předpovědi modelu prostřednictvím rozhraní REST API. Dokonce i jednoduchý případ použití, jako je tento, může způsobit problémy v produkčním prostředí. Implementace strategie operací strojového učení vám může pomoct řešit problémy s nasazením a podporovat obchodní operace, které spoléhají na aplikace infuzní z umělé inteligence.
Některé úlohy operací strojového učení se dobře hodí do obecné architektury DevOps. Mezi příklady patří nastavení testů jednotek a integračních testů a sledování změn pomocí správy verzí. Další úlohy jsou pro operace strojového učení jedinečnější a můžou zahrnovat:
- Povolte nepřetržité experimentování a porovnání s modelem podle směrného plánu.
- Monitorujte příchozí data a detekujte posun dat.
- Aktivace opětovného trénování modelu a nastavení vrácení zpět pro zotavení po havárii
- Vytvořte opakovaně použitelné datové kanály pro trénování a vyhodnocování.
Cílem operací strojového učení je uzavřít mezeru mezi vývojem a výrobou a rychleji poskytovat zákazníkům hodnotu. Abyste tohoto cíle dosáhli, musíte znovu promyslet tradiční procesy vývoje a výroby.
Ne všechny požadavky organizace na provoz strojového učení jsou stejné. Architektura operací strojového učení velkého nadnárodního podniku pravděpodobně nebude stejnou infrastrukturou, jakou vytváří malý startup. Organizace obvykle začínají malé a vytvářejí se s rostoucí vyspělostí, katalogem modelů a zkušenostmi.
Model vyspělosti operací strojového učení vám pomůže zjistit, kde je vaše organizace ve škále vyspělosti operací strojového učení, a pomůže vám naplánovat budoucí růst.
Operace strojového učení vs. DevOps
Operace strojového učení se liší od DevOps v několika klíčových oblastech. Operace strojového učení mají tyto charakteristiky:
- Průzkum předchází vývoji a provozu.
- Životní cyklus datových věd vyžaduje adaptivní způsob práce.
- Omezení kvality dat a průběhu limitu dostupnosti
- Vyžaduje se větší provozní úsilí než v DevOps.
- Pracovní týmy vyžadují odborníky a odborníky na doménu.
Souhrn najdete v sedmi principech operací strojového učení.
Průzkum předchází vývoji a provozu.
Projekty datových věd se liší od vývoje aplikací nebo projektů přípravy dat. Projekt datových věd může postupovat do produkčního prostředí, ale často je součástí tradičního nasazení více kroků. Po počáteční analýze může být jasné, že obchodní výsledek nelze dosáhnout s dostupnými datovými sadami. Podrobnější fáze průzkumu je obvykle prvním krokem v projektu datových věd.
Cílem fáze průzkumu je definovat a upřesnit problém. Během této fáze spouštějí datoví vědci průzkumnou analýzu dat. K potvrzení nebo falšování problému používají statistiky a vizualizace. Účastníci by měli vědět, že projekt nemusí překročit tuto fázi. Zároveň je důležité, aby byla tato fáze co nejrušnější pro rychlý přechod. Pokud problém, který se má vyřešit, neobsahuje prvek zabezpečení, vyhněte se omezení průzkumné fáze procesy a postupy. Datoví vědci by měli mít možnost pracovat s nástroji a daty, které preferují. Pro tuto průzkumnou práci jsou potřebná skutečná data.
Projekt se může přesunout do fází experimentování a vývoje, pokud jsou účastníci přesvědčeni, že projekt datových věd je proveditelný a může poskytnout skutečnou obchodní hodnotu. V této fázi jsou vývojové postupy stále důležitější. Je vhodné zaznamenávat metriky pro všechny experimenty, které se v této fázi provádějí. Je také důležité začlenit správu zdrojového kódu, abyste mohli porovnat modely a přepínat mezi různými verzemi kódu.
Mezi vývojové aktivity patří refaktoring, testování a automatizace kódu zkoumání v opakovatelných experimentačních kanálech. Aby organizace sloužila modelům, musí vytvářet aplikace a kanály. Refaktoring kódu v modulárních komponentách a knihovnách pomáhá zvýšit použitelnost, testování a optimalizaci výkonu.
