Sledování experimentů a modelů ML pomocí MLflow
V tomto článku se dozvíte, jak pomocí MLflow sledovat experimenty a spouštět se v pracovních prostorech Služby Azure Machine Learning.
Sledování je proces ukládání relevantních informací o experimentech, které spouštíte. Uložené informace (metadata) se liší podle vašeho projektu a můžou zahrnovat:
- Kód
- Podrobnosti o prostředí (například verze operačního systému, balíčky Pythonu)
- Vstupní data
- Konfigurace parametrů
- Modely
- Metriky vyhodnocení
- Vizualizace vyhodnocení (například matrice záměny, grafy důležitosti)
- Výsledky vyhodnocení (včetně některých předpovědí vyhodnocení)
Když pracujete s úlohami ve službě Azure Machine Learning, Azure Machine Learning automaticky sleduje některé informace o experimentech, jako je kód, prostředí a vstupní a výstupní data. Pro ostatní, jako jsou modely, parametry a metriky, ale tvůrce modelů musí nakonfigurovat sledování, protože jsou specifické pro konkrétní scénář.
Poznámka:
Pokud chcete sledovat experimenty spuštěné v Azure Databricks, přečtěte si téma Sledování experimentů Azure Databricks ML pomocí MLflow a Azure Machine Learning. Další informace o sledování experimentů spuštěných ve službě Azure Synapse Analytics najdete v tématu Sledování experimentů ML služby Azure Synapse Analytics pomocí MLflow a Azure Machine Learning.
Výhody sledování experimentů
Důrazně doporučujeme, aby odborníci na strojové učení sledovali experimenty bez ohledu na to, jestli trénujete úlohy ve službě Azure Machine Learning nebo interaktivně trénujete v poznámkových blocích. Sledování experimentů umožňuje:
- Uspořádejte všechny experimenty strojového učení na jednom místě. Pak můžete experimenty prohledávat a filtrovat a procházet k podrobnostem o experimentech, které jste spustili dříve.
- Porovnejte experimenty, analyzujte výsledky a laďte trénování modelu s trochou další práce.
- Reprodukujte nebo znovu spusťte experimenty, abyste ověřili výsledky.
- Vylepšete spolupráci, protože můžete zjistit, co dělají ostatní členové týmu, sdílet výsledky experimentů a přistupovat k datům experimentů prostřednictvím kódu programu.
Proč používat MLflow ke sledování experimentů?
Pracovní prostory Azure Machine Learning jsou kompatibilní s MLflow, což znamená, že můžete pomocí MLflow sledovat běhy, metriky, parametry a artefakty v pracovních prostorech Služby Azure Machine Learning. Hlavní výhodou použití MLflow ke sledování je, že nemusíte měnit trénovací rutiny pro práci se službou Azure Machine Learning nebo vkládání jakékoli syntaxe specifické pro cloud.
Další informace o všech podporovaných funkcích MLflow a Azure Machine Learning najdete v tématu MLflow a Azure Machine Learning.
Omezení
Některé metody dostupné v rozhraní API MLflow nemusí být při připojení ke službě Azure Machine Learning dostupné. Podrobnosti o podporovaných a nepodporovaných operacích najdete v matici podpory pro dotazování spuštění a experimentů.
Požadavky
- Předplatné Azure. Pokud ještě nemáte předplatné Azure, vytvořte si napřed bezplatný účet. Vyzkoušejte bezplatnou nebo placenou verzi služby Azure Machine Learning.
Nainstalujte balíček
mlflowMLflow SDK a modul plug-in Azure Machine Learningazureml-mlflowpro MLflow:pip install mlflow azureml-mlflowTip
Můžete použít
mlflow-skinnybalíček, což je jednoduchý balíček MLflow bez závislostí sql Storage, serveru, uživatelského rozhraní nebo datových věd.mlflow-skinnyse doporučuje uživatelům, kteří primárně potřebují funkce sledování a protokolování MLflow bez importu celé sady funkcí, včetně nasazení.Pracovní prostor služby Azure Machine Learning. Pokud chcete vytvořit pracovní prostor, přečtěte si kurz Vytvoření prostředků strojového učení. Zkontrolujte přístupová oprávnění, která potřebujete k provádění operací MLflow ve vašem pracovním prostoru.
Pokud provádíte vzdálené sledování (to znamená sledování experimentů spuštěných mimo Azure Machine Learning), nakonfigurujte MLflow tak, aby ukazoval na identifikátor URI sledování pracovního prostoru Azure Machine Learning. Další informace o připojení MLflow k pracovnímu prostoru najdete v tématu Konfigurace MLflow pro Azure Machine Learning.
Konfigurace experimentu
MLflow organizuje informace v experimentech a spuštěních (spuštění se nazývají úlohy ve službě Azure Machine Learning). Ve výchozím nastavení se spuštění protokolují do experimentu s názvem Výchozí , který se automaticky vytvoří za vás. Můžete nakonfigurovat experiment, ve kterém probíhá sledování.
Pro interaktivní trénování, například v poznámkovém bloku Jupyter, použijte příkaz mlflow.set_experiment()MLflow . Například následující fragment kódu konfiguruje experiment:
experiment_name = 'hello-world-example'
mlflow.set_experiment(experiment_name)
Konfigurace spuštění
Azure Machine Learning sleduje jakoukoli trénovací úlohu v tom, co MLflow volá spuštění. Pomocí spuštění zachyťte veškeré zpracování, které vaše úloha provádí.
Když pracujete interaktivně, MLflow začne sledovat trénovací rutinu hned, jak se pokusíte protokolovat informace, které vyžadují aktivní spuštění. Sledování MLflow se například spustí při protokolování metriky, parametru nebo spuštění trénovacího cyklu a funkce automatického protokolování Mlflow je povolená. Obvykle je ale užitečné spustit spuštění explicitně, speciálně pokud chcete zachytit celkový čas experimentu v poli Doba trvání . Chcete-li spustit spuštění explicitně, použijte mlflow.start_run().
Bez ohledu na to, jestli spuštění spustíte ručně nebo ne, budete nakonec muset spuštění zastavit, aby MLflow věděl, že je spuštění experimentu hotové a může označit stav spuštění jako Dokončeno. Chcete-li zastavit spuštění, použijte mlflow.end_run().
Důrazně doporučujeme spustit spuštění ručně, abyste je při práci v poznámkových blocích nezapomněli ukončit.
Pokud chcete spustit spuštění ručně a ukončit ho po dokončení práce v poznámkovém bloku:
mlflow.start_run() # Your code mlflow.end_run()Obvykle je užitečné použít paradigma kontextového manažera, které vám pomůže zapamatovat si ukončení spuštění:
with mlflow.start_run() as run: # Your codeKdyž spustíte nové spuštění pomocí
mlflow.start_run(), může být užitečné zadatrun_nameparametr, který se později přeloží na název spuštění v uživatelském rozhraní služby Azure Machine Learning a pomůže vám rychleji identifikovat spuštění:with mlflow.start_run(run_name="hello-world-example") as run: # Your code