Nakonec se kanály aplikace nebo dávkového odvozování, které obsluhují modely, nasadí do přípravného nebo produkčního prostředí. Kromě monitorování spolehlivosti a výkonu infrastruktury, jako je u standardní aplikace, musíte v nasazení modelu strojového učení průběžně monitorovat kvalitu dat, profil dat a model pro snížení nebo posun. Modely strojového učení také vyžadují opětovné vytrénování v průběhu času, aby zůstaly relevantní v měnícím se prostředí.
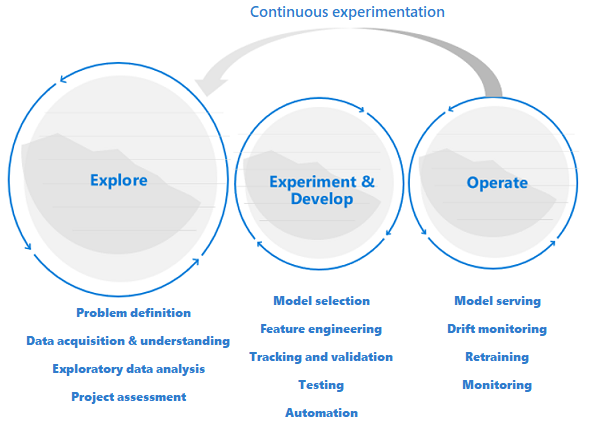
Životní cyklus datových věd vyžaduje adaptivní způsob práce.
Vzhledem k tomu, že povaha a kvalita dat je zpočátku nejistá, možná nedosáhnete svých obchodních cílů, pokud použijete typický proces DevOps na projekt datových věd. Zkoumání a experimentování jsou opakující se aktivity a potřeby v průběhu procesu strojového učení. Týmy v Microsoftu používají životní cyklus projektu a pracovní proces, který odráží povahu aktivit specifických pro datové vědy. Příkladem referenčních implementací jsou týmový Datová Věda proces a proces životního cyklu Datová Věda.
Omezení průběhu kvality dat a limitu dostupnosti
Aby tým strojového učení efektivně vyvinul aplikace s infuzí strojového učení, upřednostňuje se přístup k produkčním datům pro všechna relevantní pracovní prostředí. Pokud přístup k produkčním datům není možný kvůli požadavkům na dodržování předpisů nebo technickým omezením, zvažte implementaci řízení přístupu na základě role v Azure (Azure RBAC) pomocí služby Azure Machine Learning, přístupu za běhu nebo kanálů pro přesun dat za účelem vytvoření produkčních replik dat a zvýšení produktivity uživatelů.
Strojové učení vyžaduje větší provozní úsilí.
Na rozdíl od tradičního softwaru je výkon řešení strojového učení neustále ohrožen, protože řešení závisí na kvalitě dat. Aby se zachovalo kvalitativní řešení v produkčním prostředí, je důležité průběžně monitorovat a znovu vyhodnotit kvalitu dat i modelu. Očekává se, že produkční model vyžaduje včasné opětovné trénování, opětovné nasazení a ladění. Tyto úkoly jsou nad každodenními požadavky na zabezpečení, monitorování infrastruktury a dodržování předpisů a vyžadují specializované odborné znalosti.
Týmy strojového učení vyžadují specialisty a odborníky na doménu.
I když projekty datových věd sdílejí role s běžnými IT projekty, úspěch úsilí strojového učení velmi závisí na tom, že základní specialisté na strojové učení a odborníci na danou problematiku domény. Technický specialista má správné zkušenosti s kompletním experimentováním strojového učení. Odborník na doménu může odborníka podporovat analýzou a syntetizací dat nebo opravňujícími daty pro použití.
Mezi běžné technické role, které jsou jedinečné pro projekty datových věd, patří odborník na domény, datový inženýr, datový vědec, inženýr umělé inteligence, validátor modelů a technik strojového učení. Další informace o rolích Datová Věda ach
Sedm principů operací strojového učení
Při plánování přechodu na operace strojového učení ve vaší organizaci zvažte použití následujících základních principů jako základu:
Pro výstupy kódu, dat a experimentování použijte správu verzí. Na rozdíl od tradičního vývoje softwaru mají data přímý vliv na kvalitu modelů strojového učení. Měli byste vytvořit verzi základu kódu experimentování, ale také verzi datových sad, abyste zajistili, že můžete reprodukovat experimenty nebo odvozovat výsledky. Výstupy experimentování verzí, jako jsou modely, můžou ušetřit úsilí a výpočetní náklady na jejich opětovné vytvoření.
Použijte více prostředí. Pokud chcete oddělit vývoj a testování od produkční práce, replikujte infrastrukturu alespoň ve dvou prostředích. Řízení přístupu pro uživatele může být pro každé prostředí odlišné.
Spravujte infrastrukturu a konfigurace jako kód. Při vytváření a aktualizaci komponent infrastruktury v pracovních prostředích používejte infrastrukturu jako kód, takže nekonzistence se ve vašich prostředích nevyvíjí. Spravujte specifikace úloh experimentu strojového učení jako kód, abyste mohli snadno znovu spustit a znovu použít verzi experimentu v několika prostředích.
Sledování a správa experimentů strojového učení Sledujte klíčové ukazatele výkonu a další artefakty pro experimenty strojového učení. Když udržujete historii výkonu práce, můžete provádět kvantitativní analýzu úspěchu experimentování a zlepšit týmovou spolupráci a flexibilitu.
Otestujte kód, ověřte integritu dat a zajistěte kvalitu modelu. Otestujte základ kódu experimentování pro správnou přípravu dat a funkce extrakce funkcí, integritu dat a výkon modelu.
Kontinuální integrace a doručování strojového učení Využijte kontinuální integraci (CI) k automatizaci testování pro váš tým. Zahrňte trénování modelu jako součást kanálů průběžného trénování. Jako součást verze zahrňte testování A/B, abyste zajistili, že se v produkčním prostředí použije jenom kvalitativní model.
Monitorování služeb, modelů a dat Když obsluhujete modely v provozním prostředí strojového učení, je důležité monitorovat služby pro dostupnost infrastruktury, dodržování předpisů a kvalitu modelu. Nastavte monitorování pro identifikaci odchylek dat a modelů a zjistěte, jestli se vyžaduje opětovné trénování. Zvažte nastavení triggerů pro automatické přetrénování.
Osvědčené postupy ze služby Azure Machine Learning
Azure Machine Learning nabízí služby správy, orchestrace a automatizace prostředků, které vám pomůžou spravovat životní cyklus trénování a nasazení modelu strojového učení. Projděte si osvědčené postupy a doporučení pro použití operací strojového učení v oblastech prostředků lidí, procesů a technologií, které azure Machine Learning podporuje.
Lidé
Pracujte v projektových týmech, abyste v organizaci mohli nejlépe využívat odborné znalosti a znalosti domény. Nastavte pracovní prostory Služby Azure Machine Learning pro každý projekt tak, aby vyhovovaly požadavkům na oddělení případů použití.
Definujte sadu zodpovědností a úkolů jako roli, aby každý člen týmu v provozním týmu strojového učení mohl být přiřazen a plnit více rolí. Pomocí vlastních rolí v Azure definujte sadu podrobných operací Azure RBAC pro Azure Machine Learning , které můžou jednotlivé role provádět.
Standardizujte životní cyklus projektu a agilní metodologii. Team Datová Věda Process poskytuje referenční implementaci životního cyklu.
Vyvážené týmy můžou spouštět všechny fáze operací strojového učení, včetně zkoumání, vývoje a provozu.
Zpracovat
Standardizujte šablonu kódu pro opakované použití kódu a urychlíte dobu zrychlování v novém projektu nebo když se k projektu připojí nový člen týmu. Jako základ pro nové šablony používejte kanály Azure Machine Learning, skripty pro odesílání úloh a kanály CI/CD.
Použijte správu verzí. Úlohy odeslané ze složky založené na Gitu automaticky sledují metadata úložiště s úlohou ve službě Azure Machine Learning kvůli reprodukovatelnosti.
Použití správy verzí pro vstupy experimentu a výstupy pro reprodukovatelnost. Využijte datové sady Azure Machine Learning, správu modelů a možnosti správy prostředí k usnadnění správy verzí.
Vytvořte historii spuštění experimentů pro porovnání, plánování a spolupráci. Ke shromažďování metrik použijte rozhraní pro sledování experimentů, jako je MLflow .
Nepřetržitě změřujte a kontrolujte kvalitu práce vašeho týmu prostřednictvím CI na úplném základu kódu experimentování.
Ukončete trénování v rané fázi procesu, když se model nekonverguje. K monitorování spuštění úloh použijte architekturu pro sledování experimentů a historii spuštění ve službě Azure Machine Learning.