Povolení automatickéhologování MLflow
Metriky, parametry a soubory můžete protokolovat ručně pomocí MLflow . Můžete se ale také spolehnout na funkci automatického protokolování MLflow. Každá architektura strojového učení podporovaná MLflow rozhoduje, co se má automaticky sledovat za vás.
Pokud chcete povolit automatické protokolování, vložte před trénovací kód následující kód:
mlflow.autolog()
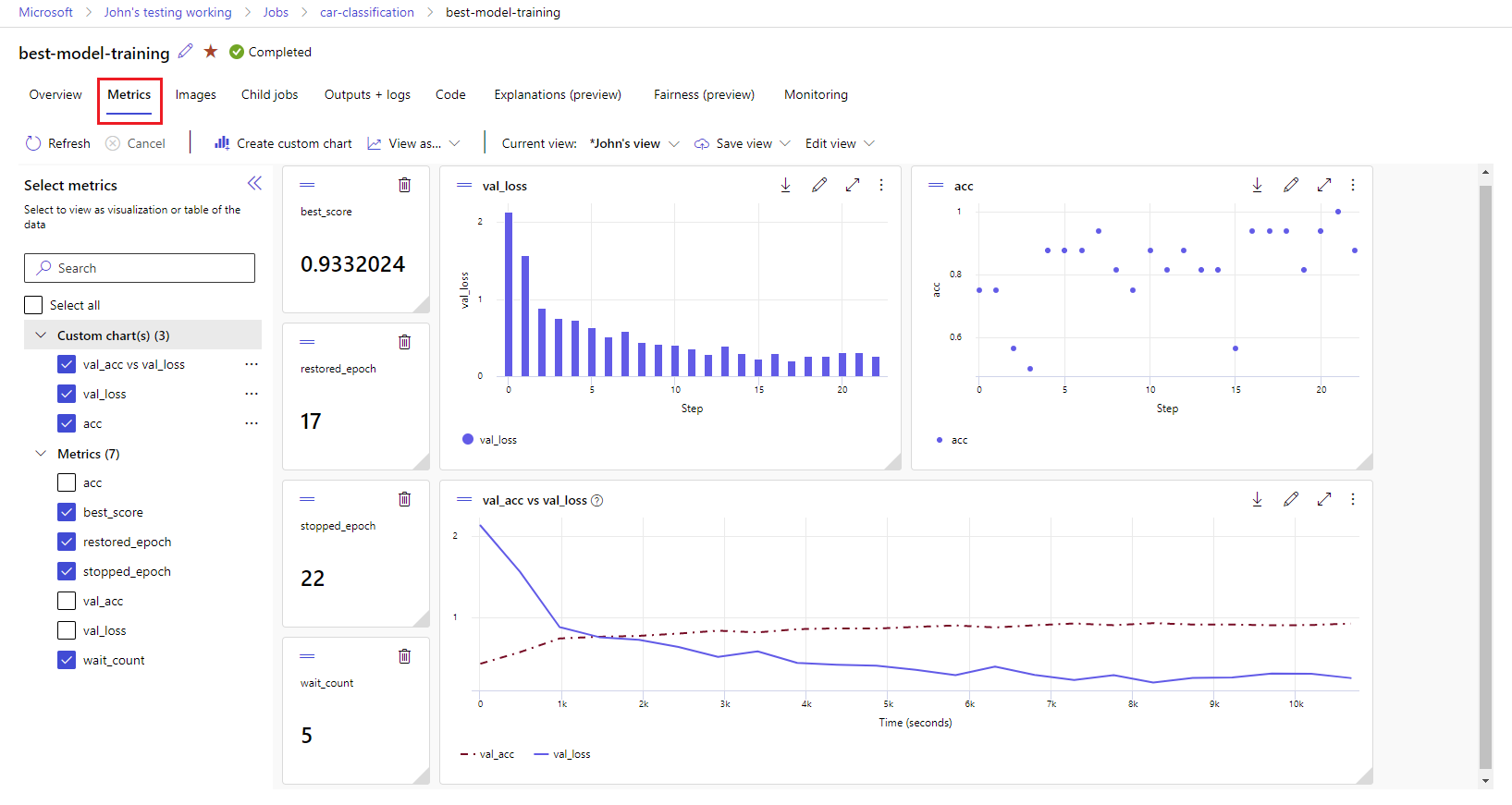
Zobrazení metrik a artefaktů v pracovním prostoru
Metriky a artefakty z protokolování MLflow se sledují ve vašem pracovním prostoru. Můžete je zobrazit a přistupovat k nim v sadě Studio kdykoli nebo k nim přistupovat programově prostřednictvím sady MLflow SDK.
Zobrazení metrik a artefaktů v sadě Studio:
Přejděte na studio Azure Machine Learning.
Přejděte do svého pracovního prostoru.
Vyhledejte experiment podle názvu v pracovním prostoru.
Vyberte protokolované metriky pro vykreslení grafů na pravé straně. Grafy můžete přizpůsobit použitím vyhlazení, změnou barvy nebo vykreslením více metrik v jednom grafu. Můžete také změnit velikost a změnit uspořádání rozložení podle potřeby.
Jakmile vytvoříte požadované zobrazení, uložte ho pro budoucí použití a nasdílejte ho s ostatními členy týmu pomocí přímého odkazu.

Pokud chcete prostřednictvím sady MLflow SDK programově přistupovat k metrikám, parametrům a artefaktům, použijte mlflow.get_run().
import mlflow
run = mlflow.get_run("<RUN_ID>")
metrics = run.data.metrics
params = run.data.params
tags = run.data.tags
print(metrics, params, tags)
Tip
U metrik vrátí předchozí ukázkový kód pouze poslední hodnotu dané metriky. Pokud chcete načíst všechny hodnoty dané metriky, použijte metodu mlflow.get_metric_history . Další informace o načítání hodnot metriky najdete v tématu Získání parametrů a metrik ze spuštění.
Pokud chcete stáhnout artefakty, které jste protokolovali, například soubory a modely, použijte mlflow.artifacts.download_artifacts().
mlflow.artifacts.download_artifacts(run_id="<RUN_ID>", artifact_path="helloworld.txt")
Další informace o tom, jak načíst nebo porovnat informace z experimentů a spuštění ve službě Azure Machine Learning pomocí MLflow, najdete v tématu Dotazování a porovnání experimentů a spuštění pomocí MLflow.