Definujte strategii experimentu a správy modelů. Zvažte použití názvu, jako je šampión , abyste se mohli podívat na aktuální základní model. Model challengeru je kandidátský model, který by mohl zprovoznět model šampiona v produkčním prostředí. Značky ve službě Azure Machine Learning můžete použít k označení experimentů a modelů. Ve scénáři, jako je prognózování prodeje, může trvat měsíce, než určíte, jestli jsou předpovědi modelu přesné.
Zvýšení úrovně CI pro průběžné trénování zahrnutím trénování modelu v buildu Začněte například trénování modelu pro úplnou datovou sadu s každou žádostí o přijetí změn.
Zkraťte dobu potřebnou k získání zpětné vazby k kvalitě kanálu strojového učení spuštěním automatizovaného sestavení ukázky dat. K parametrizaci vstupních datových sad použijte parametry kanálu Azure Machine Learning.
Využijte průběžné nasazování (CD) pro modely strojového učení k automatizaci nasazení a testování služeb bodování v reálném čase ve vašich prostředích Azure.
V některých regulovaných odvětvích možná budete muset dokončit kroky ověření modelu, než budete moct použít model strojového učení v produkčním prostředí. Automatizace ověřovacích kroků může urychlit doručení. Pokud jsou kroky ruční kontroly nebo ověření stále kritickým bodem, zvažte, jestli můžete certifikovat kanál automatizovaného ověření modelu. Značky prostředků ve službě Azure Machine Learning slouží k označení dodržování předpisů prostředků a kandidátů pro kontrolu nebo jako triggery pro nasazení.
Nepřetrénujte v produkčním prostředí a pak přímo nahraďte produkční model bez testování integrace. I když se výkon modelu a funkční požadavky můžou zdát dobré, mimo jiné potenciální problémy, může mít přetrénovaný model větší nároky na prostředí a přerušit serverové prostředí.
Pokud je přístup k produkčním datům k dispozici pouze v produkčním prostředí, použijte Azure RBAC a vlastní role k poskytnutí vybraného počtu odborníků na strojové učení přístup pro čtení. Některé role můžou potřebovat číst data pro zkoumání souvisejících dat. Případně můžete vytvořit kopii dat dostupnou v neprodukčních prostředích.
Odsouhlaste zásady vytváření názvů a značky pro experimenty Azure Machine Learning, abyste odlišili standardní kanály strojového učení od experimentální práce.
Technologie
Pokud aktuálně odesíláte úlohy prostřednictvím uživatelského rozhraní studio Azure Machine Learning nebo rozhraní příkazového řádku, místo odesílání úloh prostřednictvím sady SDK použijte úlohy rozhraní příkazového řádku nebo Azure DevOps Machine Learning ke konfiguraci kroků kanálu automatizace. Tento proces může snížit nároky na kód opětovným použitím stejných odeslání úloh přímo z kanálů automatizace.
Použijte programování založené na událostech. Můžete například aktivovat offline testovací kanál modelu pomocí Služby Azure Functions po registraci nového modelu. Nebo pošlete oznámení určenému e-mailovému aliasu, když se nepodaří spustit kritický kanál. Azure Machine Learning vytváří události ve službě Azure Event Grid. K odběru události se může přihlásit více rolí.
Při použití Azure DevOps pro automatizaci použijte Azure DevOps Tasks for Machine Learning k použití modelů strojového učení jako triggerů kanálu.
Při vývoji balíčků Pythonu pro aplikaci strojového učení je můžete hostovat v úložišti Azure DevOps jako artefakty a publikovat je jako informační kanál. Pomocí tohoto přístupu můžete integrovat pracovní postup DevOps pro vytváření balíčků s pracovním prostorem Azure Machine Learning.
Zvažte použití přípravného prostředí k testování integrace systému kanálů strojového učení s upstreamovými nebo podřízenými komponentami aplikace.
Vytvořte testy jednotek a integrace pro koncové body odvozování pro vylepšené ladění a urychlete dobu nasazení.
K aktivaci opětovného trénování použijte monitorování datových sad a pracovní postupy řízené událostmi. Přihlaste se k odběru událostí posunu dat a automatizujte trigger kanálů strojového učení pro opětovné trénování.
Továrna AI pro operace strojového učení organizace
Tým datových věd se může rozhodnout, že může spravovat více případů použití strojového učení interně. Přijetí operací strojového učení pomáhá organizaci nastavit projektové týmy pro lepší kvalitu, spolehlivost a udržovatelnost řešení. Díky vyváženým týmům, podporovaným procesům a automatizaci technologií může tým, který přijímá operace strojového učení, škálovat a soustředit se na vývoj nových případů použití.
S rostoucím počtem případů použití v organizaci roste zatížení správy podpory případů použití lineárně nebo ještě více. Výzvou pro organizaci je urychlit uvedení na trh, urychlit posuzování proveditelnosti případů použití, implementovat opakovatelnost a nejlepší využití dostupných zdrojů a dovedností v řadě projektů. Pro mnoho organizací je řešením vývoj továrny AI.
AI Factory je systém opakovatelných obchodních procesů a standardizovaných artefaktů, které usnadňují vývoj a nasazení velké sady případů použití strojového učení. AI Factory optimalizuje nastavení týmu, doporučené postupy, strategii provozu strojového učení, vzory architektury a opakovaně použitelné šablony, které jsou přizpůsobené obchodním požadavkům.
Úspěšná továrna umělé inteligence spoléhá na opakovatelné procesy a opakovaně použitelné prostředky, aby organizace efektivně škálovala z desítek případů použití na tisíce případů použití.
Následující obrázek shrnuje klíčové prvky továrny umělé inteligence:

Standardizace opakovatelných vzorů architektury
Opakovatelnost je klíčovou vlastností továrny umělé inteligence. Týmy datových věd mohou urychlit vývoj projektů a zlepšit konzistenci napříč projekty tím, že vyvíjejí několik opakovatelných vzorů architektury, které pokrývají většinu případů použití strojového učení pro jejich organizaci. Pokud jsou tyto vzory zavedené, může většina projektů používat vzory k získání následujících výhod:
- Akcelerovaná fáze návrhu
- Akcelerovaná schválení it a bezpečnostních týmů při opětovném použití nástrojů napříč projekty
- Zrychlený vývoj kvůli opakovaně použitelné infrastruktuře jako šablony kódu a šablonám projektů
Vzory architektury můžou zahrnovat, ale nejsou omezeny na následující témata:
- Upřednostňované služby pro každou fázi projektu
- Možnosti připojení k datům a zásady správného řízení
- Strategie provozu strojového učení přizpůsobená požadavkům oboru, podnikání nebo klasifikace dat
- Experiment management champion and challenger models
Usnadnění spolupráce a sdílení mezi týmy
Úložiště a nástroje sdíleného kódu můžou urychlit vývoj řešení strojového učení. Úložiště kódu je možné během vývoje projektu vyvíjet modulárním způsobem, aby byla dostatečně obecná, aby se používala v jiných projektech. Dají se zpřístupnit v centrálním úložišti, ke kterému mají přístup všechny týmy datových věd.
Sdílení a opětovné použití duševního vlastnictví
Pokud chcete maximalizovat opakované použití kódu, projděte si následující duševní vlastnictví na začátku projektu:
- Interní kód, který byl navržen tak, aby se znovu používal v organizaci. Mezi příklady patří balíčky a moduly.
- Datové sady vytvořené v jiných projektech strojového učení nebo které jsou k dispozici v ekosystému Azure.
- Stávající projekty datových věd, které mají podobnou architekturu a obchodní problémy.
- Úložiště GitHub nebo open source, která můžou projekt urychlit.
Každá retrospektivní akce projektu by měla obsahovat položku akce, která určuje, zda lze prvky projektu sdílet a generalizovat pro širší opakované použití. Seznam prostředků, které může organizace sdílet a opakovaně používat, se v průběhu času rozšiřuje.
V rámci pomoci se sdílením a zjišťováním zavedlo mnoho organizací sdílené úložiště pro uspořádání fragmentů kódu a artefaktů strojového učení. Artefakty ve službě Azure Machine Learning, včetně datových sad, modelů, prostředí a kanálů, je možné definovat jako kód, takže je můžete efektivně sdílet napříč projekty a pracovními prostory.
Šablony projektů
Aby se urychlil proces migrace stávajících řešení a maximalizoval opětovné použití kódu, mnoho organizací standardizuje šablonu projektu, aby se zahájily nové projekty. Příklady šablon projektů, které se doporučují pro použití se službou Azure Machine Learning, jsou příklady služby Azure Machine Learning, proces životního cyklu Datová Věda a proces týmového Datová Věda.
Centrální správa dat
Proces získání přístupu k datům pro zkoumání nebo využití v produkčním prostředí může být časově náročný. Mnoho organizací centralizuje správu dat, aby spojily producenty dat a uživatele dat, aby se usnadnil přístup k datům pro experimentování ve strojovém učení.
Sdílené nástroje
Vaše organizace může používat centralizované řídicí panely pro celou organizaci ke konsolidaci informací o protokolování a monitorování. Řídicí panely můžou zahrnovat protokolování chyb, dostupnost služeb a telemetrii a monitorování výkonu modelu.
Pomocí metrik Azure Monitoru můžete vytvořit řídicí panel pro Azure Machine Learning a přidružené služby, jako je Azure Storage. Řídicí panel vám pomůže sledovat průběh experimentování, stav výpočetní infrastruktury a využití kvóty GPU.
Specializovaný technický tým strojového učení
Mnoho organizací implementovala roli inženýra strojového učení. Technik strojového učení se specializuje na vytváření a spouštění robustních kanálů strojového učení, monitorování odchylek a opětovného trénování pracovních postupů a monitorování řídicích panelů. Technik má celkovou odpovědnost za industrializaci řešení strojového učení od vývoje po výrobu. Inženýr úzce spolupracuje s datovými inženýry, architekty, zabezpečením a provozem, aby se zajistilo, že jsou zavedeny všechny nezbytné kontroly.
I když datové vědy vyžadují hluboké znalosti v oblasti domény, technika strojového učení je spíše technická. Rozdíl znamená, že technik strojového učení je flexibilnější, aby mohl pracovat na různých projektech a s různými obchodními odděleními. Velké postupy pro datové vědy můžou těžit ze specializovaného technického týmu strojového učení, který řídí opakovatelnost a opakované použití pracovních postupů automatizace v různých případech použití a obchodních oblastech.
Povolení a dokumentace
Je důležité poskytnout jasné pokyny k procesu vytváření umělé inteligence pro nové a stávající týmy a uživatele. Pokyny pomáhají zajistit konzistenci a snížit úsilí potřebné od technického týmu strojového učení při industrializaci projektu. Zvažte návrh obsahu speciálně pro různé role ve vaší organizaci.
Každý má jedinečný způsob učení, takže kombinace následujících typů pokynů může pomoct urychlit přijetí architektury AI factory:
- Centrální centrum, které obsahuje odkazy na všechny artefakty. Toto centrum může být například kanálem na microsoft Teams nebo na webu Microsoft SharePointu.
- Trénování a plán povolení navržený pro každou roli
- Souhrnná prezentace přístupu na vysoké úrovni a doprovodné video.
- Podrobný dokument nebo playbook
- Videa s návody
- Posouzení připravenosti
Operace strojového učení v řadě videí Azure
V sérii videí o operacích strojového učení v Azure se dozvíte, jak vytvořit operace strojového učení pro řešení strojového učení od počátečního vývoje až po produkční prostředí.
Etika
Etika hraje instrumentální roli při návrhu řešení umělé inteligence. Pokud nejsou implementované etické zásady, mohou natrénované modely vykazovat stejnou předsudku, jakou existují v datech, na která byly natrénovány. Výsledkem může být ukončení projektu. Důležitější je, že pověst organizace může být ohrožená.
Aby se zajistilo, že se v rámci projektů implementují klíčové etické principy, které organizace představuje, měla by organizace poskytnout seznam těchto principů a způsobů, jak je během testovací fáze ověřit z technického hlediska. Funkce strojového učení ve službě Azure Machine Learning vám pomohou pochopit, co je zodpovědné strojové učení a jak ho integrovat do operací strojového učení.
Další kroky
Přečtěte si další informace o tom, jak uspořádat a nastavit prostředí Služby Azure Machine Learning, nebo se můžete podívat na praktickou sérii videí o operacích strojového učení v Azure.
Další informace o správě rozpočtů, kvót a nákladů na úrovni organizace pomocí služby Azure Machine Learning:
Váš názor
Připravujeme: V průběhu roku 2024 budeme postupně vyřazovat problémy z GitHub coby mechanismus zpětné vazby pro obsah a nahrazovat ho novým systémem zpětné vazby. Další informace naleznete v tématu: https://aka.ms/ContentUserFeedback.
Odeslat a zobrazit názory pro